最近,機械学習について勉強したので,Pythonで実装する際にどういった手順で行うかについてまとめておきました
データの前処理
機械学習ではまずデータを読み込んだり,どういった分布をしているのかといったことを知っておく必要があります.その手順について書いていきます
データの読み込み
データを実際に読み込むために,先程読み込んだpandasのread_csvというメソッドを使いcsvファイルを読み込みます
# ライブラリの読み込み
import pandas as pd
import numpy as np
# 直下にあるhoge.csvを読み込む
df = pd.read_csv("./hoge.csv")
# 上から5行のみを取り出す
df.head()
読みこんだデータの確認
機械学習というと,データを突っ込めばなんとかしてくれるというイメージがありますが実際にはデータをしっかり見る必要があります
例えば,欠損値がないかやバラつきが大きすぎないか,相関があるかといったことです
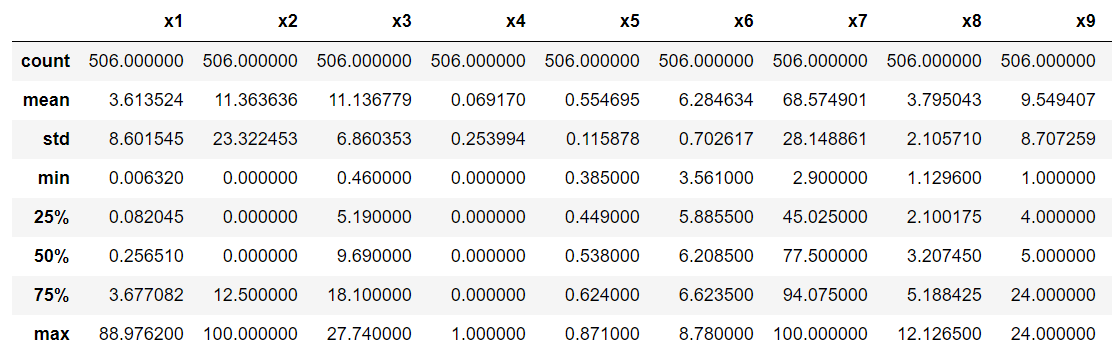
基本統計量
以下のコードを入力することで,データの数,平均値,標準偏差,最小値,最大値といったものが一気にわかります
# 統計量の算出
df.describe()
こんな感じで基本統計量が一覧でわかります
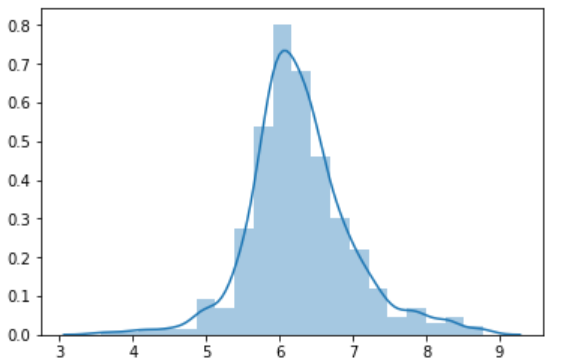
分布の確認
といっても標準偏差や平均値といった数字を見るだけではわかりづらいので,グラフにしたほうが人間にとってはわかりやすいです そのため分布を表します
%matplotlib inline
# seabornというグラフを表示するライブラリの読み込み
import seaborn as sns
# 分布の確認
sns.distplot(df["x1"]) #先にデータを確認する(ここでは列x1のデータを確認)
これはデータが正規分布に従っていそうなのでいい感じのデータです
相関係数の確認
もし全く相関関係のないデータであれば,学習させたところで意味はないので相関係数を確認します.ちなみに相関係数は-1から+1の間で,高ければ高いほど相関があるということになります
# 相関係数の算出
df.corr()
# 相関係数をグラフで確認
sns.pairplot(df)
入力変数と出力変数の切り分け
実際には$ y = w0x0 + w1x1 + w2x2 +...+$というようなものを作るわけなので,データの中身を出力変数であるyと入力変数であるxに分ける必要があります
その際に使うのがpandasのilocというメソッドです
# df.iloc[行,列]とすることでその行と列のデータを取り出せる
例 example = df.iloc[1,3]
結果 100
# 最後の列-1まですべての行を取り出す(入力変数X)
X = df.iloc[:,:-1]
# こう書いてもいいが汎用性は低い
X = df.iloc[:,:最後の列番号]
# yを取り出す
y = df.iloc[:,-1]
前処理したデータを使って機械学習をする
上の作業をすることで機械学習を実際に行う下準備はできました.次から実際に学習を行っていきます.ここでは機械学習ライブラリのscikit-learnを使います.
訓練データと検証データに分ける
機械学習を行う目的はデータを学習させ,未知のデータを入れたときに予測するというものでした つまり,学習に用いたデータは使わないということです
当たり前ですが,学習に用いたデータを入れて予測を行えば,そのデータで学習したんだから,正確な答えが出るよね?ってことになります
そのため,学習をさせる前に訓練データ(train)と検証データ(test)に分ける必要があります
from sklearn.model_selection import train_test_split
# 訓練データと検証データの分割
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)
testsizeは訓練データと検証データの割合を指定しており,ここでは学習:訓練=6:4としています またrandom_stateは固定にすることで再現性を保っています
モデル構築・検証
scikit-learnを使えば以下のコードのみでモデルの構築から検証まで行えます
今回学習に使うモデルは重回帰分析です
# ライブラリのインポート
from sklearn.linear_model import LinearRegression
# モデルの宣言(LinearRegressionは重回帰分析という意味)
model = LinearRegression()
# モデルの学習(パラメータの調整をする)
model.fit(X,y)
# パラメータの確認
model.coef_
# 決定係数(予測の精度)0~1の間で高いほどいい
model.score(X,y)
# 予測値の計算
x = X.iloc[0,:] #Xの一行目を取り出し
y_pred = model.predict([x])
モデルの保存・読み込み
モデルの保存は以下のコードで出来ます
# インポート
from sklearn.externals import joblib
# モデルの保存(hoge.pklという名前で保存
joblib.dump(model,"hoge.pkl")
モデルの読み込みは以下のコードで行います
# hoge.pklの読み込み
model_new = joblib.load("hoge.pkl")
# 読み込んだモデルの予測値を表示
model_new.predict([x])[0]
以上が機械学習の基本的な流れになっています 今回はモデルを重回帰分析で行いましたが,例えばロジスティック回帰で行いたいとかSVMで行いたいといった時も基本的な流れは同じです