こんにちは。大学3年生で計量経済学を専攻しているSと申します。
僕がインターン生として所属しているかっこ株式会社では、試用期間に、あるWebサイトをクローリングとスクレイピングして取得したデータを集計、可視化、分析を行い、結果や考察をまとめて、プレゼンをするという課題が出されます。
課題について
僕は、 「大学生で1人暮らしをすることになり、不動産サイトを見ると物件数が多くて選べないため、データ分析で解決してください。」 という課題に挑戦しました。
課題が抽象的であるため、自分で分析対象を決めなければなりません。
まず、ある大学生は池袋駅へ通学するとします。
また、池袋駅からの通学時間が60分以内、40分以内、20分以内に区分します。
というのも、電車通学する際、考えられる通学時間を考慮する必要があり、また、僕は東京の物件について詳しくないので、データの概観を行う必要もあったからです。
この3つのデータを使い、効率的に物件を探す条件を導き出します。
対象にしたサイトは、SUUMOです。
試用生時点でのスキル
Rを用いて散布図作成や回帰分析をしていた程度。
大学で統計学や計量経済学を履修。
Python経験なし。
➡整理したデータを分析したことがあるが、自分でデータを集めたことがないという状態でした。
分析手順
1. 対象ページのurlを取得し、htmlで保存(クローリング)
2. 取得したhtmlから、必要なデータを取得(スクレイピング)
3. データの整形
4. 取得したデータの選定
5. 選別したデータの分析
6. 結果と考察
(クローリング、スクレイピングはpython、データの可視化、分析はRを使用しました。)
クローリング
まず、SUUMOのサイトには、「通勤、通学時間から探す」という条件を指定して検索する機能があります。それを使用し、20分以内で検索して出てきた1ページ目のURL、40分以内で検索して出てきた1ページ目のURL、60分以内で検索して出てきた1ページ目のURLを取得し、htmlとして保存します。
以下がクローリングのコードです。
import requests
from bs4 import BeautifulSoup
import os
import time
# 通学時間20分、40分、60分場合分け
for folder in 20, 40, 60:
# ディレクトリの場合分け
dirname = "htmlbox{}".format(folder)
if not os.path.exists(dirname):
# ディレクトリ作成
os.mkdir(dirname)
# それぞれの1ページ目をhtml化
if folder == 20:
base_url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&ta=13&bs=040&ekInput=02060&tj=20&nk=-1&ct=9999999&cb=0.0&et=9999999&mt=9999999&mb=0&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&fw2=&pc=30"
if folder == 40:
base_url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&ta=13&bs=040&ekInput=02060&tj=40&nk=-1&ct=9999999&cb=0.0&et=9999999&mt=9999999&mb=0&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&fw2=&pc=30"
if folder == 60:
