はじめに
前回(XinferenceにhuggingfaceからRuriシリーズのモデルを登録)の続き
EmbeddingとRerankはXinferenceからlaunchできたが、LLMはOllamaから動かしているので、LLMもXinferenceに移植したい。
JSONの準備
前回と同様に、Web UIからはhuggingface経由でダウンロードできないのでJSONで設定ファイルを書いて登録させます。
cyberagent製のQwen2に蒸留したDeepseek-R1モデルと、これをGGUFに変換したモデルを書きました。
{
"version": 1,
"context_length": 131072,
"model_type": "LLM",
"model_name": "cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese",
"model_lang": [
"ja"
],
"model_ability": [
"chat"
],
"model_description": "This is a Japanese finetuned model based on DeepSeek-R1-Distill-Qwen-32B.",
"model_family": "DeepSeek-R1-Distill-Qwen-32B-Japanese",
"model_specs": [
{
"model_format": "pytorch",
"model_size_in_billions": 32,
"quantizations": [
"4-bit",
"8-bit",
"none"
],
"model_id": "cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese",
"model_hub": "huggingface"
},
{
"model_format": "ggufv2",
"model_size_in_billions": 32,
"quantizations": [
"IQ1_S",
"IQ1_M",
"IQ2_XXS",
"IQ2_XS",
"IQ2_SQ2_K",
"IQ3_XXS",
"IQ3_S",
"Q3_K_S",
"Q3_K_M",
"Q3_K_L",
"IQ4_XS",
"Q4_K_S",
"IQ4_NL",
"Q4_0",
"Q4_K_M",
"Q5_K_S",
"Q5_0",
"Q5_K_M",
"Q6_K",
"Q8_0"
],
"model_id": "mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf",
"model_file_name_template": "cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-{quantization}.gguf",
"model_hub": "huggingface"
}
],
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}",
"stop_token_ids": [
151643
],
"stop": [
"<|end▁of▁sentence|>"
]
}
"model_specs"に2種類のモデルを書き込んでます。
起動まで
コンテナにコピーして登録します。
docker cp cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese.json xinference:/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese.json
docker exec -it xinference xinference register --model-type LLM --file /cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese.json --persist
起動させます。
docker exec -it xinference xinference launch -n cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese -t LLM -en Transformers -f pytorch -q 8-bit
エンジンはTransformersでpytorchのフォーマット、そして8-bit版。
コマンド打ったら、Model UIDが返ってきます。指定していなかったら、起動したモデル名がUIDとなるはずです。
Web UIで確認してみる。
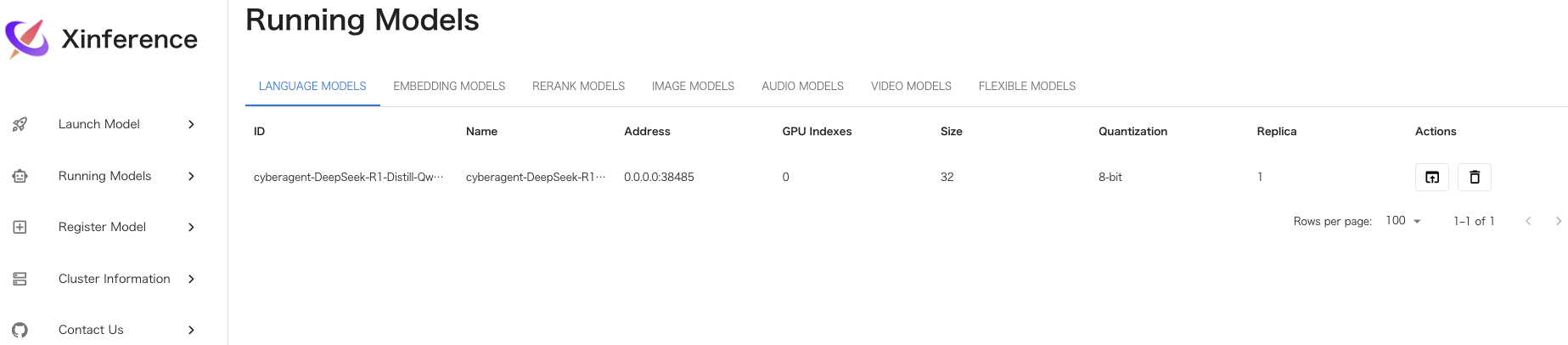
cyberagentのpytorch版はlaunchできるが、gguf版はエラーがでる(汗)
デフォルトで用意されている他のモデルもggufはエラー、以下のエラーメッセージのパスには実体もあるのになぜ?
