この記事は…
マイナビ出版の『つくりながら学ぶ!深層強化学習 -PyTorch による実践プログラミング-』の Q学習の Pythonコードを Excel VBA で実装しなおして、Excel VBA でも強化学習をやってみちゃおう!という内容です。強化学習 や Q学習 の詳しい内容は上記書籍を参考にしてください。
強化学習は他の書籍を読んでも何をやってるのかよくわからなかったのですが、上記書籍を読んでなんとなくイメージができるようになりました。
そして… VBA で作ることにより、より一層深く理解できるんじゃないかな?と思ってこの記事を書きました。
お断り
Q学習の Pythonコードを VBAで実装しなおすことが目的なため、コードの最適化等は行っていません。
また、若干処理の内容を変えている部分があります。
こういう感じのものを作ります
シートの作成
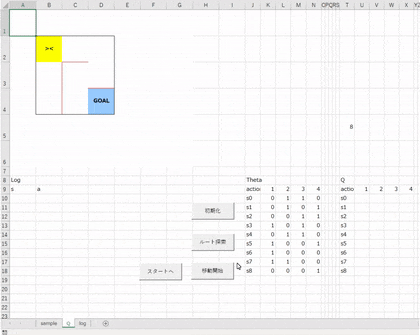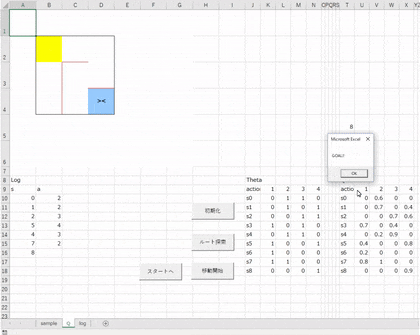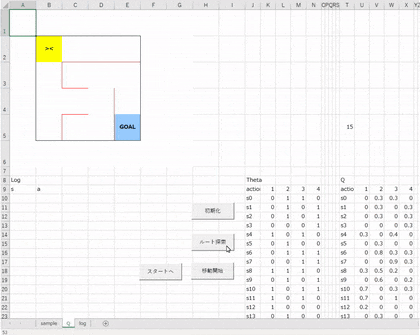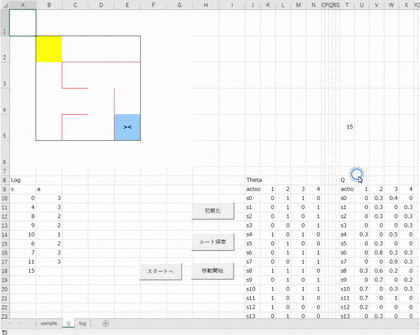
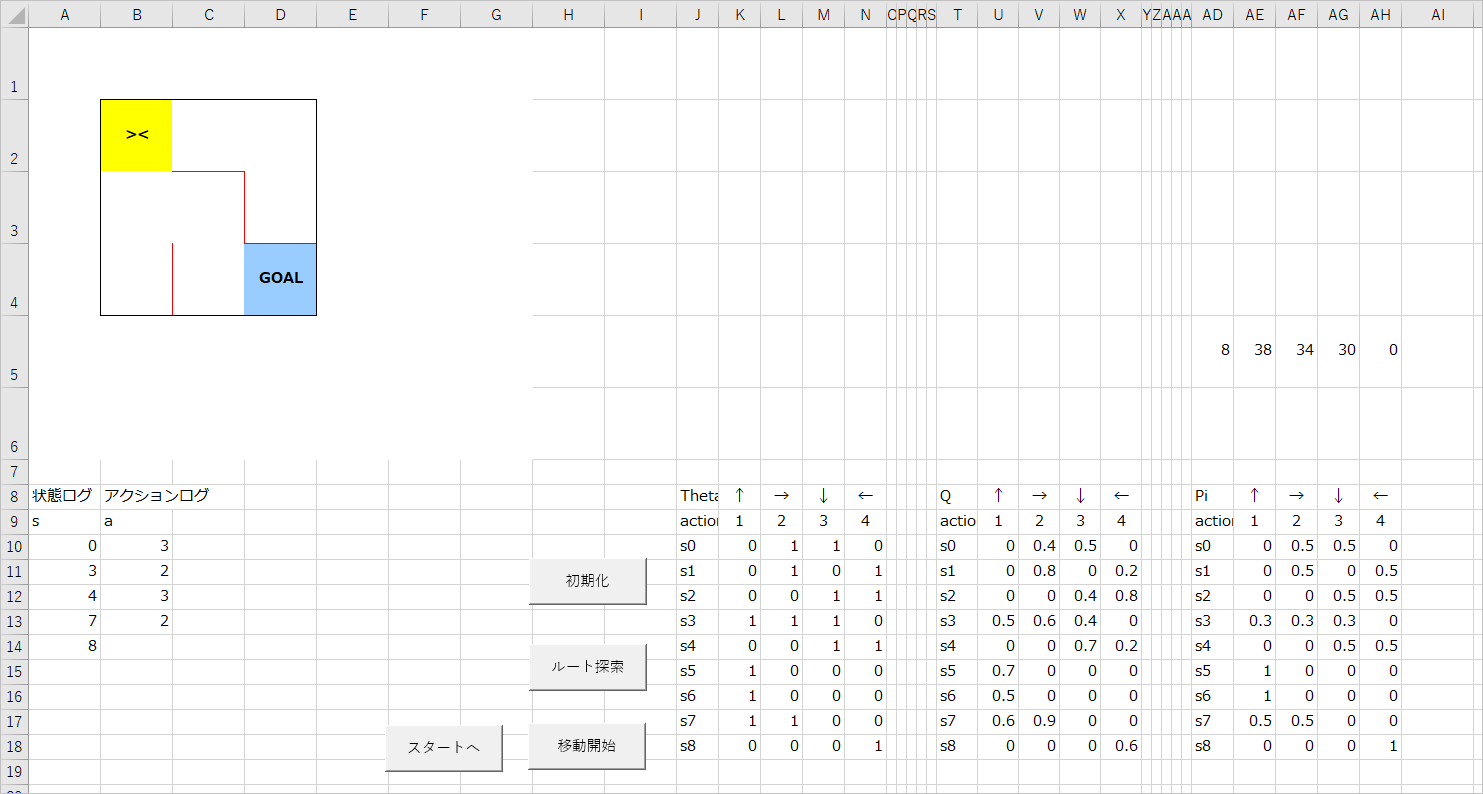
メインとなるシートをこのように作成します。
1行目から6行目は高さを72ピクセルにしています(列幅と同じにしています)。
J列以降の列幅は適当で。ここでは42ピクセル、最も狭い幅は10ピクセルにしています。
迷路部分は壁を罫線で描いています。
まわりの壁は黒、中の壁は赤にしていますが、コード的には特に関係がないので、好きな色にしていただいてかまいません。
ボタンの位置などは適当でよいですが、各項目はこの位置(セル)にしておいてください。
ちなみに、見切れている部分ですが、J8セルは「Theta」、J9、T9、AD9セルは「action」と書かれています。
VBAコード
VBEを開いてコードを書いていきましょう。
さぁ、強化学習の時間だ!(モーパイ風)
モジュールの追加など
標準モジュールを4つ追加し、以下のオブジェクト名に変更しておきます。
(ただし、「G」以外のオブジェクト名はコード内では使用しません。)
| オブジェクト名 | 内容 |
|---|---|
| G | 定数などの宣言 |
| mdlInit | 初期化 |
| mdlRL | 学習 |
| mdlMove | エージェントの移動 |
また、メインのシートのオブジェクト名を以下のように変更しておきます。シート名は適当なものにしておいてください。
| オブジェクト名 | 内容 |
|---|---|
| wsMain | メインのシート |
定数の宣言
標準モジュール「G」に定数などを宣言します。
Option Explicit
Public Const AD_END_S As String = "AD5" '迷路のゴールの状態値(s)を格納するセル
Public Const OFFSET_T_Q As Long = 10 'Theta から Q を計算する際に使用
Public Const OFFSET_T_P As Long = 20 'Theta から Pi を計算する際に使用
Public Const AGENT As String = "><" 'エージェントを表す文字列
Public Enum eRW '行の設定
MAZE_START = 2 '迷路のスタート位置
PARAM_RANDOM_POINT = 5 'np.random.choiceの代用実装で使用
PARAM_START = 10 'パラメータの開始行
LOG_START = 10 'ログ(状態、アクション)の開始行
End Enum
Public Enum eCL
MAZE_START = 2 '列の設定
THETA_ = 10 'Theta の項目列
THETA_UP = 11 'Theta の 上 パラメータ列
THETA_RIGHT = 12 'Theta の 右 パラメータ列
THETA_DOWN = 13 'Theta の 下 パラメータ列
THETA_LEFT = 14 'Theta の 左 パラメータ列
Q_ = 20 'Q の 項目列
Q_UP = 21
Q_RIGHT = 22
Q_DOWN = 23
Q_LEFT = 24
PI_ = 30 'Piの項目列
PI_UP = 31
PI_RIGHT = 32
PI_DOWN = 33
PI_LEFT = 34
LOG_S = 1 '状態ログ
LOG_A = 2 'アクションログ
End Enum
Public Enum eAction 'アクション
UP_ = 1
RIGHT_ = 2
DOWN_ = 3
LEFT_ = 4
End Enum
Public pRwMazeEnd As Long '迷路の終端行
Public pClMazeEnd As Long '迷路の終端列
初期化処理
「mdlInit」に初期化処理を記述します。
迷路の一辺のサイズを取得する