base_url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&ta=13&bs=040&ekInput=02060&tj=60&nk=-1&ct=9999999&cb=0.0&et=9999999&mt=9999999&mb=0&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&fw2=&pc=30"
response = requests.get(base_url)
time.sleep(1)
#ファイルに保存
with open('htmlbox{}/page1.html'.format(folder), 'w', encoding='utf-8') as file:
file.write(response.text)
# urlの引き出し
soup = BeautifulSoup(response.content, "lxml")
# 2ページ以降のurlを定義
pages = soup.find_all("div", class_="pagination pagination_set-nav")
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
num_pages = int(pages_split[0].split('>')[-1])
#2ページ目以降のurlをhtml化
for i in range(2, num_pages + 1):
next_url = base_url + "&page=" + str(i)
response2 = requests.get(next_url)
time.sleep(1)
#ファイルに保存
with open('htmlbox{}/page{}.html'.format(folder, i), 'w', encoding='utf-8') as file:
file.write(response2.text)
#検収条件
print("{}分圏内の総ページ数".format(folder))
print(num_pages)#実際取れたhtml数と比較
クローリングで難しかったところは最終ページの取得でした。
例えば、20分圏内だけをクローリングする場合、ページ数は、その条件で出てきた最終ページの「数字」を使えばよいが、今回の場合、3つの条件をクローリングするため、ページ数がバラバラになります。そのため、1ページ目のURLからその条件の最終ページを引き抜かなければなりませんでした。
htmlの基礎さえ知らなかった僕には、ここでかなり苦戦をしました。
スクレイピング
取得したhtmlから実際に必要なデータ(数値)を抽出します。
使用するデータは、
① 建物名 ② 最寄り駅 ③ 住所 ④ 駅までの所要時間 ⑤ 家賃 ⑥ 管理費
⑦ 敷金 ⑧礼金 ⑨ 間取り ⑩専有面積 ⑪部屋がある階数 ⑫建物に築年数 ⑬建物高さ です。
以下がスクレイピングのコードになります。
import requests
from bs4 import BeautifulSoup
import os
import csv
import pandas as pd
# 通学時間20分、40分、60分場合分け
for folder in 20, 40, 60:
if folder == 20:
num_html = 1702 #取れたhtml数
if folder == 40:
num_html = 3937 #取れたhtml数
if folder == 60:
num_html = 4580 #取れたhtml数
for i in range(num_html + 1):
if i == 0:
with open('sumodata{}.csv'.format(folder), 'w', encoding='CP932',newline="") as file:
writer = csv.writer(file)
writer.writerow(["subtitle", "location", "station", "times", "years", "heights",
"floor", "rent", "admin", "deposit", "gratuity", "madori", "menseki"])
else:
with open('htmlbox{}/page{}.html'.format(folder, i), 'r', encoding='utf-8') as file:
read = file.read()
soup = BeautifulSoup(read, "lxml")
cassetteitems = soup.find_all("div", class_="cassetteitem")
# 建物自体からスクレイピング
for cas in range(len(cassetteitems)):
tbodies = cassetteitems[cas].find_all('tbody')
times1 = cassetteitems[cas].find("ul", class_="cassetteitem_transfer-list")
yearsheights = cassetteitems[cas].find("li", class_="cassetteitem_detail-col3") #築年数 高さ
subtitle = cassetteitems[cas].find("div", class_="cassetteitem_content-title").string
location = cassetteitems[cas].find("li", class_="cassetteitem_detail-col1").string
station = cassetteitems[cas].find("div", class_="cassetteitem_detail-text").string
times = times1.find("li").string
years = yearsheights.find_all('div')[0].string
heights = yearsheights.find_all('div')[1].string
# 一つの建物のうちの部屋数をスクレイピング
for tbody in tbodies:
cols = tbody.find_all("td")
for col, floor1 in enumerate(cols):
if col == 2:
floor = floor1.string
rent = tbody.find(class_="cassetteitem_price cassetteitem_price--rent").string
admin = tbody.find(class_="cassetteitem_price cassetteitem_price--administration").string
deposit = tbody.find(class_="cassetteitem_price cassetteitem_price--deposit").string
gratuity = tbody.find(class_="cassetteitem_price cassetteitem_price--gratuity").string
madori = tbody.find(class_="cassetteitem_madori").string
