AI推論の高速化ライブラリ「TensorRT for RTX」
もう結構前のことでお忘れになっている方も多いかもしれませんが、2025/05/19 NVIDIAは、COMPUTEX TAIPEI 2025にあわせて、AI推論の高速化ライブラリ「TensorRT for RTX」を発表しました。
TensorRT for RTXの特徴は次のように説明されています。
- DirectMLと比べると50%以上高速に動作する
- エンジンモデル作成を、事前のAOTコンパイルとジャストインタイムのJITコンパイルに分割。AOTで15秒程度、JITでは数秒でエンジンが作成され、ユーザーエクスペリエンスが改善
- WindowsML対応で、ファイルサイズは200MB未満
- Linux x86-64、Windows x64対応
私も自作WindowsアプリでTensorRTを利用しています。
TensorRTは推論速度で目覚ましいものがあるものの、DLLのファイルサイズや事前コンパイルにややウンザリしていたので、そのあたりがどのようになっているか気になっていました。
WindowsMLを見越してのTensorRT-RTX対応ということのようなので、WindowsMLが正式リリースされてからでもいいかなとも思ったのですが、正式リリースは2025年内くらいとまだ少し先のようなので、まずはTensorRT-RTXだけでも見てみたい!と思っていました。
TensorRT for RTXをダウンロードしてみた!
TensorRT-RTXの発表後、まだかまだかと定期的に様子を見に行っていたのですが、2025/06/15頃にダウンロードできるようになっていました。
TensorRTとTensorRT-RTXのファイルサイズ
私はWindows版をダウンロードしました。
ダウンロードするとわかるのですが、ファイルサイズがTensorRTとは全然違います。
TensorRT-RTXはこんな感じ。
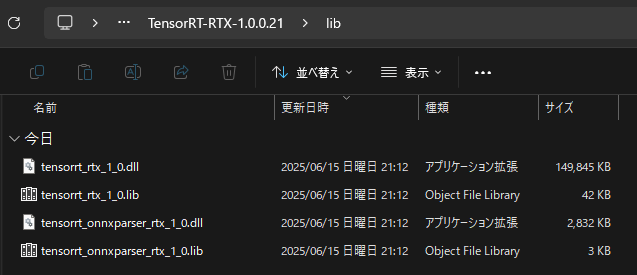
200MB未満という触れ込みでしたが、なんと150MBです。なんと軽量化されているのでしょう!
ちなみにTensorRTはこんな感じです。
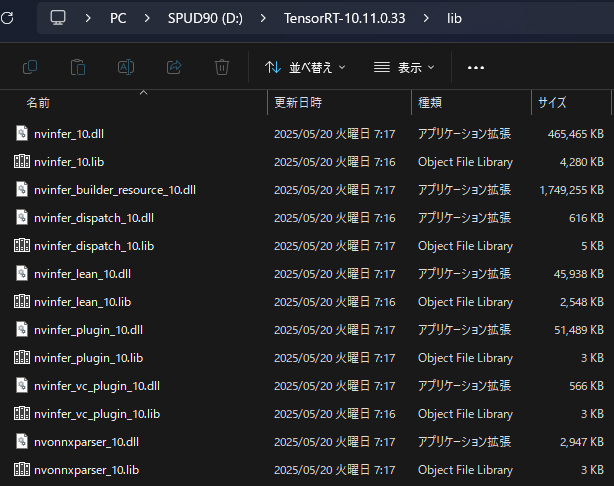
1つのDLLで1.75GBのファイルとかありますね。わたしこの1.75GBのDLLをWindowsアプリに同梱してます。だってこれがないと各ユーザのGPUに最適化されたエンジンの構築ができないから。アプリの圧縮ファイルで3.5GBくらいあったかな?ほとんどTensorRTの仕業です。
それが200MB!これだったらアプリ全体でも500MBくらいとか、いけるのでは??
フットプリントを大幅に改善できそうな気がします!
TensorRT-RTX ダイエットの秘密?
TensorRT-RTXは、WindowsMLを睨んでリリースされました(たぶん)
WindowsMLでは、各PCごとに最適な方法で推論できるように各クライアントで都度エンジンをダウンロードする仕組みもあるようで、確かに数百MB程度でないと気軽にAIアプリを利用できないような気もします。
TensorRTはGeforceもそうですが、データセンター向けGPUや、Jetsonなどもターゲットに開発されいます。
TensorRT-RTXは、TensorRTからデータセンター向けGPUの機能や、推論で主力ではない機能をそぎ落とすことでダイエットに成功したのではないか?と考えています。
例えば
こちらのissueによると、TensorRT-RTXはONNXモデルをFP16精度で出力する機能を持ってないようです。
ONNXモデルをFP16にしておけばいいよね、という判断のようで、まぁごもっともではありますが、この件からGeforceでの推論で主力以外の機能は大胆にカットしたのではないか?と想像したりもしてしまいます。(単にまだ1.0でリリースされたばかりだから、という気もしなくもないですが)
※2025/07/01 追記
TensorRTでもFP16出力は廃止予定で、microsoft/onnxconverter-commonかNVIDIA/TensorRT-Model-Optimizerで変換するのが正道のようです。
TensorRTとTensorRT-RTXの処理速度
水道の蛇口を針金で縛るようなダイエットを敢行したTensorRT-RTX、そのパンチに鋭さは残っているのか?