Server error: 400 - [address=0.0.0.0:39237, pid=2074] Failed to load model from file: /root/.cache/huggingface/hub/models--mmnga--cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf/blobs/7176e8eb29afda0768fb22cbb6a1227348a1a85ee800356cebaff18fb22a7437
Difyと接続
前回と同じくモデルプロバイダから登録
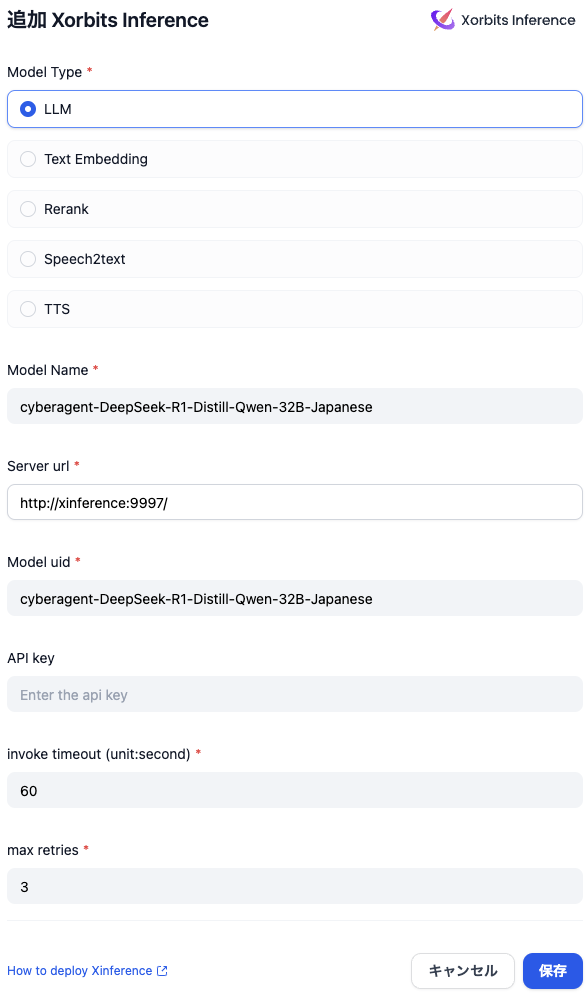
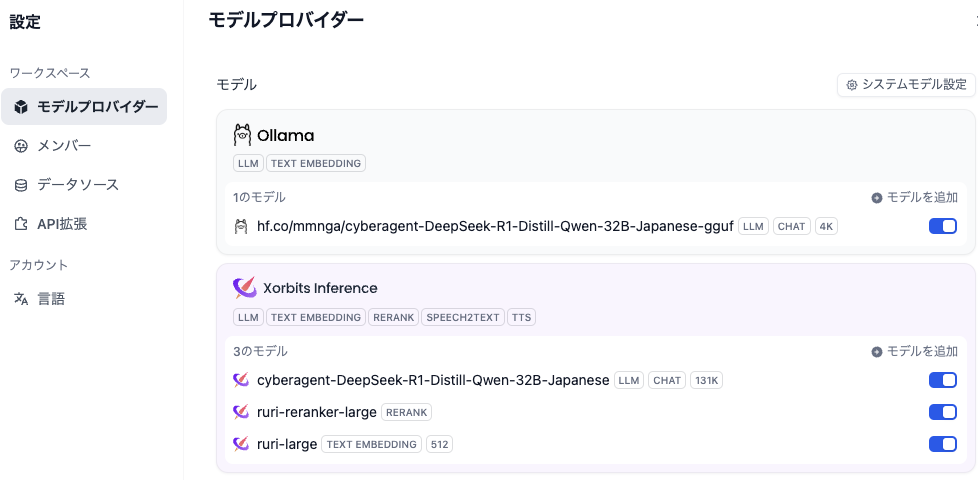
Ollamaもありますが、Xorbits Inferenceにも登録完了。
使用感
VRAM
Ollamaは推論時のみVRAMを消費していたが、XinferenceはlaunchさせるとVRAMをずーっと占有してしまう。
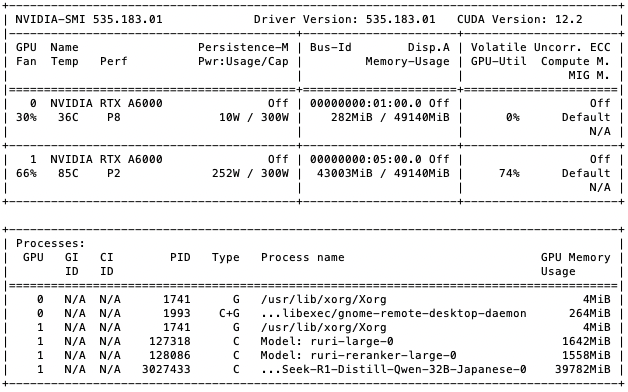
スクショはナレッジデータベースをQ&A形式で推論しながら作っている所で、1番GPUに集約すると37〜44GBをウロウロしています。
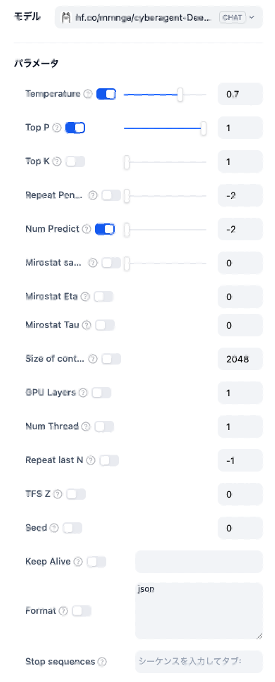
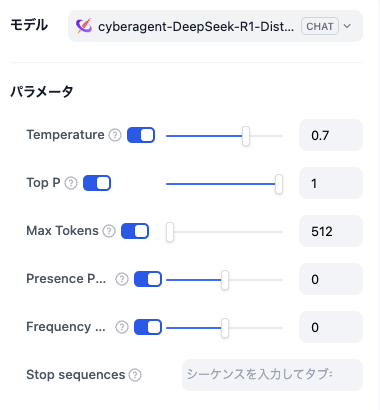
推論の設定
Xinferenceは渡せる引数が少ないぞ;
Xinferenceはlaunchして起動し続ける動きなので、launch時にあらかじめ設定か。
ollamaは調整が簡単。
終わりに
ollamaの方が賢い挙動な印象。Xinferenceと併用して利用しようと思います。
おまけ
クローラーを無課金で構築するなら、Firecrawlで可能です。
次のサイトの通りにすれば可能なので参照してください。