はじめに
本記事では、AI platform上に作ったMLの学習・予測基盤の監視を簡単に行う方法を紹介します。
監視のために新たにサーバーを立てたりライブラリを入れたりすることなく、最低限の監視をサクッとやりたい時向けの内容です。
この記事で紹介する手法での監視対象は以下のものになります。
学習時
- AI platform pipelinesのRunの開始・終了
- AI platform training内で吐き出したログから作った各種メトリクス
- データ内のユニークユーザー数や処理時間等
予測時
- AI platform predictionで作った予測サーバーのエラー
- AI platform predictionで作った予測サーバーのレイテンシ
- AI platform predictionで作った予測サーバーのCPU使用率、メモリ使用率
上記のものを監視する仕組みをgoogle cloud loggingやgoogle cloud monitoringを使って構築していきます。
AI platformとは
AI platformはgoogle cloudのサービスの一つで、MLモデルの学習パイプラインやモデルのサービング機能を提供しています。
AI plafformを利用しての学習パイプライン構築やモデルのサービング方法の詳細については他の記事や公式ドキュメントを参照いただければと思います。
本記事では以下のような構成でAI platformを使ってML基盤を構築している状況を想定しています。
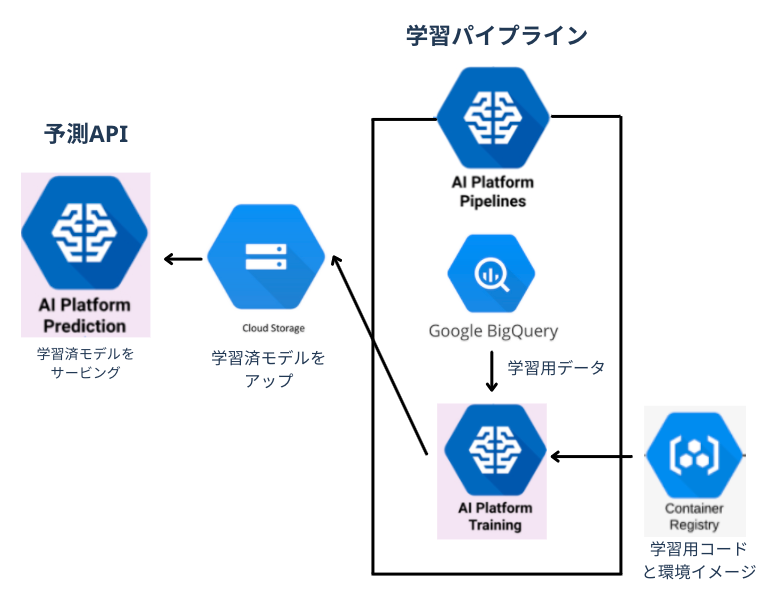
- 学習時
- AI platform pipelinesを使って学習パイプラインを構築
- 学習そのものはAI platform trainingの独自container実行機能で行っている
- 予測時
- AI platform predictionを使い、AI platform trainingで学習したモデルをサービング
学習時の監視
AI platform pipelinesのRunの開始・終了
1.cloud loggingにて「ログベースの指標」を作成
-
指標タイプはCounterに設定
-
単位は1に設定