menseki = tbody.find(class_="cassetteitem_menseki").text
with open('sumodata{}.csv'.format(folder), 'a', encoding='CP932',newline="") as file :
writer = csv.writer(file)
writer.writerow([subtitle, location, station, times, years, heights,floor, rent, admin, deposit, gratuity, madori, menseki]) # リストの中身を格納していく
#検収条件
df = pd.read_csv("sumodata{}.csv".format(folder), encoding="CP932")
with open('htmlbox{}/page1.html'.format(folder), 'r', encoding='utf-8') as file:
url = file.read()
#掲載物件数をスクレイピング
soup = BeautifulSoup(url,"lxml")
pages = soup.find("div", class_="paginate_set-hit")
pages_text = str(pages)
pages_split = pages_text.split('\n')
pages = pages_split[1]
num_text = pages.split("<span>")
num = num_text[0]
if len(num) == len(df):
print("Clear")
else:
print("データが欠損")
スクレイピングで悩んだ点は、メモリーエラーです。
どういうことかというと、最初、取得したいデータのリストを作成し、そこに実際に取得したデータを次々に入れて、最後にCSVへ書き込んでいました。
多大なhtml数とデータ量だったため、実行中にメモリーエラーが起きていました。
その問題を解決するために、データを取得する度にCSVに書き込むという方法を取りました。
ここでのポイントは、同じ建物に複数の物件があることです。
つまり、部屋数に応じて建物名を揃えて、CSVに書き込む必要があります。
部屋数と建物数が異なり、さらに、メモリーエラーも起こるため、ここでも苦戦を強いられました。
また、ここで取得したデータ数とSUUMOのサイトに記載されている「掲載物件総数」を比較し、実際にとれたデータ数が正しく取得出来ているか確認します。
データの整形
取得したデータを分析できるように整形します。
分析するためには、数値のみのデータが必要ですが、実際に取得したデータには文字が含まれています。
分析するためには、それらを除く必要がります。
さらに、単位が異なる場合もあるため、それも統一します。
以下がそのコードです。
import pandas as pd
for a in 20, 40, 60:
if a == 20:
df = pd.read_csv("sumodata20.csv", encoding="CP932")
if a == 40:
df = pd.read_csv("sumodata40.csv", encoding="CP932")
if a == 60:
df = pd.read_csv("sumodata60.csv", encoding="CP932")
# 文字列の削除
df['rent'] = df['rent'].str.replace(u'万円', u'')
df['admin'] = df['admin'].str.replace(u'円', u'')