3×3以外の迷路でも対応できるように、迷路のサイズを取得しておきます。
'迷路の一辺のサイズを取得する
Private Function getSize() As Long
Dim c As Long '列カウンタ
Dim size As Long '迷路の一辺のサイズ
With wsMain
size = 0
'今回はシートの作りの都合上、最大5×5なので6列目までをチェック
'壁の長さを計る
For c = eCL.MAZE_START To 6
If .Cells(eRW.MAZE_START, c).Borders(xlEdgeTop).LineStyle = xlContinuous Then
size = size + 1
End If
Next
End With
getSize = size
End Function
迷路のリセット
エージェントをスタート位置に戻してゴールに「GOAL」と表示します。
このプロシージャは他のモジュールからも呼ばれるため、Public にしています。
'迷路を初期化、エージェントをスタート位置にセット
Public Sub ResetMaze()
With wsMain
.Range(.Cells(eRW.MAZE_START, eCL.MAZE_START), .Cells(G.pRwMazeEnd, G.pClMazeEnd)).ClearContents
.Cells(eRW.MAZE_START, eCL.MAZE_START).Value = G.AGENT
.Cells(G.pRwMazeEnd, G.pClMazeEnd).Value = "GOAL"
End With
End Sub
ログのクリア
状態ログとアクションログをクリアします。
このプロシージャも他のモジュールからも呼ばれるため、Public にしています。
Public Sub ClearLog()
Dim lastR As Long '最終行
With wsMain
lastR = .Cells(.Rows.count, eCL.LOG_S).End(xlUp).Row
If lastR < eRW.LOG_START Then
lastR = eRW.LOG_START
End If
.Range(.Cells(eRW.LOG_START, eCL.LOG_S), .Cells(lastR, eCL.LOG_A)).ClearContents
End With
End Sub
初期化
いろいろ初期化します。
Public Sub Click_Initialize()
Dim r As Long '行カウンタ
Dim c As Long '列カウンタ
Dim sR As Long '状態カウンタ
Dim lastR As Long '最終行
Dim size As Long '迷路の一辺のサイズ
'ログをクリア
Call ClearLog
With wsMain
'迷路の一辺のサイズを取得
size = getSize
'迷路の終端行、終端列を計算
G.pRwMazeEnd = eRW.MAZE_START + size - 1
G.pClMazeEnd = eCL.MAZE_START + size - 1
'迷路を初期化、エージェントをスタート位置にセット
Call ResetMaze
'Theta, Q, Pi パラメータをクリア
lastR = .Cells(.Rows.count, eCL.THETA_).End(xlUp).Row
If lastR < eRW.PARAM_START Then
lastR = eRW.PARAM_START
End If
.Range(.Cells(eRW.PARAM_START, eCL.THETA_), .Cells(lastR, eCL.PI_LEFT)).ClearContents
.Range(.Cells(eRW.PARAM_RANDOM_POINT, eCL.PI_), .Cells(eRW.PARAM_RANDOM_POINT, eCL.PI_LEFT)).ClearContents
'迷路の各セルにおける壁を調べて、移動できる方向を設定する(Theta)
'壁がある方向:0, 壁がない方向:1
sR = eRW.PARAM_START
For r = eRW.MAZE_START To G.pRwMazeEnd
For c = eCL.MAZE_START To G.pClMazeEnd
If .Cells(r, c).Borders(xlEdgeTop).LineStyle = xlContinuous Then
.Cells(sR, eCL.THETA_UP).Value = 0
Else
.Cells(sR, eCL.THETA_UP).Value = 1
End If
If .Cells(r, c).Borders(xlEdgeRight).LineStyle = xlContinuous Then
.Cells(sR, eCL.THETA_RIGHT).Value = 0
Else
.Cells(sR, eCL.THETA_RIGHT).Value = 1
End If
