はじめに
一人暮らしを始めてからというものの、読書が趣味になりました。
家には本棚が6か所あり、そのどこに何の本があるかをしりたくなったので、書籍管理line bot作ってみました。line botベンリィ
完成イメージ
写真をアップロード⇒本の登録
本情報の手打ちはしんどいなあと思ったので、本の写真アップロードで代用。
背表紙にあるISBN番号をOCRで読み取って、Google Books APIで書籍情報を呼び出します。
「これ登録しますけどどの棚に入れますか~」と聞かれるので、棚番号を応えて登録。
登録済のものについては※で忠告を出しておきます。
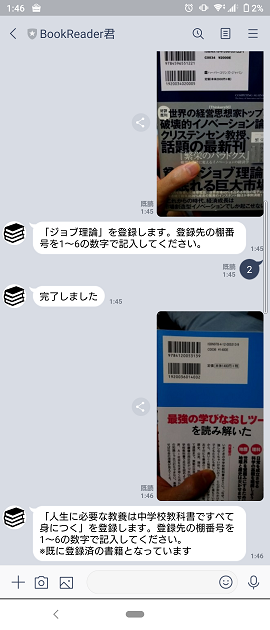
検索 (本の名前)⇒本の検索
「検索」(スペース)(本の名前の一部)とすると、その言葉を含む本がどの棚になるかを教えてくれます。複数の場合も対応、該当がない場合は該当するものがないよ、と言ってくれます。
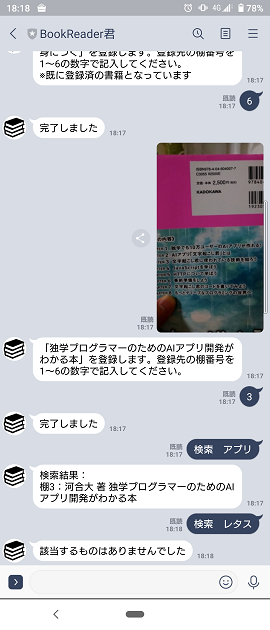
スタンプ⇒キレる
スタンプに対しては厳しめの対応です。
そりゃあ書籍管理botだもんね。
スタンプなんて意味わかんないよね。

スタンプかわいい
全体構造
本の登録
ざくっとした流れは
①写真アップロード
②cloud functionsが写真をcloud vision APIへ。写真内の文字を読み取る。
③cloud functionsでISBN番号を取り出し、google books APIへ。書籍情報を取得。
④cloud functionsからgoogle apps scriptに書籍情報を送り、スプレッドシートに入力。
となっています。
直接GASとやり取りすればいいじゃんと思った人もいると思います。
その通りです(作ってる最中に思いました)。
その通りなんです。。。クソウセッカクツクッチャッタカラ
本の検索
こちらの処理は
①検索_(書籍名の一部) と送る
②cloud functionsがgoogle apps scriptへ受け流す
③google apps scriptでスプレッドシート内の検索処理
④cloud functions経由でlineへ返す。
となっています。
GASメインの処理ですね。いよいよcloud functionsなぜ使った感。
見切り発車でcloud functionsを起動したのが仇でしたね。。。
だからline botとGASつなげればいいじゃんとか言わないでやめて石投げなry
サンプルコード
Cloud Functions
line botがpostする先の処理になります。
基本的にはpost内容に応じて処理を変えるようになっています。
言語はpythonで書いております。
import os
import base64, hashlib, hmac
import logging
import requests
import json
import re
import base64
import urllib.request
from flask import abort, jsonify
from linebot import (
LineBotApi, WebhookParser
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage
)
def main(request):
#環境変数から各トークンの取得
channel_secret = os.environ.get('LINE_CHANNEL_SECRET')
channel_access_token = os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')
#botインスタンス
line_bot_api = LineBotApi(channel_access_token)
parser = WebhookParser(channel_secret)
#lineから運ばれてきたデータ
body = request.get_data(as_text=True)
#認証周り
hash = hmac.new(channel_secret.encode('utf-8'),
body.encode('utf-8'), hashlib.sha256).digest()
signature = base64.b64encode(hash).decode()
if signature != request.headers['X_LINE_SIGNATURE']:
return abort(405)
try:
events = parser.parse(body, signature)
except InvalidSignatureError:
return abort(405)
#内容に応じて分岐
for event in events:
#メッセージタイプに応じて処理を変化
message_type = event.message.type
response_text = ""
print(event)
#テキストの場合、検索か棚番号
if message_type == "text":
#テキストの内容を取得
message_text = event.message.text
message_list = message_text.split()
message = message_list[0]
#検索の場合
if message == "検索" and len(message_list) >= 2:
body = {"mode":"search","target":message_list[1]}
res = send_to_GAS(body)
response_text = res["content"]
#数値の場合(写真を挙げた後の棚番号)
elif message in ["0","1","2","3","4","5","6"]:
body = {"mode":"int", "int":message}
res = send_to_GAS(body)
print(res)
response_text = res["content"]
