概要
陸上競技の男子 100m 走の歴代3900 傑のリストを使って、回帰分析を行いたいと思います。いろいろな回帰モデルを使って分析を進め、決定係数 R2 で比較していきます。さらに、2030 年と 2050 年にどれくらいの記録が出るのかを、それぞれのモデルを使って予想していきます。それぞれのモデルがどのくらいの記録を予想するのか興味が惹かれます。
環境
- M2 Mac
- JupyterLab 3.3.2
- Python 3.9.12
- Numpy 1.21.5
- Pandas 1.4.2
- Matplotlib 3.5.1
- Scikit-learn 1.0.2
分析
1. Data 前処理
1) 100m Excel Data の読み込み
最初に陸上競技の男子 100m 走の歴代3900 傑のリストの Excel ファイルを読み込みます。100m の歴代リストは下記のサイトから取得しました。
Data 出典 : http://www.alltime-athletics.com/men.htm
import pandas as pd
df = pd.read_excel("M100m for ML.xlsx")
df
今回の分析で使用するデータは以下のような内容で、約 3,900 行あります。
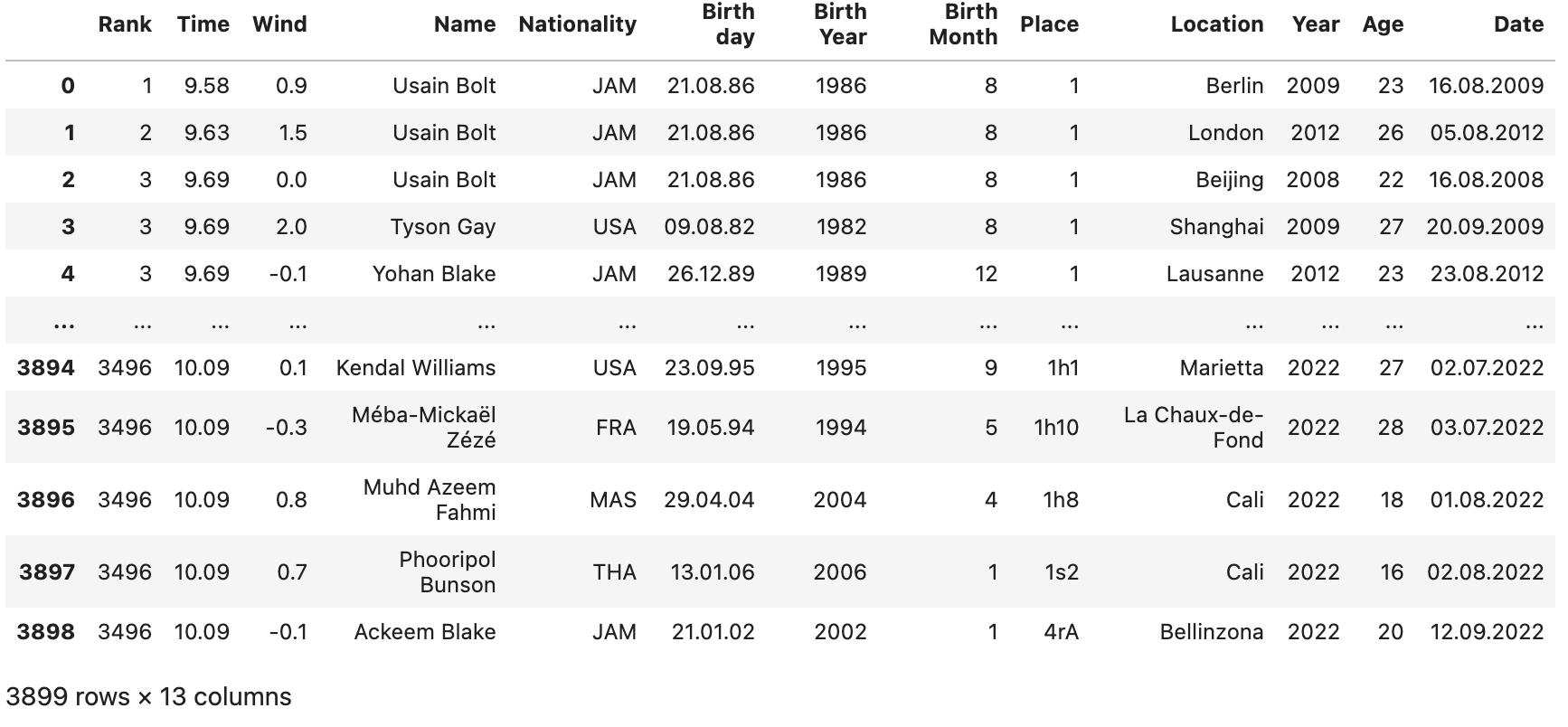
各 Column について説明いたします。
Rank : 順位(歴代の記録で何番目に良い記録なのか)
Time : 記録(単位は sec(秒)で、1/100 sec まで記載)
Wind : 風(正の数は追い風、負の数は向かい風を表す。単位は m/sec)
* 追い風の場合、最大 2.0 m/sec までが記録として公認されます
Name : 記録した者の名前
Nationality : 記録した者の国籍
Birthday : 記録した者の誕生年月日(表記は日.月.年)
Birth Year : 記録した者の誕生年
Birth Month : 記録した者の誕生月
Place : 記録したレースでの順位
Location : 記録した場所(レースの開催地)
Year : 記録した年
Age : 記録した年齢
Date : 記録した年月日(表記は日.月.年)
データに欠損がないかを確認します。
# 欠損値の確認
df.isnull().sum()

Wind と Location に欠損があります。Wind は 0 を入れれば分析に影響はでないので、0 を入れます。Location は説明変数、目的変数いずれにも使用しないため、この先で列自体を削除する予定ですので、同じく 0 を入れておきます。
# 欠損値穴埋め
df = df.fillna(0)
df.isnull().sum()

これでデータに欠損は無くなりました。
データの内容を見るために、いくつかのパラメーターを組み合わせてプロットしてみます。
まずは、タイムの推移を時系列で見ます。
import matplotlib.pyplot as plt
# タイムを時系列でプロット
df.plot(kind = 'scatter', x = "Year", y = "Time")
plt.ylabel('Time (sec)')
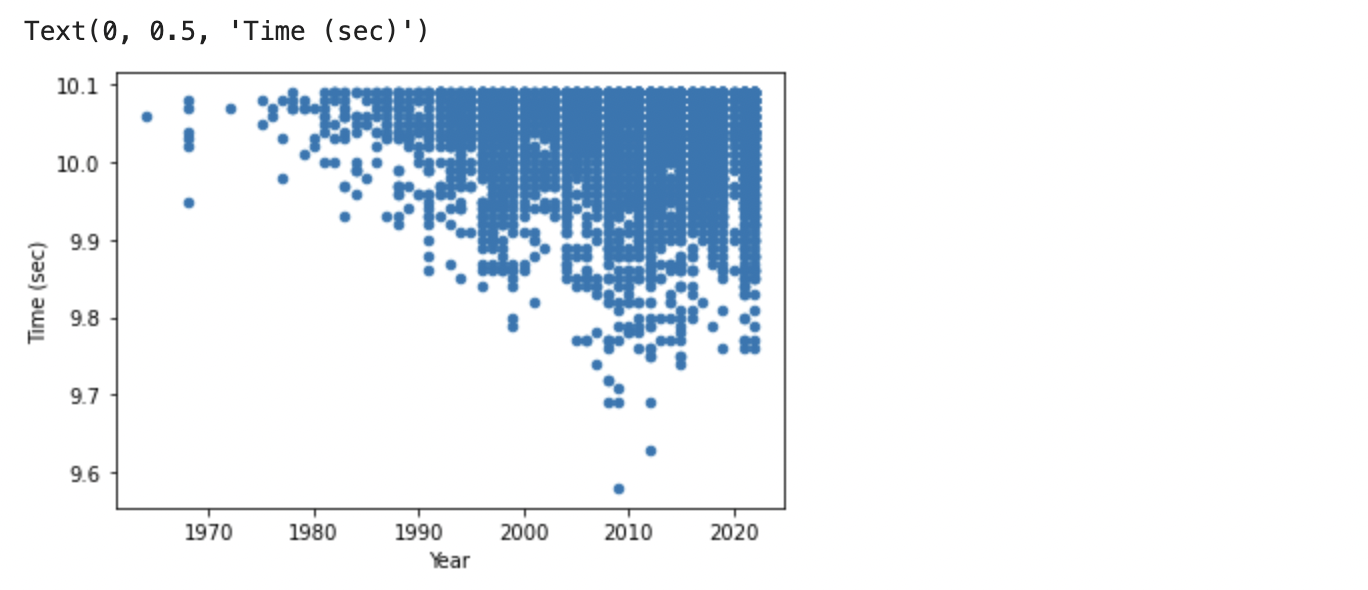
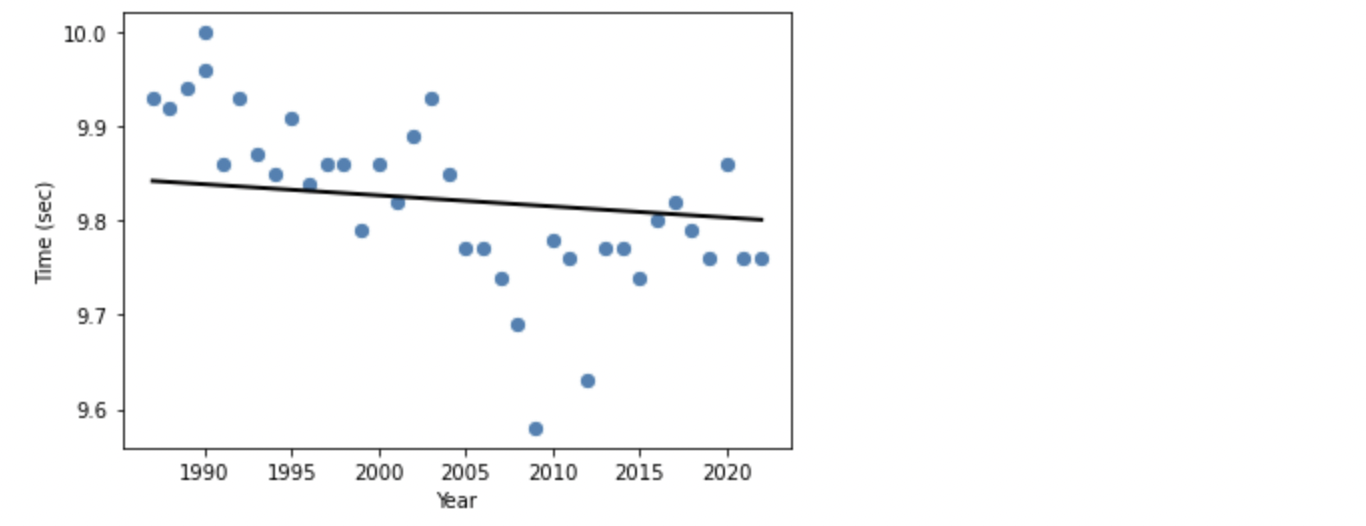
年々少しずつタイムが良くなっているのがわかります。
2010 年前後に 9.6 秒前後の飛び抜けて良いタイムが 2 つありますが、これはボルトさんが出した記録です。いかに彼が突出していたのかが、このグラフからもわかります。
続いてタイムと年齢でプロットしてみます。
# 'Time' を 'Age' でプロット
df.plot(kind = 'scatter', x = "Age", y = "Time")
plt.ylabel('Time (sec)')
 18 歳くらいから 40 歳くらいまでに集中しています。ピークは 25~27 歳くらいです。80 歳のところに 1 つドットがありますが、これは外れ値のため、削除します。
18 歳くらいから 40 歳くらいまでに集中しています。ピークは 25~27 歳くらいです。80 歳のところに 1 つドットがありますが、これは外れ値のため、削除します。
df=df.drop(df['Age'].idxmax())
タイムと気象条件(風)でプロットします。
# タイムを気象条件(風)でプロット
df.plot(kind = 'scatter', x = "Wind", y = "Time")
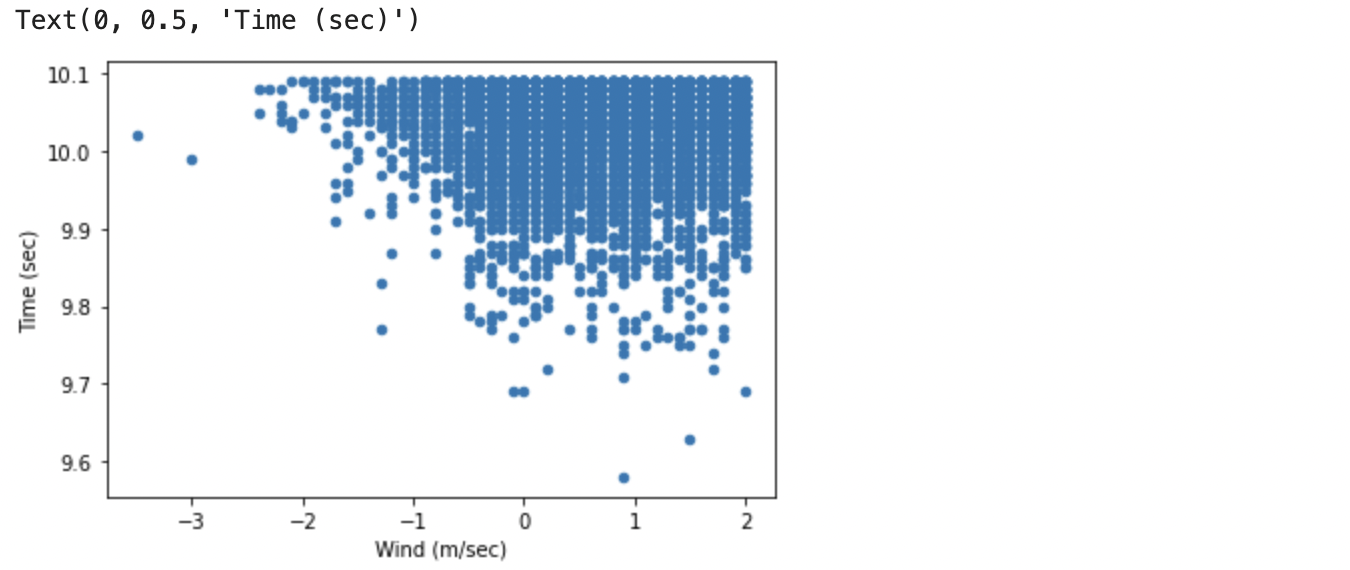
当然向かい風よりは追い風の方がいい記録が出ますが、グラフからもそれは明確に読み取れます。しかしグラフをよく見ると、追い風が強ければ強いほど良い記録が出るというわけではないようです。追い風は 2.0m 以内までが公認記録となります。
さて、このデータテーブルには分析に不要な列がありますので、それらを削除します。
# リストからランク、名前、国籍、誕生日、誕生月、順位、場所、年月日を削除
df2 = df.drop(columns=['Rank','Name','Nationality','Birth day',\
'Birth Month','Place','Location','Date'])
df2

