こんばんわ。mixiグループ Advent Calendar 2015 14日目の記事です!
実は Diverse Advent Calendar 2015 にもちゃっかり登録させてもらっています。 重複登録は出来ないようでしたm(_ _)m
よろしくお願いします。
背景
突然ですが、みなさんホワイトボードは使っていますか?
ミクシィグループでは、開発手法にスクラムを取り入れている部署もあり、多くでホワイトボード+ポストイットがタスク管理の一端を担っています。
IT時代のIT企業でも部分的とはいえタスク管理にアナログな方法が使われているのは喜べないことかもしれませんが、デジタルとアナログ、それぞれの良い所を上手く使うことが大切ですね。
さて、私もそんなIT企業に勤める人間なので、当然自宅にもホワイトボードがあります(↓自宅のホワイトボードの図)。

(汚かったので頑張って掃除しました)
それっぽくタスクをポストイットに書いて貼ることで毎朝目が覚めると同時に色々と確認できて非常に良いのですが、いざ外出すると何がタスクだったか忘れがちです。
今回は、「外出中でもホワイトボード確認したい!」という思いを実現させるため、ホワイトボードの写真をとってポストイットをデジタルで管理することに試みましたので、その道筋を紹介します。
(もっと良いやり方があるよ!という場合はご指摘くださると幸いです!)
環境: Python 3.4.3 (pyenv), OpenCV 3.0.0
流れ
- OpenCV のインストール
- 画像の2値化から輪郭検出
- ポストイット部分を取得
- ポストイットの色でクラスタリング
OpenCV のインストール
pyenv環境だと、Anacondaをインストールしていれば簡単にインストールできます。
conda install -c https://conda.binstar.org/menpo opencv
今回はpyenvで既にある環境の上で使いたかったので、homebrew でインストールしました。
brew tap homebrew/science
brew install opencv3 --with-python3
brew link opencv3 --force
pyenv 環境の Python 3 から OpenCV を利用できるようにリンクをはる必要があります。
ln -s /usr/local/Cellar/opencv3/3.0.0/lib/python3.4/site-packages/cv2.so ~/[pyenv_path]/versions/3.4.3/lib/python3.4/site-packages/cv2.so
ipython などのインタプリタ環境で cv2 が import 出来れば完了です。
$ ipython
In [1]: import cv2
In [2]: cv2.__version__
Out[2]: '3.0.0'
画像の2値化から輪郭検出
OpenCV を使って画像の2値化を行い、そこからポストイット部分だけ取り出すため、ポストイットの輪郭部分の取得を行います。今回は我が家のホワイトボードのこの写真を使用しました!