df['deposit'] = df['deposit'].str.replace(u'万円', u''*10000)#単位を円に統一
df['deposit'] = df['deposit'].str.replace(u'円', u'')
df['gratuity'] = df['gratuity'].str.replace(u'万円', u''*10000)#単位を円に統一
df['gratuity'] = df['gratuity'].str.replace(u'千円', u''*1000)
df['menseki'] = df['menseki'].str.replace(u'm', u'')
df['years'] = df['years'].str.replace(u'新築', u'0') #新築は築年数0年とする
df['years'] = df['years'].str.replace(u'築', u'')
df['years'] = df['years'].str.replace(u'年', u'')
df['floor'] = df['floor'].str.replace(u'階', u'')
df['floor'] = df['floor'].str.replace(u'-', u'00')
df['floor'] = df['floor'].str.replace(u'B', u'0')
df['madori'] = df['madori'].str.replace('ワンルーム', '1R')
#-は0と置く
df['admin'] = df['admin'].replace('-', 0)
df['floor'] = df['floor'].replace('-', 0)
df['deposit'] = df['deposit'].replace('-', 0)
df['gratuity'] = df['gratuity'].replace('-', 0)
# 文字列の数値化
df['rent'] = pd.to_numeric(df['rent'])
df['admin'] = pd.to_numeric(df['admin'])
df['deposit'] = pd.to_numeric(df['deposit'])
df['gratuity'] = pd.to_numeric(df['gratuity'])
df['menseki'] = pd.to_numeric(df['menseki'])
df['years'] = pd.to_numeric(df['years'])
#csv書き込み
df.to_csv("sumodata{}process.csv".format(a), encoding="CP932")
取得したデータの選定
Pythonで作ったCSVをRで読み込んで分析しました。
結論から言うと、 ①20分県内のデータを用いて、②家賃は15万円以下に制限し、③間取りは1DK、1K、1LDK、1R、2DK、2K、2LDKに絞って分析 することにしました。
理由は2つあります。
① それぞれデータの家賃の差異があまりないため。
以下の表は左から20分圏内、40分圏内、60分圏内それぞれのデータの家賃の第一四分位数、中央値、平均値、第三四分位数を表したものです。(単位は万円)

表を見ると、それぞれ差異は、2000円です。
この差異を考慮するよりも、通学時間を考慮したほうがいいと判断し、20分圏内のデータを使用する方がよいと考えました。
② 大学生の一人暮らしに適さない物件が多く含まれているため。
図は、横軸:家賃(万円) 縦軸:間取りの散布図です。(60分圏内の物件データを使用)
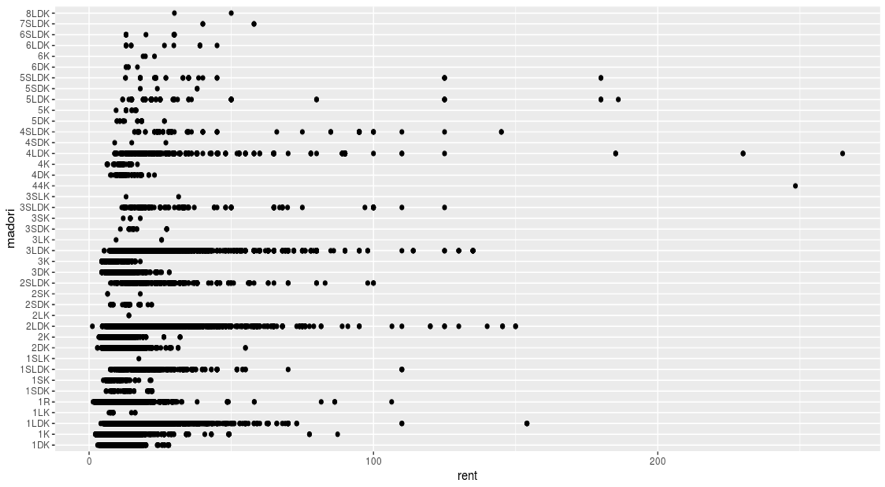
まず、家賃の目盛が0から300まであります。大学生の一人暮らしを考えると、300万円の物件を借りることは考えられません。