#その他
else:
response_text = "本の背表紙のアップロードをするか、\n「検索(スペース)(本の名前の一部)」で検索してください"
#写真の場合、本の登録
elif message_type == "image":
#写真取得
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
#OCRで文字を取得
res_json = vision_api(message_content)
try:
#文字からISBN番号を取得
res = res_json['responses'][0]['textAnnotations'][0]['description']
num = extractISBNNumbers(res)
#ISBN番号から書籍を特定し一時保存
info_json = searchBooksFromISBN(num)
res = send_to_GAS(info_json)
#登録済の場合、警告を足す
addition = ""
if res["content"] >= 1:
addition = "\n※既に登録済の書籍となっています"
else:
pass
#確認レスポンス
response_text = "「"+info_json["book"]["title"]+"」を登録します。登録先の棚番号を1~6の数字で記入してください。"+addition
except KeyError:
print('画像の品質が悪いようです')
#スタンプはキレる
elif message_type == "sticker":
response_text = "は???????"
#その他はキレない
else:
response_text = "本の背表紙のアップロードをするか、\n「検索(スペース)(本の名前の一部)」で検索してください"
#lineに返信
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=response_text))
return jsonify({ 'message': 'ok'})
# 共通method
# Google Apps ScriptとJSONのやり取りをする処理
def send_to_GAS(info_json):
#基本パラメータ
url = (Google Apps ScriptのURL)
headers = {"Content-Type": "application/json"}
#引数の内容をdumpsしてPOST
body = json.dumps(info_json).encode("utf-8")
post_request = urllib.request.Request(url, data=body, method="POST", headers=headers)
#レスポンスをdictにparse
with urllib.request.urlopen(post_request) as response:
response_binary = response.read().decode("utf-8")
response_dict = json.loads(response_binary)
return response_dict
# ここから先は写真に対する処理
# 取得した写真をcloud visionへ送って文字取得
def vision_api(image_content):
#基本パラメータ
GOOGLE_CLOUD_VISION_API_URL = 'https://vision.googleapis.com/v1/images:annotate?key='
API_KEY = (cloud visionのAPI KEY)
api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY
#画像データをエンコード
image_base64 = base64.b64encode(image_content.content).decode('utf-8')
#POSTするJSONの用意
req_body = json.dumps({
'requests': [
{
'image': {
'content': image_base64
},
'features': [
{
'type': 'TEXT_DETECTION',
'maxResults': 1,
}
]
}]
})
res = requests.post(api_url, data=req_body)
return res.json()
# 取得した文字列からISBN番号を取得
def extractISBNNumbers(words):
#ISBNが始まる文字の番号を取得し、そこから多めにとる
startLetterNumber = words.find('ISBN')
endLetterNumber = startLetterNumber + 21
ISBN_Number = words[startLetterNumber:endLetterNumber]
#数値のみ取り出す
number = re.sub("\\D", "", ISBN_Number)
if len(number)==13 or len(number)==10:
return number
else:
print('ISBNナンバーが読み取れません')
return 'null'
# 取り出したISBN番号を利用して書籍情報を取得
def searchBooksFromISBN(num):
#基本パラメータ
API_URL = 'https://www.googleapis.com/books/v1/volumes?q=isbn:'
FULL_API_URL = API_URL + num
res = requests.get(FULL_API_URL).json()['items'][0]
#取得したデータ
title = res['volumeInfo']['title']
authors_list = res['volumeInfo']['authors']
authors_str = ''