このデータのパラメーター間の相関を見るために、相関行列を作ります。
# 相関行列の作成
correlation_matrix = df.corr().round(2)
sns.heatmap(data=correlation_matrix, annot=True)
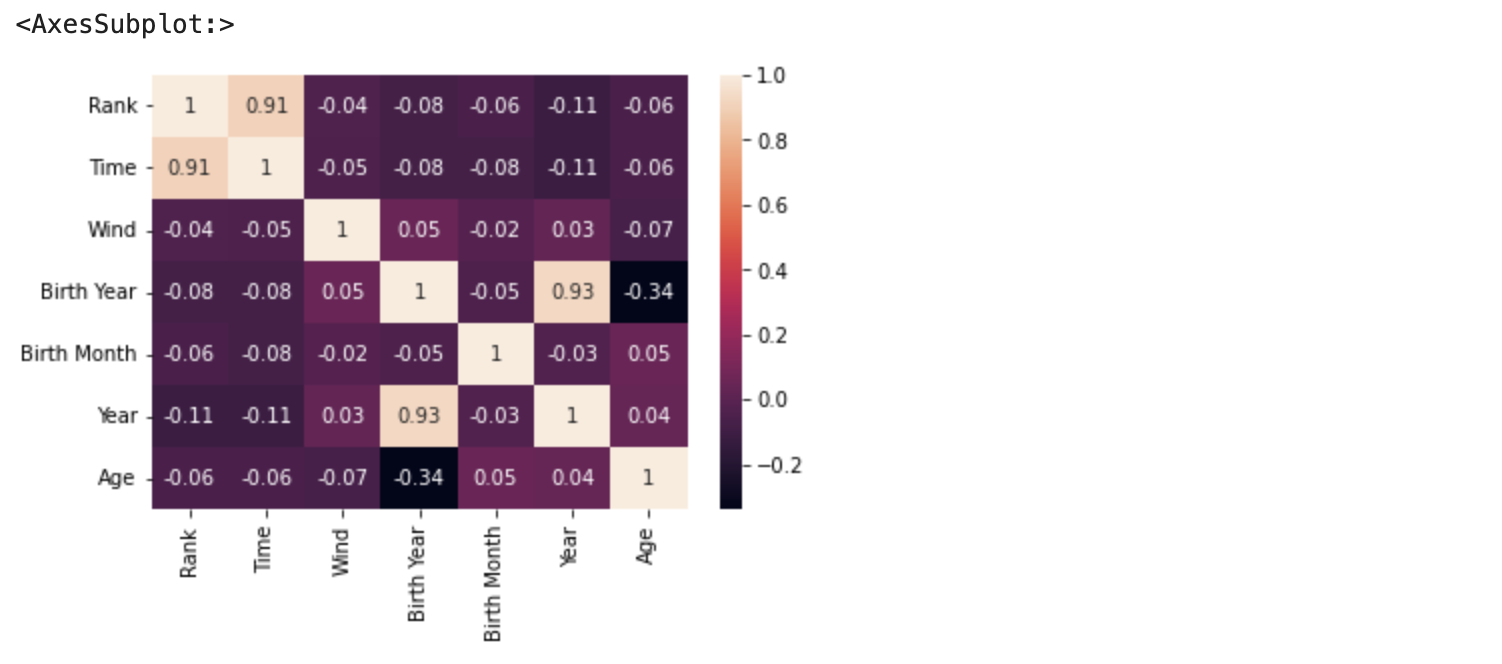
今回はタイムを予測したいので、タイムと相関が高いパラメーターが必要ですが、相関が高いパラメーターはランクくらいしかありません。このデータテーブルのままでは良い分析はできそうにありませんので、一工夫が必要です。
2) 新しい DataFrame を作成する
方針
- 各年のベスト記録を抽出したリストを作成する
- そのリストに各年の 10 番目の記録を加える
10 番目の記録を加える理由は、その年のベスト記録と 10 番目の記録の差が小さければ全体のレベルが高く、ベストの記録は翌年以降短縮されていく可能性が高く、差が大きければ、ベスト記録は突出しており、その先はなかなかベスト記録は向上しにくいなど、その年以降を予測する際の重要なヒントとなりうるからです。
新しい DataFrame は Df_year_best_time とし、以下のように、枠組みを用意します。
# Df_year_best_time DataFrame の作成
list=[[0,0,0,0,0,0]]
df_year_best_time = pd.DataFrame(data=list)
df_year_best_time.columns = ['Time','Wind','Birth Year','Year','Age','10th Time']
df_year_best_time