If .Cells(r, c).Borders(xlEdgeBottom).LineStyle = xlContinuous Then
.Cells(sR, eCL.THETA_DOWN).Value = 0
Else
.Cells(sR, eCL.THETA_DOWN).Value = 1
End If
If .Cells(r, c).Borders(xlEdgeLeft).LineStyle = xlContinuous Then
.Cells(sR, eCL.THETA_LEFT).Value = 0
Else
.Cells(sR, eCL.THETA_LEFT).Value = 1
End If
'パラメータの項目部分を設定
.Cells(sR, eCL.THETA_).Value = "s" & sR - eRW.PARAM_START
.Cells(sR, eCL.Q_).Value = "s" & sR - eRW.PARAM_START
.Cells(sR, eCL.PI_).Value = "s" & sR - eRW.PARAM_START
sR = sR + 1
Next
Next
'ゴールの状態値(s)をセルに格納(3×3の場合:3*3-1=8)
.Range(G.AD_END_S).Value = size * size - 1
End With
End Sub
初期化を実行
「Click_Initialize」プロシージャをメインシートの【初期化】ボタンに登録し、実行してみましょう。
このようになればOKです。
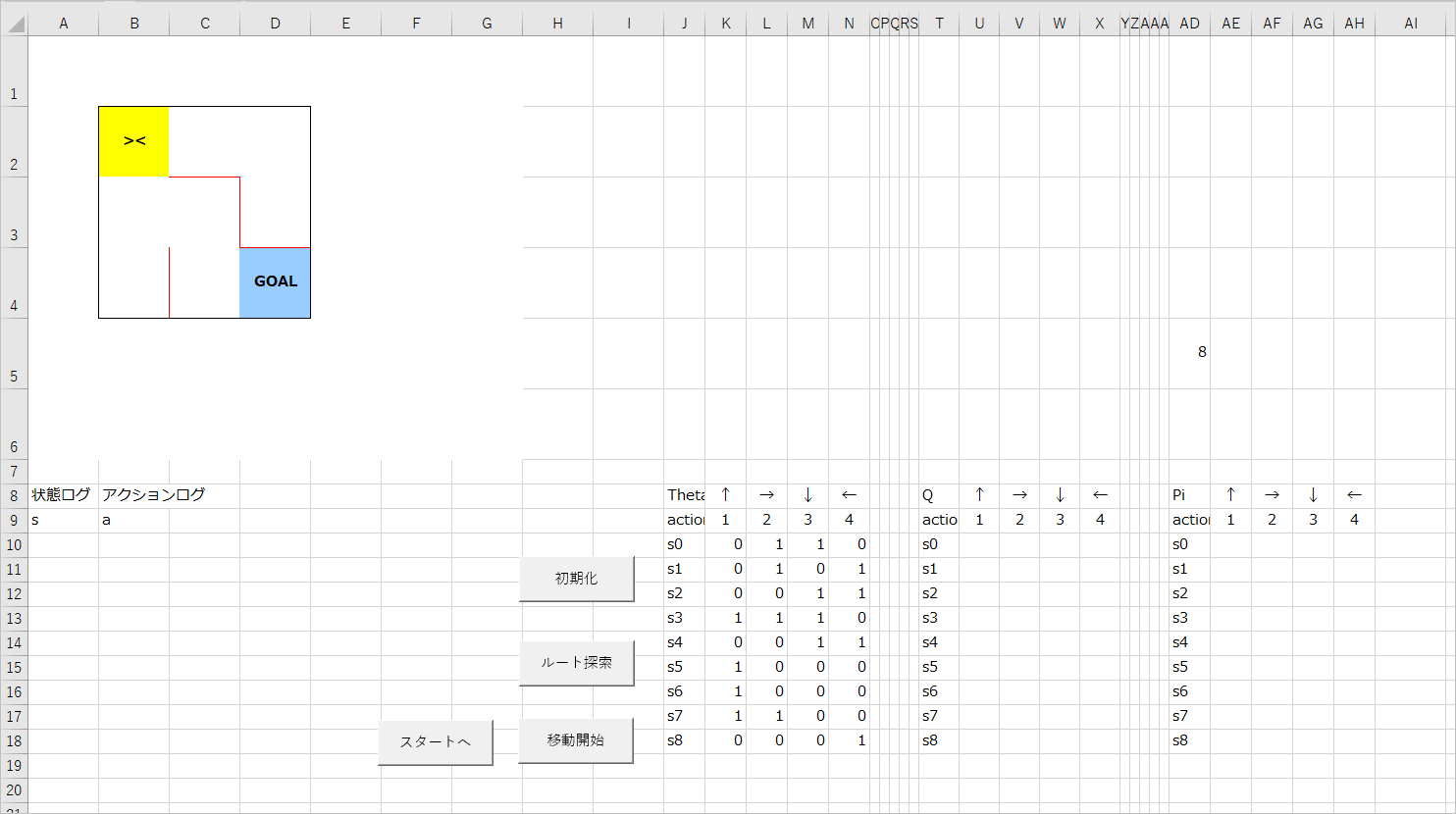
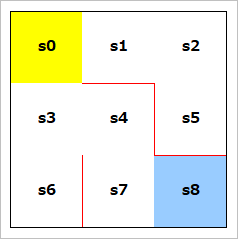
s0 ~ s8 は迷路の各セル(状態)を意味しています。
スタート地点(黄色のセル)が s0(B2セル) で、そこから右に s1(C2セル), s2(D2セル)、次の行に行って s3(B3セル), s4(C3セル), s5(D3セル)…というようになっています。図にするとこんな感じ。
また、各状態にそれぞれ設定されている 1 ~ 4(↑, →, ↓, ←)のセルはその方向への移動が可能かどうかを表しています。
たとえば、s0 の場合、上と左には壁があって移動不可なので 0、右と下は移動可能なので 1 になっています。
AD5のセルに 8 と表示していますが、これはゴールの状態値をメモ代わりに格納しているもので、今後の処理で利用します。
Q学習の実装
「mdlRL」にQ学習を実装していきます。
基本的には Python のコードを VBA で実装しなおす形になります。
Qテーブルの初期化
はじめに Q値 を格納する Qテーブル を初期化します。
具体的には、Theta の値が 0 のものは 0、そうでない場合(1の場合)は ランダムに設定します。
ランダムに設定する理由は、最初の段階では正しい Q値 がわからないためです。
コード自体は特に難しいところはないかと思います。
定数「G.OFFSET_T_Q」は値としては 10 が設定されていて、Theta のセルの列に 10 を足すことで、対応する Qテーブル のセルを指定しています。
'Qテーブルを初期化する
'Theta の値が 0 のときは 0、そうでないときはランダム
Private Sub initializeQ()
Dim r As Long
Dim c As Long
Dim lastR As Long
With wsMain
lastR = .Cells(.Rows.Count, eCL.THETA_).End(xlUp).Row
Randomize
For r = eRW.PARAM_START To lastR
For c = eCL.THETA_UP To eCL.THETA_LEFT
If .Cells(r, c).Value = 0 Then
.Cells(r, c + G.OFFSET_T_Q).Value = 0
Else
.Cells(r, c + G.OFFSET_T_Q).Value = Rnd
End If
Next
Next
End With
End Sub
方策 π(Pi) を計算
こちらも特に難しいところはありません。割合を求めるためにいったん各状態(s)の Theta の合計を求めています。
'Theta から方策 pi を求める
'該当の状態(s)について、各方策(pi)の割合を求める
Private Sub simpleConvertIntoPiFromTheta()
Dim r As Long
Dim c As Long
Dim lastR As Long
Dim sumTheta As Double
With wsMain
lastR = .Cells(.Rows.Count, eCL.THETA_).End(xlUp).Row
For r = eRW.PARAM_START To lastR
sumTheta = 0
For c = eCL.THETA_UP To eCL.THETA_LEFT
sumTheta = sumTheta + .Cells(r, c).Value
