はじめに
機械学習初心者ながら、UTH-BERTを用いた自然言語処理(NLP)のタスクが指導教員から降ってきたので試行錯誤しております。
BERTで不均衡なデータセット(全体のうち正例が0.6%)で文章の2値分類をしており、そのままunder samplingしたら性能はすこぶるいいけど、そのままぶっこんで回したら正例がまったく当たらない(当たり前、損失関数はそう動く)。
それでも負例の情報量をばっさり切り捨てるのは如何なものかと悶々としてたら、指導教員から「under sampling + bagging」がいいみたい、と言う天の声が…実装するしかないでしょ。
[1] UTH-BERTをTensorflow2.X / Keras BERT から利用して文書分類を行う
[2] itokashi: 不均衡データ分類問題をDNNで解くときの under sampling + bagging 的なアプローチ
[3] Yilin Yan et al.: Deep Learning for Imbalanced Multimedia Data Classification
なので、先行の記事がpytorchベースであったため、kerasのジェネレータで同じような動きになるよう作ってみた。
NLPってHugging Faceの影響なのかpytorchのコードが多くって、画像処理でkerasに慣れてるぶん困る。
引用文献より実装するイメージ
-
ミニバッチでunder samplingするアプローチ[2]
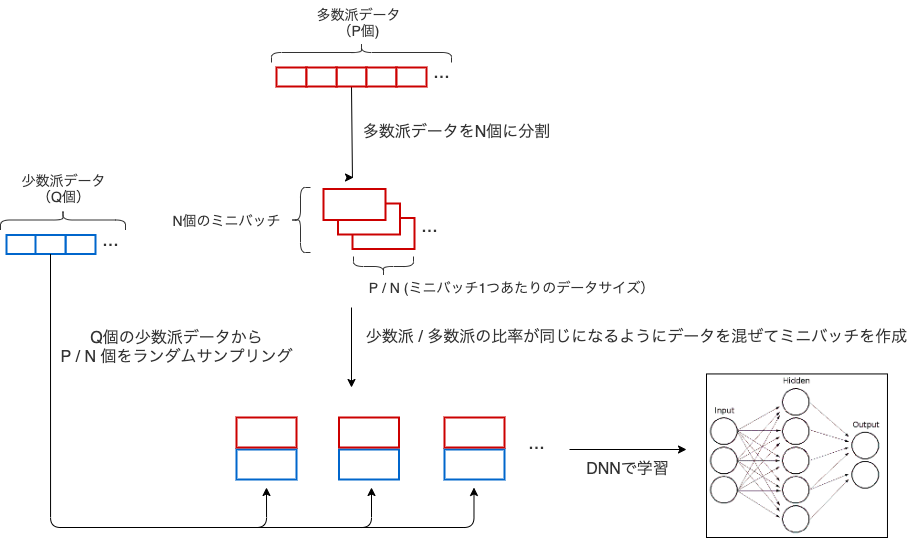
-
pytorchの実装例が以下[2]
多数派データと少数派データのインデックスを抽出して、少数派を多数派に合わせて同じ数だけランダムに選出してミニバッチを作成。
class BinaryBalancedSampler:
def __init__(self, features, labels, n_samples):
self.features = features
self.labels = labels
label_counts = np.bincount(labels)
major_label = label_counts.argmax()
minor_label = label_counts.argmin()
self.major_indices = np.where(labels == major_label)[0]
self.minor_indices = np.where(labels == minor_label)[0]
np.random.shuffle(self.major_indices)
np.random.shuffle(self.minor_indices)
self.used_indices = 0
self.count = 0
self.n_samples = n_samples
self.batch_size = self.n_samples * 2
def __iter__(self):
self.count = 0
while self.count + self.batch_size < len(self.major_indices):
# 多数派データ(major_indices)からは順番に選び出し
# 少数派データ(minor_indices)からはランダムに選び出す操作を繰り返す
indices = self.major_indices[self.used_indices:self.used_indices + self.n_samples].tolist()\
+ np.random.choice(self.minor_indices, self.n_samples, replace=False).tolist()
yield torch.tensor(self.features[indices]), torch.tensor(self.labels[indices])
self.used_indices += self.n_samples
self.count += self.n_samples * 2
これをkerasに移植します。
ここで問題となるのが、
- BERTの分類問題は特徴量にfeatureとsegmentが必要
- steps per epochが必要
って2点。
ジェネレータの実装
def BinaryBalancedSampler(features, labels, n_samples):
label_counts = np.bincount(labels.T)
major_label = label_counts.argmax()
minor_label = label_counts.argmin()
major_indices = np.where(labels.T == major_label)[0]
minor_indices = np.where(labels.T == minor_label)[0]
np.random.shuffle(major_indices)
np.random.shuffle(minor_indices)