より適切に物件探しを行うために、家賃の上限を決める必要があります。
ここでは、15万円を上限に設定しました。
次に、家賃15万円を上限にした散布図を見ます。(60分圏内、家賃15万円以下に制限したデータを使用)
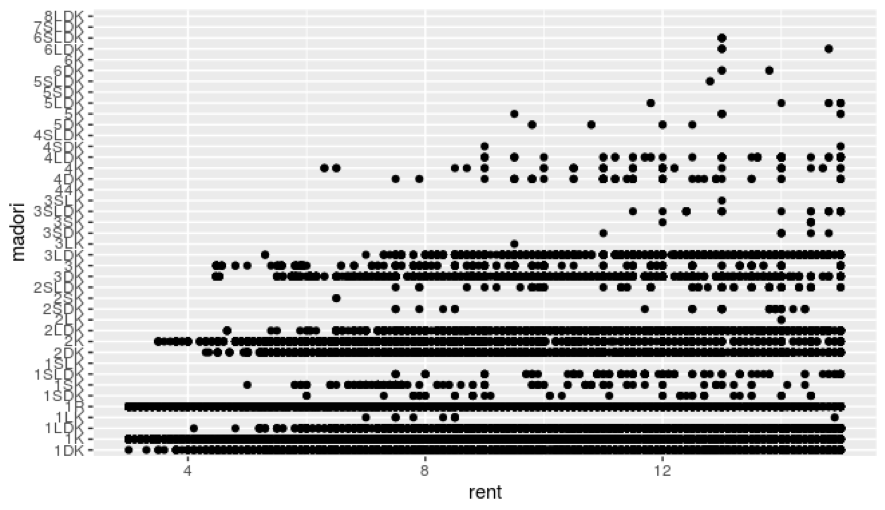
物件が多い間取りは、1DK、1K、1LDK、1R、2DK、2K、2LDK、3DK、3LDKが挙げられます。
大学生の一人暮らしを考慮すると、1K、1Rが候補に挙がりやすいと思います。
その中で、大学生の一人暮らしを考慮すると、3DK、3LDKを借りることは考えにくいです。
一方で 1DKや1LDK、2DK、2LDKが家賃の側面から見ると、大学生の一人暮らしの候補に挙げても良いと思われます。 (1Kや1Rに負けないぐらいの物件数があるということ。)
データを可視化した中で、この発見は驚きでした。
ですので、間取りは、1DK、1K、1LDK、1R、2DK、2K、2LDKに絞って分析します。
以上の理由より、データを選定します。
以下がデータを選定するコードです。
import pandas as pd
from pandas import Series
# CSV読み込み
df20 = pd.read_csv("sumodata20process.csv", encoding="CP932")
# 家賃15万円以下&1R,1K,1DK,1LDK,2DK,2K,2LDKを抽出
df1 = df20[(df20["rent"] <= 15) & (df20["madori"] == "1R")]
df2 = df20[(df20["rent"] <= 15) & (df20["madori"] == "1K")]
df3 = df20[(df20["rent"] <= 15) & (df20["madori"] == "1DK")]
df4 = df20[(df20["rent"] <= 15) & (df20["madori"] == "1LDK")]
df5 = df20[(df20["rent"] <= 15) & (df20["madori"] == "2DK")]
df6 = df20[(df20["rent"] <= 15) & (df20["madori"] == "2K")]
df7 = df20[(df20["rent"] <= 15) & (df20["madori"] == "2LDK")]
# データフレーム結合&CSVへ書き込み
df8 = pd.concat([df1,df2,df3,df4,df5,df6,df7])
df8.to_csv("sumodata.csv",encoding="CP932")
選定したデータの可視化と結果・考察
選定したデータを以下の図のように可視化しました。
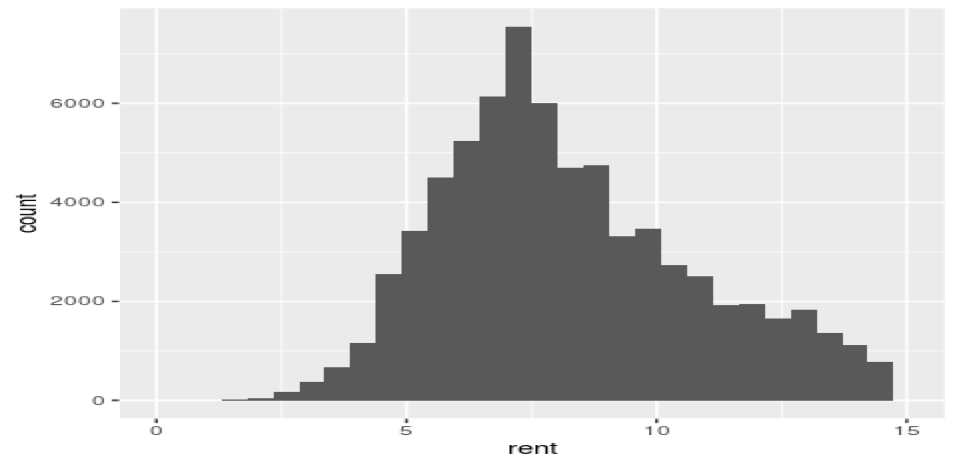
図1 家賃のヒストグラム(20分圏内、家賃15万円以下、間取り1R,1K,1DK,1LDK,2DK,2K,2LDKに制限したデータを使用)
最小値:1.4万円 第一四分位数:6.4万円 中央値:7.9万円 平均値:8.271万円 第三四分位数:9.9万円 最大値:14.950万円 最頻値: 7万円 (単位:万円)
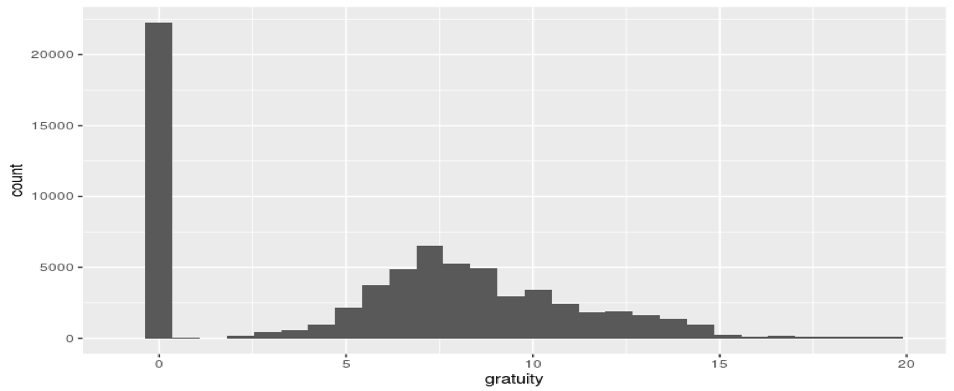
図2 管理費のヒストグラム(20分圏内、家賃15万円以下、間取り1R,1K,1DK,1LDK,2DK,2K,2LDKに制限したデータを使用)
最小値:0円 第一四分位数:0円 中央値:6.8千円 平均値:6.139千円 第三四分位数:9.3千円 最大値:192.100千円 最頻値:0円 (単位:千円)
