この記事は
kaggle用にNVIDIA A100 GPUを使いたかったので、
GCP&kaggleコンテナイメージを用いた環境構築に挑戦したところ、
思ったより難しくて数日を費やしてしまったので、備忘録として手順を整理しました。
GCPに手を出してみたいけど躊躇している方や、今現在同じように苦労している方の助けになれば幸いです。
(注意事項)
- あくまでkaggle用学習環境の構築方法であることにご注意ください。例えばプロダクト用のGPU環境が欲しい場合は、より適切な手順があると思います。
- 本記事では(筆者がPyTorchユーザーのため)Tensorflowはサポートしていません。
- ただし、kaggleコンテナを開始するところまでは同じ進め方のはずなので、参考にはなると思います。
手順
(事前準備)GPUの割り当て申請
GCPでGPUを使用するためには、割り当ての申請を事前に行う必要があります。
A100GPUを使用するためには、以下に対して上限1以上の割り当てが必要です。
- GPUs (all regions)
- NVIDIA A100 GPUs(region: VMを立てたいリージョン)
まずGCPコンソールへサインインし、
ナビゲーションメニュー(左上の三本線)から「IAMと管理 → 割り当て」の順で遷移します。
遷移先の画面を見ると、「フィルタ」の横に検索窓があるので、
「割り当て」を選択して「GPU」で検索し、「GPUs(all regions)」を選択します。
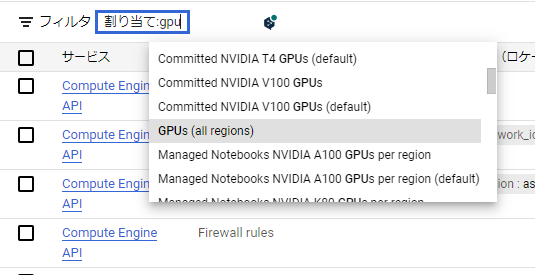
すると、以下のようにフィルタされるので、GPUs(all regions)のチェックボックスを選択し、
画面右上の「割り当てを編集する」をクリックします。
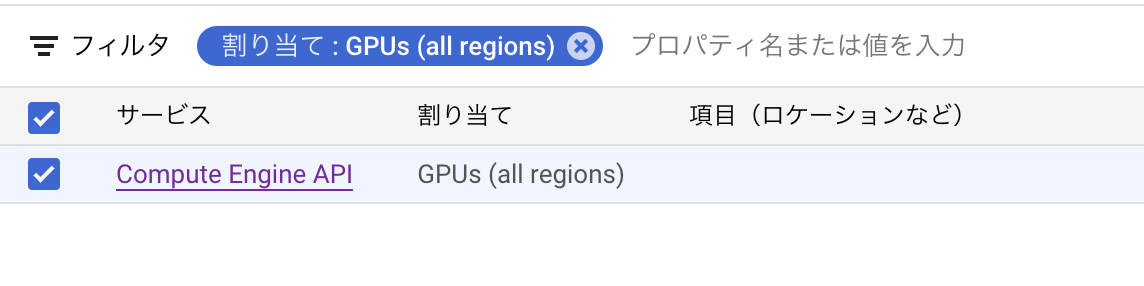
すると、下のような画面が表示されるので、
新しい割り当て上限と用途を入力し、「次へ」をクリックします。
(※上限を大きくしすぎると承認されない場合があるので、理由がない限りは1で申請するのが安全です)
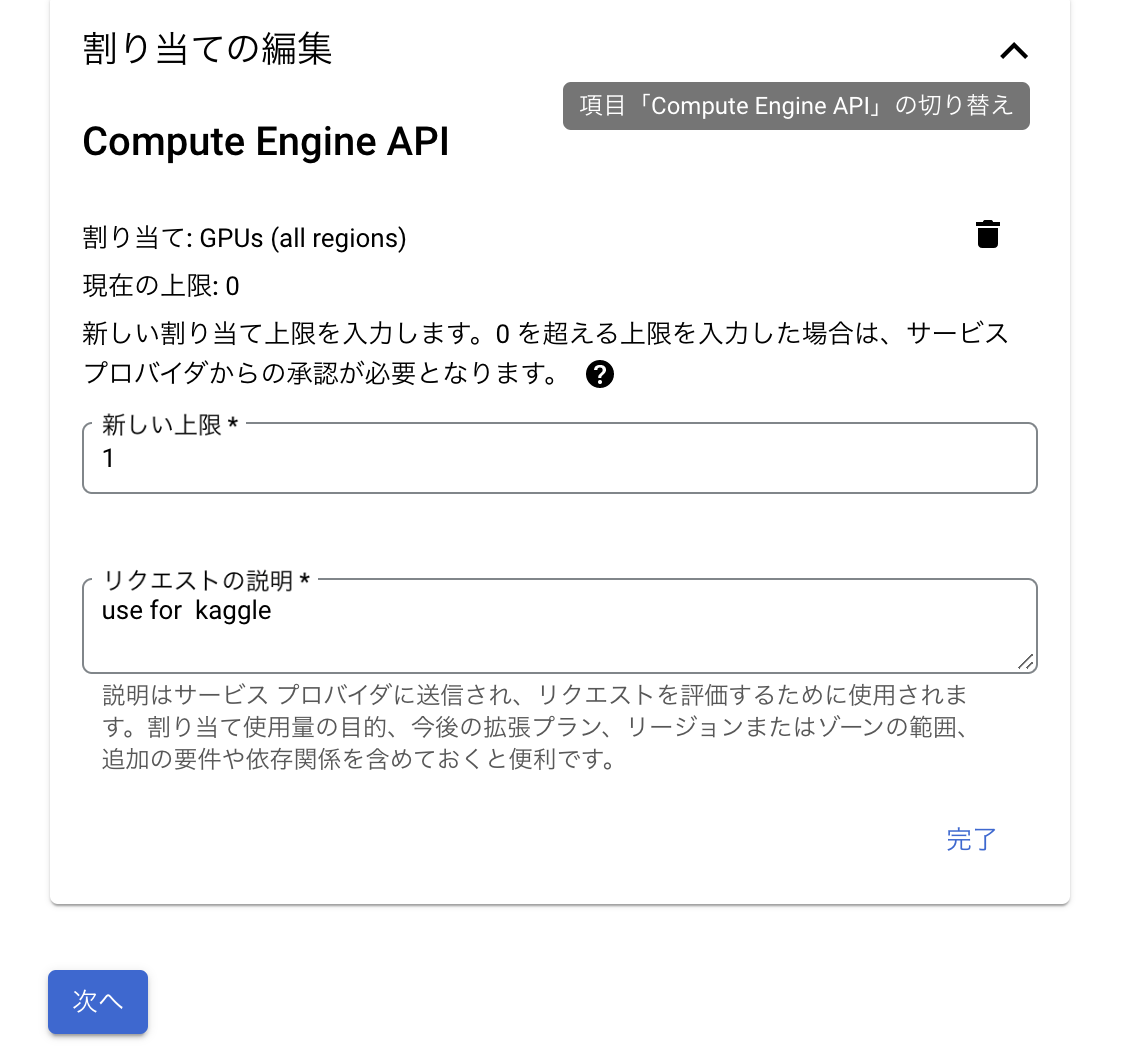
次の画面で氏名、メールアドレス、電話番号を求められるので、
入力して「リクエストを送信」をクリックすると、申請は完了です。
しばらく待つと、Googleから審査結果のメールが返ってきて、OKであればGPUの利用が可能になります。
また、同じ申請を「NVIDIA A100 GPUs」に対して行う必要があるのですが、
こちらは以下のようにregion毎に申請する形になっています。
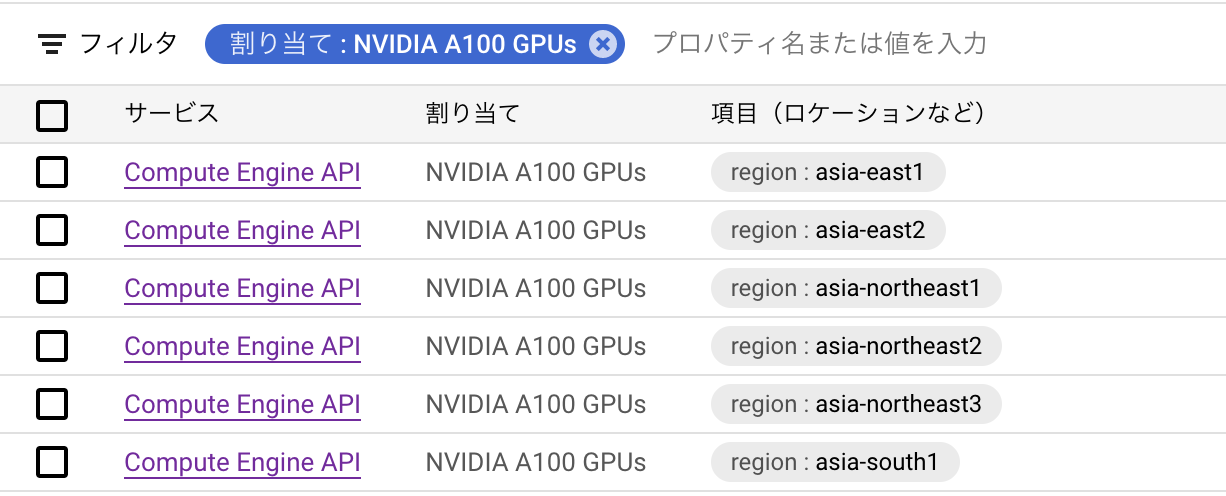
申請するregionは実際にVMを立てるregionを選べば良いのですが、