used_indices = 0
count = 0
# BERTのinput(feature, segment)をconcatして3D->2D
features_ = np.concatenate([features, np.zeros_like(features)], 1)
while True :
# 多数派データ(major_indices)からは順番に選び出し
# 少数派データ(minor_indices)からはランダムに選び出す操作を繰り返す
indices = major_indices[used_indices:used_indices + n_samples].tolist() + np.random.choice(minor_indices, n_samples, replace=False).tolist()
# バランス後、concatしていたfeature, segmentを縦割りに成形
X = np.hsplit(features_[indices], 2)
y = (labels.T)[indices].reshape(-1, 1)
used_indices += n_samples
count += n_samples * 2
# 最後まで切り出したらリセットして最初のインデックスに戻して対応
if count > len(major_indices):
count = 0
used_indices = 0
yield X, y
スマートでは無いですが、入力したfeatureと、作ったsegmentをconcatして、while構文以下でミニバッチを作らせる。
features_ = np.concatenate([features, np.zeros_like(features)], 1)
ミニバッチ作成後に2分割してfeatureとsegmentに分け分け(力技)。
X = np.hsplit(features_[indices], 2)
ジェネレータで増殖する場合のために、繰り返せるようにリセット。
# 最後まで切り出したらリセットして最初のインデックスに戻して対応
if count > len(major_indices):
count = 0
used_indices = 0
ジェネレータの設定は以下。train用とvalidation用。
ジェネレータ内で、負例に合わせて正例が同数増えるので、欲しいバッチサイズの半分にしてn_samplesに渡す。
# bagging
training_generator = BinaryBalancedSampler(features=X_train, labels=y_train, n_samples=BATCH_SIZE // 2)
val_training_generator = BinaryBalancedSampler(features=X_valid, labels=y_valid, n_samples=BATCH_SIZE // 2)
といった具合に、初心者の私には良いのか悪いのか判断しかねるコードで動かしてみた。
steps per epoch
次にsteps per epochの設定が以下。kerasはどこまでジェネレータを回すのか分かんないので明示する必要がある。
とりあえず負例1周分のバッチを作るように書いてみた。
steps_per_epoch = max(np.bincount((y_train.T))) // BATCH_SIZE
max(np.bincount(y_train.T))で増殖させる基準となる負例の数を算出し、バッチサイズで除す。これで1周ぶんのはず。
ってな感じで以下で回す。
history = model.fit_generator(
generator = training_generator,
steps_per_epoch = max(np.bincount(y_train.T)) // BATCH_SIZE,
validation_data= val_training_generator,
validation_steps= max(np.bincount(y_valid.T)) // BATCH_SIZE,
epochs=EPOCHS,
verbose=1,
shuffle=True,
callbacks = [
EarlyStopping(patience=5, monitor='val_loss', mode='min'),
ModelCheckpoint(monitor='val_loss', mode='min', filepath=train_model_checkpoint_path, save_best_only=True, verbose=1)
])
負例を増やしながら回してますが、baggingのおかげで性能が落ちることなく結果が出ている模様。
そもそも正例:負例 = 1:1でサチってるから、baggingなしでどんだけ落ちるか検証しないと…
ともあれ慣れないジェネレータが動いて良かった。プログラミングは初心者なので、今後はclassを自作できるようにしないと、です。