はじめに
みなさん、こんにちは。今回は私が関わる東芝のソフトウェア開発効率化のための生成AI活用の取り組みについてお話しします。
まず、東芝でのソフトウェア開発効率化のための生成AI活用の全体像をお話しします。
特に私が取り組んだ、生成AIを利用した単体テストコード生成方法について、簡単なコードで試行してみた結果をご紹介したいと思います。
ソフトウェア開発効率化のための生成AI活用の取り組み
東芝グループでは、事業活用・スタッフ業務効率化・設計効率化など、生成AI活用について様々な取り組みを進めています。
その中で、ソフトウェア開発業務の効率化に向けては、大量の既存ソフトウェア資産の活用を重要な課題として取り組んでいます。
現状は、ソフトウェア開発全般の様々な作業について試行と評価を大量に実施し、有用な活用方法をベストプラクティスとして整理しています。
最終的に生成AIを用いたソフトウェア開発効率化の技術(以下、生成AI活用技術)として開発するための試行と評価のステップは、以下の通りです。
- 【仮説構築】現状資産と課題の把握と生成AI活用の構成検討により実施可能を確認する
- 【仮説実装】具体的なモチーフに対して生成AI活用方法を工夫し期待した結果が得られるよう実装する
- 【仮説検証】類似のモチーフに対して同じ生成AI活用方法で期待した結果が得られるか検証する
- 【実地評価】実際の開発プロジェクトで生成AI活用方法を適用し効果を計測して評価する

このように、モチーフに対して有効な生成AI活用方法を検討し、大量のソフトウェア資産への活用展開と業務自動化を志向しています。
また、以下の図のようにソフトウェア開発工程と対応づけて生成AI活用技術を開発しています。特に、オレンジの枠で囲まれた各生成AI活用技術は、重点対象領域として取り組んでいます。各生成AI活用技術のブロックの背景色は、2024年12月現在の開発ステップとの対応づけを示しています。
例えば、「設計書生成・修正・補完」は実地評価ステップを行っており、「ソースコード生成・修正・補完」は仮説実装~仮説検証ステップを行っています。
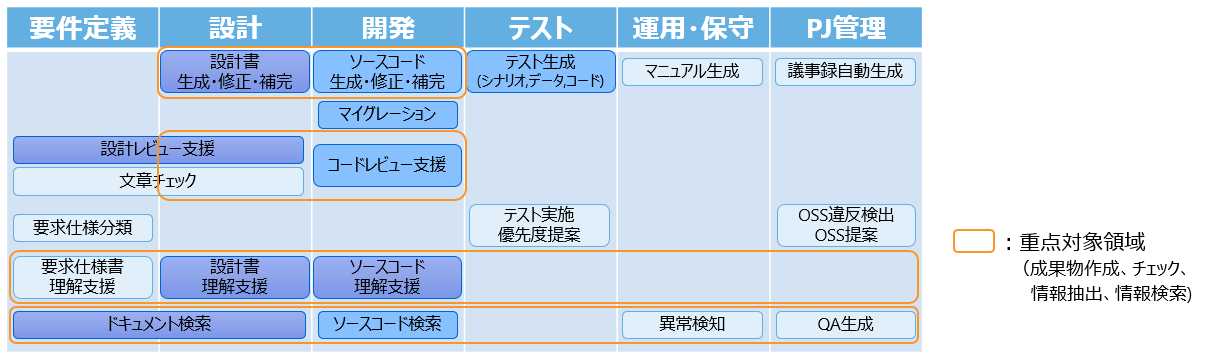
さらに、以下の表ではソフトウェア開発工程ごとの作業に対して実施した生成AI活用の試行の例を示しています。
これらの試行で利用した生成AIは、主にAzure OpenAIのAPIやGitHub Copilotです。

ソフトウェア開発効率化のための生成AI活用の試行例
上記の表から、いくつかの生成AI活用の試行について簡単にご紹介します。
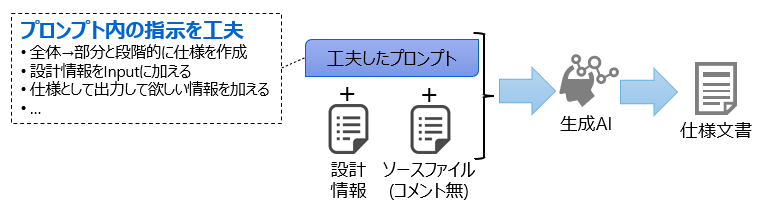
「ソースコードから仕様書を生成する」
- 【目的】
- ブラックボックス化したソースコードを修正、改造したい場合に、ソースコードから仕様書を生成することで、ソースコードの理解を助けること
- 【方法】
- 設計情報やソースコードを付加したプロンプトを入力に、プログラム全体および各モジュールの仕様文書を生成
- 【工夫】
- 全体から部分と段階的に仕様を作成するなど、プロンプト内の指示を工夫すること
- 【試行結果】
- ソースファイル作成者がほぼ正しい内容であることを確認でき、人手での作成時間と生成結果の確認時間を比較すると約80%の作業時間を削減
「ソースコードから単体テストコードを生成する」
- 【目的】
- テストケースおよびテストコード作成にかかる工数を低減し、自動テストの実施率を高めて、リリース後の不具合発生を減少すること
- 【方法】
- ソースコードや仕様書を入力として、テストケースおよびテストコードを生成すること
- 【工夫】
- 複数の情報源を利用してプロンプト内の指示を工夫して、まずテストケースを生成し、テストケースを整理してからテストコードを生成すること
- 【試行結果】
- 生成されたテストコードの分岐網羅率は平均91%、人手でのテストコード作成見積もり時間と比べて66.7%の作業時間削減

生成AIを利用した単体テストコード生成の試行
今回は、上記で紹介した「ソースコードから単体テストコードを生成する」について、簡単なコードを試行してみた結果をご紹介します。
今回の試行ではGitHub Copilot Chatを利用して、テスト対象のPythonのソースコードから単体テストコードを生成してみました。
まず、定型化されたプロンプトを利用して、テストケースを生成し、整理、修正を行います。
次に、GitHub Copilot Chatの機能である/testsというスラッシュコマンドや定型化されたプロンプトを利用して、テスト対象向けに指示を工夫してテストコードを生成しました。
最後に、生成されたテストコードを実行してみた結果を共有します。
テスト対象のコードについて
テスト対象のコードは、指定されたディレクトリ内のPDFファイルを処理し、特定のページから指定された領域を切り抜いて画像として保存する処理を行います。
私の子どものPTA活動での広報資料作成にて、大量のPDFファイルから画像を切り抜く必要があったため、この処理を自動化するプログラムを作成しました。
