概要
「機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発」でTransformersの勉強をしました!
書籍サンプルプログラムを参考にして
- トークナイザーの学習
- aiモデルの学習
のプログラムを書きました
この本は
- aiの仕組み
- transformerの仕組み
- Transformersの使い方
- 自作aiモデルの作成チュートリアル
- github上のpythonのコードを取得して自作モデル作成
が書かれていてとても勉強になりました。
finetuning、モデルの作成などのいろいろな検証をしたかったのですが、どうもスペックが足りなくざっと動かすことしかできませんでした
主に足りないスペックはgpuのメモリです
aiの勉強をするためにゲーミングpc(34万円程)を買ったのですが残念です😢
自分の環境
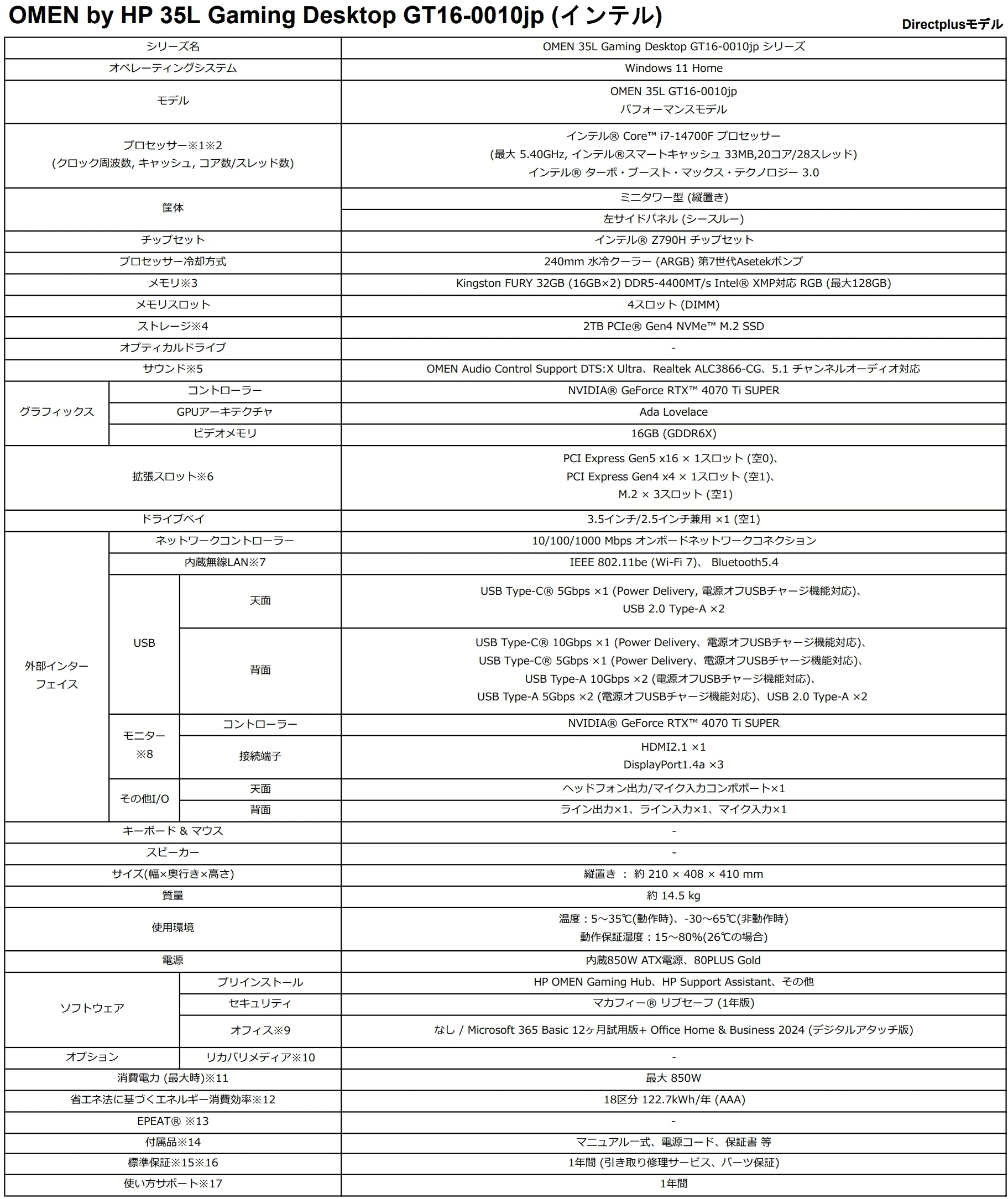
リポジトリ
ソースコード全体を公開しています
docker環境です
https://github.com/campbel2525/sample-transformers
環境構築や実行方法はreadmeを参考にしてください。
参考url
- 機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発
- 本書のサンプルコード
- https://huggingface.co/transformersbook
プログラム
該当のコード抜粋
https://github.com/campbel2525/sample-transformers/blob/main/code/src/sample-transformers.py
import logging
import os
from argparse import Namespace
import datasets
import datasets.utils.logging
import torch
import transformers
import transformers.utils.logging
from accelerate import Accelerator
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader, IterableDataset
from tqdm.auto import tqdm
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, get_scheduler
from transformers.models.gpt2.tokenization_gpt2 import bytes_to_unicode
# =====================================================================
# 定数宣言
# =====================================================================
# pcのスペックが足りなく実行できない場合は下記の値を小さくして対応
# - TRAIN_LENGTH
# - config_dict
# - train_batch_size
# - valid_batch_size
# - seq_length
# 学習データの長さ
TRAIN_LENGTH = 100000
# データセット名
# 書籍で用意されているデータセット名を使用する
TRAIN_DATASET_NAME = "transformersbook/codeparrot"
# 学習に使用するモデル名
MODEL_NAME = "gpt2"
# 語彙サイズ
VOCAB_SIZE_LARGE = 12500
# ベース語彙
BASE_VOCAB = bytes_to_unicode()
# プロジェクト名
PROJECT_NAME = "myproject"
# トークナイザーの保存先(local)
TOKENIZER_SAVE_DIR = "/hf_repo/tokenizers/myproject/"
# モデルの保存先(local)
MODEL_SAVE_DIR = "/hf_repo/models/myproject/"
# トークナイザー名
# hugging faceのトークナイザーを指定することも可能
# 今回はlocalに保存しているトークナイザーを指定
TOKENIZER_NAME = TOKENIZER_SAVE_DIR
# Accelerate などで使用されるパラメータ
config_dict = {
"train_batch_size": 1, # 書籍:2
"valid_batch_size": 1, # 書籍:2
"weight_decay": 0.1, # 書籍:0.1
"shuffle_buffer": 1000, # 書籍:1000
"learning_rate": 2e-4, # 書籍: 2e-4
"lr_scheduler_type": "cosine", # 書籍:
"num_warmup_steps": 750, # 書籍: 750
"gradient_accumulation_steps": 16, # 書籍: 16
"max_train_steps": 50000, # 書籍: 50000
"max_eval_steps": 10000, # 書籍: -1 -1: すべて
"seq_length": 128, # 書籍: 1024
"seed": 1, # 書籍: 1
"save_checkpoint_steps": 10, # 書籍: 50000
}
args = Namespace(**config_dict)
# =====================================================================
# トークナイザーの学習
# =====================================================================
def train_tokenizer():
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# ストリーミングデータセットを用いて学習
dataset = load_dataset(TRAIN_DATASET_NAME, split="train", streaming=True)
iter_dataset = iter(dataset)
def batch_iterator_larger(batch_size=10):
for _ in tqdm(range(0, TRAIN_LENGTH, batch_size)):
yield [next(iter_dataset)["content"] for _ in range(batch_size)]
new_tokenizer = tokenizer.train_new_from_iterator(