-
フィルタの指定は以下
resource.type="k8s_cluster" resource.labels.location="<kubernetesクラスタがあるリージョン>" resource.labels.cluster_name="<kubernetesクラスタ名>" log_name="projects/<プロジェクト名>/logs/events" jsonPayload.involvedObject.name=~"^<パイプライン名>.*$" -
ラベルは以下
-
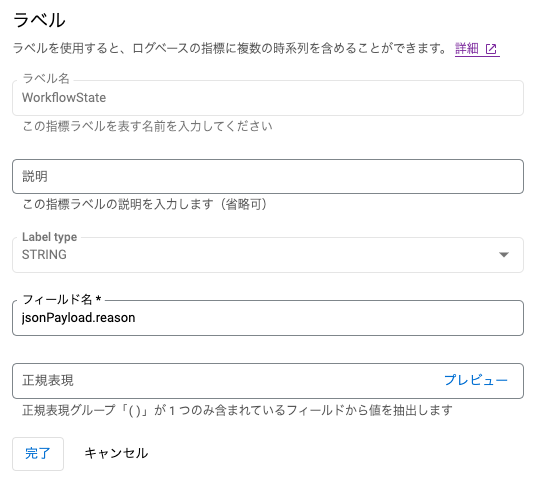
上記のようにログベースの指標を作成することで、特定のパイプラインが走った際に、WorkflowFailed,WorkflowRunning,WorkflowSucceededといったイベントを取得できるようになります。step2でこれらの状態をslackに通知する設定を行います。
また、ログのフィルタの設定は各自の環境に合わせて変更して下さい。
2.cloud monitoringにてslack通知を設定
- monitoring filterは
metric.type="logging.googleapis.com/user/<1で作ったログベースの指標名>" - Transform dataは状況に合わせてよしなに設定。自分は以下のようにしています。
- ローリングウィンドウ:1分
- ローリングウィンドウ関数:delta
- 時系列集計:none
- alert trigger
- Condition type:threshold
- alert trigger:任意の時系列の違反
- しきい値の位置:しきい値より上
- しきい値:0
- slackの通知先チャンネルはよしなに設定下さい
- documentationを以下のようにしておくと、slackにどのワークフローがどのような状態になったかが通知されます
ワークフロー名:${metric.display_name}
ワークフローの状態:${metric.label.WorkflowState}
slackでの見え方
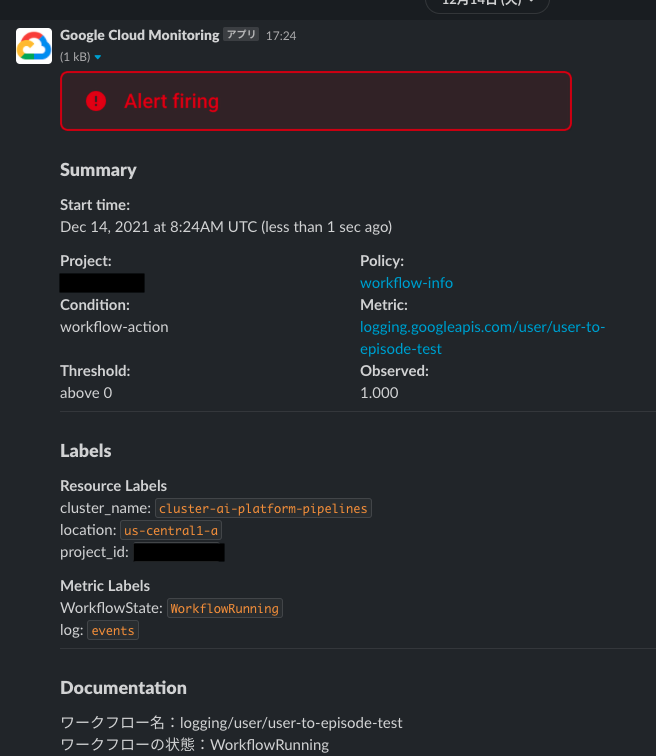