このプログラムのほとんどは生成AIが生成していて、最初にプロンプトで指示してスケルトンコードを生成してもらった後、少しずつコードを補完しながら手直ししたものです。
○○のプログラムを実装したい、と思いついたことを生成AIで簡単に実現できるようになり、本当に便利になりました。
----------------------------------------
テスト対象のコードを表示(折りたたみ)
------------------------------------------
import os
import glob
from PyPDF2 import PdfFileReader
from pdf2image import convert_from_path
from PIL import Image
def crop_image_from_pdf(pdf_path, page_number, x, y, width, height, dpi, output_path):
try:
# PDFを画像に変換
images = convert_from_path(pdf_path, dpi=dpi, first_page=page_number, last_page=page_number)
if not images:
raise ValueError("指定したページが見つかりません")
# 画像を切り抜き
image = images[0]
cropped_image = image.crop((x, y, x + width, y + height))
# 切り抜いた画像を保存
cropped_image.save(output_path)
except Exception as e:
print(f"エラーが発生しました: {e}")
def process_pdfs(pdf_dir, out_dir, page_number, x, y, width, height, dpi):
try:
if not os.path.exists(pdf_dir):
raise FileNotFoundError(f"指定されたディレクトリが見つかりません: {pdf_dir}")
if not os.path.exists(out_dir):
os.makedirs(out_dir)
for pdf_path in glob.glob(pdf_dir + '*.pdf'):
filename, ext = os.path.splitext(os.path.basename(pdf_path))
out_path = os.path.join(out_dir, filename + '.png')
print('Processing: {}'.format(pdf_path))
crop_image_from_pdf(pdf_path, page_number, x, y, width, height, dpi, out_path)
except Exception as e:
print(f"エラーが発生しました: {e}")
テストケースおよびテストコード生成の試行結果
上記のテスト対象のPythonコードに対して、GitHub Copilot Chatが生成したテストケースの例は以下の通りです。
テストケースNo.1
- テストケースの概要: 正常系 - 有効なPDFディレクトリと出力ディレクトリが存在する場合のテスト
- 事前条件:
pdf_dirに有効なPDFファイルが含まれているディレクトリパスを指定するout_dirに有効なディレクトリパスを指定するpage_numberに有効なページ番号(例: 1)を指定するx,y,width,heightに有効な座標とサイズ(例: 0, 0, 100, 100)を指定するdpiに有効な解像度(例: 300)を指定する- 手順:
process_pdfs関数を呼び出す- 期待値:
out_dirにPDFファイルから切り取られた画像ファイルが生成される- コンソールに "Processing: {pdf_path}" のメッセージが表示される
上記以外にも複数のテストケースを生成し、実際にテストに利用できそうなテストケースは異常系を含めて合計13件ありました。
生成したテストケースを整理、修正などして、テストケースを入力としてGitHub Copilot Chatが生成したテストコードを以下に示します。
----------------------------------------
テストコードを表示(折りたたみ)
------------------------------------------
import os
import shutil
import pytest
from crop_imgs_from_pdfs import process_pdfs
# テストデータの準備
TEST_PDF_DIR = "./test_data/pdf/"
TEST_OUTPUT_DIR = "./test_output/"
NORMAL_PDF_PATH = "./test_pdf/normal_pdf.pdf"
@pytest.fixture(scope="function", autouse=True)
def setup_and_teardown():