まずは2値化までの部分を。
image_dir = './image/'
image_file = 'xxx.jpg'
im = cv2.imread(image_dir + image_file, 1) #(A)
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) #(B)
im_blur = cv2.GaussianBlur(im_gray, (11, 11), 0) #(C)
(A)で画像を3カラーチャネルで読み込んでいますが、二値化を行うにはグレースケールの画像に変換する必要があり、それを行っているのが(B)にあたります。(B)の第二引数は定数で、他にもBGR2HSV等様々な変換をcvtColorによって行えます。
グレースケール化した画像のしきい値を判別しやすくするため、(C)でガウシアンブラーをかけています。
前処理の終わった画像に2値化処理を行います。2値化というのは、グレースケールで与えられている画像を(基本的には)0と255の2色で置き換えるものです。ここで使用するのが threshold 関数なのですが、全体に対してしきい値を設定する threshold関数 と、部分に応じて適応的にしきい値を設定する adaptiveThreshold 関数があります。
ret1, th1 = cv2.threshold(im_blur, 127, 255, cv2.THRESH_BINARY_INV)
th2 = cv2.adaptiveThreshold(im_blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 3)
threshold は第二引数をしきい値として、画像全体の2値化を行います。
adaptiveThreshold の第5引数は、しきい値を取る際に見る範囲で、その範囲から計算したしきい値から第6引数を引いたものが最終的なしきい値になります。
範囲内のしきい値の計算法は、単純に範囲内のピクセルの平均を取る cv2.ADAPTIVE_THRESH_MEAN_C と、ガウシアンの重みをつけて平均を取る cv2.ADAPTIVE_THRESH_GAUSSIAN_C の二種類があります。
threshold の第4引数、adaptiveThreshold の第3引数は他にも色々な定数を取ります。
詳細は参考一覧からどうぞ。
適当な画像に適用してみたのが下図です。
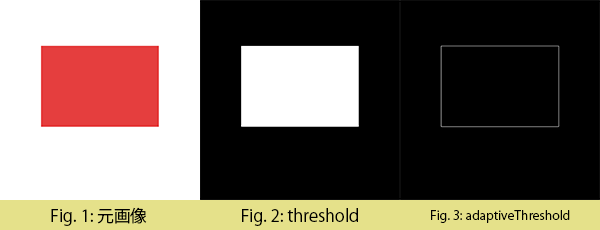
今回はポストイット部分を検出したいため、全体でしきい値を決める threshold に、しきい値を上手く決めてくれるアルゴリズムである OTSU アルゴリズムを使用しました。使用自体は非常に簡単で、先ほどの関数に少し足すだけです。
th = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)[1]
簡単に説明すると、OTSUアルゴリズム(大津アルゴリズム)というのは別段むずかしーいものというわけではなく、一般的には判別分析法、フィッシャーの線形判別などと呼ばれているものです。
2つのクラス(ここでは画像の背景と物体、等)があるときに(1)それぞれのクラス内の分散が小さく、(2)クラス間の分散が大きくなる、この(1)と(2)を満たすようなしきい値を求めています。そのため、こちらが人出でしきい値を設定する必要なく、画像だけ渡せば自動で最適なしきい値を算出してくれます。詳しく知りたい方は"判別分析法"などで調べてみてください。
最初に上げた写真にこれを適用すると、次のようになります。

全然取れてない!!!!!
ただ字の汚さが際立っただけみたいになってしまいました。
そのままグレースケールにするだけでは取れなかったので、今回は次の5つの2値化画像の和を最終的な2値化画像として使用しました。
- cvtColor を使用して元画像を2値化したもの
- 元の3つのカラーチャネルそれぞれの値を一次元のグレースケール画像にしたもの
- 3つのカラーチャネルの赤から他の青と緑を引いたものの和(赤がなかなか取れなかったので無理やり取るために作成、imを元画像として、下記の値)
(np.abs(int_im[:,:,2] - int_im[:,:,1]) + np.abs(int_im[:,:,2] - int_im[:,:,0]))
これらから5種類の2値化画像を作成し、全ての和を取って作成した画像がこちら!

それっぽい感じになってきました。
次に輪郭の座標を取得したいのですが、OpenCVには輪郭抽出する findContours 関数が既に用意されているのでそれを使います。
contours = cv2.findContours(im_th, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[1]
これにより、輪郭部分の情報が取得できます。
ポストイット部分を取得
その後は、取得した輪郭の頂点を元に面積が一定以上の大きさのところだけ取り出し、approxPolyDP 関数により直線近似に行って、得られた四角形部分を元の画像から切り抜いて保存します。
# filtered with area over (all area / 100 )
th_area = im.shape[0] * im.shape[1] / 100
contours_large = list(filter(lambda c:cv2.contourArea(c) > th_area, contours))
outputs = []
rects = []
approxes = []
for (i,cnt) in enumerate(contours_large):
arclen = cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, 0.02*arclen, True)
if len(approx) < 4:
continue
approxes.append(approx)
rect = getRectByPoints(approx)
rects.append(rect)
outputs.append(getPartImageByRect(rect))
cv2.imwrite('./out/output'+str(i)+'.jpg', getPartImageByRect(rect))
ここで、getPartImageByRect, getPartImageByRect として下記のような画像から指定範囲を切り抜いた画像を取得する関数を用意しました。
def getRectByPoints(points):
# prepare simple array
points = list(map(lambda x: x[0], points))
points = sorted(points, key=lambda x:x[1])
top_points = sorted(points[:2], key=lambda x:x[0])
bottom_points = sorted(points[2:4], key=lambda x:x[0])
points = top_points + bottom_points
left = min(points[0][0], points[2][0])
right = max(points[1][0], points[3][0])
top = min(points[0][1], points[1][1])
bottom = max(points[2][1], points[3][1])
return (top, bottom, left, right)
def getPartImageByRect(rect):
img = cv2.imread(image_dir + image_file, 1)
return img[rect[0]:rect[1], rect[2]:rect[3]]
これでポストイット部分を元画像から切り抜くことができました。
元画像に枠を入れてみたのが次の画像です。

