目的
Yellowfin(BIツール)にはもともと用意された関数の他に、自分で関数を作って拡張できる「高度な関数」というものがあります。これまで使ったことがなく、プログラムを書かないといけないことから手を付けていなかったのですが、幾何平均を求めたいという要望があり、作ってみた感じを記事にしています。個人的には、正直公式のWikiだけではなかなか理解するのが難しいところもあったのでそこをフォローできたらいいなと思います。
はじめに
基本的な開発の始め方としては、Eclipseを使って開発するのですが、高度な関数の基礎を見ながら設定すれば自動的に必要なメソッドがAnalyticalFunctionからOverrideして追加されるので、その中のパラメータを設定して、必要な処理をapplyAnalyticFunctionメソッドの中で記述していく流れになります。
1つのカラムの合計を出す関数(累積合計)であれば、高度な関数の作成を見ればわかると思います。この例では選択したカラムから1レコードずつ足していくだけですね。結果的に、applyAnalyticFunctionのreturnの値がレポートの方に返されます。
公式wikiから抜粋↓
import com.hof.mi.interfaces.AnalyticalFunction;
public class AccumulativeTotal
extends AnalyticalFunction{
private Double total = 0.0;
public String getName()
{
return "Accumulative Total";
}
public String getDescription()
{
return "Calculates the accumulative total for the selected field";
}
public String getCategory()
{
return "Analysis";
}
public String getColumnHeading(String colName)
{
return "Accumulative Total of " + colName;
}
public int getReturnType()
{
return TYPE_NUMERIC;
}
public boolean acceptsNativeType(int type)
{
return type == TYPE_NUMERIC;
}
public Object applyAnalyticFunction(int index, Object value) throws Exception
{
if (value == null) return null;
this.total += Double.valueOf(value.toString());
return this.total;
}
}
TYPE_NUMERICのような定数については高度な関数付録を参照してください。Integer値と定数とどちらでも大丈夫です。
カラム全体に対しての数値の処理について(例.幾何平均)
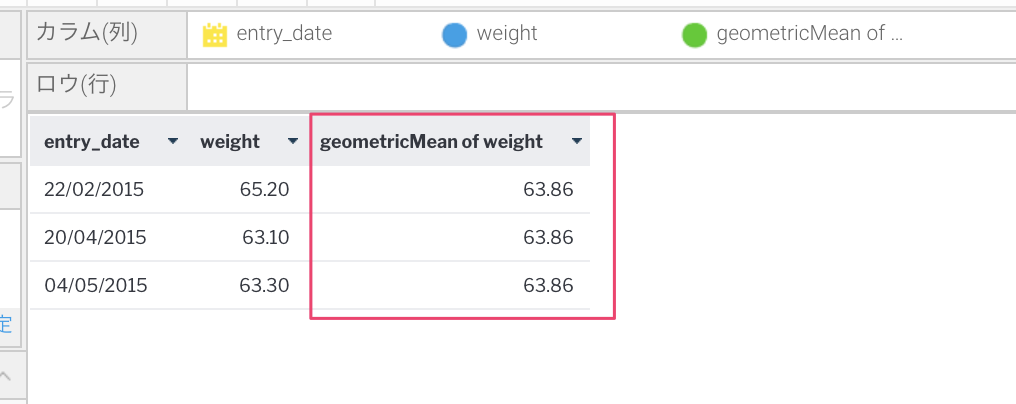
これは詳しくはあまり載っていなかったので手探りで試してみたのですが、高度な関数の作成にしれっと書いてあるpreAnalyticFunctionメソッドを使用します。データセット全体に渡り操作を実行するために使用されます。と書かれているんですがサンプルが書いてないのでイメージしにくいんですよね。先程のコードの追加・変更の部分のみ記載します。
解説としては、preAnalyticFunctionの引数selectedColにカラムの値のオブジェクト配列がレコード分格納されているので、初めだけthis.totalに代入してその後は何回処理を繰り返したかをcntでインクリメントしながら掛けていきます。