# テストデータディレクトリの作成
os.makedirs(TEST_PDF_DIR, exist_ok=True)
os.makedirs(TEST_OUTPUT_DIR, exist_ok=True)
yield
# テストデータディレクトリの削除
shutil.rmtree(TEST_PDF_DIR)
shutil.rmtree(TEST_OUTPUT_DIR)
def test_process_pdfs_valid_directories_case1():
# テストデータの準備
shutil.copy(NORMAL_PDF_PATH, TEST_PDF_DIR + "test1.pdf")
pdf_dir = TEST_PDF_DIR
out_dir = TEST_OUTPUT_DIR
page_number = 1
x, y, width, height = 0, 0, 100, 100
dpi = 300
# テスト実行
process_pdfs(pdf_dir, out_dir, page_number, x, y, width, height, dpi)
# 期待値の確認
assert os.path.exists(out_dir + "test1.png")
def test_process_pdfs_output_directory_not_exist_case2():
# テストデータの準備
shutil.copy(NORMAL_PDF_PATH, TEST_PDF_DIR + "test2.pdf")
pdf_dir = TEST_PDF_DIR
out_dir = TEST_OUTPUT_DIR + "non_existent/"
page_number = 1
x, y, width, height = 0, 0, 100, 100
dpi = 300
# テスト実行
process_pdfs(pdf_dir, out_dir, page_number, x, y, width, height, dpi)
# 期待値の確認
assert os.path.exists(out_dir + "test2.png")
def test_process_pdfs_pdf_directory_not_exist_case3():
# テストデータの準備
pdf_dir = TEST_PDF_DIR + "non_existent/"
out_dir = TEST_OUTPUT_DIR
page_number = 1
x, y, width, height = 0, 0, 100, 100
dpi = 300
# テスト実行
with pytest.raises(FileNotFoundError):
process_pdfs(pdf_dir, out_dir, page_number, x, y, width, height, dpi)
def test_process_pdfs_no_pdf_files_case4():
# テストデータの準備
pdf_dir = TEST_PDF_DIR
out_dir = TEST_OUTPUT_DIR
page_number = 1
x, y, width, height = 0, 0, 100, 100
dpi = 300
# テスト実行
process_pdfs(pdf_dir, out_dir, page_number, x, y, width, height, dpi)
# 期待値の確認
assert len(os.listdir(out_dir)) == 0
上記のテストコードを実行した結果は以下の通りです。

3件はpassしましたが、1件はfailedしています。
テスト対象のコードの実際の挙動ではFileNotFoundErrorの場合にエラーメッセージを表示しますが、テストコードではFileNotFoundErrorが発生する期待結果になっていたため、テストがfailedしています。
テストケースでもエラーメッセージの表示を期待していましたが、生成されたテストコードではテストケース通りに実装されませんでした。
実際にソフトウェア開発で利用する際には、生成AIで生成されたテストコードは必ずテストケース通りに作成されているか確認して、そうでない場合は修正が必要です。
確認して修正する時間は、生成されたテストコードの品質にも依りますが、一からテストコードを人手で作成する時間よりも早いと感じています。
ベストプラクティスを積み重ねて、ある程度定型化されたプロンプトをベースとして利用できれば、さらに効率化できると思います。
おわりに
今回は、東芝のソフトウェア開発効率化のための生成AI活用の取り組みについてお話し、生成AIを利用した単体テストコード生成方法を簡単なPythonコードに試行してみた結果をご紹介しました。
生成AIを利用することで、テストケースやテストコードの作成などのソフトウェア開発作業は効率化できるようになってきています。
ただし、ご紹介したように生成AIの出力には誤りや期待しない回答が含まれることもあるため、生成AIを利用する際は注意が必要です。
今後も生成AIをソフトウェア開発にうまく利用し、人を支援する道具として活用していきたいと考えています。