Next
For c = eCL.THETA_UP To eCL.THETA_LEFT
.Cells(r, c + G.OFFSET_T_P).Value = .Cells(r, c).Value / sumTheta
Next
Next
End With
End Sub
ε-greedy法の実装
ε-greedy法を実装します。
greedyは調べると「貪欲」を意味しますが、これは Q値 が最大値のものを行動として採用することからきているようです。ただし、行動を決定する元になる Q値 は、最初の段階では正しい値がわからないため、とりあえずランダムに設定しています。そのため、学習の初期段階では、誤った行動をとり続けてしまう可能性があります。そういった状況を避けるため、「一定の確率」で異なる行動をとらせるようにします。「一定の確率」として ε(イプシロン)という値を設定し、行動の選択に若干の不規則性を持たせます。また、学習が進むにつれて、Q値 は正しく更新されていくため、ε の値は徐々に小さくしていきます。
行動を決める
ε-greedy法で行動(a:アクション)を決めます。
ランダムな値を求めて、それが ε(epsilon)よりも小さければランダムに行動を決めて、そうでなければその状態で最も大きな Q値 を持つ行動を選択します。
'ε(epsilon)の確率でランダムに動く
'求めた確率(Rnd)が epsilon 未満 → ランダムに行動する(randomAction())
'求めた確率(Rnd)が epsilon 以上 → Q値が最も高い行動をとる(maxQAction())
Private Function getAction(ByRef s As Long, ByRef epsilon As Double) As Long
Randomize
If Rnd < epsilon Then
getAction = randomAction(s)
Else
getAction = maxQAction(s)
End If
End Function
np.random.choice()の実装
ランダムに求めた値が ε より小さければ不規則な行動をとるようにします。そのため、numpy の random.choice() (と同じような感じの機能)を実装します。ここでは、方策 pi の比率(確率)をもとにランダムに行動(a)を決定しています。そのため、与えられた確率のリストに従って、ランダムに選択するような処理を実現する必要があります。今回は次のようなロジックで近似しています。
randomAction():
・ 各 pi について、以下を100回試行する
・ ランダム(Rnd)で求めた値が、該当の pi の値(確率)よりも小さければカウント
・ getMaxCoutAction() で求めた行動(a)を採用
getMaxCountAction():
・ カウントの値が最も大きい pi の行動(a)を求める
・ ただし、カウントの最大値をとる pi が複数あった場合は、再度 randomAction() を実行する
'np.random.choice()の実装
'方策 pi の割合をもとにした確率により行動を決定する
Private Function randomAction(ByRef s As Long) As Long
Dim a As Long
Dim c As Long
Dim i As Long
Dim ratio As Double
Dim count As Long
With wsMain
Do
For c = eCL.PI_UP To eCL.PI_LEFT
ratio = .Cells(eRW.PARAM_START + s, c).Value
If ratio = 0 Then
.Cells(eRW.PARAM_RANDOM_POINT, c).Value = 0
Else
count = 0
Randomize
For i = 1 To 100
If Rnd < ratio Then
count = count + 1
End If
Next
.Cells(eRW.PARAM_RANDOM_POINT, c).Value = count
End If
Next
a = getMaxCountAction
Loop While a = 0
End With
randomAction = a
End Function
'もっとも多くのカウント数を獲得した行動を求める
'最大カウント数の行動(a)がダブった場合は 0 を戻して再度 randomAction() を実行させる
Private Function getMaxCountAction() As Long
Dim c As Long
Dim a As Long
Dim count As Long
Dim maxCount As Long
With wsMain
a = 1
maxCount = .Cells(eRW.PARAM_RANDOM_POINT, eCL.PI_UP).Value
For c = eCL.PI_RIGHT To eCL.PI_LEFT