for author in authors_list:
authors_str += author + ' '
#returnするデータ
res = {"mode":"input","book":
{
"box_num":"box1",
"title":title,
"authors":authors_str
}}
return res
Cloud Functionsこまごま
環境変数から取得
# 環境変数から各トークンの取得
channel_secret = os.environ.get('LINE_CHANNEL_SECRET')
channel_access_token = os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')
cloud functionsで環境変数に設定したものを取り出す処理です。
今回初めて知ったので備忘録的にメモさせてください。
QiitaとかGitHubに上げるときとかに、いちいちマスキングする必要がなくなるので便利そうですね。
参考:(https://qiita.com/spre55/items/da2ded18ac4652abb936)
Cloud Vision APIへのPOST処理
# 取得した写真をcloud visionへ送って文字取得
def vision_api(image_content):
#基本パラメータ
GOOGLE_CLOUD_VISION_API_URL = 'https://vision.googleapis.com/v1/images:annotate?key='
API_KEY = 'Cloud VisionのAPI Key'
api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY
#画像データをエンコード
image_base64 = base64.b64encode(image_content.content).decode('utf-8')
#POSTするJSONの用意
req_body = json.dumps({
'requests': [
{
'image': {
'content': image_base64
},
'features': [
{
'type': 'TEXT_DETECTION',
'maxResults': 1,
}
]
}]
})
res = requests.post(api_url, data=req_body)
return res.json()
こちらがCloud Vision APIを叩く際の処理。
base64エンコードをしたり、jsonでdumpsするなどのお作法の実装に苦労しました。
テキスト検出がこんなに簡単にできるなんて便利な時代ですよね。
参考:https://qiita.com/atomyah/items/25db0c9c2ecd319218df
参考:「独学プログラマーのためのAIアプリ開発がわかる本」https://www.amazon.co.jp/%E7%8B%AC%E5%AD%A6%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9E%E3%83%BC%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AEAI%E3%82%A2%E3%83%97%E3%83%AA%E9%96%8B%E7%99%BA%E3%81%8C%E3%82%8F%E3%81%8B%E3%82%8B%E6%9C%AC-%E6%B2%B3%E5%90%88-%E5%A4%A7/dp/4046040076
Google Books APIへのPOST処理
# 取り出したISBN番号を利用して書籍情報を取得
def searchBooksFromISBN(num):
#基本パラメータ
API_URL = 'https://www.googleapis.com/books/v1/volumes?q=isbn:'
FULL_API_URL = API_URL + num
res = requests.get(FULL_API_URL).json()['items'][0]
ISBNさえ手に入れば、書籍情報の引っこ抜きはお手軽にできるようです。
authorsやtitle以外の情報も何かに使ってみたいところ。
自分の読む本の傾向分析とかいいかもしれませんね。
Google Apps Script
こちらがスプレッドシートと直接やり取りをする処理になります。
言語はjavascriptですね。
function doPost(e){
//シートオブジェクト
var spreadsheet = SpreadsheetApp.openById(スプレッドシートのID);
var sheet = spreadsheet.getSheetByName("mode");
//POSTされた内容を確認
var str = e.postData.contents;
var json = JSON.parse(str);
var mode = json["mode"];
//①写真アップロードの場合
//①A 一時セルに本情報を保存して確認する
if (mode == "input"){
inputTemp(json);
res_list = searchTarget(json["book"]["title"])
return returnAsJSON(res_list.length);
//①B 棚番号を応えてきたら、そこに本情報を記入する
} else if (mode == "int"){
tempMode = sheet.getRange("B2").getValue();
//写真アップロード後ならば、棚に記入
if (tempMode == "input"){
sheet.getRange("B2").setValue("")
inputSheet(json);
return returnAsJSON("完了しました");
}
//写真をアップロードしていないならば、エラーを返す
else {