無事に全てのポストイットが検出できています。あとはそれぞれの画像をアプリで持つなりサーバで管理するなりすればデジタル管理への道が拓けますね。
ポストイットの色でクラスタリング
ポストイットが使用されているところでは、多くの場合色によってタスクをカテゴライズしていると思います。せっかくなので、そこも管理できるようにしましょう。
次のような流れで考えます。
- 代表色の取得
- クラスタリング
- 同じクラスタの平均色をそのカテゴリの色として枠をつける
まず、それぞれ切り抜いた画像の代表色を取得します。
現在ポストイット部分のみ切り抜かれた画像になっているので、この画像は、周りの白、ポストイットの色、文字色の黒、の三色が入っていると考えられます。
すなわち、簡単に各カラーチャネルの中央値を代表色とすればポストイットの色が取れそうです。
t_colors = []
for (i,out) in enumerate(outputs):
color = np.zeros(3)
for j in range(3):
color[j] = np.median(out[:,:,j])
t_colors.append(color)
t_colors = np.array(t_colors)
次に、得られたそれぞれのポストイットの代表値をKMeans法を用いてクラスタリングを行いました。
KMeans法によるクラスタリングについては、Qiitaを始めとしたネット上にたくさんの分かりやすい解説があるのでそちらをご参照ください。
from sklearn.cluster import KMeans
# KMeans
cluster_num = 4 # num of colors
kmeans = KMeans(n_clusters=cluster_num).fit(t_colors)
labels = kmeans.labels_
centers = np.array(kmeans.cluster_centers_).astype(np.int) # convert into int to express color
さて、クラスタリングされた結果の色(と数字)を元の画像に足したものがこちらです!
かなり見づらいですが、0~3のクラスタリング結果のラベルをポストイット左上に書き足しています。

結果を見ると、青、赤は上手くクラスタリングされていますが、黄色と黄緑で光の当たり具合のせいか、それぞれが混ざったクラスとなってしまいました。
これは、画像のRGBチャネルそれぞれの要素だけをクラスタリングに使用したので、HSVに変換して彩度の情報も入れるとまた変わるかもしれませんが、今回はここまでです。
今後
今回の例は、あくまで私の自宅のホワイトボードだけ動作確認をしているため、もっと広く使えるようにする必要があります。また、クラスタリングに関しても不十分で、現状では色数が増えた際に対応出来ていません。
あと自分で毎朝写真取るのも馬鹿らしいので、誇りをかぶっているRaspberry Piさんを引っ張ってそこらへんも自動化してみたいので、また続きとして書こうと思います。
まとめ
ホワイトボード自宅導入を進めまくる記事を書こうとしていたらあんまりそこに触れられませんでした。
皆さんも自宅に一台はホワイトボードを導入しましょう。タスク管理も出来る、計算もできる、メモ書きも出来る。色々捗りますよ。
明日は、@isaoshimizu さんがなにか書いてくださります。よろしくお願いします。
参考
Mac に Python 3.4 + OpenCV 3.0 の環境をつくる
https://librabuch.jp/2015/07/python-34_opencv-30_mac/
OpenCVで輪郭抽出
http://docs.opencv.org/master/d4/d73/tutorial_py_contours_begin.html#gsc.tab=0
cv2.threshold (OpenCV 2.1)
http://opencv.jp/opencv-2.1/cpp/miscellaneous_image_transformations.html#cv-threshold
cv2.adaptiveThreshold (OpenCV 2.1)
http://opencv.jp/opencv-2.1/cpp/miscellaneous_image_transformations.html#cv-adaptivethreshold
cv2.findContours (OpenCV 2.1)
http://opencv.jp/opencv-2.1/cpp/structural_analysis_and_shape_descriptors.html#cv-findcontours