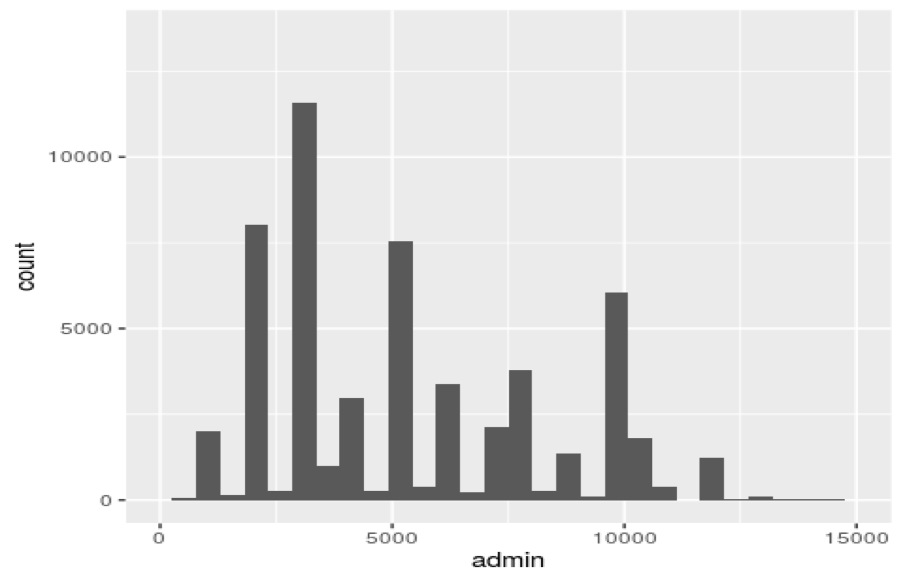
図3 敷金のヒストグラム (20分圏内、家賃15万円以下、間取り1R,1K,1DK,1LDK,2DK,2K,2LDKに制限したデータを使用)
最小値:0円 第一四分位数:2000円 中央値:3000円 平均値:4556円 第三四分位数:7000円 最大値:105000円 最頻値:0円 (単位:円)
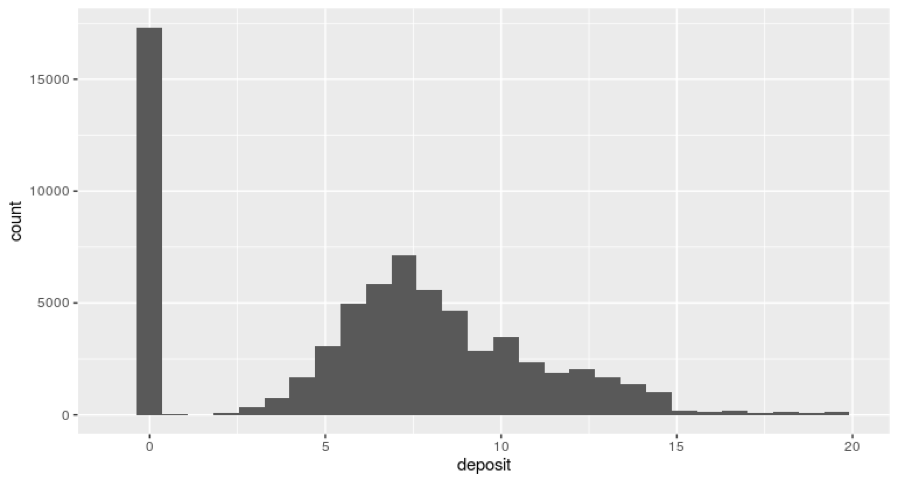
図4 礼金のヒストグラム (20分圏内、家賃15万円以下、間取り1R,1K,1DK,1LDK,2DK,2K,2LDKに制限したデータを使用)
最小値:0円 第一四分位数:3千円 中央値:7千円 平均値:6.655千円 第三四分位数:9.400千円 最大値:74千円 最頻値:0円 (単位:円)
ヒストグラムのまとめ
① 物件は家賃79,000円、敷金2000円~5000円または0円、礼金、管理費共に0円で探すことが妥当です。
② 選定したデータの特徴として、板橋区と練馬区に池袋から近い物件が多いです
➡板橋区には、東武東上線、JR埼京線など、練馬区には西武池袋線など多くの路線が通っているためです。
下の図は選定したデータの住所と最寄り駅の最頻値を表しています。
例えば、このデータにおける物件で、一番多い住所は東京都板橋区板橋3、一番多い最寄り駅はJR埼京線/板橋駅です。
板橋区、練馬区の他に杉並区に多くの物件があります。
しかし、乗り換えがあったりしますので、お勧めできません。
(20分圏内、家賃15万円以下、間取り1R,1K,1DK,1LDK,2DK,2K,2LDKに制限したデータを使用)

さらに、間取りごとに家賃の統計量などを見てみましょう。
上の結論は、1DK、1K、1LDK、1R、2DK、2K、2LDK、すべてを合わせた結論です。
ここでは、間取りごとの特徴を見ます。
データの可視化
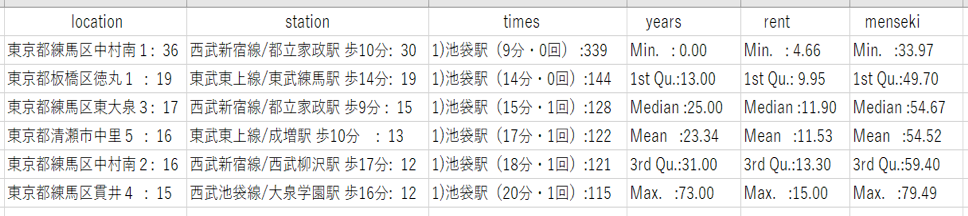
図5 1DKの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量 (物件数:4306件 20分圏内のデータを使用)
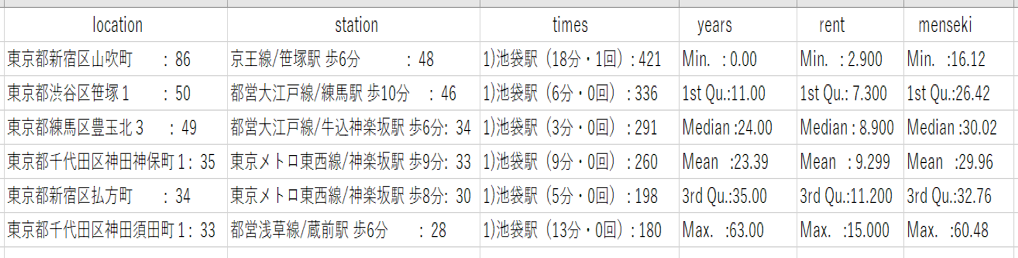
図6 1Kの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量
(物件数:28614件 20分圏内のデータを使用)
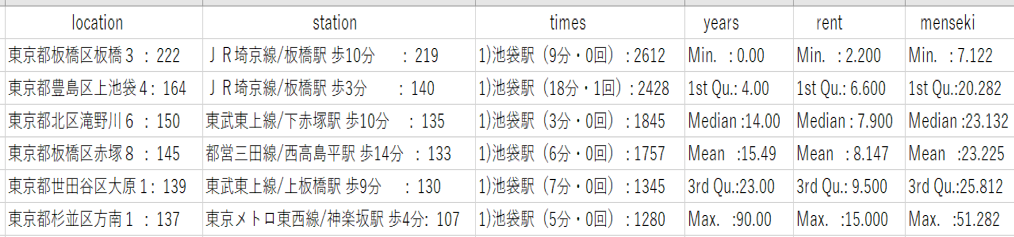
図7 1LDKの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量(物件数:5058件 20分圏内のデータを使用)
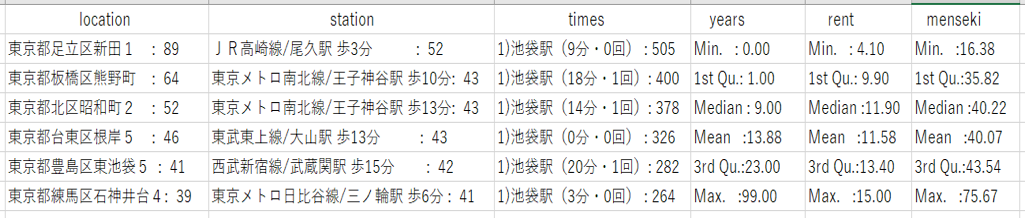
図8 1Rの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量
(物件数:12949件 20分圏内のデータを使用)
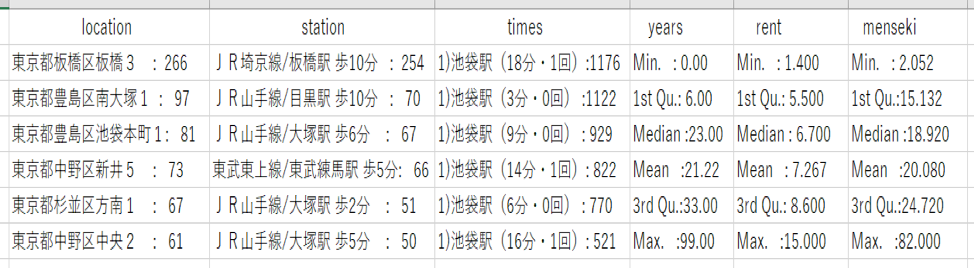
図9 2DKの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量(物件数:3771件 20分圏内のデータを使用)
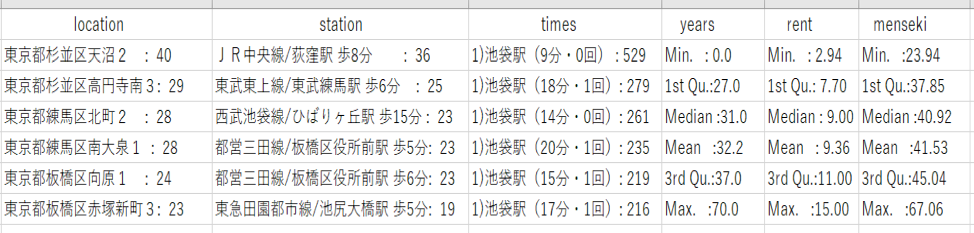
図10 2Kの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量
(物件数:2056件 20分圏内のデータを使用)
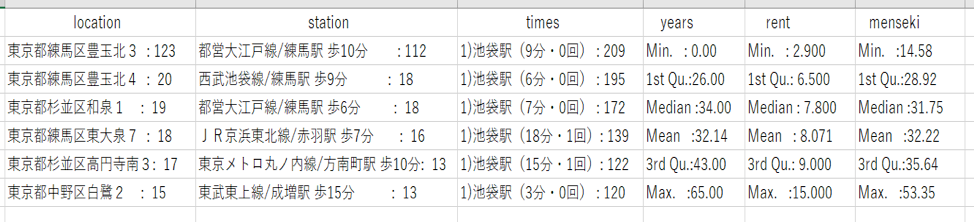