ややこしいことに、実際にはA100を使えないregionに対しても申請可能だったりするので、
以下ページで、A100を使えるregionを確認してから申請することをお勧めします。
GPU のリージョンとゾーンの可用性
「GPUs (all regions)」「NVIDIA A100 GPUs」の両方で申請が通ったら、この手順は完了です。
(2023/03/25追記)
初稿では参考リンク(GCPでDeep LearningのためのGPU環境を構築する)を説明としていましたが、2019年の記事のため現行の操作と変わっている部分があるとの情報を頂きましたので、修正しました。(元ツイート)
VMインスタンスの作成
割り当ての申請が通ったら、VMインスタンスを作成します。
GCPコンソールから「Compute Engine」→「VMインスタンス」の順で遷移し、「インスタンスを作成」をクリックして作成を開始します。
設定
以下のように設定を入力します。
(※ 記載のないところはデフォルトでOK)
| 項目 | 内容 |
|---|---|
| リージョン/ゾーン | A100を使用可能&割り当て申請済みのゾーン |
| マシンファミリー | GPU |
| GPUのタイプ | NVIDIA A100 40GB |
| マシンタイプ | a2-highgpu-1g(A100だとこれしか選べないはず) |
| ブートディスク | OS: Ubuntu 18.04 LTS(x86/64, amd64) サイズ: 200GB |
| IDとAPIへのアクセス | アクセススコープ: APIごとにアクセス権を設定 ストレージ: フル |
| 詳細オプション → 管理 → 可用性ポリシー |
VMプロヴィジョニングモデル: スポット |
すべての設定が終わったら、ページ最下部の「作成」をクリックしてVMインスタンスを作成します。
補足
- OSは筆者の手元で実績のあるものを書いています(変えても大丈夫な気はしますが、未確認)
- ディスクのサイズは、kaggleコンテナイメージが容量を大きく消費するので、大きめに設定しています。
- 「ストレージ: フル」の設定を忘れると、マウントしたGCSバケットへの書き込みが出来なくなります。後から変更しようとすると面倒なので、忘れずに設定しましょう。
- 「VMプロヴィジョニングモデル: スポット」の設定をすると、VMがスポットインスタンスで作成されます。価格が安くなるのでなるべく設定したいですが、VMが突然停止するリスクが発生します。長期間の学習を回す場合は、この設定を外すことも検討すると良いでしょう(懐具合と相談しましょう)。
必要ソフトウェアのインストール(CUDA、Docker関連)
ここからは、docker上でGPUを使用するのに必要なソフトウェアをインストールしていきます。