それでは、新しく作成した DataFrame にデータを入れていきます。
# df_year_best_time DataFrame へ、各年のデータを入れていくルーティン
for num in range(1986,2023):
# ある年のリストを作成
df_a_year = df2[df2["Year"]==num]
# ある年のベストタイムの行数を抽出
df_year_best_time_a_year_column_number = df_a_year['Time'].idxmin()
# ある年のベストタイムのデータを抽出
df_year_best_time_a_year = pd.DataFrame()
df_year_best_time_a_year = df2.iloc[df_year_best_time_a_year_column_number]
# 年ベストタイムリストにある年のベストタイムデータを追加
df_year_best_time.loc[num] = df_year_best_time_a_year
0 行目のデータは不要なので削除します。うまく各年のベスト記録の情報が拾えているかを確認します。
df_year_best_time = df_year_best_time.drop(index=0)
df_year_best_time.head(10)
上記のコードで、各年のベスト記録のデータがうまく拾えました。10th Time のデータは以下のコードにて別途取得します。
# df_year_best_time DataFrame へ、各年の 10th Time データを入れていくルーティン
for num in range(1986,2023):
# ある年のリストを作成
df_a_year = df2[df2["Year"]==num]
# ある年の 10 番目の記録データを抽出
df_year_10th_time_a_year = df_a_year.iloc[10]
# ある年の 10 番目の記録データからタイムだけを抽出
df_year_10th_time_a_year_2 = df_year_10th_time_a_year['Time']
# 年ベストタイムリストにある年のベストタイムデータを追加
df_year_best_time.loc[num,'10th Time'] = df_year_10th_time_a_year_2
うまく各年の 10 番目のタイムを抽出し、それを df_year_best_time の 10th Time の列に入れられているかを見てみます。
df_year_best_time.head(10)
うまく各年の 10 番目の記録を取得することができました。
各パラメーター間の相関を見ます。
# 相関行列を作ります。
correlation_matrix = df_year_best_time.corr().round(2)
sns.heatmap(data=correlation_matrix, annot=True)
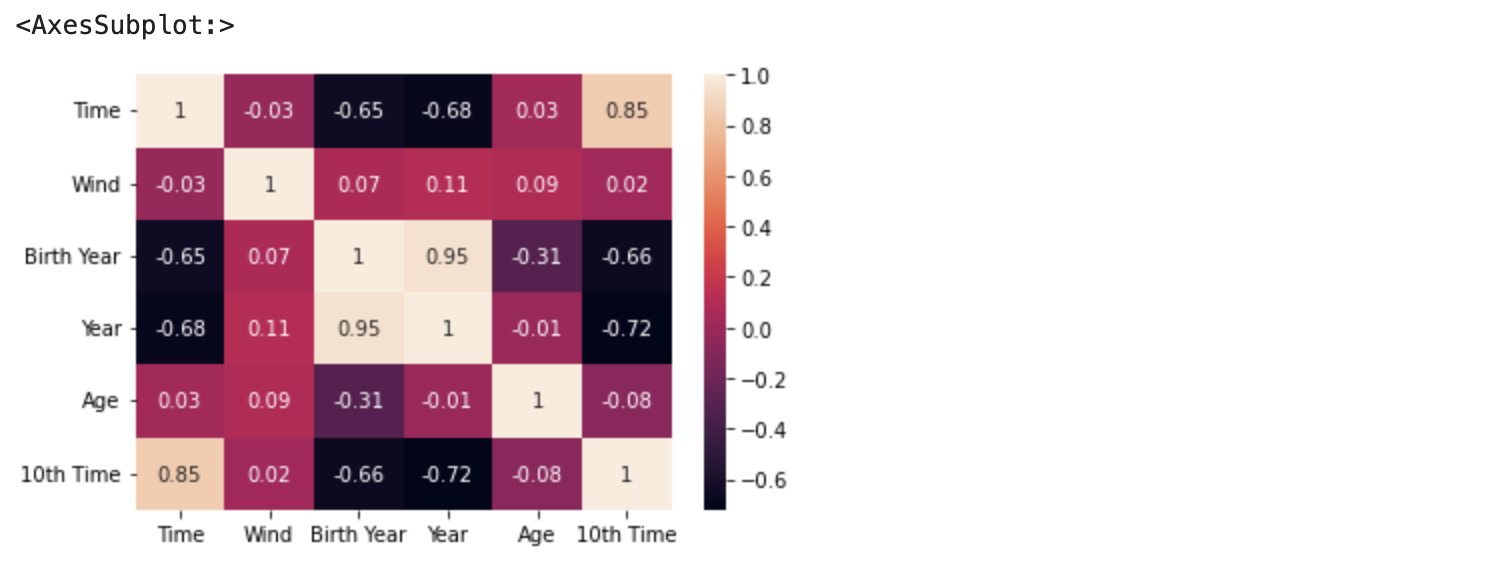
やはり 10th Time は Time (ベスト記録)との相関がかなり高いです。Year も負の相関ですが、かなり相関が高いです。単純に時代が進むほど記録が向上することを表しています。
説明変数度同士の相関を見ると、Year と Birth Year の相関が非常に高いです。重回帰分析において、説明変数の間の相関が強すぎる場合に多重共線性という現象が起こることがあります。多重共線性が起こっている場合は、係数の推定結果、それをもとにした解釈、予測などは信頼できない情報となります。
今回の場合では、Birth Year を削除した上で各モデルの学習を行い、R2、MAE のスコア、未来の予測タイムを算出し、Birth Year を削除しない場合の結果と比較してみましたが、結果は全く同じものとなりました。ですので、今回は多重共線性のリスクはありませんので、パラメーターの削減は行わないものとします。
続いて、各パラメーター間の関係をプロットします。
import seaborn as sns
sns.pairplot(df_year_best_time, size=1.0)
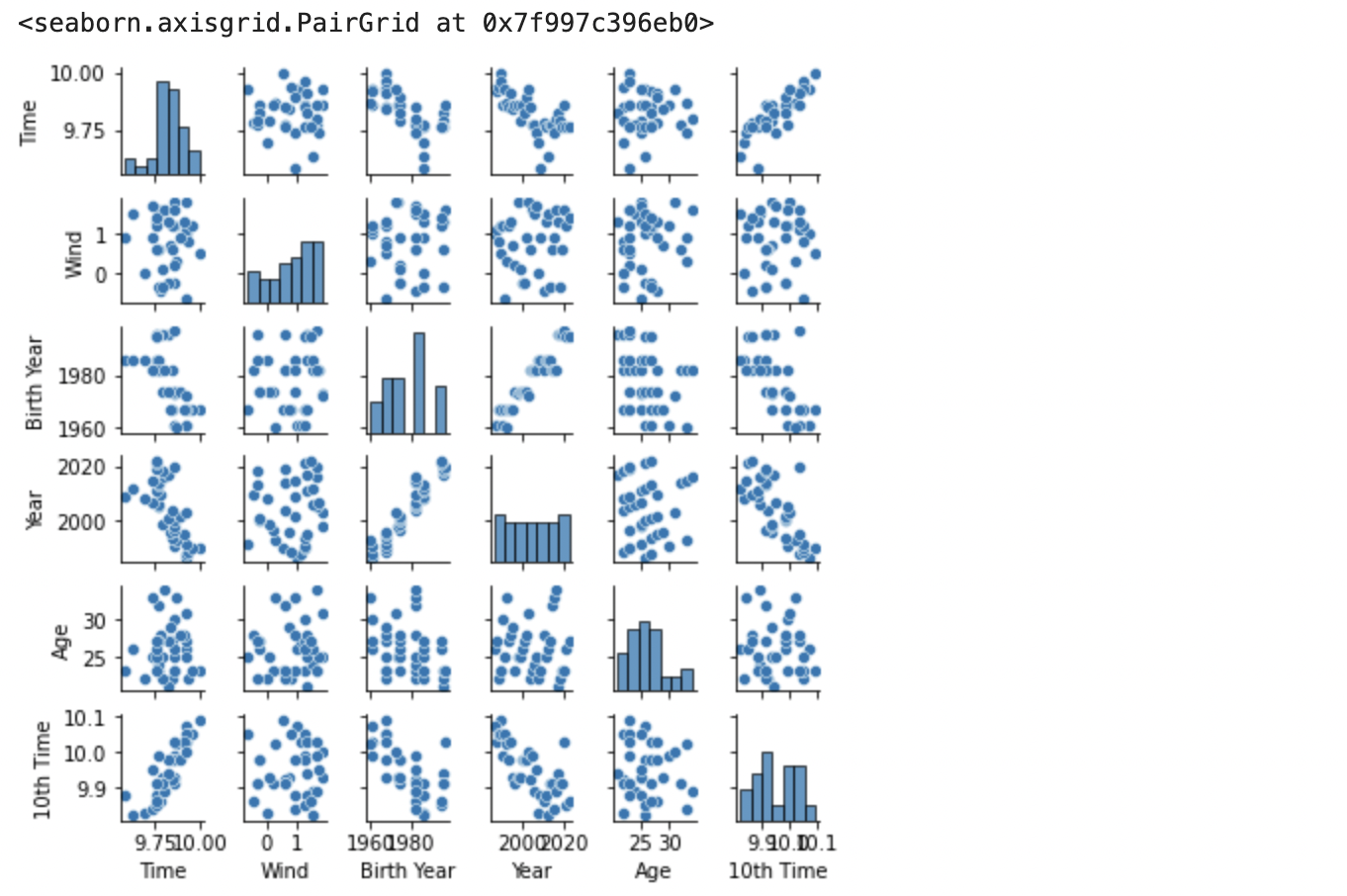
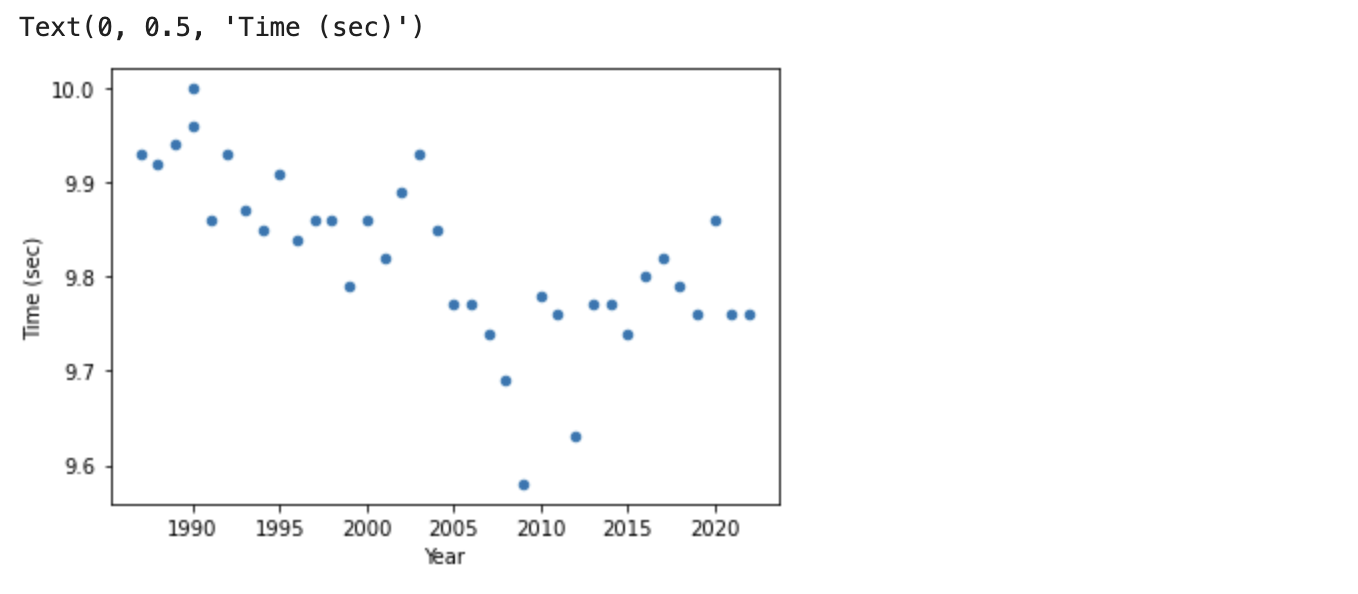
各年ベストタイムを時系列で見ると、
# タイムを時系列でプロット
df_year_best_time.plot(kind = 'scatter', x = "Year", y = "Time")
plt.ylabel('Time (sec)')
これを線形回帰(単回帰)で見ると、
sns.regplot('Year','Time',data=df_year_best_time)
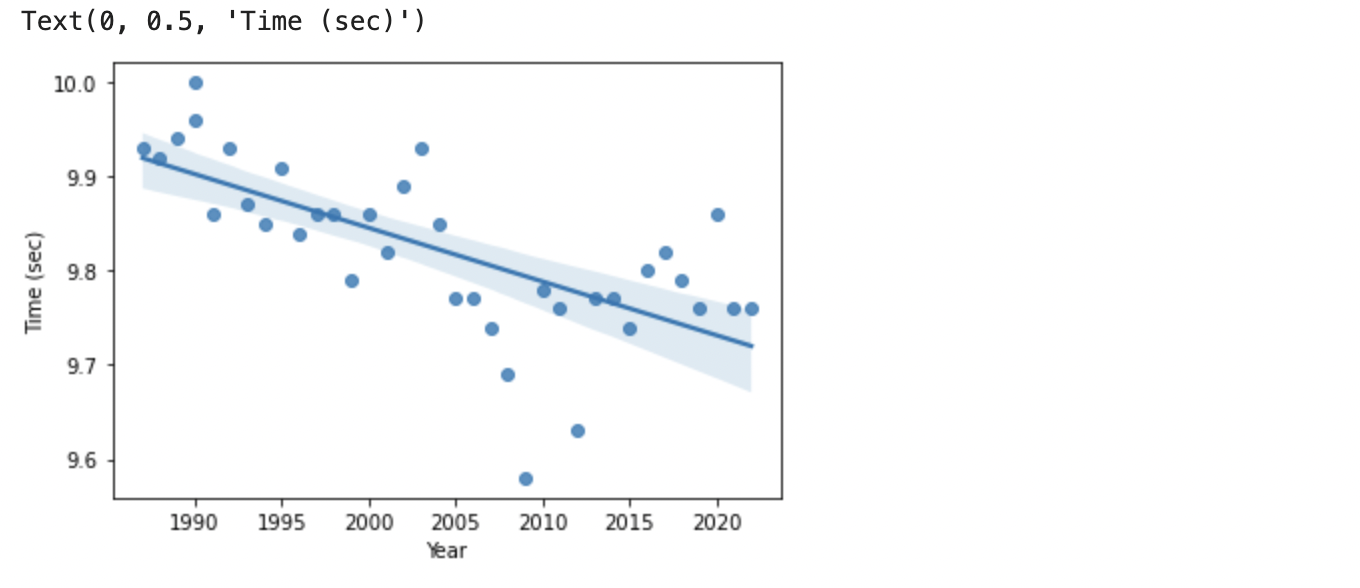
時の経過とともに記録が向上しています。
次に10th Time を時系列で見ると、
# 10th Time を時系列でプロット
df_year_best_time.plot(kind = 'scatter', x = "Year", y = "10th Time")
plt.ylabel('Time (sec)')
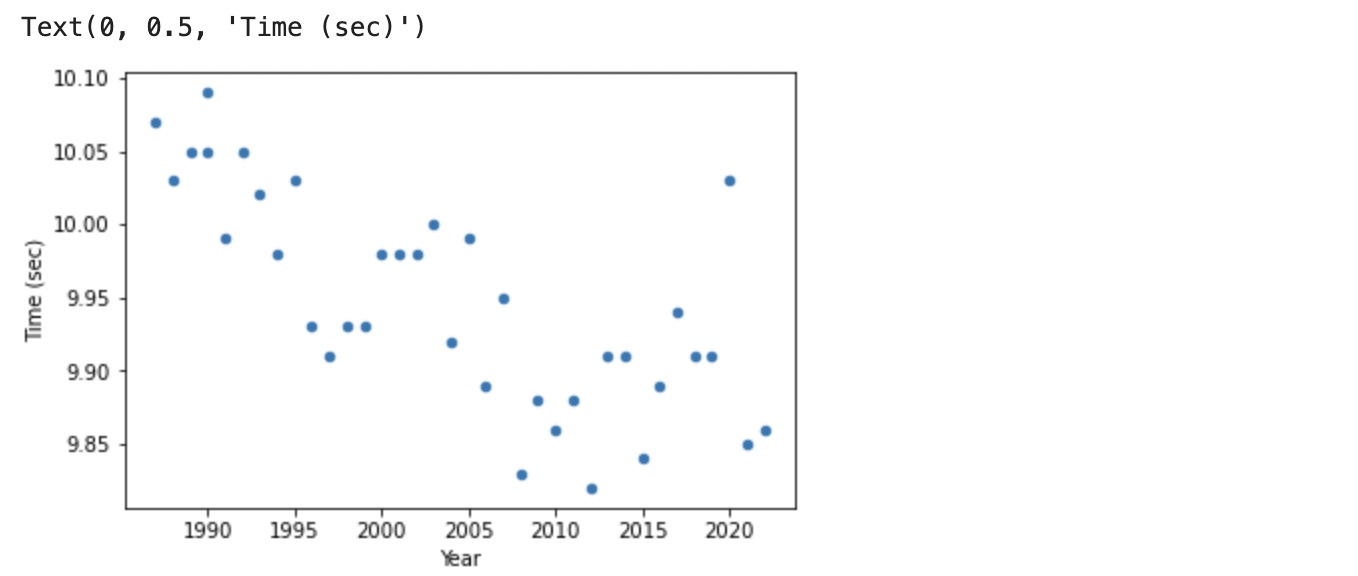
10th Time もベスト記録と同じように、少しづつタイムが良くなっています。
2. 回帰モデルの学習
1) 特徴量の標準化(分散正規化)
特徴量ごとの最大値、最小値を見てみます。
df_year_best_time.describe()
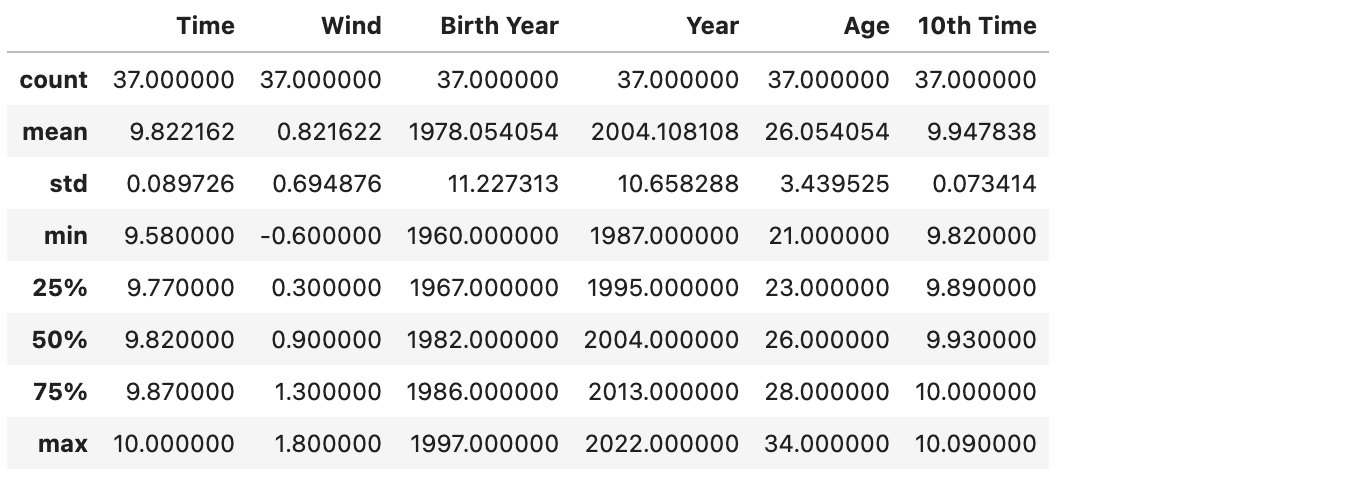
上記表の min が最小値、max が最大値です。Year や Birth Year などは数値が 4 桁あり、最大値と最小値の差は比率で見るとほとんどありませんが、Wind は最小値 -0.6、最大値 1.8 と非常に小さい数値ですが、比率で見ると、ばらつきは非常に大きいです。このままではそれぞれの特徴量を同じスケールで測れませんので、数値を調整する必要があります。
特徴量ごとの重みを均一にするために、それぞれの偏差に置き換えます。偏差に置き換えることで、すべての特徴量のウェートが均一になります。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =\
train_test_split(X, t,test_size = 0.2,random_state=0)
# データを標準化(分散正規化)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
2) 各モデルでの学習と評価
準備したデータを使用し、様々な回帰用のモデルで学習を進めます。
a. LenearRegression
LinearRegression は最小二乗法による線形回帰モデルです。最小二乗法ではデータとモデルの予測値の誤差の二乗和が最少となる重みパラメーターが最も良いと仮定します。特徴量が 1 つであれば単回帰、複数あれば重回帰となります。
モデルの学習
from sklearn.linear_model import LinearRegression
# スコア計算のためのライブラリー
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
# モデルの学習
lr = LinearRegression()
lr.fit(X_train_std, y_train)
# 回帰
pred_lr = lr.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_lr = r2_score(y_test, pred_lr)
# 平均絶対誤差(MAE)
mae_lr = mean_absolute_error(y_test, pred_lr)
print("R2 : %.3f" % r2_lr)
print("MAE : %.3f" % mae_lr)
# 回帰係数
print("Coef = ", lr.coef_)
# 切片
print("Intercept = ", lr.intercept_)

