経緯
私は大学の学部3年生で情報検索分野の研究室に所属しています。
最近、ElasticSearchという検索エンジンを耳にし、検索分野の研究室生として知っておいて損はないと思い、調べてみることにしました。
ElasticSearchって何?
公式によると、
Elasticsearchはオープンソースの分散型RESTful検索・分析エンジン、スケーラブルなデータストア、ユースケースの急増に対処可能なベクトルデータベースの役割を兼務します。データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、手軽に実行可能になります。
ElasticSearchでできることの一部
- RAG(外部の知識ベースを元にLLMが回答を生成するようにする技術)
- 高速な全文文書検索
- 密検索(入力されたキーワードの意味に近いものを検索する技術)
ElasticSearchの仕組み
分散型アーキテクチャ
まず、分散型アーキテクチャって何?って感じですが、ElasticSearchでは以下のようにデータを管理しているようです。
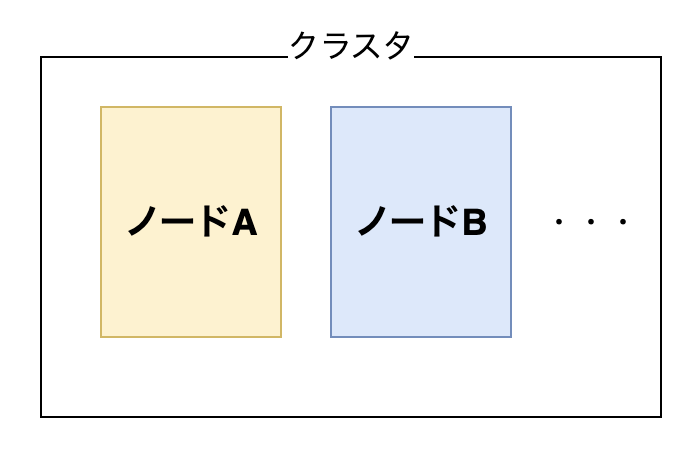
要は、ノード(=サーバ)を複数設置することで、並列処理や分散ストレージを実現しているっていうことです。ちなみにクラスタの定義は「ノードの集合体」です。
JSONベースのRESTful API
ElasticSearchの使用はREST APIを介して行われます。
RESTって何?
一定のルールが設けられているAPIの一種。Representational State Transferの略称。以下のルールがあります。
- クライアント・サーバ方式
- ステートレス
- リクエストの情報を保存しない(リクエスト単位で区切られる)
- 接続性
- 他のアドレスのリンクを入れることができる
- 統一されたインターフェース
- GET(データの取得)、POST(データの登録)、PUT(データの更新)、DELETE(データの削除)
- アドレス可能性
-全てのリソースがURIで表現される
↓ リクエストとレスポンスの例(公式より)
// リクエスト例
POST localhost:9200/accounts/person/1
{
"name" :"John",
"lastname" :"Doe",
"job_description" :"Systems administrator and Linux specialit"
}
// レスポンス例
{
"_index": "accounts",
"_type": "person",
"_id":"1",
"_version":1,
"result": "created",
"_shards": {
"total":2,
"successful":1,
"failed":0
},
"created": true
}
データの管理
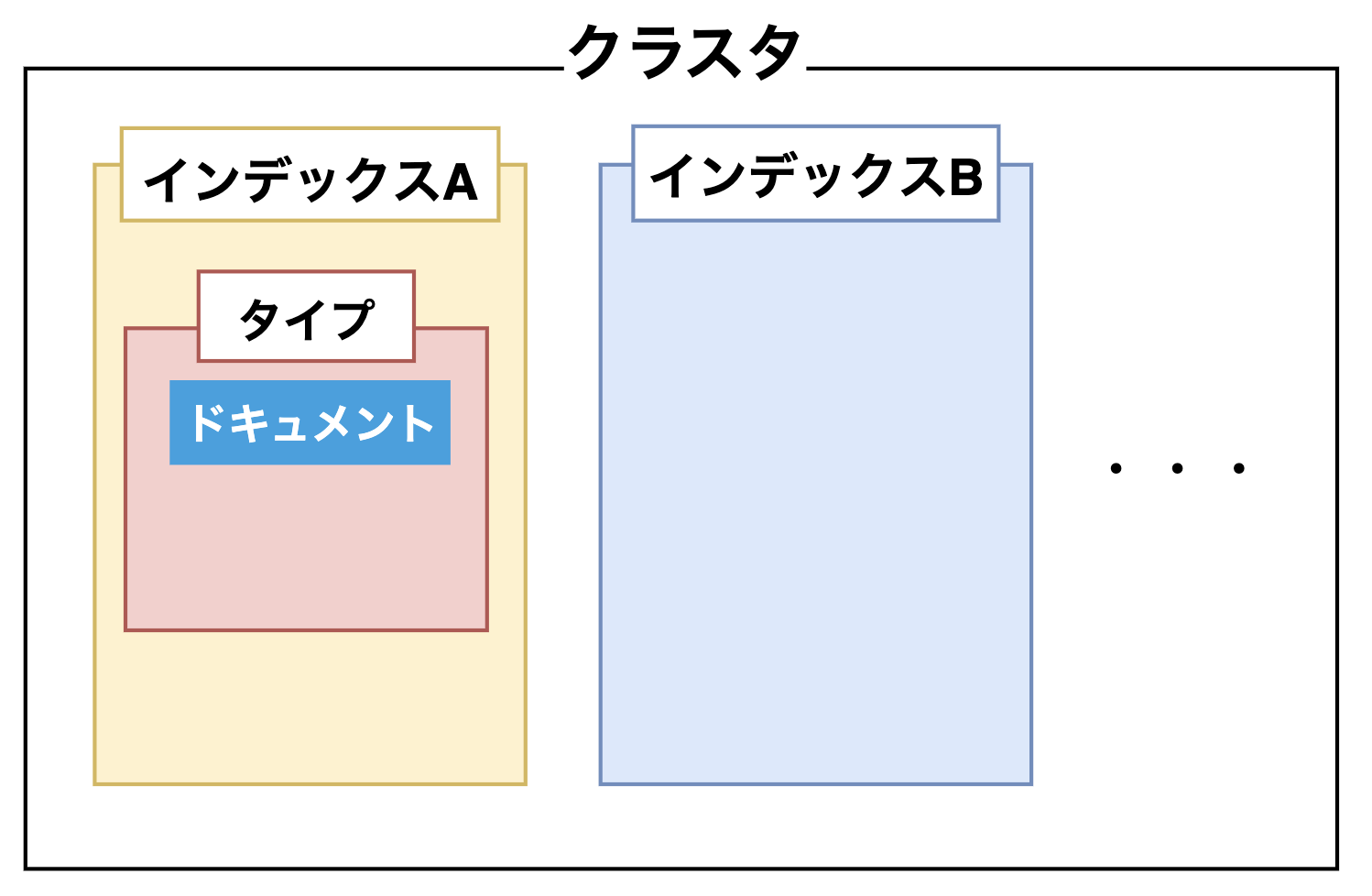
データ(ElasticSearchの場合はドキュメントと呼ぶ)は、インデックス(DBのようなもの)とタイプ(テーブルのようなもの)によって管理されているようです。
まとめ
普段の開発ではRDBしか使ったことがなかったので、DBの種類の良い勉強になりました。
個人で使うにはやや高額なため、すぐに使う予定はないですが、業務等で使う機会があれば便利さを実際に感じてみようと思います。
参考にしたサイト