(事前準備)kaggleコンテナイメージ側のドライババージョン確認
kaggleコンテナイメージのgithubを事前に確認し、kaggleコンテナイメージが想定するCUDAバージョンを調べておきましょう。
config.txt によると、2023年3月現在は11.3に対応しているようなので、本記事ではその前提で進めます。
CUDA_MAJOR_VERSION=11
CUDA_MINOR_VERSION=3
VMに接続
先ほど作成したVMに接続します。
接続方法は色々ありますが、慣れた方法で良いです。
「接続」→「ブラウザウィンドウで開く」が一番頭を使わなくて楽ちんです。
adminユーザーに切り替え
VMのターミナル上で以下コマンドを実行し、adminユーザーに切り替えます。
sudo su
cuda toolkitのインストール
CUDA Toolkit Archive から、対象のバージョン(11.3)を探します。

リンク先の画面で、「OS -> Architecture -> Distribution -> Version」の順に選択していきます。
(今回はLinux -> x86_64 -> Ubuntu -> 18.04)
Installer Typeは好みで良いですが、ここでは「deb(local)」を選びます。
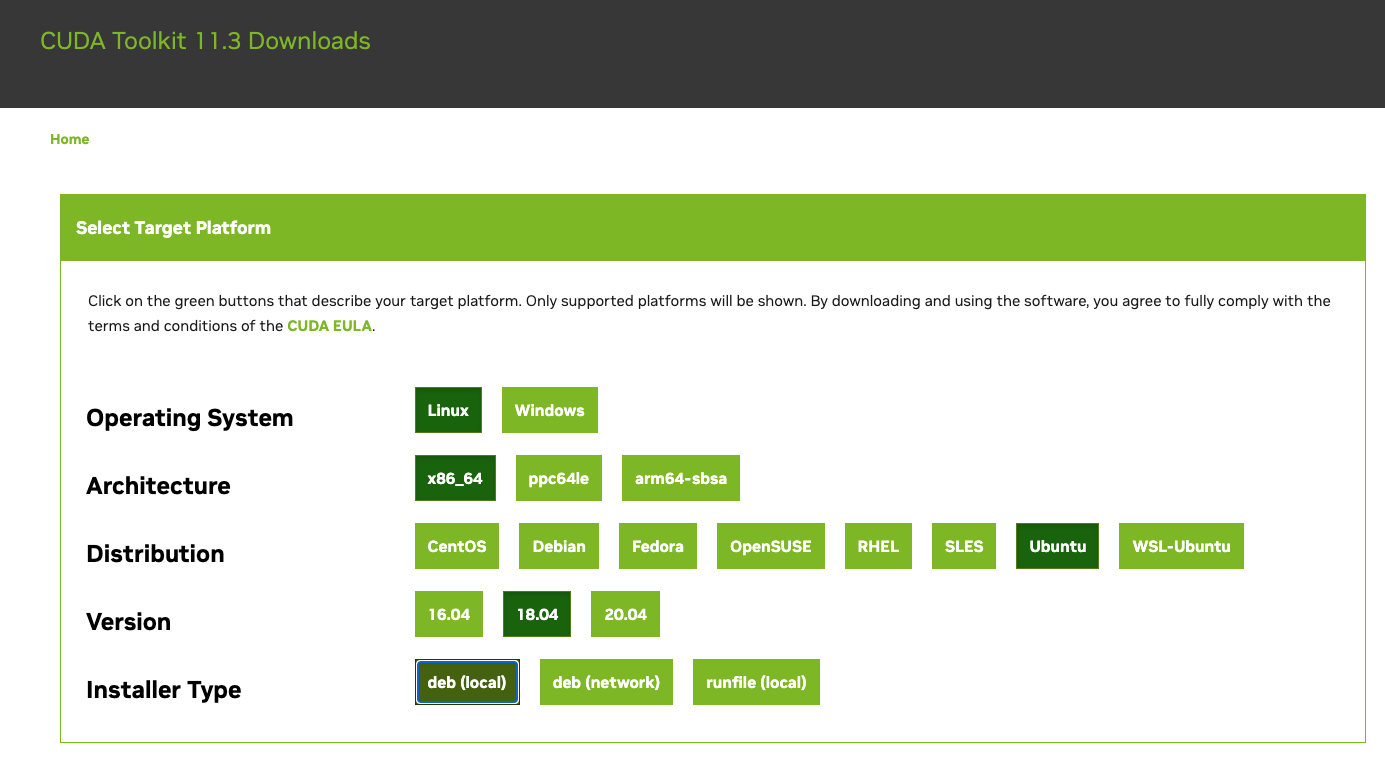
全ての選択を終えると、インストール用のコマンドが表示されるため、VMのターミナルにコピペして実行します。
今回の環境だと、以下のようになります。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda-repo-ubuntu1804-11-3-local_11.3.0-465.19.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-11-3-local_11.3.0-465.19.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu1804-11-3-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
実行完了後、動作確認のために以下を実行します。
nvidia-smi
次のような表示がされれば成功です。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... Off | 00000000:00:04.0 Off | 0 |
| N/A 30C P0 52W / 400W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Dockerのインストール
以下を実行し、dockerの最新安定板をインストールします。