こちらはパイプラインがキックされた時に来る通知です。ワークフローが失敗したらWorkflowStateがWorkflowFailed,成功したらWorkflowSucceededと表示されます。
ただ、ここまで紹介しておいてなんなのですが、この方法でのslack通知は微妙な点があります。
ワークフローの開始、失敗、成功を判別するのがWorkflowState欄しか無いので一見してどの通知なのかがわからなかったり、ワークフローの開始イベントもincidentとして記録されてしまいます。ワークフロー開始、成功の通知を流すチャンネルと、失敗時だけ通知を流すチャンネルを作るなどした方が見やすいです。
時間があれば自前でslack通知機能を実装して、ワークフロー内からキックするほうが良いかも知れません。
AI platform training内で吐き出したログから作った各種メトリクス
学習の成否に関わるようなメトリクスをログに書き出しておき、ダッシュボードから確認したり必要があればアラートを設置する方法です。メトリクスは、例えばデータの量や分布を想定しています。
1.AI platform trainingで動かすコード内で、必要なデータを構造化ログの形で出力するようにしておく
AI platform trainingは何もしなくても標準出力・標準エラー出力をcloud loggingに吐き出していますが、そのままだとログが構造化されておらず、検索がしづらいです。そのため、構造化した状態でログを吐いておく必要があります。
構造化ログの吐き出し方は公式ドキュメントを参照下さい。
本記事では以下のように構造化ログを吐いています。
client = google.cloud.logging.Client()
client.setup_logging()
logger = client.logger("<ログ名>")
logger.log_struct({"name": "ユニークユーザー数", "value": unique_user_ids.size})
2.1の構造化ログを拾う、分布ベースのログベース指標を作成
-
指標タイプはDistributionに設定
-
フィルタの指定は以下