batch_iterator_larger(),
vocab_size=VOCAB_SIZE_LARGE,
initial_alphabet=BASE_VOCAB,
)
# トークナイザーをローカルに保存
os.makedirs(TOKENIZER_SAVE_DIR, exist_ok=True)
new_tokenizer.save_pretrained(TOKENIZER_SAVE_DIR)
return new_tokenizer
# =====================================================================
# モデルの初期化
# =====================================================================
def init_model(tokenizer_name: str, model_name: str):
# 語彙サイズを合わせて初期化
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
config = AutoConfig.from_pretrained(model_name, vocab_size=len(tokenizer))
model = AutoModelForCausalLM.from_config(config)
return model, tokenizer
# =====================================================================
# モデルの学習
# =====================================================================
class ConstantLengthDataset(IterableDataset):
def __init__(
self,
tokenizer,
dataset,
seq_length=1024,
num_of_sequences=1024,
chars_per_token=3.6,
):
super().__init__()
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.eos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
def __iter__(self):
iterator = iter(self.dataset)
while True:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
# もう一度イテレータを作り直す
iterator = iter(self.dataset)
all_token_ids = []
tokenized_inputs = self.tokenizer(buffer, truncation=False)
for tokenized_input in tokenized_inputs["input_ids"]:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length] # noqa
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
def create_dataloaders(tokenizer):
from datasets import load_dataset
train_data = load_dataset(
TRAIN_DATASET_NAME + "-train", split="train", streaming=True
)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
valid_data = load_dataset(
TRAIN_DATASET_NAME + "-valid", split="validation", streaming=True
)
train_dataset = ConstantLengthDataset(
tokenizer, train_data, seq_length=args.seq_length
)
valid_dataset = ConstantLengthDataset(
tokenizer, valid_data, seq_length=args.seq_length
)
train_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)
return train_dataloader, eval_dataloader
def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay):
params_without_wd.append(p)
else:
params_with_wd.append(p)
return [
{"params": params_with_wd, "weight_decay": args.weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},
]
def evaluate_model(model, eval_dataloader, accelerator):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.valid_batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = torch.tensor(float("inf"))
return loss.item(), perplexity.item()
def setup_logging(project_name, accelerator):
"""
Python の logger だけを使用してロギングを行うセットアップ。
"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# ログの整形や出力方法を指定
formatter = logging.Formatter(
fmt="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
)
# ファイル出力とコンソール出力の例
file_handler = logging.FileHandler(f"log/debug_{accelerator.process_index}.log")
file_handler.setFormatter(formatter)
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(stream_handler)
if not accelerator.is_main_process:
# サブプロセスで冗長なログを出さない
logger.setLevel(logging.ERROR)
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
else:
# メインプロセス
datasets.utils.logging.set_verbosity_debug()
transformers.utils.logging.set_verbosity_info()
run_name = f"{project_name}_run"
return logger, run_name
def log_metrics(step, metrics, logger):
"""
Python logger でのみログを出す関数。
"""
logger.info(f"Step {step} | " + " | ".join(f"{k}: {v}" for k, v in metrics.items()))
def train_model():
# モデルの初期化
model, tokenizer = init_model(
tokenizer_name=TOKENIZER_NAME,
model_name=MODEL_NAME,
)
# モデルの学習
_train_model(model, tokenizer)
def _train_model(model, tokenizer):
accelerator = Accelerator()
samples_per_step = accelerator.state.num_processes * args.train_batch_size
# ログのセットアップ
logger, run_name = setup_logging(PROJECT_NAME, accelerator)
logger.info(accelerator.state)
# データローダー作成
train_dataloader, eval_dataloader = create_dataloaders(tokenizer)
# Optimizer & Scheduler
optimizer = AdamW(get_grouped_params(model), lr=args.learning_rate)
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
def get_lr():
return optimizer.param_groups[0]["lr"]
# Accelerator で準備
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
model.train()
completed_steps = 0
for step, batch in enumerate(train_dataloader, start=1):
outputs = model(batch, labels=batch)
loss = outputs.loss
# ログ出し (Python logger)
log_metrics(
step,
{
"lr": get_lr(),
"samples": step * samples_per_step,
"steps": completed_steps,
"loss/train": loss.item(),
},
logger,
accelerator,
)
# 勾配積算
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
# チェックポイントの保存
if step % args.save_checkpoint_steps == 0:
logger.info("Evaluating and saving model checkpoint")
eval_loss, perplexity = evaluate_model(model, eval_dataloader, accelerator)
log_metrics(
step,
{"loss/eval": eval_loss, "perplexity": perplexity},
logger,
accelerator,
)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
if accelerator.is_main_process:
# ローカルに保存
ckpt_dir = f"{MODEL_SAVE_DIR}model_checkpoint_step_{step}"
os.makedirs(ckpt_dir, exist_ok=True)
unwrapped_model.save_pretrained(ckpt_dir)
model.train()
if completed_steps >= args.max_train_steps:
break
# 学習終了後に最終チェックポイント保存
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate_model(model, eval_dataloader, accelerator)
log_metrics(
step,
{"loss/eval": eval_loss, "perplexity": perplexity},
logger,
accelerator,
)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
if accelerator.is_main_process:
# ローカル保存を行う
final_dir = f"{MODEL_SAVE_DIR}model_final"
os.makedirs(final_dir, exist_ok=True)
unwrapped_model.save_pretrained(final_dir)
if __name__ == "__main__":
# デバッグ
# from config.debug import *
# 1. トークナイザーの学習&保存
new_tokenizer = train_tokenizer()
# 2. モデルの学習&保存
train_model()
プログラムの説明
学習で使用するデータセットについて
学習に必要なデータセットは書籍で公開されているhugging face上の
を使用します。
設定値
pcのスペックが足りなく動かない場合は下記の値を小さくして対応してください
- TRAIN_LENGTH
- config_dict
- train_batch_size
- valid_batch_size
- seq_length
処理の流れ
1
'train_tokenizer()'
transformersbook/codeparrotをもとにトークナイザーの学習を行いlocalに保存
2
'train_model()'
保存したトークナイザーとtransformersbook/codeparrotをもとにモデルの学習を行いlocalに保存