※ 参考: docker公式のマニュアル
curl https://get.docker.com | sh
sudo systemctl start docker && sudo systemctl enable docker
NVIDIA Container Toolkit のインストール
以下を実行し、NVIDIA Container Toolkitをインストールします。
※ 参考: nvidia-docker2 公式ドキュメント
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
処理が完了したら、dockerを再起動します
sudo systemctl restart docker
再起動後、以下を実行し、nvidia-smiと同じ表示がされれば成功です。
docker run --gpus all --rm nvidia/cuda:9.0-base nvidia-smi
kaggleコンテナイメージのビルド
以下を実行し、kaggleコンテナイメージをビルドします。
git clone https://github.com/Kaggle/docker-python.git
cd docker-python
./build -g
A100GPUのVMだと、だいたい1時間経たないくらいで終わります。
kaggleコンテナの開始
以下を実行し、kaggleコンテナを開始します。
docker run -itd \
--gpus all \
--shm-size 512m \
--privileged \
-p 8888:8888 \
-v /root/workspace:/home \
--name kaggle \
-h kaggle \
kaggle/python-gpu-build:latest \
jupyter lab --ip=0.0.0.0 --allow-root --no-browser --NotebookApp.token=''
GCSを使う場合は、--priviragedを付けるのを忘れないようにしましょう。
これが無いと、GCSバケットをマウントする際にOperation not permittedエラーで失敗する場合があります。
なお、作業中断等でVMを停止すると、次回起動時にはkaggleコンテナは停止されているため、
その場合は以下を入力してコンテナを起動します。
docker start kaggle
ローカルからkaggleコンテナへ接続
GCP CLIをローカルから使用するため、未インストールの場合はインストールします。
インストール手順: https://cloud.google.com/sdk/docs/install?hl=ja
インストール完了後、ローカルのターミナルで以下を実行します。