最終的に、Math.powで処理を繰り返した数で冪根(累乗根)したものをapplyAnalyticFunctionでそのまま返(表示)しているだけです。
private int cnt = 0;//add
public Object applyAnalyticFunction(int index, Object value) throws Exception {//modify method
// TODO Auto-generated method stub
if (value == null) return null;
return this.total;
}
public void preAnalyticFunction(Object[] selectedCol){//add method
this.total=0.0;
for (Object value : selectedCol) {
if (value!=null) {
if(this.total==0.0){
this.total = Double.valueOf(value.toString());
} else {
this.total= this.total * Double.valueOf(value.toString());
}
cnt++;
}
}
this.total = Math.pow( this.total, (double)1/cnt);
}
public Object applyAnalyticFunction(int index, Object value) throws Exception {//modify
// TODO Auto-generated method stub
if (value == null) return null;
return this.total;
}
選択したカラムに対して他のカラムを比較したい・他のカラムも含めて処理したい場合(例.共分散)
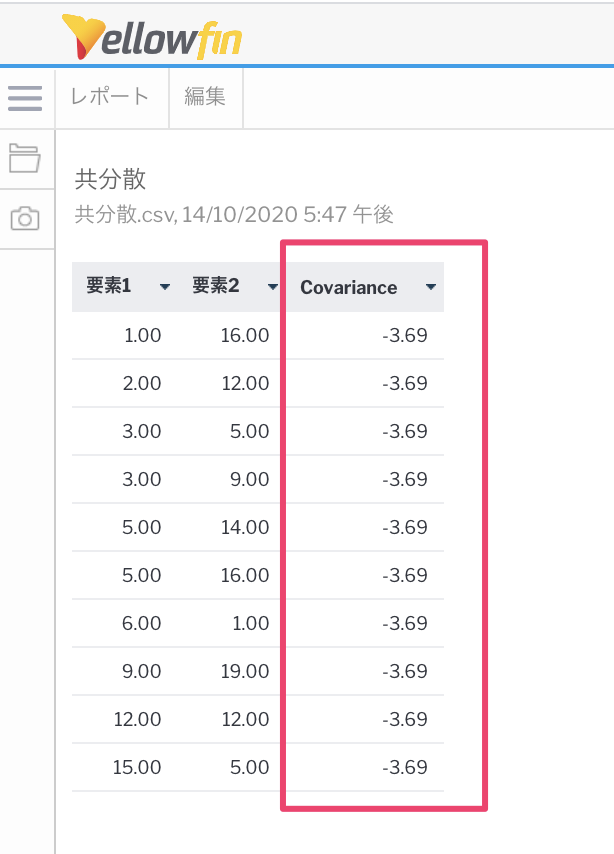
高度な関数を使用するカラムの他に任意のカラムに対しての影響・比較をしたい時にユーザーにカラムを指定させて関数を実行するといったこともできるようです。
これもwikiでは分かりづらかったのですが、パラメーターセットアップのsetupParametersのaddParameterメソッドを通してパラメーターに加えることでgetParameterValue("ユニークキー")でその設定したパラメーターが取得できます。この時にparameterのsetDataTypeをTYPE_FIELD(100)にすることで任意のカラムを選択できるようになります。
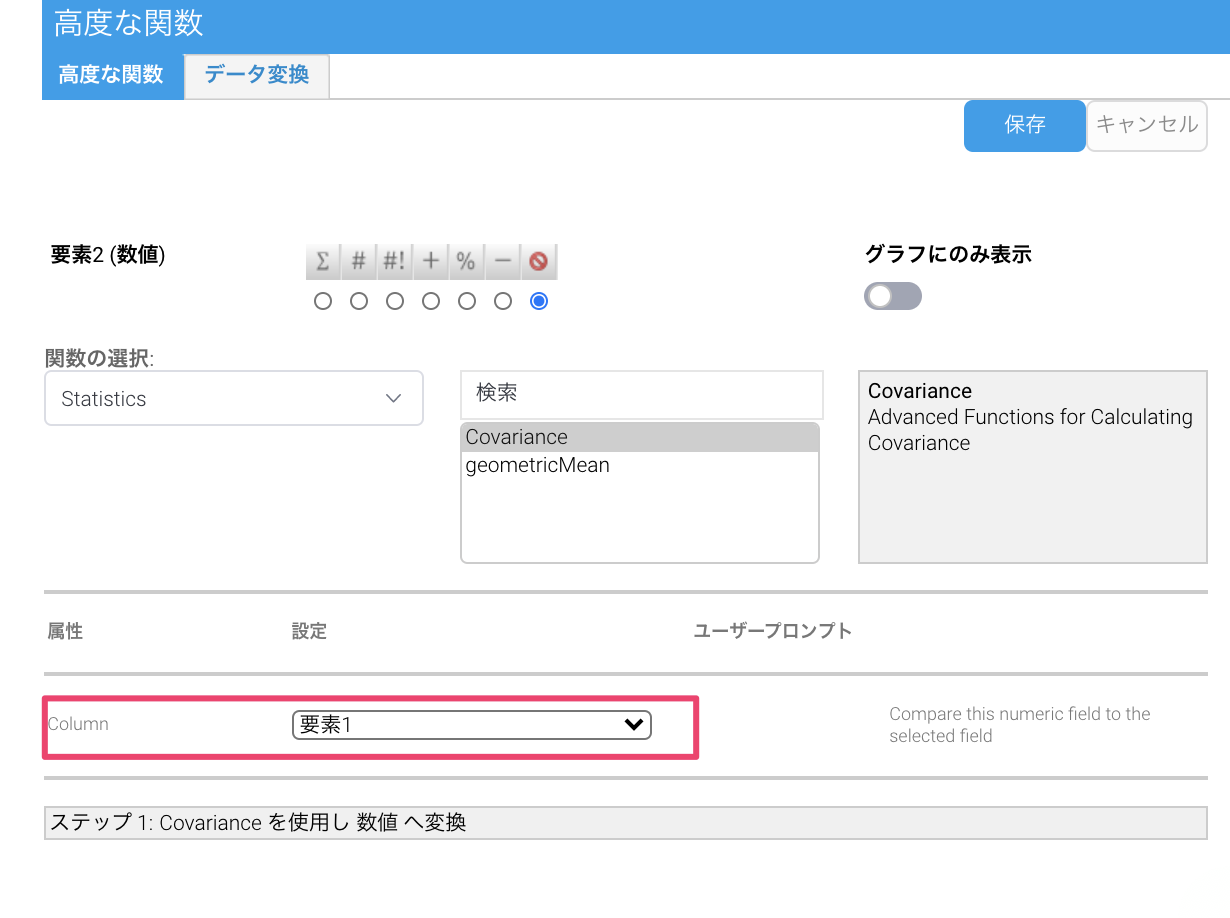
コードの解説ですが、これも一番初めのwikiのコードからの変更点のみ記載します。
preAnalyticFunctionで高度な関数を適用した値(selectedCol)のオブジェクト配列と、早速getParameterValueで先程解説したユニークキー"FIELD_SELECTION"のカラムの値(inputColumn)のオブジェクト配列を取得し(上の画像では要素1)、それぞれDouble型にキャストして配列に加えていきます。そこでこの2つの配列をcovarianceに渡して共分散の値を取得しています。
covarianceとsumメソッドについては共分散と合計を求めるだけなので解説を割愛します。
import java.util.ArrayList;//add
import java.util.List;//add