import matplotlib.pyplot as plt
%matplotlib inline
plt.xlabel("pred_lr (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_lr, y_test)
plt.show()
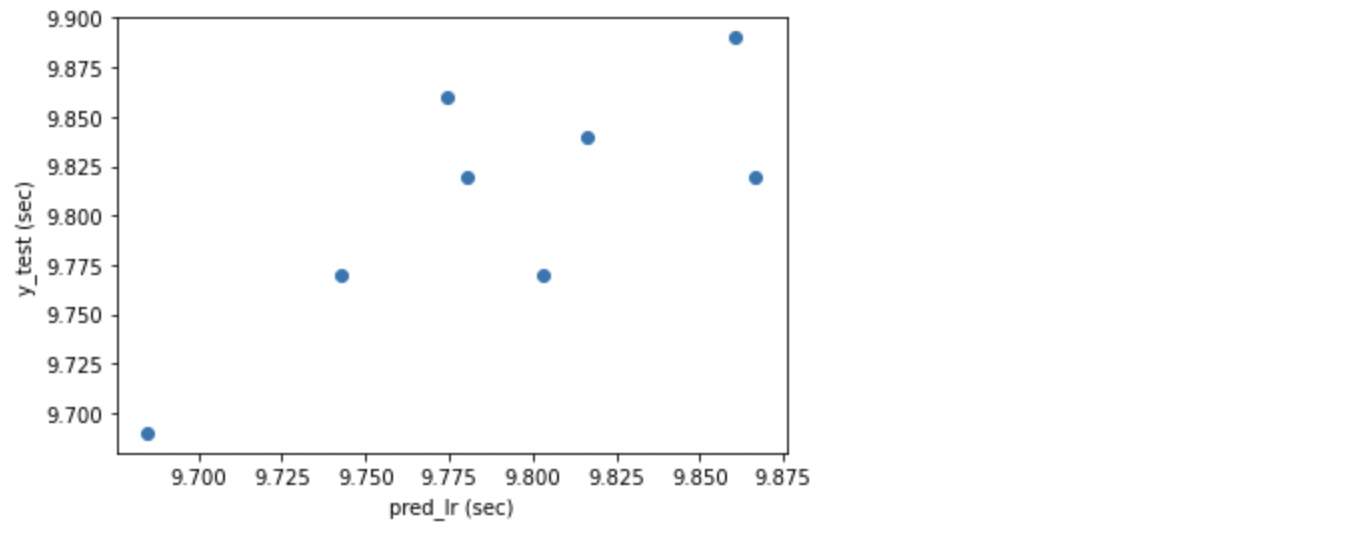
LinearRegression での R2 は 0.475 で、やや悪いといったところです。MAE(平均絶対誤差)は 0.036 で、まずまずの数値となりました。
モデルの可視化
このモデルではどのような回帰となっているのかを可視化したいと思いますが、今回の回帰分析は特徴量(説明変数)が 5 つ、ラベル(目的変数)が 1 つあるため、6 次元のグラフとなります。2 次元である画面上では表現できませんので、簡易的に 'Year' と 'Time' の 2 次元のグラフで可視化します。
# y='Time'、 X='Year' の 2軸で見た場合の線形回帰の可視化
def lin_regplot(X, y, model):
plt.scatter(X, y, c='steelblue', edgecolor='white', s=70)
plt.plot(X, model.predict(X), color='black', lw=2)
return None
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
lr2 = LinearRegression()
lr2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], lr2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
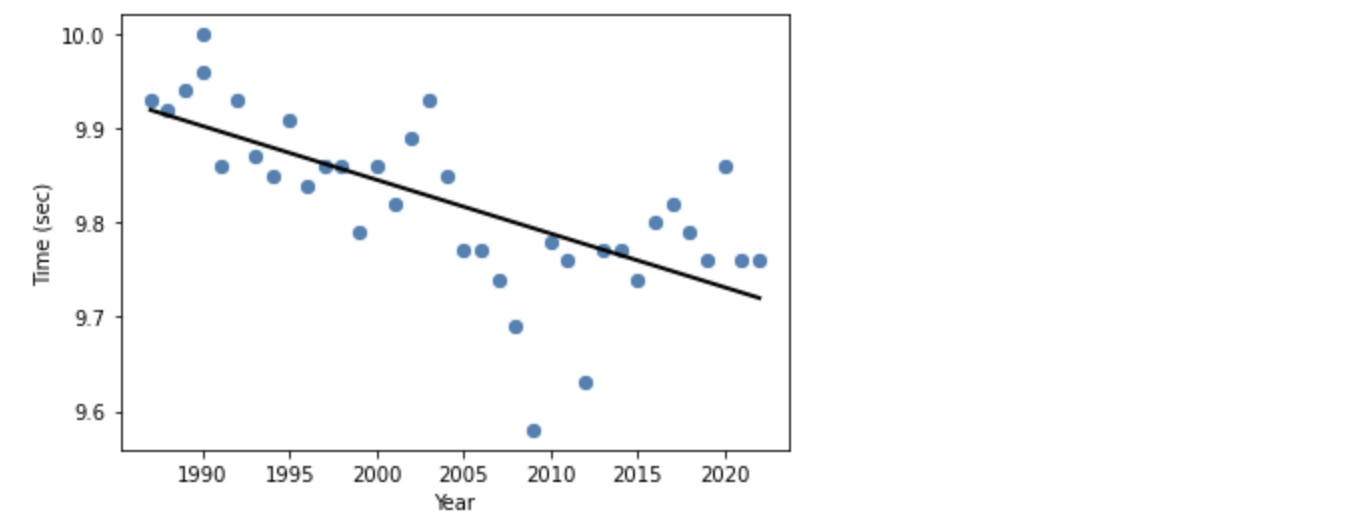
LinearRegresson は線形回帰ですので直線になります。
b. Ridge
Ridge 回帰は線形回帰モデルの 1 種であり、誤差関数の罰則項は学習パラメーターの二乗和(L2 正則化)です。正則化を行うことで過学習を防ぐことができます。
モデルの学習
from sklearn.linear_model import Ridge
# モデルの学習
ridge = Ridge(alpha=10, random_state=0)
ridge.fit(X_train_std, y_train)
# 回帰
pred_ridge = ridge.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_ridge = r2_score(y_test, pred_ridge)
# 平均絶対誤差(MAE)
mae_ridge = mean_absolute_error(y_test, pred_ridge)
print("R2 : %.3f" % r2_ridge)
print("MAE : %.3f" % mae_ridge)
# 回帰係数
print("Coef = ", ridge.coef_)
# 切片
print("Intercept = ", ridge.intercept_)