gcloud compute ssh <インスタンス名> -- -N -f -L 8888:localhost:8888
初回実行時はパスフレーズの設定を求められるので、適当なパスフレーズを入力しましょう。(内容を覚えておくor控えておくこと)
実行後、ローカルのブラウザからhttp://localhost:8888にアクセスすると、
jupyter-labの画面が表示され、kaggleコンテナ上での作業が可能になります。
kaggleコンテナ(jupyter-lab)上で作業開始前にやること
分析作業開始前に、kaggleコンテナ上でやるべきことを記載します。
この節のコマンドは、すべてjupyter-labのセル上で実行することを想定します。
PyTorchの再インストール
PyTorchはkaggleコンテナ上にデフォルトでインストール済みなのですが、
そのまま使おうとすると、処理が異常に遅くなる不具合が発生する場合があります。
(model.to(device)が1時間経っても終わらないレベル)
この不具合は、以下のようにPyTorchを再インストールすることで解消します。
!pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
※ 異なるバージョンのpytorchまたはcudaを使用する場合は、
https://pytorch.org/get-started/previous-versions/ から対象バージョンのインストール方法を参照してください。
GCSのマウント
GCSのバケットをマウントする場合は、以下の手順で実施します。
まず、gcsufseをインストールします。
※ 参考: https://github.com/GoogleCloudPlatform/gcsfuse/blob/master/docs/installing.md
# gcsfuseのインストール
!echo "deb http://packages.cloud.google.com/apt gcsfuse-`lsb_release -c -s` main" | sudo tee /etc/apt/sources.list.d/gcsfuse.list
!curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
!apt-get update
!apt-get install gcsfuse
インストールが完了したら、バケットをマウントします。
# マウント先のディレクトリを作成
!mkdir -p /content/gcs
# バケットをディレクトリにマウント
!gcsfuse <バケット名> /content/gcs
以上で環境構築は完了です。
A100GPUをガンガン使って学習を回していきましょう!!