If maxCount < .Cells(eRW.PARAM_RANDOM_POINT, c).Value Then
a = c - eCL.PI_
maxCount = .Cells(eRW.PARAM_RANDOM_POINT, c).Value
End If
Next
count = 0
For c = eCL.PI_UP To eCL.PI_LEFT
If .Cells(eRW.PARAM_RANDOM_POINT, c).Value = maxCount Then
count = count + 1
End If
Next
If count = 1 Then
getMaxCountAction = a
Else
getMaxCountAction = 0
End If
End With
End Function
Qの最大値の行動をとる
ランダムに求めた値が ε 以上なら、その状態(s)で最大となる Q値 を持つ行動(a)を選択します。
'Q値の最も大きな行動を選択する
Private Function maxQAction(ByRef s As Long) As Long
Dim a As Long
Dim c As Long
Dim q As Double
With wsMain
q = .Cells(eRW.PARAM_START + s, eCL.Q_UP).Value
a = 1
For c = eCL.Q_RIGHT To eCL.Q_LEFT
If q < .Cells(eRW.PARAM_START + s, c).Value Then
q = .Cells(eRW.PARAM_START + s, c).Value
a = c - eCL.Q_
End If
Next
End With
maxQAction = a
End Function
行動から次の状態を求める
現在の状態(s)から行動(a)をとったら、次の状態(s_next)はどうなるか?を求めます。
例えば、現在 s1 にいて、行動 right(右に行く) をとった場合、s2 に移動するため、次の状態は s + 1 となります。
逆に、left(左に行く)とした場合は、次の状態は s0 になります。コードでも、s - 1 としています。
up, down についても、その行動を取ったらどの状態(s)になるかを計算しています。
'行動から次の状態を求める
Private Function getSNext(ByRef s As Long, ByRef a As Long) As Long
Select Case a
Case eAction.UP_
getSNext = s - (G.pClMazeEnd - eCL.MAZE_START + 1)
Case eAction.RIGHT_
getSNext = s + 1
Case eAction.DOWN_
getSNext = s + (G.pClMazeEnd - eCL.MAZE_START + 1)
Case eAction.LEFT_
getSNext = s - 1
End Select
End Function
Q値の更新式
Q値の更新式は以下のようにあらわされます。
Q(s_t, a_t) = Q(s_t, a_t) + \eta * (R_{t+1} + (\gamma * maxQ(s_{t+1}, a)) - Q(s_t, a_t))
この式を実装します。
この式で、$Q(s_t, a_t)$ はその状態(s)で行動(a)をとったときの Q値、$R$ は報酬、$maxQ(s_{t+1}, a)$ は次の状態(s)での最大の Q値 を意味します。
$Q(s_t, a_t)$ が何度も出てくるので、初めに変数 qsa に値を代入しています。コード的には Qテーブル から該当の Q値 を取得しているだけです。
$maxQ(s_{t+1}, a)$ は「maxQ」プロシージャで Qテーブルから該当の(最大の)Q値 を調べて取得しています。
そのほか、
$\eta$ は学習率、$\gamma$ は割引率と呼ばれるハイパーパラメータです。
'Q値を更新する
Private Function QLearning(ByRef s As Long, ByRef a As Long, ByRef reward As Long, _
ByRef sNext As Long, ByRef eta As Double, ByRef gamma As Double) As Double
Dim qsa As Double
Dim endS As Long
With wsMain
'ゴールの状態(s)を取得
endS = .Range(G.AD_END_S).Value
'Q(s, a)の値を取得しておく
qsa = .Cells(eRW.PARAM_START + s, eCL.Q_ + a).Value
If sNext = endS Then
qsa = qsa + (eta * (reward - qsa))
Else
qsa = qsa + eta * (reward + (gamma * maxQ(sNext)) - qsa)