plt.xlabel("pred_ridge (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_ridge, y_test)
plt.show()
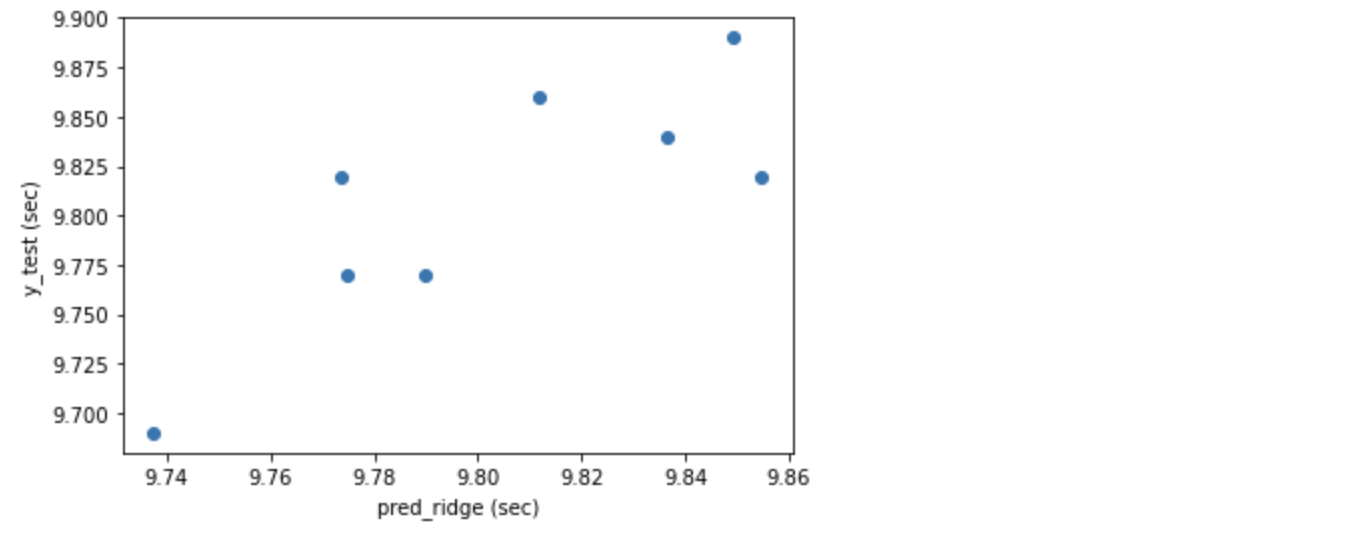
Ridge の R2 は単純な線形回帰である LinearRegression を上回る 0.635 となり、まずまずの結果となりました。MAE 0.031 は他のモデルより良い数値です。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の Ridge 回帰の可視化
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
ridge2 = Ridge(alpha=10, random_state=0)
ridge2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], ridge2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
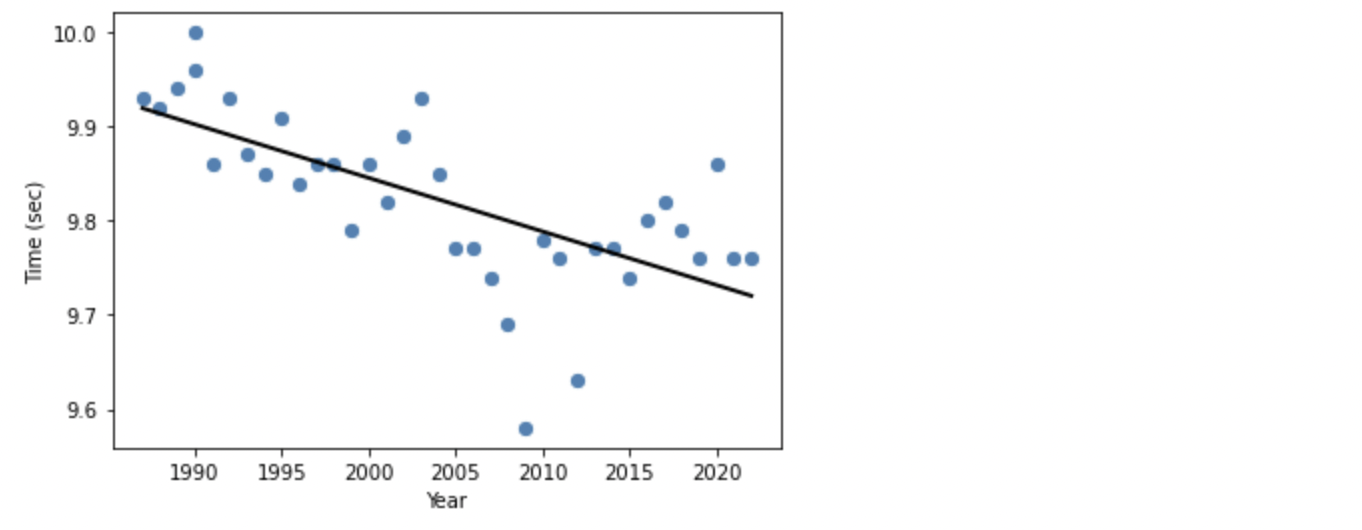
Ridge の回帰は LinearRegression にかなり近い切片と傾きであることが窺われます。
c. Lasso
Lasso は Ridge と類似していますが、Lasso では罰則項は学習パラメーターの絶対値の和になっています(L1 正則化)。Lasso 回帰は学習パラメーターが 0 になりやすいという性質があります。この性質によりパラメーターが 0 になった特徴量を使わずにモデルを構築できるので、特徴量選択を行うことができます。
モデルの学習
from sklearn.linear_model import Lasso
# モデルの学習
lasso = Lasso(alpha=1, random_state=0)
lasso.fit(X_train_std, y_train)
# 回帰
pred_lasso = lasso.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_lasso = r2_score(y_test, pred_lasso)
# 平均絶対誤差(MAE)
mae_lasso = mean_absolute_error(y_test, pred_lasso)
print("R2 : %.3f" % r2_lasso)
print("MAE : %.3f" % mae_lasso)
# 回帰係数
print("Coef = ", lasso.coef_)
# 切片
print("Intercept = ", lasso.intercept_)
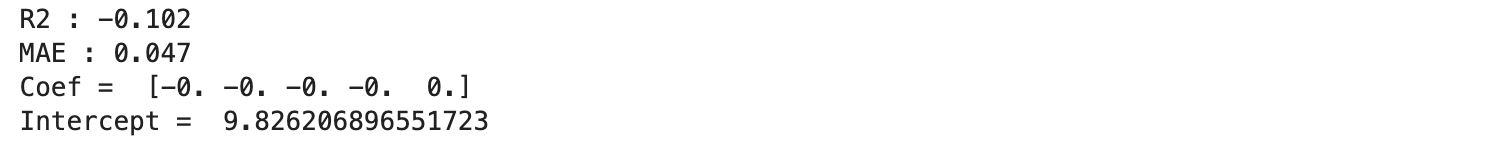
plt.xlabel("pred_lasso (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_lasso, y_test)
plt.show()
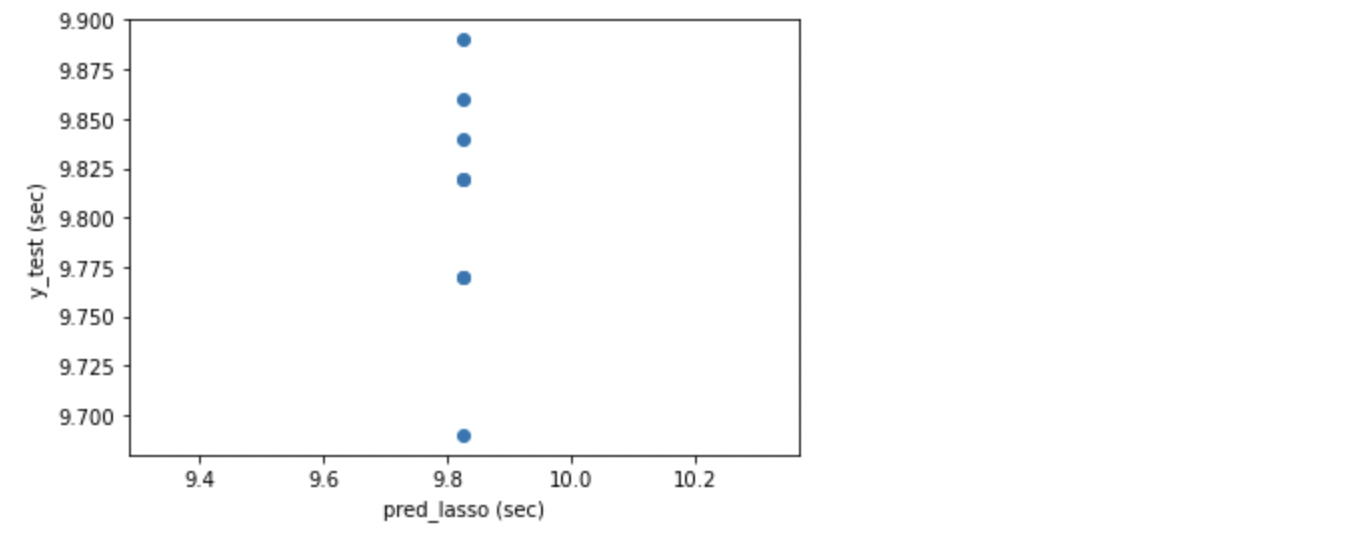
Lasso の R2 は負の数となってしまいました。散布図でみると、垂直に一直線上にプロットされています。また、MAE も 0.047 とよくありません。同じ線形回帰の正則化モデルでも Ridge はかなり良い学習ができていたのに対して、Lasso はうまく学習ができず、対照的な結果となったのが意外です。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の Lasso 回帰の可視化
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
lasso2 = Lasso(alpha=1, random_state=0)
lasso2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], lasso2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
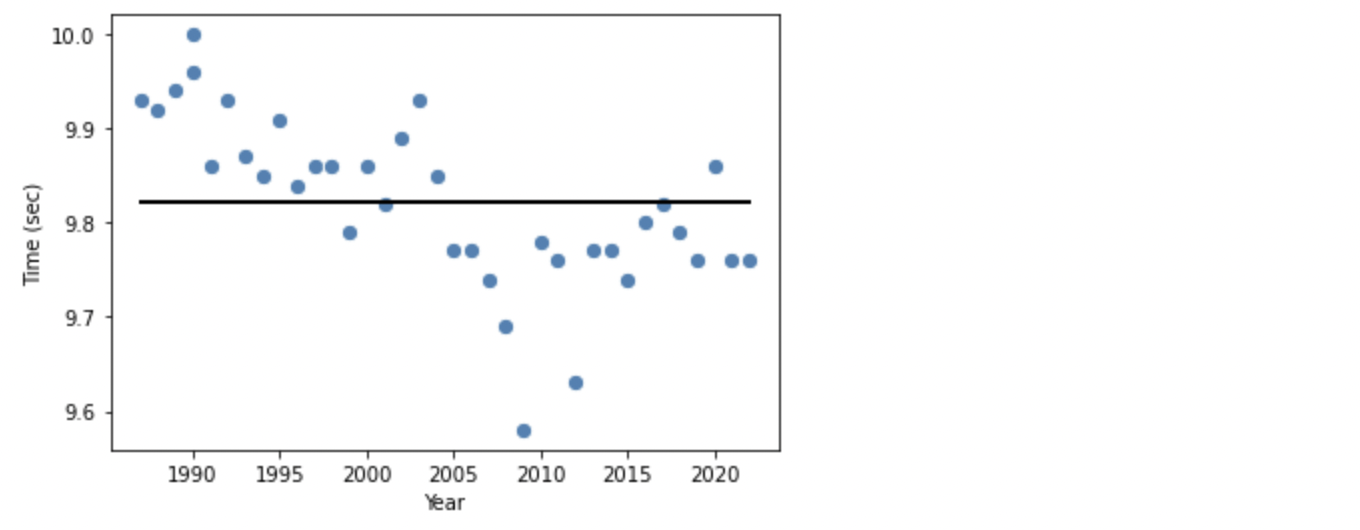
Lasso はうまく学習できず、傾きが 0 の線形となっています。
pred_lasso

全て 9.82 となっています。
d. ElasticNet
ElasticNet は L1 正則化と L2 正則化の両方を用いて学習する線形回帰モデルです。この組み合わせにより、Ridge の正則化の特性を維持したまま、Lasso のように 0 以外の重みがほとんどない疎なモデルを学習することができます。l1_ratio パラメーターを使用して、L1 と L2 の凸結合を制御します。ElasticNet は互いに相関のある複数の特徴量がある場合に有効です。
モデルの学習
from sklearn.linear_model import ElasticNet
# モデルの学習
elasticnet = ElasticNet(alpha=0.05, random_state=0)
elasticnet.fit(X_train_std, y_train)
# 回帰
pred_elasticnet = elasticnet.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_elasticnet = r2_score(y_test, pred_elasticnet)
# 平均絶対誤差(MAE)
mae_elasticnet = mean_absolute_error(y_test, pred_elasticnet)
print("R2 : %.3f" % r2_elasticnet)
print("MAE : %.3f" % mae_elasticnet)
# 回帰係数
print("Coef = ", elasticnet.coef_)
# 切片
print("Intercept = ", elasticnet.intercept_)
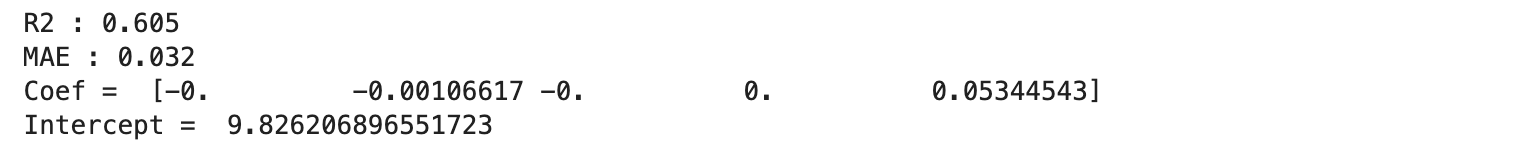
plt.xlabel("pred_elasticnet (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_elasticnet, y_test)
plt.show()
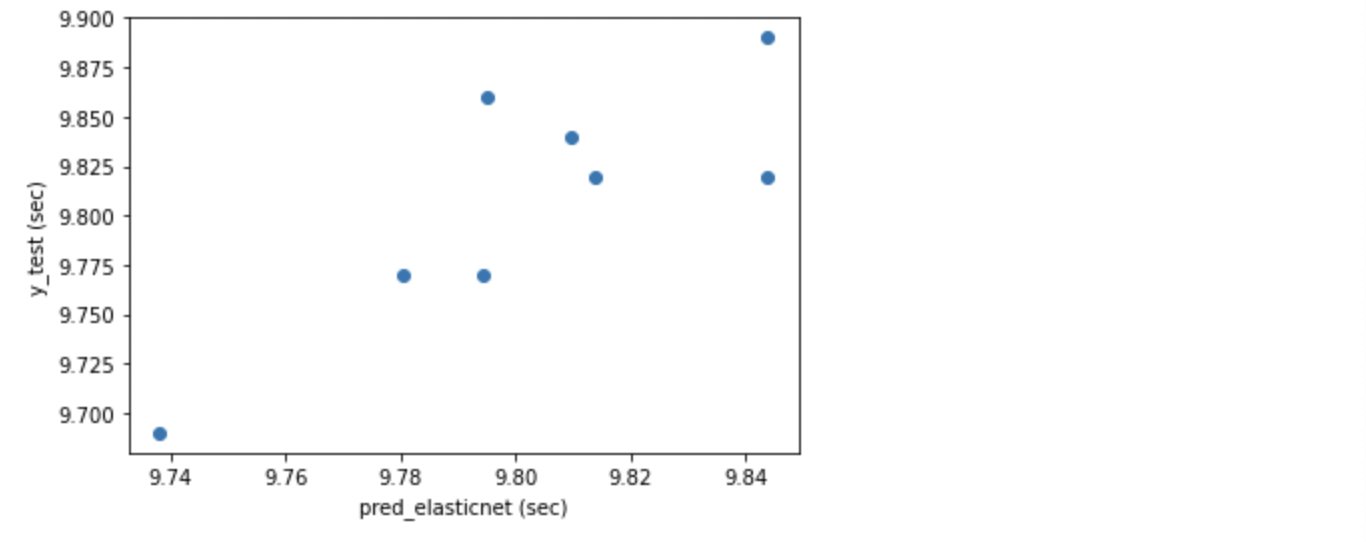
Ridge と Lasso の折衷モデルである ElasticNet の R2 は 0.605 と、Ridge ほどではないにせよ、まずまずのスコアとなりました。MAE も 0.032 と優れています。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の ElasticNet 回帰の可視化
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
ElasticNet2 = ElasticNet(random_state=0)
ElasticNet2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], ElasticNet2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
LinearRegression や Ridge の線形と似ていますが、傾きはやや緩やかです。
e. SVR
SVR は回帰で使用する Suport Vector Machine の一つです。Support Vector Machine の基本コンセプトはマージンの最大化です。Support Vector Machine は回帰と分類両方に適用できます。LinearSVM と非線形の SVM がありますが、今回は非線形のモデルを使用しています。SVM の長所として汎化性能のコントロールのしやすさが挙げられます。マージン内侵入の許容度を適度に大きくすれば過学習を避けられ、汎化性能が上がります。もう一点の長所としては境界線付近にあるデータだけを使用しますので、外れ値にモデルの性能が左右されません。一方、短所としては、データ量が多いと計算量が極めて大きくなることと、値の変動が大きい特徴量の影響を過大評価してしまうことが挙げられます。
モデルの学習
from sklearn.svm import SVR
# モデルの学習
SVR = SVR(kernel='linear', C=1, epsilon=0.1, gamma='auto')
SVR.fit(X_train_std, y_train)
# 回帰
pred_SVR = SVR.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_SVR = r2_score(y_test, pred_SVR)
# 平均絶対誤差(MAE)
mae_SVR = mean_absolute_error(y_test, pred_SVR)
print("R2 : %.3f" % r2_SVR)
print("MAE : %.3f" % mae_SVR)
# 変数重要度
print("Coef = ", SVR.coef_)