VMを起動しっぱなしだと利用料金が大変な事になるので、こまめに停止するのを忘れずに!!
トラブルシューティング
ここでは、作業中に発生した不具合について記載します。
VM立てられない問題
VM作成時、以下のエラーにより失敗する場合があります。
A a2-highgpu-1g VM instance is currently unavailable in the <VMを立てようとしたゾーン> zone
このエラーが発生した場合、10分程度待ってから再作成すると成功する場合があります。
何度やっても失敗する場合は、運が悪いと思って諦めて、他のzoneで試すのが良いかも。
kaggle-dockerのビルドに失敗する問題
kaggleコンテナのbuild途中で、pipのタイムアウトエラーで処理が中断される場合があります。
解決策としては、Dockerfile.tmplの一部を以下のように書き換えて、
build中にpip install --upgrade pipを実行するよう修正するとエラーが解消しました。
ADD patches/nbconvert-extensions.tpl /opt/kaggle/nbconvert-extensions.tpl
ADD patches/template_conf.json /opt/kaggle/conf.json
# ↓の一行を追記。pipを最初に使う行より前に追記すること。
RUN pip install --upgrade pip
{{ if eq .Accelerator "gpu" }}
# b/200968891 Keeps horovod once torch is upgraded.
RUN pip uninstall -y horovod && \
/tmp/clean-layer.sh
{{ end }}
ただし、この記事を書いている時にもう一度buildを試したところ、上記の対策が無くても処理が最後まで通ったので、
そもそも再現したりしなかったりする現象である可能性があり、上記の対策は有効な方法ではないかも知れません。
他に有効な対策をご存知の方がいらしたら、コメント等で教えて頂けると幸いです。
dockerとGPUが通信できない問題
kaggleコンテナをrunする際、以下のエラーで失敗する場合があります。
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
この場合、VMのターミナルからnvidia-smiを実行することで切り分けを行います。
もしこの時点でエラーが出るなら、cudatoolkitのインストールに失敗している可能性があるので、
インストール方法を再確認し、再インストールするのが良いでしょう。
エラーが出ない場合は、dockerとGPUが通信できていないことが考えられます。
よくあるのは、インストール後にdockerを再起動していないケースで、
以下コマンドで再起動をすると、症状が消える場合があります。
sudo systemctl restart docker
GCP CLIのzoneが違う問題
ローカルからkaggleコンテナへ接続しようとすると、以下のエラーが発生することがあります。
ERROR: (gcloud.compute.ssh) Could not fetch resource:
- The resource 'projects/<プロジェクト名>/zones/asia-northeast3-a/instances/<インスタンス名>' was not found
これはローカルのGCP CLIに設定されたゾーンがVMを立てたゾーンと対応していないために発生します。
以下のようにconfigを変更することで改善します。
gcloud config set compute/zone <自分がVMを立てたゾーン>
参考記事
「必要ソフトウェアのインストール」の大部分は、以下記事を参考にしました。
偉大な先人に感謝申し上げます。