return returnAsJSON("本の背表紙のアップロードをするか、「検索(スペース)(本の名前の一部)」で検索してください");
}
//②検索の場合
} else if (mode == "search"){
res_list = searchTarget(json["target"]);
res = buildResponse(res_list);
return returnAsJSON(res);
}
}
//共通パーツ
//引数をJSONでくるんでGoogle functionsに返す処理
function returnAsJSON(res){
dict = {"content": res};
// dictデータをjsonに変換
// payloadをreturnするだけではだめ
// ContentServiceを利用して、responseを作成
payload = JSON.stringify(dict);
//正味よくわからない
ContentService.createTextOutput();
var output = ContentService.createTextOutput();
output.setMimeType(ContentService.MimeType.JSON);
output.setContent(payload);
return output;
}
//検索処理
function searchTarget(target){
var ss = SpreadsheetApp.openById(スプレッドシートのID);
//検索結果を入れるリスト
var res_list = [];
//検索してリストにぶち込む
//シートを一つ一つ調べていく
for (var sheetNum = 1; sheetNum < 6; sheetNum++){
var sheet = ss.getSheets()[sheetNum];
var textFinder = sheet.createTextFinder(target);
var ranges = textFinder.findAll();
//検索結果から取り出してリストにぶち込む
for (var i = 0; i < ranges.length; i++ ) {
var row = Math.round(ranges[i].getRow());
var authorLocation = "A" + row;
var titleLocation = "B" + row;
author = sheet.getRange(authorLocation).getValue()
title = sheet.getRange(titleLocation).getValue()
res_list.push("\n棚"+sheetNum+":"+author+ "著 "+title);
}
}
return res_list
}
//上記で作ったレスポンスのリストを文面にする処理
function buildResponse(res_list){
//検索内容がある場合とない場合で返答を変える
res = "検索結果:"
if (res_list.length == 0){
res = "該当するものはありませんでした";
} else {
for (i = 0; i < res_list.length; i++){
res = res + res_list[i];
}
}
Logger.log(res);
return res;
}
//一時セルにスプレッドシートに一時保存
function inputTemp(json) {
var spreadsheet = SpreadsheetApp.openById(スプレッドシートのID);
var modeLocation = "B2";
var authorLocation = "B3";
var titleLocation = "C3";
var sheet = spreadsheet.getSheetByName("mode");
var location = sheet.getLastRow() +1;
//スプレッドシートに一時保存
sheet.getRange(modeLocation).setValue("input");
sheet.getRange(authorLocation).setValue(json["book"]["authors"]);
sheet.getRange(titleLocation).setValue(json["book"]["title"]);
}
//一時セルから棚のシートに記入
function inputSheet(json) {
var spreadsheet = SpreadsheetApp.openById(スプレッドシートのID);
var sheet = spreadsheet.getSheetByName("mode");
//一時セルから本情報を取る
author = sheet.getRange("B3").getValue();
title = sheet.getRange("C3").getValue();
//記入先のセル情報
var sheet = spreadsheet.getSheetByName("box"+json["int"]);
var location = sheet.getLastRow()+1;
var authorLocation = "A" + location;
var titleLocation = "B" + location;
//記入処理
sheet.getRange(authorLocation).setValue(author);
sheet.getRange(titleLocation).setValue(title);
}
スプレッドシートの構成
写真から書籍情報を取り出して、linebotに「この書籍をどこに入れますか」と返す際に、取り出した書籍情報をどこかに保持する必要があるなあと思いました。
そこで今回はスプレッドシートにmodeというシートを作りました。
もっとスマートにやりたいんですが、この辺り何か良いアイデアがありましたら教えてください・・・!