plt.xlabel("pred_SVR (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_SVR, y_test)
plt.show()
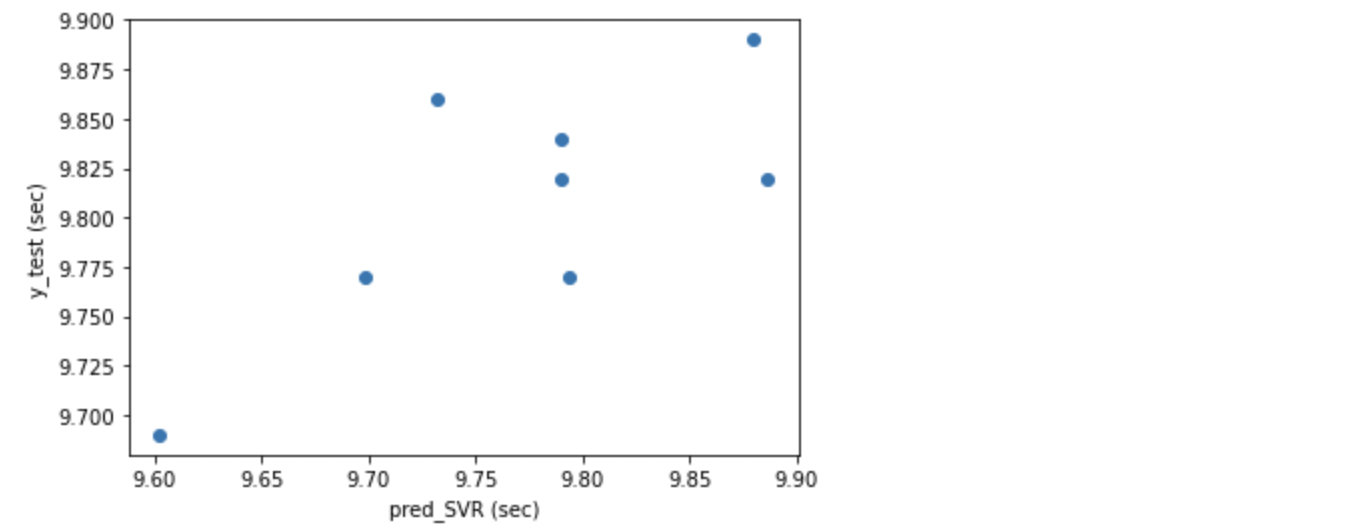
SVR の R2 は 0 を割ってしまいました。MAE も 0.059 と良くありません。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の SVR 回帰の可視化
from sklearn.svm import SVR
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
SVR2 = SVR()
SVR2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], SVR2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
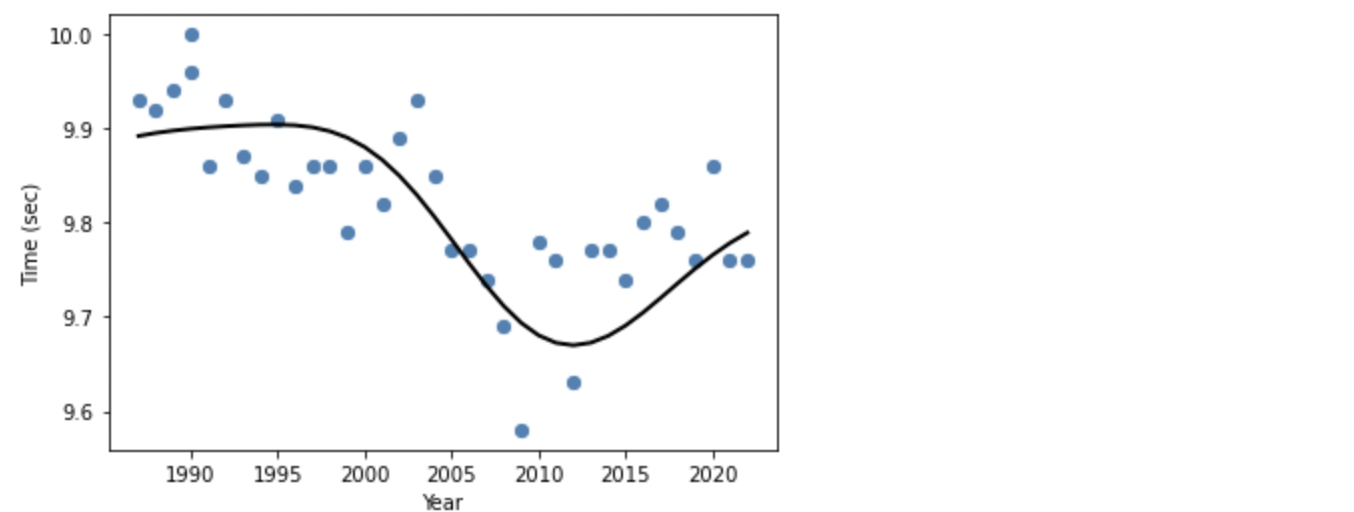
上記のグラフでは SVM らしい曲線を描いています。
f. RandomForest
RandomForest は DecisionTree を複数利用することで DecisionTree 単体よりも予測精度向上を図る手法です。RandomForest は 2 つのランダム性(データ抽出のランダム性と特徴量抽出のランダム性)を取り入れています。RandomForest では、特徴量の多重共線性の回避と、過学習にならないように気を付ける必要があります。
モデルの学習
from sklearn.ensemble import RandomForestRegressor
# モデルの学習
RF = RandomForestRegressor(random_state=0)
RF.fit(X_train_std, y_train)
# 回帰
pred_RF = RF.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_RF = r2_score(y_test, pred_RF)
# 平均絶対誤差(MAE)
mae_RF = mean_absolute_error(y_test, pred_RF)
print("R2 : %.3f" % r2_RF)
print("MAE : %.3f" % mae_RF)
# 変数重要度
print("feature_importances = ", RF.feature_importances_)

plt.xlabel("pred_RF (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_RF, y_test)
plt.show()
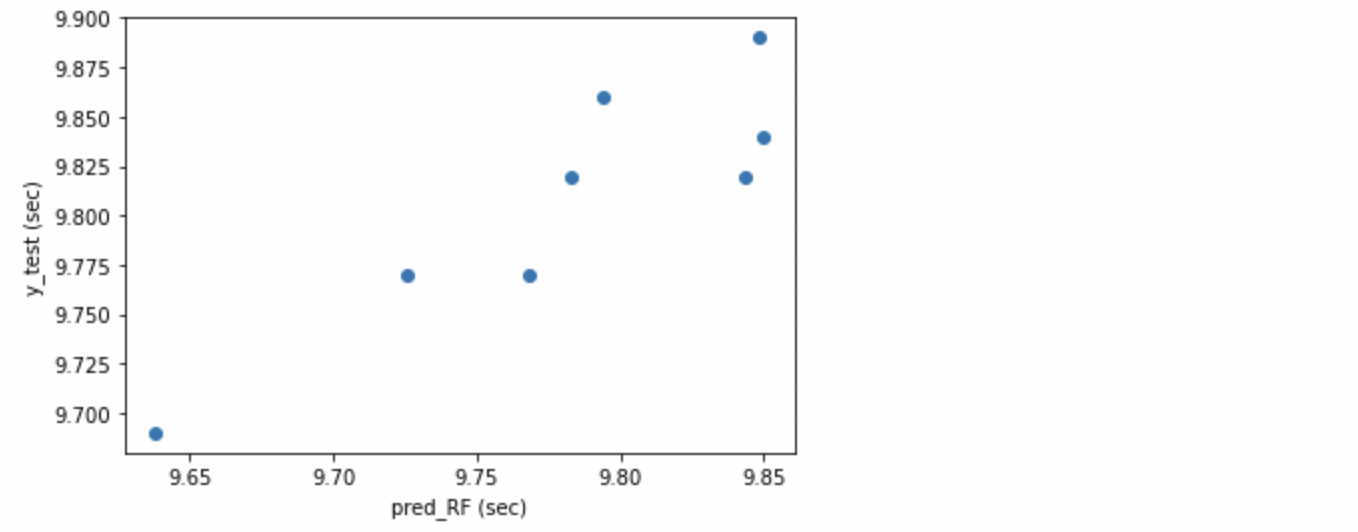
RandomForest の R2 は 0.537 と、可もなく不可もなくほどほどのスコアでした。MAE も 0.035 と悪くない数値となりました。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の RandomForest 回帰の可視化
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
RF2 = RandomForestRegressor(random_state=0)
RF2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], RF2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
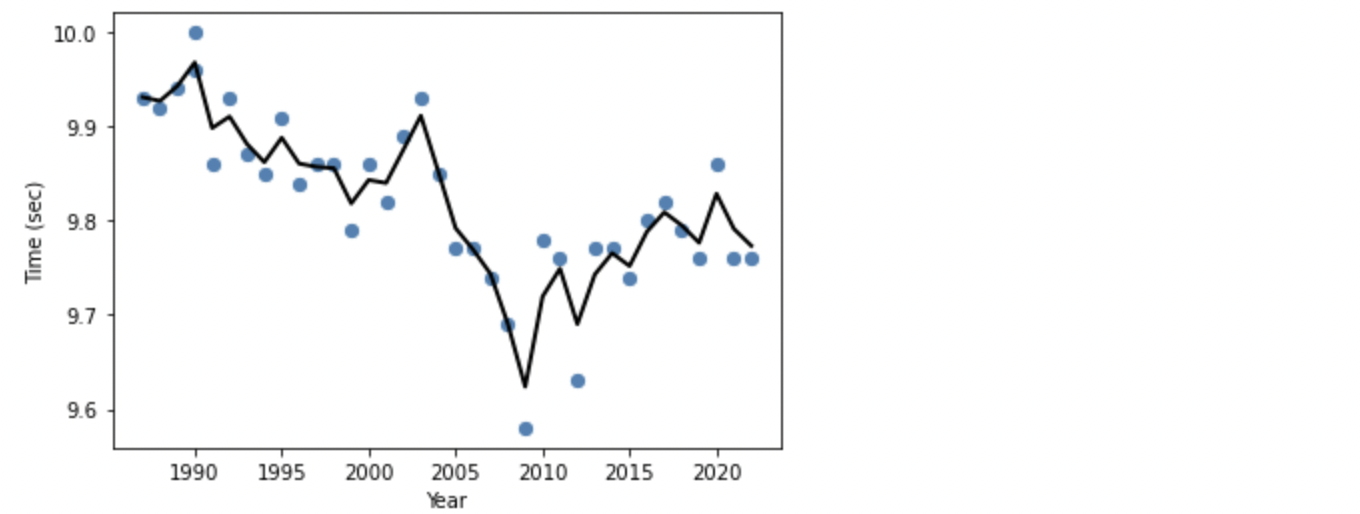
RandomForest の回帰は DecisionTree 系らしい、非線形の線になっています。DecisionTree 系のモデルでは、葉の数や深さなどの設定を調整することで、過学習や学習不足を避け、予測精度を高めます。
g. GradientBoosting
RandomForest はブーストラップによって擬似的に再構成した標本に対して DecisionTree を推定していくものでした。これに対して GrandientBoosting (勾配ブースティング)は何度もDecisionTree を推定していくのは同じですが、ターゲット変数から各 DecisionTree の推定結果を少しづつ引いていき、その残差に対して繰り返し DecisionTree を推定していき、最終的に推定していきます。
モデルの学習
from sklearn.ensemble import GradientBoostingRegressor
# モデルの学習
GBDT = GradientBoostingRegressor(random_state=0)
GBDT.fit(X_train_std, y_train)
# 回帰
pred_GBDT = GBDT.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_GBDT = r2_score(y_test, pred_GBDT)
# 平均絶対誤差(MAE)
mae_GBDT = mean_absolute_error(y_test, pred_GBDT)
print("R2 : %.3f" % r2_GBDT)
print("MAE : %.3f" % mae_GBDT)
# 変数重要度
print("feature_importances = ", RF.feature_importances_)