End If
End With
QLearning = qsa
End Function
'その状態の最大の Q値 を求める
Private Function maxQ(ByRef s As Long) As Double
Dim c As Long
Dim q As Double
With wsMain
q = .Cells(eRW.PARAM_START + s, eCL.Q_UP).Value
For c = eCL.Q_RIGHT To eCL.Q_LEFT
If q < .Cells(eRW.PARAM_START + s, c).Value Then
q = .Cells(eRW.PARAM_START + s, c).Value
End If
Next
End With
maxQ = q
End Function
迷路を解くロジック
Q値を更新しながら迷路を解いていきます。ゴールに到達したらループを抜けます。少し長いですが、実際のところは Q値 を更新する「QLearning」プロシージャの引数となる値を求めるのとログ出力に費やされています。
'迷路を解く
Private Function goalMazeRetSAQ(ByRef epsilon As Double, ByRef eta As Double, ByRef gamma As Double) As Long
Dim s As Long '状態 s
Dim sNext As Long '次の状態 s_next
Dim a As Long '行動 a
Dim aNext As Long '次の行動 a_next
Dim reward As Long '報酬
Dim logR As Long 'ログ用の行カウンタ
Dim endS As Long 'ゴール状態のsの値
Dim stepCount As Long 'ステップ数
s = 0
'最初の行動(a)を決める
a = getAction(s, epsilon)
aNext = a
'行カウンタに初期値をセット
logR = eRW.LOG_START
With wsMain
'状態ログ、アクションログをクリア
Call ClearLog
'ゴールの状態 s の値を取得する
endS = .Range(G.AD_END_S).Value
'状態(s)をログ出力
.Cells(logR, eCL.LOG_S).Value = s
stepCount = 0
Do
a = aNext
'行動(a)をログ出力
.Cells(logR, eCL.LOG_A).Value = a
logR = logR + 1
'現在の状態(s)で行動(a)をとった場合の次の状態を求める
sNext = getSNext(s, a)
'状態(s)をログ出力
.Cells(logR, eCL.LOG_S).Value = sNext
'次の移動でゴールに到達すれば報酬を与える
'そうでなければ次の状態(s_next)から次の行動(a_next)を決める(報酬は0)
If sNext = endS Then
reward = 1
Else
reward = 0
aNext = getAction(sNext, epsilon)
End If
'Q値を更新
.Cells(eRW.PARAM_START + s, eCL.Q_ + a).Value = QLearning(s, a, reward, sNext, eta, gamma)
'次の移動でゴールに到達したらループを抜ける
'そうでなければ次の状態に移動
If sNext = endS Then
Exit Do
Else
s = sNext
stepCount = stepCount + 1
End If
Loop
End With
'かかったステップ数を戻す
goalMazeRetSAQ = stepCount
End Function
探索学習処理
効率的に迷路が解けるようになるまで繰り返します。書籍では100回繰り返す処理になっていますが、ここでは、ゴールまでのステップ数が10回連続で同じになったら学習終了と判断してループを抜けるようにしています。(10回という回数は、同じステップ数で連続10回ゴールに到達していれば、同じルートをたどっている = 学習が終了している と判断してもいいんじゃないか?という理屈によって、適当に決めた回数です。)
また、エージェントが迷路を解いている様子を見たい場合は「エージェントを動かす」部分のコメントを外します。ただし、当然ながら処理速度は遅くなります。
「MoveAgent」プロシージャはこの後で実装します。
Public Sub Click_StartSearch()
Dim eta As Double '学習率
Dim gamma As Double '割引率
Dim epsilon As Double 'ε(イプシロン)
Dim episode As Long 'エピソード数(ゴールまで到達した回数)
Dim lastStepCount As Long 'ステップ数(前回分)(ゴール到達までに行動した回数)