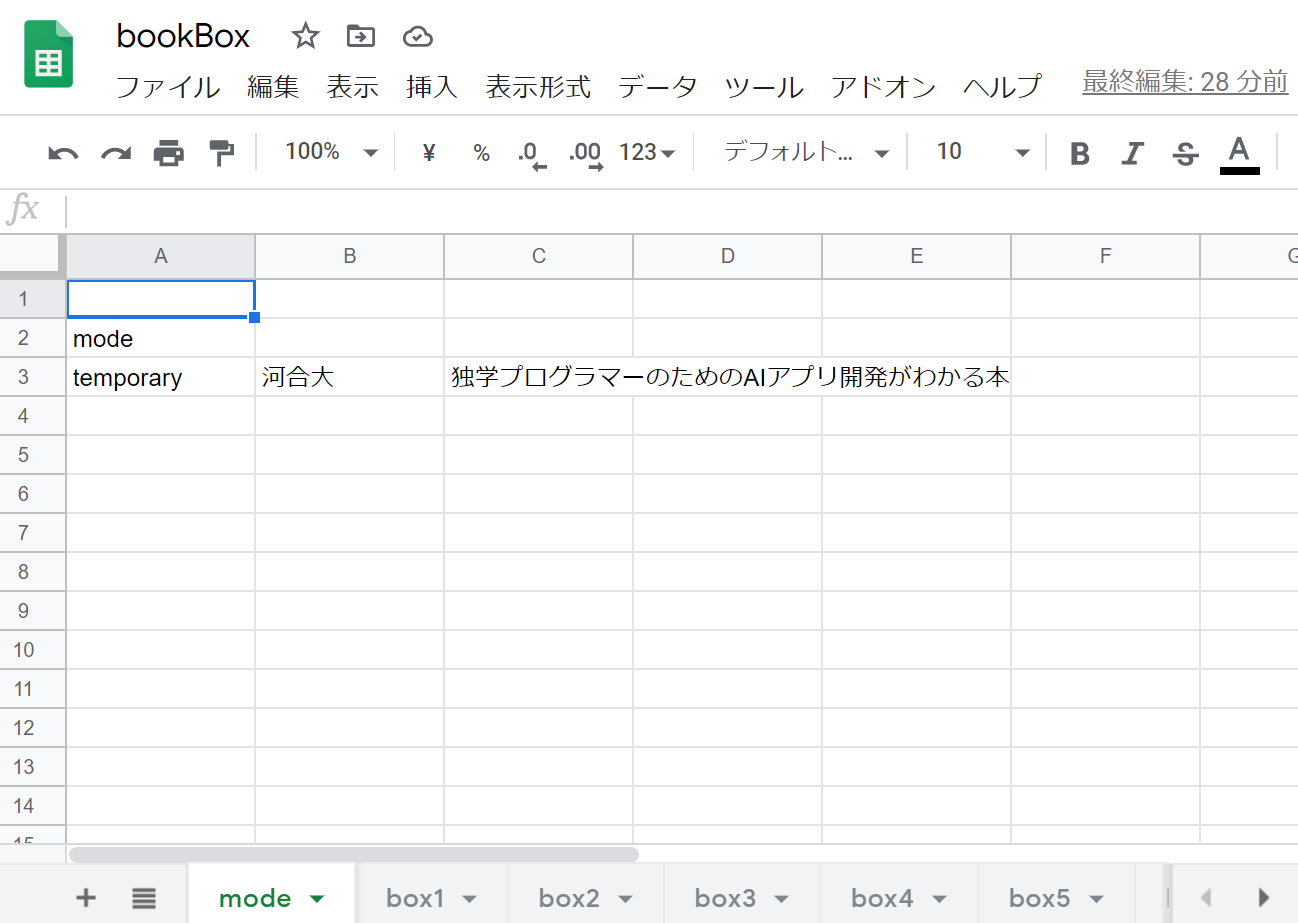
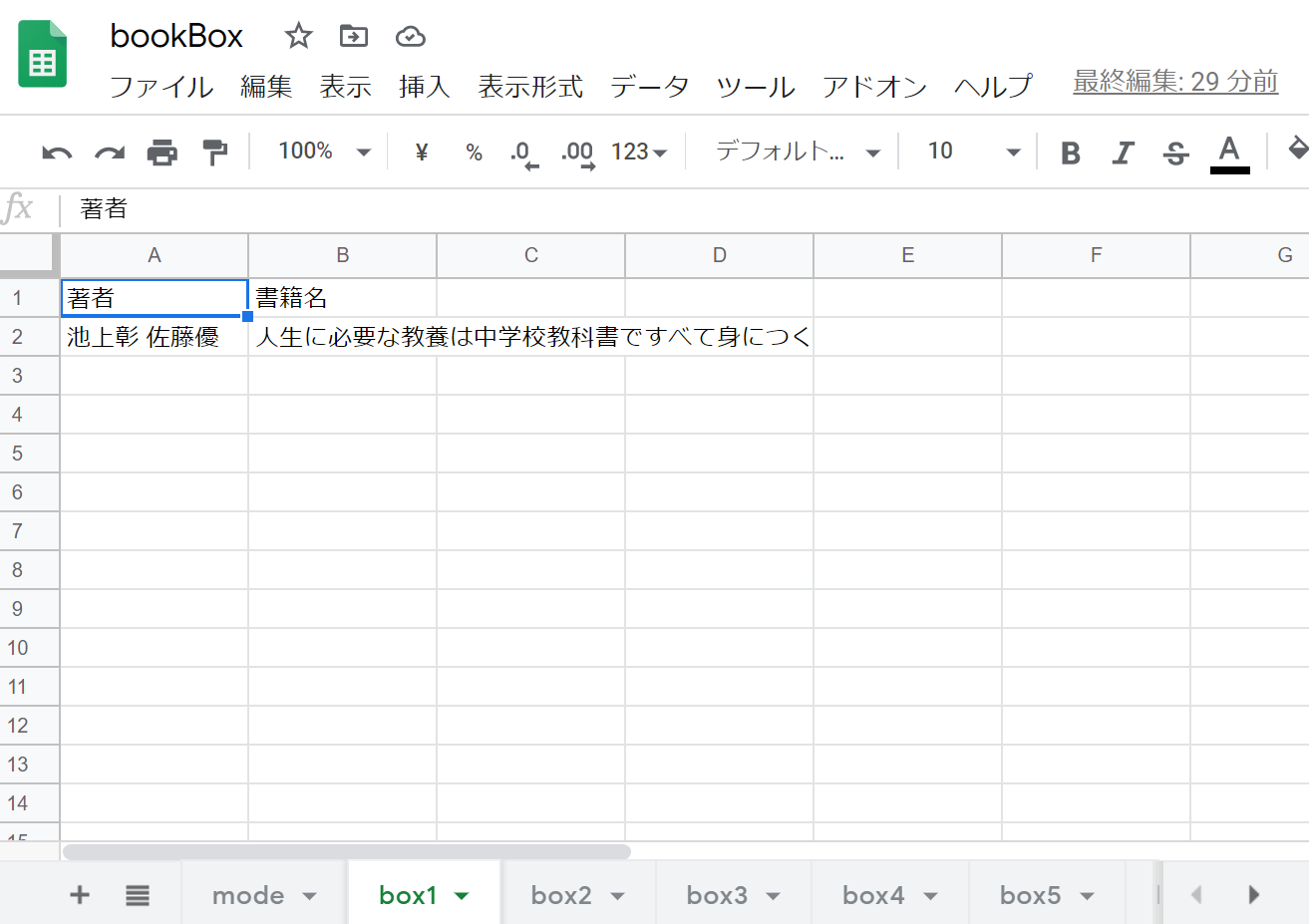
こちらが本棚になります。
box1~box6までそれぞれシートを分けて書いております。
検索処理もここを調べて結果を返します。
今後やってみたいこと
ランダムで棚の中の本を出してくれる機能欲しいなあと思ってます。
処理自体はそれほど難しくないと思うんですが、まだまだ不慣れでGASとの疎通がうまくいかないときがしばしば。
本当になんでcloud functions挟んだろうか(白目)
あとは本の情報を一元管理できるようになったら、自分の読む本の傾向とか分析してみたいなあと思います。
どんな傾向の本を読むのか分析して、違うジャンルの本を読み始めてみるとか。
機械学習モデルをどこかにデプロイして、自分向けリコメンドシステムを作ってみるとか面白いかも。