plt.xlabel("pred_GBDT (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_GBDT, y_test)
plt.show()
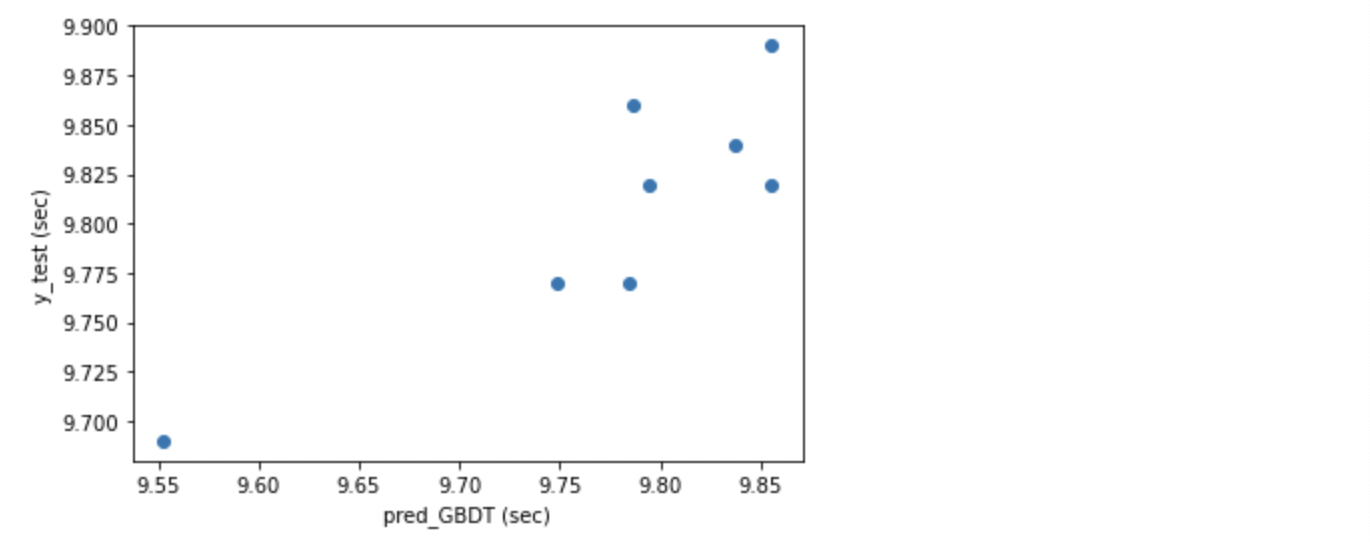
GradientBoostingRegressor の R2 は意外にも、0 を割ってしまいました。MAE 0.043 も良くない数値です。データサイズが小さすぎたのか、うまく学習できませんでした。同じ DecisionTree 系の RandomForest よりもスコアが悪いのは意外でした。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の GBDT 回帰の可視化
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
GBDT2 = GradientBoostingRegressor(random_state=0)
GBDT2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], GBDT2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
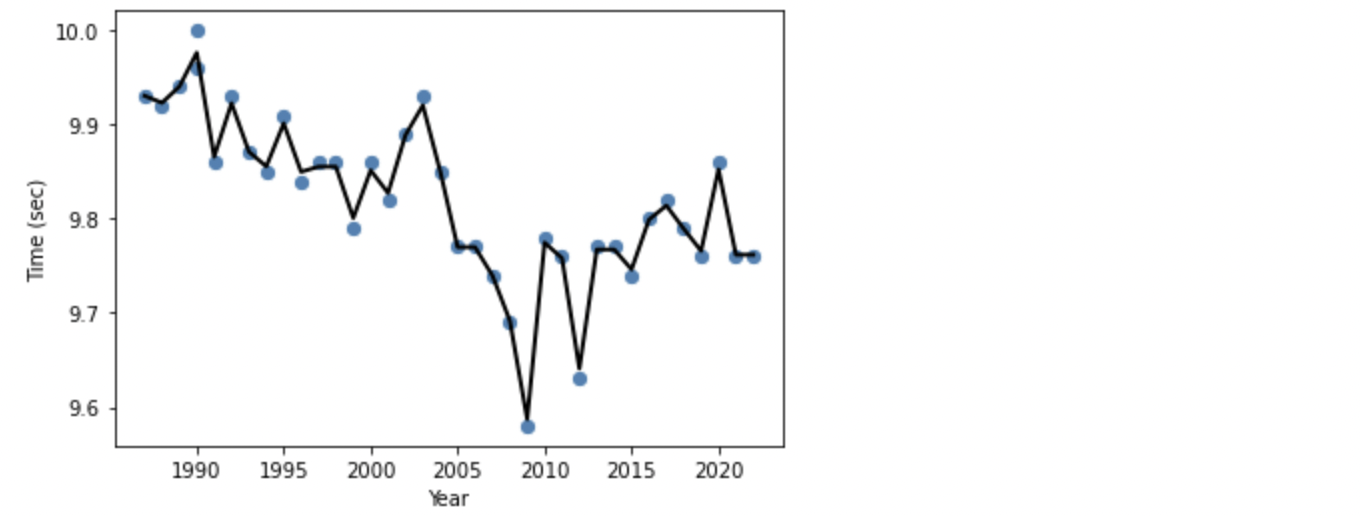
GBDT は RandomForest と同様、DecisionTree 系ですので、RondomForest と似た線になっていますが、GDBT では過剰に適応しているように見えますので、過学習気味になっているようです。Train Data に過剰に適応してしまうと、Test Data や未知のデータでは予測値からの乖離が大きくなってしまいます。
h. LightGBM
これまでに使用してきた回帰モデルは Scikit-learn 内にあるモデルでしたが、LightGBM は Microsoft のスポンサーによって開発されたライブラリです。GDBT や xgboost などの他の勾配ブースティングのモデルよりも軽く(計算が早く)、高性能であると言われており、そのため Kaggle などのコンペでは非常に良く使われています。勾配ブースティング全般の弱点として過学習になりやすいため、深さなどのハイパーパラメーターを適切に調整する必要があります。
モデルの学習
import lightgbm as lgb
# モデルの学習
lgb = lgb.LGBMRegressor(n_estimators=100,learning_rate=0.1,max_depth=-1)
lgb.fit(X_train_std, y_train)
# 回帰
pred_lgb = lgb.predict(X_test_std)
# 評価
# 決定係数(R2)
r2_lgb = r2_score(y_test, pred_lgb)
# 平均絶対誤差(MAE)
mae_lgb = mean_absolute_error(y_test, pred_lgb)
print("R2 : %.3f" % r2_lgb)
print("MAE : %.3f" % mae_lgb)
# 変数重要度
print("feature_importances = ", lgb.feature_importances_)

plt.xlabel("pred_lgb (sec)")
plt.ylabel("y_test (sec)")
plt.scatter(pred_lgb, y_test)
plt.show()
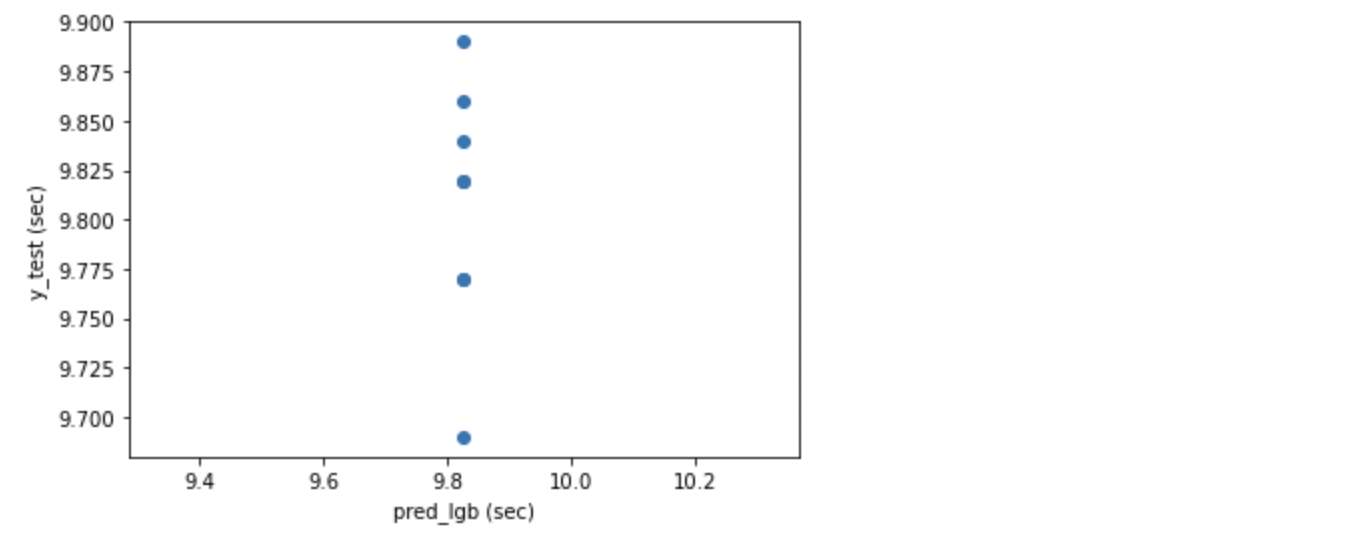
LightGBM もうまく学習できませんでした。
モデルの可視化
# y='Time'、 X='Year' の 2軸で見た場合の LightGBD 回帰の可視化
import lightgbm as lgb
X = df_year_best_time[['Year']].values
y = df_year_best_time['Time'].values
lgb2 = lgb.LGBMRegressor()
lgb2.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], lgb2)
plt.xlabel('Year')
plt.ylabel('Time (sec)')
plt.show()
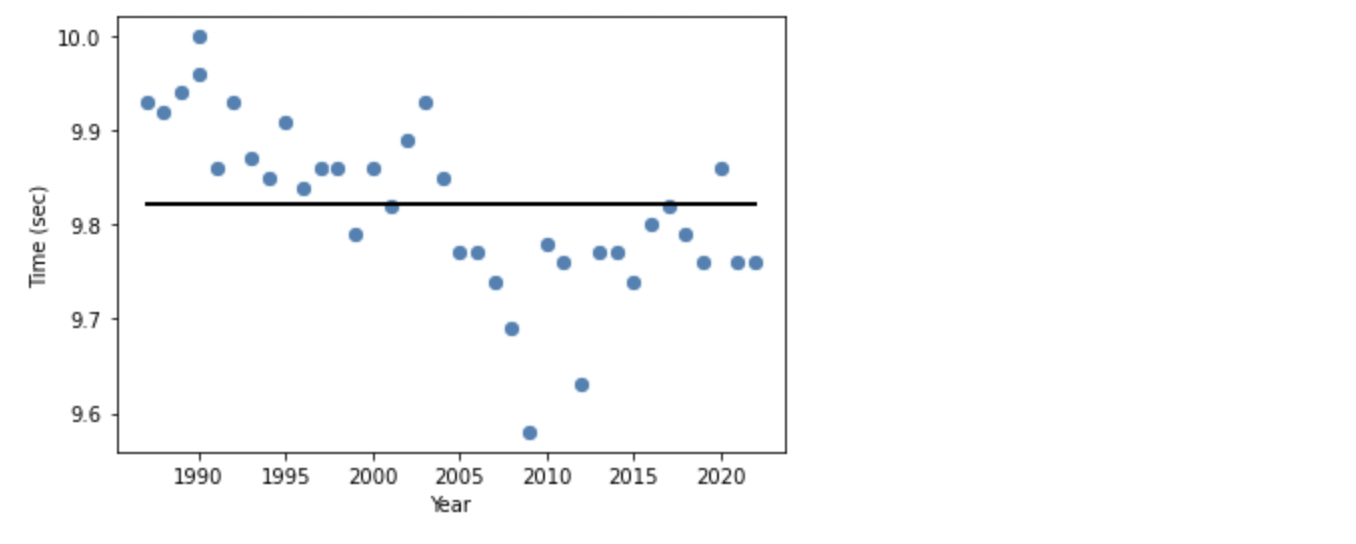
LightGBM ではうまく学習できず、Lasso と同じような傾き 0 の線形回帰となってしまいました。ハイパーパラメーターの設定を調整する必要がありそうです。
3. 未来の記録の予測
さて、ここからは、2. で作成した各回帰モデルを使用して、未来の記録を予測していきます。予測するのは 2030 年と 2050 年とします。
1) 予測のための各パラメーターの設定
問題となるのは、各パラメーターの値ですが、以下のように設定することとします。
- 気象条件(風)と年齢 :
気象条件(風)と年齢は 'df_year_best_time' での平均値とします。これは未来の記録を予測する前提として良くも悪くもない平準的な条件とするためです。
- '10th Time' :
10th Time については、時とともにタイムが向上していきますので単純に平均値とはせずに 'df_year_best_time' を使用して、'10th time' と 'Year' の単回帰から、2030 年と 2050 年の 10 番目のタイムを取得します。
df_year_best_time の各平均値の取得
df_year_best_time.mean()
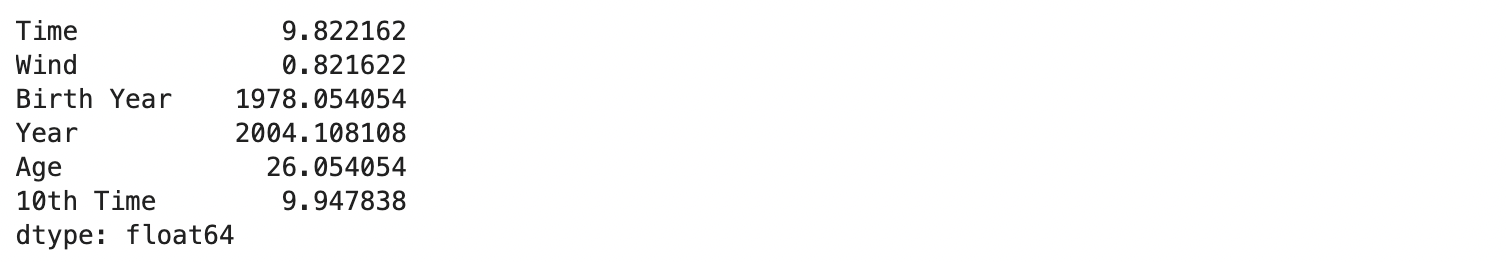
上記より、将来予測で使用する数値として、風は 0.8m、年齢は 26 歳とする。
2030 年と 2050 年の 10th Time の取得(単回帰分析)
import numpy as np
df_year_best_time_10th_time = df_year_best_time.drop\
(['Time','Wind','Birth Year','Age'], axis=1)
df_year_best_time_10th_time
x_10th_time = df_year_best_time_10th_time['Year']
T_10th_time = df_year_best_time_10th_time['10th Time']
# 'ValueError: Expected 2D array, got 1D array instead'を避けるために、
# reshape(-1,1) を使用
X_10th_time = np.array(x_10th_time).reshape(-1,1)
t_10th_time = np.array(T_10th_time).reshape(-1,1)
X_train, X_test, y_train, y_test = train_test_split\
(X_10th_time, t_10th_time, test_size = 0.2,random_state=0)
lr_10th = LinearRegression()
lr_10th.fit(X_train, y_train)
# 2030 年の 10th Time の予想
pred_2030 = [[2030]]
LinerRegression_pred_10th_2030 = lr_10th.predict(pred_2030)
print('Predict 10th time in 2030 : LinerRegression :')
print(LinerRegression_pred_10th_2030)
# 2050 年の 10th Time の予想
pred_2050 = [[2050]]
LinerRegression_pred_10th_2050 = lr_10th.predict(pred_2050)
print('Predict 10th time in 2050 : LinerRegression :')
print(LinerRegression_pred_10th_2050)