Dim newStepCount As Long 'ステップ数(今回分)
Dim stepCountHistory As Long 'ステップ数の履歴
Dim maxContinuous As Long '同じステップ数の最大連続数
'ハイパーパラメータの設定
eta = 0.1
gamma = 0.9
epsilon = 0.5
'初期化
episode = 1
lastStepCount = 0
stepCountHistory = 0
maxContinuous = 10
'Qテーブルを初期化
Call initializeQ
'Theta を pi に変換
Call simpleConvertIntoPiFromTheta
'ゴール到達までのステップ数が10回連続で同じになるまで繰り返す
Do
Application.StatusBar = "episode:" & episode
'迷路を解く
newStepCount = goalMazeRetSAQ(epsilon, eta, gamma)
'------------
' エージェントを動かす (迷路を解いている様子を見たい場合はコメントを外す)
' Application.Wait Now + TimeValue("0:00:01")
' Call MoveAgent(episode)
' Call ResetMaze
'------------
'前回のステップ数と今回のステップ数が同じ場合は履歴をカウントアップ
'そうでない場合は、今回のステップ数を前回のステップ数として設定
If lastStepCount = newStepCount Then
stepCountHistory = stepCountHistory + 1
'同じステップ数が10回続いた場合は学習終了と判断してループを抜ける
If stepCountHistory >= maxContinuous Then
Exit Do
End If
Else
stepCountHistory = 0
lastStepCount = newStepCount
End If
'学習の進みに応じてランダムな要素を少なくしていくため、ε を小さくする
epsilon = epsilon / 2
episode = episode + 1
Loop
MsgBox "探索が終了しました。"
Application.StatusBar = False
End Sub
探索動作確認
「Click_StartSearch」プロシージャを【ルート探索】ボタンに登録して動作確認をしてみましょう。
「MoveAgent」はまだ実装していないので、「エージェントを動かす」部分はコメントアウトしたままにしておきます。
【初期化】ボタンを押して初期化したのち、【ルート探索】ボタンを押します。
このような結果になればOKです。(Qテーブルの値は異なります。)
ログの確認
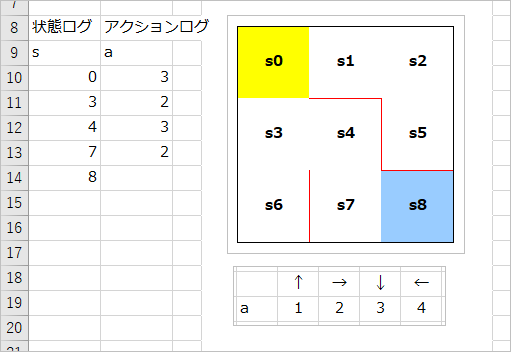
ちゃんとゴールまで到達しているか確認してみましょう。
状態 s の初めは 0 なので s0 つまりエージェントはスタート(黄色のセル)にいます。
そこで行動(アクション)a として 3 をとっています。3 は下への移動なので、下に移動すると次の状態(位置)は s3(11行目) になります。
s3 でのアクションは 2 なので右に移動すると、状態(位置)は s4 に、s4 でのアクションは 3 なので下に移動すると s7、s7 でのアクションは 2 なので、右に移動すると無事にゴールに到達しました。
ここまでで Q学習の実装は終わりです。
エージェントの移動処理を実装
エージェントの移動処理を実装します。コードは「mdlMove」モジュールに記述します。
エージェントの移動
ログをもとにエージェントを移動させます。他のモジュールからも呼び出されるため、Public にしています。
呼び出し元によって Wait の値を変えるようにしています。
【移動開始】ボタンから呼び出されたときは Wait を 1秒 にしていますが、【ルート探索】から呼び出されたときは、ステップ数に応じて、1ミリ秒 もしくは 4ミリ秒 になるようにしています。
'エージェントを移動させる
'引数の episode はステータスバー表示および呼び出し元の判断で使用
Public Sub MoveAgent(Optional ByRef episode As Long = 0)
Dim r As Long '行カウンタ
Dim c As Long '列カウンタ
Dim logR As Long 'ログ用行カウンタ
Dim lastR As Long 'ログの最終行
Dim stepCount As Long 'ステップ数
Dim a As Long '行動
r = eRW.MAZE_START
c = eCL.MAZE_START
With wsMain
lastR = .Cells(.Rows.count, eCL.LOG_A).End(xlUp).Row
stepCount = lastR - eRW.LOG_START + 1