private List<Double> items1 = new ArrayList<>();//add
private List<Double> items2 = new ArrayList<>();//add
protected void setupParameters() {//add
Parameter p = new Parameter();
p.setUniqueKey("FIELD_SELECTION");
p.setDisplayName("Column");
p.setDescription("Compare this numeric field to the selected field");
p.setDataType(TYPE_FIELD);//100
p.setAcceptsFieldType(TYPE_NUMERIC, true);
p.setDisplayType(DISPLAY_SELECT);//6
addParameter(p);
}
public void preAnalyticFunction(Object[] selectedCol){//add
this.total=0.0;
Object [] inputColumn = (Object[]) getParameterValue("FIELD_SELECTION");
for (Object value : selectedCol) {
items1.add(Double.valueOf(value.toString()));
}
for (Object value : inputColumn) {
items2.add(Double.valueOf(value.toString()));
}
Double r = covariance(items1, items2);
this.total = r;
}
public Object applyAnalyticFunction(int index, Object value) throws Exception {//modify
// TODO Auto-generated method stub
if (value == null) return null;
return this.total;
}
public Double covariance(final List<Double> items1, final List<Double> items2) {//add
List<Double> items3 = new ArrayList<>();
int n = items1.size();
Double i1Mean = sum(items1)/n;
Double i2Mean = sum(items2)/n;
for (int i = 0; i < n; i++) {
items3.add((i1Mean - items1.get(i)) * (i2Mean - items2.get(i)));
}
Double i3Sum = sum(items3);
return i3Sum / n;
}
public Double sum(final List<Double> items) {//add
Double result = 0.0;
for (Double item : items) {
result += item;
}
return result;
}
ということで
少し説明が長くなってしまいましたが、高度な関数を作成することでレポートで表現するには少しめんどくさいこと(多重なreportFromReportなど)をJavaで書ける範囲ですぐに値を出すことができるようになり、コーディングの手間はかかりますが、いつも社内で使っているある一定の式を当てたい・2つのカラムの関係性を求めたいなどの処理を簡単にてきようできるようになりますね。