気になりますよね?私も気になります。
多少犠牲にしたところもあるだろうとは思うのですが、実際どんなものだろう?
こうやったら従来のTensorRTとTensorRT-RTX、比較できるよ!と公式ドキュメントの移行方法に記載されています。
# TensorRT:
trtexec --onnx=myModel.onnx --saveEngine=myModel.plan
# TensorRT-RTX:
tensorrt_rtx --onnx=myModel.onnx --saveEngine=myModel.rtxplan
TensorRT、TensorRT-RTXにはそれぞれtrtexec.exe、tensorrt_rtx.exeがついており、どちらもONNXをTensorRT(-RTX)のエンジンに変換し、スループットやレイテンシーを計測することができます。
とりあえず私のyolov8.onnxで、TensorRT、TensorRT-RTXを試してみました!
ライセンスについて
は?ライセンス?
TensorRT-RTXのベンチマークは?動かしたんでしょ?
・・・いや、動かしたんですよ?
記事にこれくらいだなーって書こうと思ってたんですよ!
でもアプリに適用することも考えて、ライセンスも見ておこうと思ったら、
2. License Restrictions.
Your license to use the Software and Derivatives is restricted as stated in this Section 2 (“License Restrictions”). You will cooperate with NVIDIA and, upon NVIDIA’s written request, you will confirm in writing and provide reasonably requested information to verify your compliance with the terms of this Agreement. You may not:
2.13 Distribute or disclose to third parties the output of the Software where the output reveals functionality or performance data pertinent to NVIDIA hardware or software products, results of benchmarking, competitive analysis, or regression or performance data relating to the Software or NVIDIA GPUs without the prior written permission from NVIDIA.
(超訳)
2. 次のことはしちゃだめだゾ!
2.13 ベンチマークとか勝手に公開とかすること
えええ
またこの世にいらぬポエムを作成してしまった・・・
ぜひ皆さんもtrtexec.exe、tensorrt_rtx.exeを動かして、ご自身の目で結果を確かめてみてください。
ま、もしかしたらそのうち別にいいよ、ってそっと条項が消えるかもしれないので、そうなったらアップします。
※ 2025/09/24追記
WindowsMLが正式リリースされたからか、TensorRT-RTXのライセンスから2.13項がなくなってました。
もう勝手にベンチマーク公開NG縛りはなくなったのかもしれません。
7月からNVIDIAとメールやり取りしてる私の立場よ・・・(しかもまだ公開できてないっていう
TensorRTからTensorRT-RTXへの移行
まだ移行自体をしたわけではありませんが、先ほどの移行の記事によると、名前空間はTensorRTと共通にしてあるものが多く、TensorRTからの移行を容易にできるようにしているようです。
TensorRTに詳しいわけではないのですが、パッと見た感じでは似たような雰囲気がありました。
まとめ
とりあえずまとめてみる
- TensorRT-RTXはWindowsMLなどクライアントPCでの利用を意識してTensorRTからデータセンター専用の機能などを排除したGeforce用の軽量な推論エンジンです。ファイルサイズは200MB未満!
- JITコンパイルで、事前コンパイルが不要となり、ユーザーエクスペリエンスが改善するよ!
- TensorRT-RTX 1.0のライセンスでは、出力結果のベンチマークとかを勝手に公開できないよ!
感想、今後の取り組み
ファイルサイズが大幅に削減されているのは大歓迎!大喜び!
ファイルサイズとのトレードオフは・・・?
私は動画処理アプリにTensorRTを利用しているのですが、ユーザーには静止画だけに利用している方もいらっしゃいます。
そんな方に、TensorRTの1.75GB(アプリで3.5GB)をダウンロードしてもらうのは忍びないとも思っていて、DirectML版とTensorRT版を別アプリに分けようか?とも考えていました。
TensorRT-RTXはファイルサイズが軽量なので、例えばDirectML+TensorRT-RTX版、DirectML+TensorRT版の2つにするという案もあるかなー?と思ったりもしています。
まだ実際に移行をし始めたわけではないのですが、WindowsMLの動向も気にしながらWindowsアプリの開発を継続していきたいと思います。