For logR = eRW.LOG_START To lastR
If episode = 0 Then
Application.Wait Now + TimeValue("0:00:01")
Else
'ステップ数によってWait時間を変える
If stepCount > 10 Then
Application.Wait [Now() + "0:00:00.1"]
Else
Application.Wait [Now() + "0:00:00.4"]
End If
End If
.Cells(r, c).Value = ""
a = .Cells(logR, eCL.LOG_A).Value
Select Case a
Case eAction.UP_
r = r - 1
Case eAction.RIGHT_
c = c + 1
Case eAction.DOWN_
r = r + 1
Case eAction.LEFT_
c = c - 1
End Select
DoEvents
.Cells(r, c).Value = G.AGENT
Application.StatusBar = "episode:" & episode & " / " & logR - eRW.LOG_START + 1 & "/" & stepCount
Next
End With
Application.StatusBar = False
End Sub
移動開始
先ほど書いた「MoveAgent」を呼び出すプロシージャを作成して、【移動開始】ボタンに登録します。
「MoveAgent」プロシージャの引数はオプションにしてあるため、ここでは引数として(episodeを)渡す必要はありません。
Public Sub Click_Move()
Call MoveAgent
MsgBox "GOAL!!"
End Sub
スタートに戻る
エージェントをスタートに戻します。「ResetMaze」を呼び出しているだけです。【スタートへ】ボタンに登録します。
Public Sub Click_GoBackStart()
Call ResetMaze
End Sub
完成
お疲れさまでした。
いろいろな迷路を作って試してみましょう。
感想
エージェントの探索過程を見てみると、初めのうちは非常に非効率というよりほとんど適当に動いて「たまたまゴールに到達する」ということを繰り返しています。このくらいの大きさの迷路であれば「たまたまゴールに到達する」可能性は比較的高いですが、少し複雑になるとゴールに到達できるとは到底思えません。(時間をかければそのうち到達するかもしれませんが…)。何か別の方策を導入する必要がありそうですね。
おまけ
Sarsaの実装
Q学習の代わりに Sarsa を実装したい場合は、以下のコードを実装します。
Private Function Sarsa(ByRef s As Long, ByRef a As Long, ByRef reward As Long, _
ByRef sNext As Long, ByRef aNext As Long, ByRef eta As Double, ByRef gamma As Double) As Double
Dim qsa As Double
Dim qsaNext As Double
Dim endS As Long
With wsMain
endS = .Range(G.AD_END_S).Value
qsa = .Cells(eRW.PARAM_START + s, eCL.Q_ + a).Value
If sNext = endS Then
qsa = qsa + (eta * (reward - qsa))
Else
qsaNext = .Cells(eRW.PARAM_START + sNext, eCL.Q_ + aNext).Value
qsa = qsa + eta * (reward + (gamma * qsaNext) - qsa)
End If
End With
Sarsa = qsa
End Function
また「goalMazeRetSAQ」プロシージャで「QLearning」を呼び出しているところを「Sarsa」に変更すればOKです。
ただし、引数が一部異なることに注意してください。
Sarsa の場合は、Q学習 に比べて引数に aNext が余分に必要です。aNext は「getAction」で決定される行動で、「getAction」では、ε-greedy法で行動を決定しているため、若干の不規則性があります。そのため、Q学習 の方が Sarsa よりも収束が早いという特徴があるようです。
'Q値を更新
'.Cells(eRW.PARAM_START + s, eCL.Q_ + a).Value = QLearning(s, a, reward, sNext, eta, gamma)
.Cells(eRW.PARAM_START + s, eCL.Q_ + a).Value = Sarsa(s, a, reward, sNext, aNext, eta, gamma)