等高線を書きたい
いくつかの地点の標高データが手元にあるとします。
人間であればそのデータを基になんとなく等高線図を書けると思います。
この「何となく等高線図を書く」という作業をpythonで出来ないかトライしてみました。
結論からいうとこの記事では__うまくいってません__ので、コードや方針を参考にする程度にとどめておいてください。
方針
- 手元データの位置情報(経度&緯度)から標高データを予測する機械学習モデルを作る。
- その後、データの無い地点での標高を機械学習モデルで予測を行い網羅的に取得する。
- 取得したデータを等高線図に直す
実装こまごま
データの作製
今回は中部地方付近の地理データをここのサイトとここのサイトから作りました。
geo.xlsxの中身はこんな感じ。xが経度、yが緯度、zが標高を表しています。
こう見ると長野って抜群に標高高いんですね。
データの読み込み&説明変数の複製
read_excelでデータを読み込んだのち、説明変数同士の積和を取るなどして説明変数を増やします。
今回はlinear regressionを利用し線形な近似しか行う方針でいきますが、x2やx3のデータを増やすことでより複雑な近似曲面の取得を試みます。
今回は二次の曲面で近似してみます。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 説明変数を増やす関数
def arrange(df):
df["x2"] = df["x"]*df["x"]
df["xy"] = df["x"]*df["y"]
df["y2"] = df["y"]*df["y"]
return df
# データの読み込み
df = pd.read_excel("geo.xlsx")[["x","y","z"]]
df = arrange(df)
この処理で、データはこうなります。三次・四次の場合もやってみたので後ほど結果だけ示しますね。
線形回帰で学習
手元のデータを利用して、線形回帰モデルの学習を行います。
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
X = df.drop(["z"],axis=1).values # 説明変数(Numpyの配列)
Y = df['z'].values # 目的変数(Numpyの配列)
lr.fit(X, Y) # 線形モデルの重みを学習
データの無い地点の標高を予測
データの無い場所についてはこの学習モデルを利用して標高を予測します。
データの無い地点の経度と緯度を網羅的に定義して、予測するためのデータを用意します。
x = np.round(np.arange(135, 140, 0.05),decimals=4) # x軸 135から140まで0.05ずつ100地点
y = np.round(np.arange(34, 38, 0.04),decimals=4) # y軸 34から38まで0.04ずつ100地点 ⇒合計100×100の10000地点
X, Y = np.meshgrid(x, y)
data = pd.DataFrame([])
for _x in x:
for _y in y:
data = pd.concat([data, pd.Series([_x,_y])],axis=1)
dataの中身はこんな感じ。

あとはこのデータから学習データ同様に説明変数を増やします。
input_df = data.T
input_df.columns = ["x","y"]
input_df = arrange(input_df)
input_dfの中身はこんな感じ。
そしてこのデータを説明変数として標高を予測し、等高線に起こすだけです。
# 予測
pred_z = lr.predict(input_df)
pred_z_resh = pred_z.reshape(100,-1)
x = np.round(np.arange(135, 140, 0.05),decimals=4) # x軸
y = np.round(np.arange(34, 38, 0.04),decimals=4) # y軸
X, Y = np.meshgrid(x, y) #等高線を書く舞台を作る
Z = pred_z_resh #標高データ
cont = plt.contour(X,Y,Z,colors=['r', 'g', 'b']) #舞台に標高データを一個一個入れていく
cont.clabel(fmt='%1.1f', fontsize=14)
plt.gca().xaxis.get_major_formatter().set_useOffset(False) #横軸の表記をa×e^nにしない
plt.gca().yaxis.get_major_formatter().set_useOffset(False) #縦軸の表記をa×e^nにしない
plt.xlabel('X', fontsize=14)
plt.ylabel('Y', fontsize=14)
plt.show()
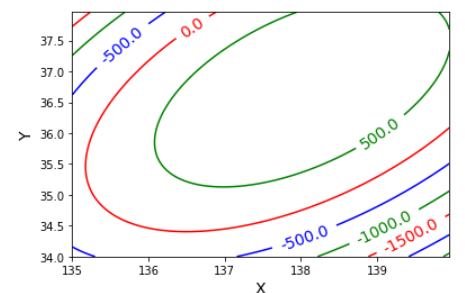
その結果がこちら。
やっぱり単純なモデルなだけあって標高マイナス値とか出ちゃってますね。
三次や四次の場合
三次や四次の場合もやってみました。
三次の場合は、
# 説明変数を増やす関数
def arrange(df):
df["x2"] = df["x"]*df["x"]
df["xy"] = df["x"]*df["y"]
df["y2"] = df["y"]*df["y"]
df["x3"] = df["x"]*df["x"]*df["x"]
df["x2y"] = df["x"]*df["x"]*df["y"]
df["xy2"] = df["x"]*df["y"]*df["y"]
df["y3"] = df["y"]*df["y"]*df["y"]
return df
四次の場合は、
def arrange(df):
df["x2"] = df["x"]*df["x"]
df["xy"] = df["x"]*df["y"]
df["y2"] = df["y"]*df["y"]
df["x3"] = df["x"]*df["x"]*df["x"]
df["x2y"] = df["x"]*df["x"]*df["y"]
df["xy2"] = df["x"]*df["y"]*df["y"]
df["y3"] = df["y"]*df["y"]*df["y"]
df["x4"] = df["x"]*df["x"]*df["x"]*df["x"]
df["x3y"] = df["x"]*df["x"]*df["x"]*df["y"]
df["x2y2"] = df["x"]*df["x"]*df["y"]*df["y"]
df["x1y3"] = df["x"]*df["y"]*df["y"]*df["y"]
df["y4"] = df["y"]*df["y"]*df["y"]*df["y"]
return df
となります。
書いた等高線は三次の場合は
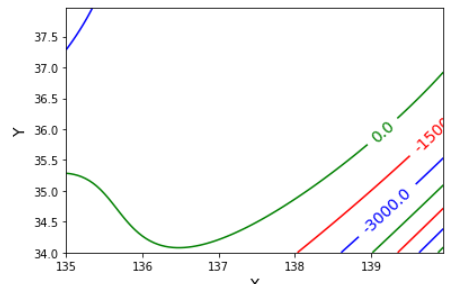
四次の場合は
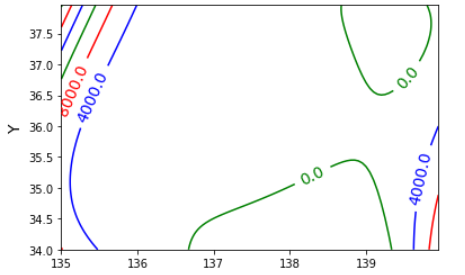
となりました。
三次の方は相変わらず海の底に沈んだ場所がありつつ。
四次の方は山が二個あってそれっぽいと思いきや、実は谷になってたり。
次はRandomForestあたりでやってみても面白いかも。
最後に
等高線書くだけなのに意外と難しくてびっくり。
是非トライしてみてくださいね。