logName="projects/<プロジェクト名>/logs/<ログ名>" jsonPayload.name="ユニークユーザー数" -
フィールド名:
jsonPayload.value
3.2のログベース指標をcloud monitoringでダッシュボード化
ダッシュボード化の方法は公式ドキュメントを読めばわかるかと思います。以下画像のように、2で作成したmetricを指定してグラフ化します。
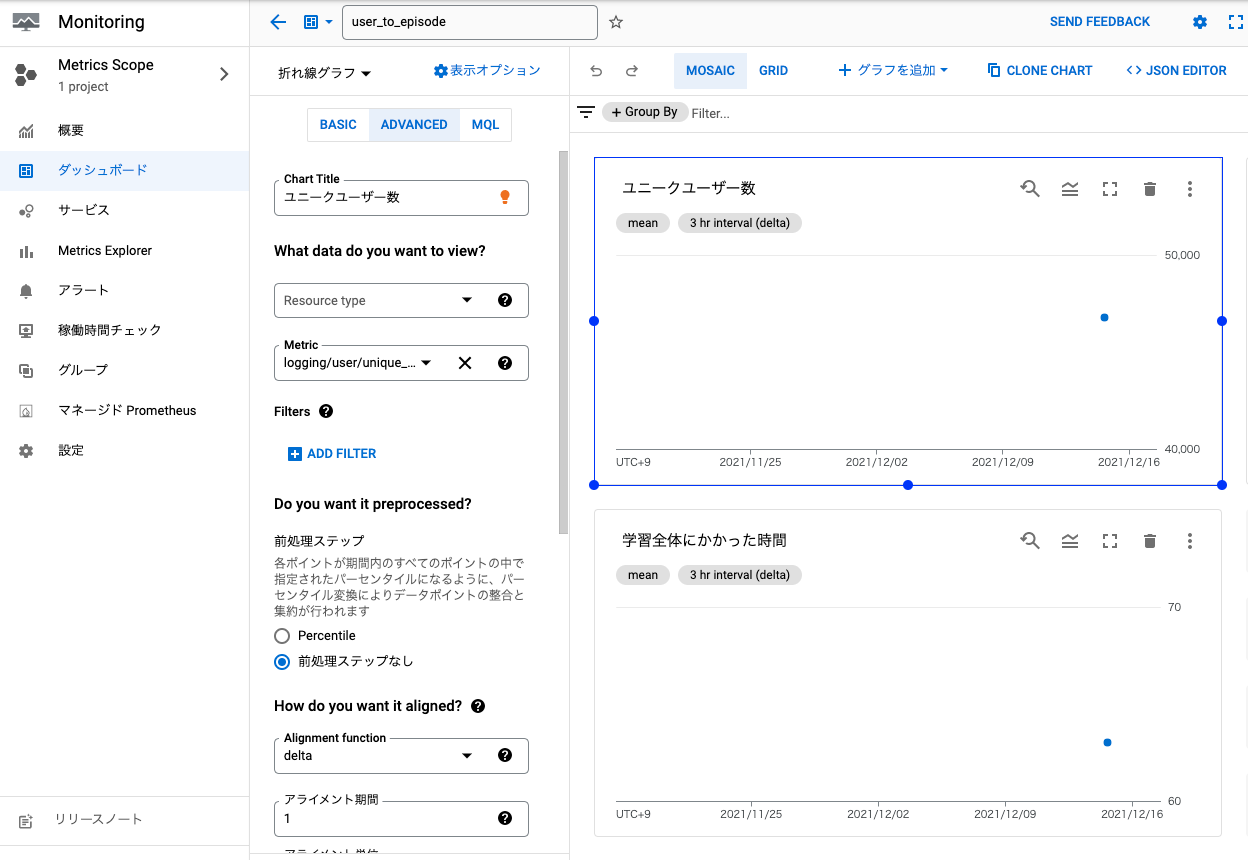
(4.slack通知の設定)
AI platform pipelinesのRunの開始・終了と同様に、cloud monitoringを使ってアラートを設定できます。ユニークユーザー数が一定以上に増えたらアラート発出、といった形です。
予測時の監視
予測時の監視はAI platform predictionを使っている場合は非常に楽です。AI platform側でエラーやレイテンシを取得するメトリックを既に用意してくれているので、cloud monitoringを使ってダッシュボードを作ったりアラートを設定するだけで済みます。
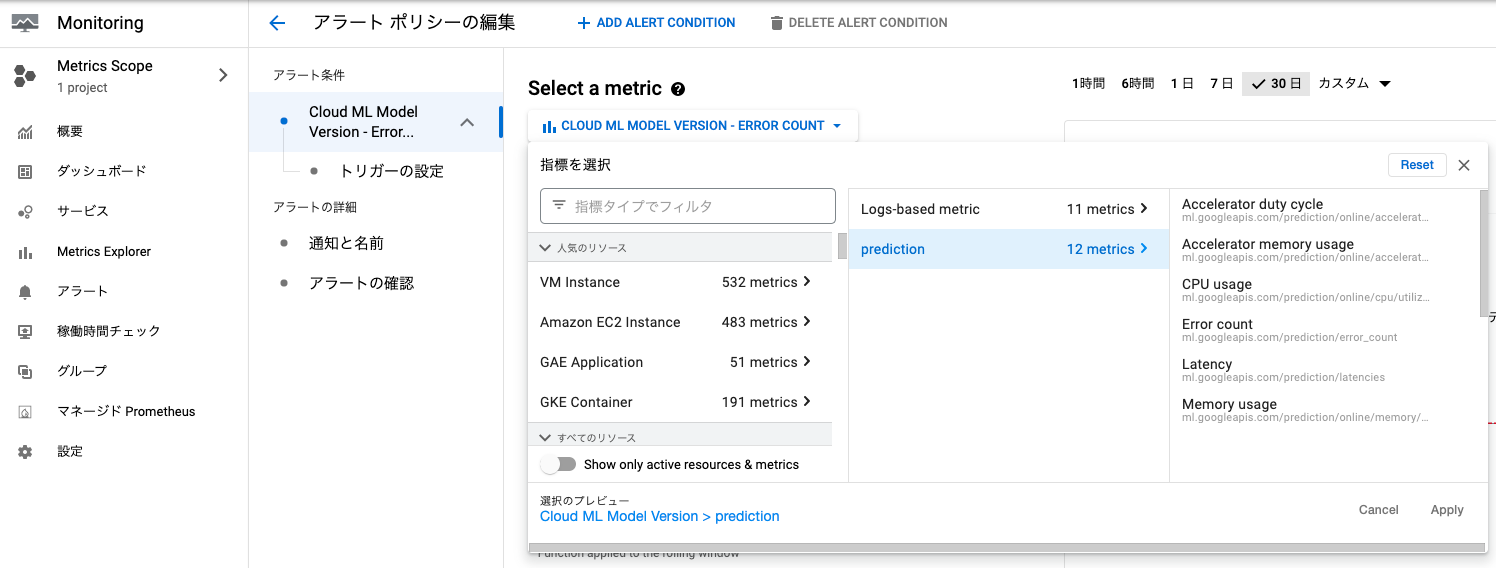
アラートポリシーの設定をする際、cloud ml model version > predictionからgoogle cloud側で用意しているメトリックを選択できます。
CPU usageやError count,Latency等を選択できるので、アラートを設定したいメトリックを選びます。後はAI platform pipelinesのRunの開始・終了の通知と同様に、条件や通知先チャンネルを指定するだけです。
特にレイテンシ監視が便利で、latency typeがいくつか用意されており、インスタンス立ち上げオーバーヘッドや通信時間のみのレイテンシを見ることもできます。
おしまい
本記事では簡易的にML基盤の監視をする方法を書きました。本格的にML基盤を運用していく場合はもっとしっかりした監視基盤を作った方が良い気はしますが、そこまで工数が割けない場合はcloud logging,monitoringでサクッと作ってしまうのも良いかと思います。ご参考になれば幸いです。