上記で取得したデータから、2030 年の 10th Time は 9.82、2050 年は 9.71 とします。
2) 各モデルでの記録の予測
a. LenearRegression
# LinearRegression : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
LinerRegression_pred_2030 = lr.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : LinearRegression :')
print(LinerRegression_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
LinearRegression_pred_2050 = lr.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : LinearRegression :')
print(LinearRegression_pred_2050)

LinearRegression の予測は 2030 年 9.68 2050 年 9.54 となりました。直感的にもまずまず妥当な予測だと思います。ボルトさんが 2009 年に記録した 9.58 は 2050 年近くにならないと到達しないレベルということで、改めてものすごい記録だということがわかります。
b. Ridge
# Ridge : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
Ridge_pred_2030 = ridge.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : Ridge :')
print(Ridge_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
Ridge_pred_2050 = ridge.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : Ridge :')
print(Ridge_pred_2050)

Ridge の予測は 2030 年 9.69 2050 年 9.57 となりました。LinearRegression の予想値に近い数値です。
c. Lasso
# Lasso : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
Lasso_pred_2030 = lasso.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : Lasso :')
print(Lasso_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
Lasso_pred_2050 = lasso.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : Lasso :')
print(Lasso_pred_2050)

d. ElasticNet
# ElasticNet : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
ElasticNet_pred_2030 = elasticnet.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : ElasticNet :')
print(ElasticNet_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
ElasticNet_pred_2050 = elasticnet.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : ElasticNet :')
print(ElasticNet_pred_2050)
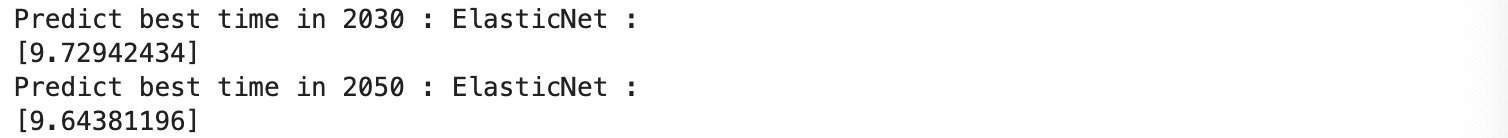
ElasticNet の予測は 2030 年 9.73 2050 年 9.64 となりました。LinearRegresson や Ridge の予想地と比べるとやや遅いタイムとなりました。ElasticNet の予想では 2050 年になってもまだボルトさんの記録に到達することはできません。
e. SVR
# SVR : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
SVR_pred_2030 = SVR.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : SVR :')
print(SVR_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
SVR_pred_2050 = SVR.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : SVR :')
print(SVR_pred_2050)
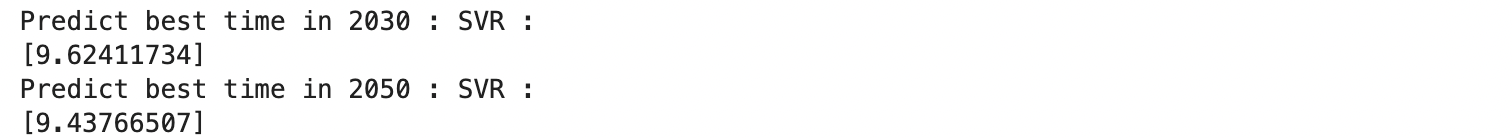
LinearRegression の予測は 2030 年 9.62 2050 年 9.44 となりました。SVR はだいぶ早いタイムを予想しています。特に 2050 年は 9.50 秒を大きく上回る予想となっており、本当にこんなタイムが出たらすごいなと思います。
f. RandomForest
# RandomForest : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
RF_pred_2030 = RF.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : RandomForest :')
print(RF_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
RF_pred_2050 = RF.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : RandomForest :')
print(RF_pred_2050)
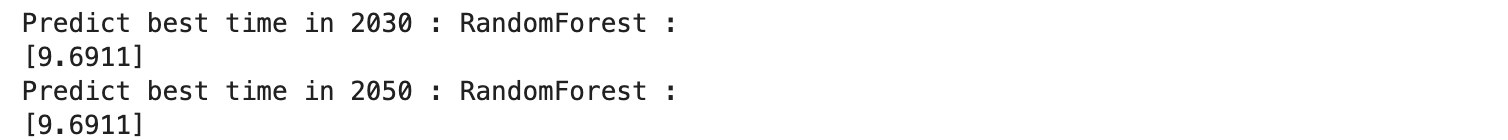
RandomForest は 2030 年と 2050 年の予想値が同じ数値となってしまい、うまく予測できていません。
g. GradientBoosting
# GradientBoosting : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
GBDT_pred_2030 = GBDT.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : GradientBoosting :')
print(GBDT_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
GBDT_pred_2050 = GBDT.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : GradientBoosting :')
print(GBDT_pred_2050)

GBDT も 2030 年と 2050 年の予想値が同じ数値となってしまい、うまく予測できていません。
h. LightGBM
# LightGBM : Best Time Prediction for 2030 and 2050
# Prediction for 2030
pred_2030 = [[0.8, 2004, 2030, 26, 9.82]]
lgb_pred_2030 = lgb.predict(sc.transform(pred_2030))
print('Predict best time in 2030 : LightGBM :')
print(lgb_pred_2030)
# Prediction for 2050
pred_2050 = [[0.8, 2024, 2050, 26, 9.70]]
lgb_pred_2050 = lgb.predict(sc.transform(pred_2050))
print('Predict best time in 2050 : LightGBM :')
print(lgb_pred_2050)

LightGBM も 2030 年と 2050 年の予想値が同じ数値となってしまい、うまく予測できていません。DecisionTree 系のモデルは全てうまく予測できませんでした。
2030 年と 2050 年のタイムが同じだったモデルを除き、うまく予測できたモデルを以下の表にまとめました。
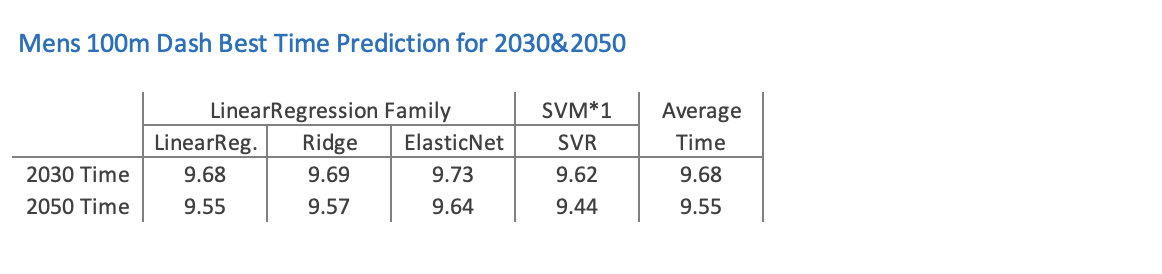
うまく予測できた 4 つの回帰モデルの平均値で見ると、2030 年は 9.68、2050 年は 9.55 となります。LinearRegression の予測はこの平均値と全く同じ数値となりました。Ridge の予測値も平均値とほぼ同等となり、ElasticNet はやや遅いタイム、SVR はやや速いタイムとなりました。
ボルトさんが 2009 年に 9.58 で走った時には、この記録は数十年未来を先取りしていると言われていましたが、今回の回帰分析で見ると、2050 年にようやく 9.55 ですから、本当に 40 年も未来を先取りしていたことになります。
4. まとめ
各回帰モデルのスコア(R2 と MAE)と 2030 年、2050 年の予測タイムをまとめると以下のようになります。
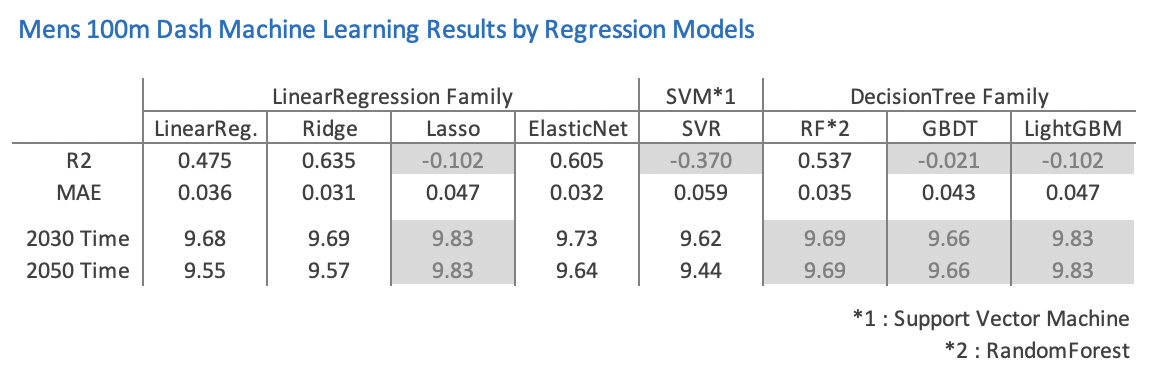
R2 が 0 以下のものと、将来予測で 2030 年と 2050 年の数値が同じものは結果が思わしくないものとしてグレイにしています。
少し意外ですが、RandomForest や LightGBM のような凝ったモデルよりも、線形回帰モデルの方が総じて良い結果となりました。
今回の分析では R2、MAE のスコアから見ると、 Ridge が最も良い成績となりました。
未来の記録の予測では、DecisionTree 系は全てのモデルが 2030 年の予測値と 2050 年の予測値が同じとなってしまい、全滅となりました。
今回は主要な回帰モデルを一通り使用して学習、将来記録の予測を行いました。
さまざまな回帰モデルを扱ったことで、それぞれのモデルの特徴、長所、短所などが見えてきて、非常に興味深かったです。
今回多様な回帰モデルを扱ったため、広く浅い分析となったと思います。Grid Search や Random Search でハイパーパラメーターの設定を追い込んだり、データ前処理の段階で特徴量をいじったりして評価値を上げるような深掘りする作業もしたいところですが、一方でデータのサイズ的にはこれで十分かなとも感じています。今後はより大きなデータを使用して、そうした作り込みの経験も積んでいきたいと考えています。
今回はデータ前処理から、学習したモデルの評価までの機械学習の一通りの流れを実際に体験したわけですが、100m 走の記録の分析が題材ということもあり、非常に楽しく分析を進めることができました。本稿をお読みくださった皆様にもその楽しさが伝わりましたらこれ以上の喜びはありません。最後までお付き合いくださいまして、まことにありがとうございました。