図11 2LDKの住所、最寄り駅、乗り換え回数、築年数の最頻値と家賃、専有面積の統計量(物件数:1703件 20分圏内のデータを使用)
まず、家賃の中央値を見てみると、
1R<2K<1K<1DK<2DK<1LDK<2LDK
の順に、家賃が高くなっています。
ここで、不思議に感じる点は、2Kと1Kの位置です。
2Kと1Kを比較した時、1Kの方が安いはずだと普通は考えると思います。
なので、もう少し分析してみましょう。
間取りと似た概念に専有面積があります。
確かに、間取りが多ければ専有面積が大きいといえますが、その逆は成立しません。
というのも、例えば、20㎡の2K(10㎡の部屋が二つ)、20㎡の1K(20㎡の部屋が一つ)というパターンが考えられるからです。
つまり、家賃に影響を与えている要因に、間取りではなく、専有面積が当てはまると考えられます。
それを散布図などで確認したいと思います。
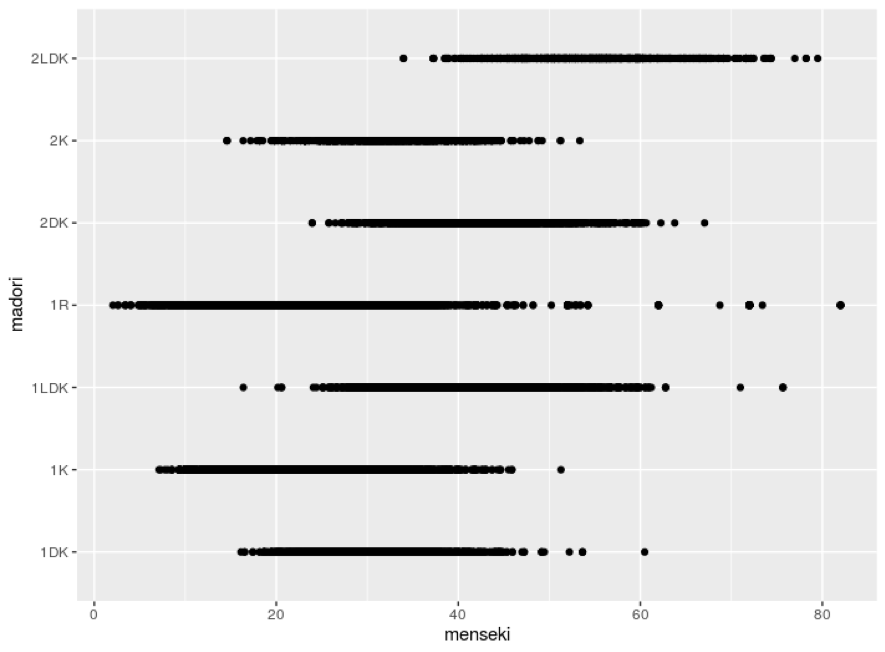
図12 専有面積と間取りの散布図(20分圏内のデータを使用)
専有面積が大きいと間取りも大きくなるが、差があまりなく、間取りそれぞれの帯が重なっています。
つまり、面積と間取りの関係はあまりないと考えられます。
次に、専有面積と家賃の散布図を見ます。
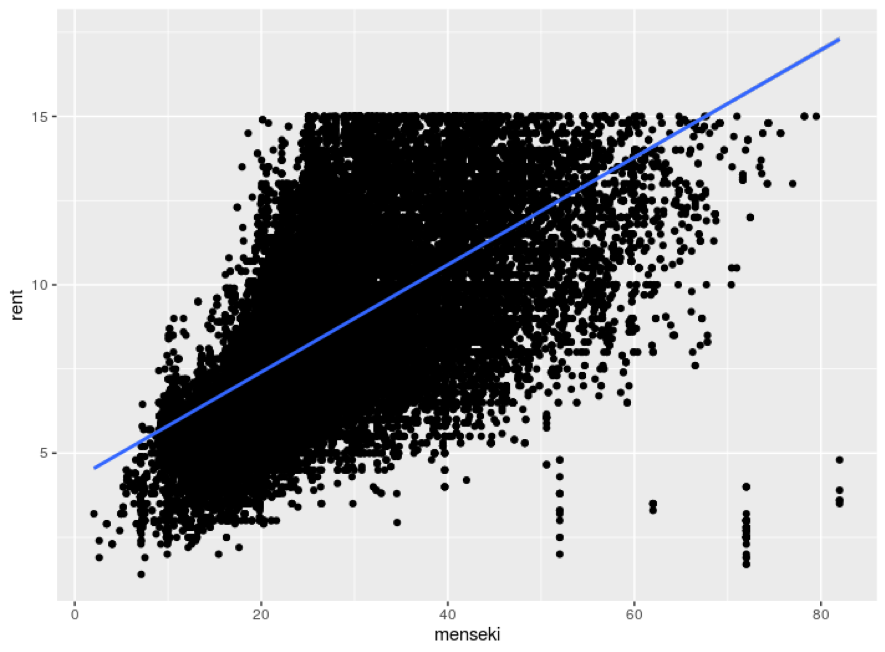
図13 専有面積と家賃の散布図(20分圏内のデータを使用)
青い線は回帰線を表しています。
図13を見てみると、正の相関関係があることがわかります。
間取りは専有面積を考慮に入れて区切るため専有面積とはある程度の関係があると考えられ、間取りは家賃に影響を与えているように見えます。しかし、間取りと家賃との間に専有面積という隠れた変数が存在しているため、間取りが家賃に影響を与えているように見えます。
なので、間取りよりも専有面積の大きさを考える必要があります。
専有面積を見てみると、1Kの専有面積の中央値は23.132㎡、2Kの専有面積の中央値は31.75㎡です。
先ほど、出した結論とは異なる結果が出ました。
つまり、専有面積ではなく、他の要因が家賃に影響を与えていると考えられます。
専有面積の次に考えるべき、家賃に影響を与える要因は、築年数でしょう。
家賃を決定する要因として、場所が挙げられますが、今回は池袋から20分圏内の物件に制限しているため、ある程度場所は確定されてしまします。
なので、築年数と家賃の散布図を見てみましょう。
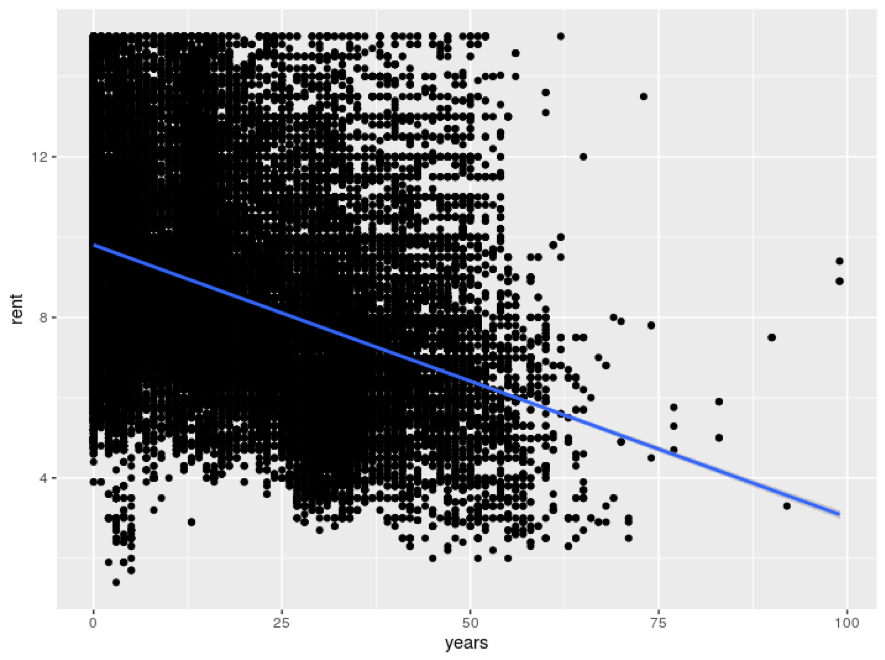
図14 建物の築年数(years)と家賃の散布図(20分圏内のデータを使用)
築年数と家賃との間には、負の相関関係が見られます。
1K、2Kのそれぞれの築年数の中央値を見ると、14年と34年です。
何故、1Kより2Kの方が安いのか、 それは築年数が大きい物件が2Kに多くあるからである という結論に至りました。
更に、物件数を見てみると、1Rと1Kが1万件を超えており、効率的に探すにはこの2つの間取りに制限して探すことがよいです。
故に、家賃、築年数、家賃の3つ全てを要求するならば、1Rまたは1Kで探すのが妥当だと思います。
以上を踏まえて、
板橋区または練馬区で、物件は家賃79,000円、敷金2000円~5000円または0円、礼金、管理費共に0円の条件 で探せば、効率的に納得のいく物件を探すことが出来ます。
終わりに
新しく学んだこと
Pythonでのコーディング、文字列の意味やhtmlの扱い方、Linuxの使い方などを学べました。
データサイエンスだけでなく、コンピューターサイエンスも学ぶ必要があると感じました。
反省点
Pythonでのコーディングに、多くの時間をかけすぎてしまったことが大きな反省です。
全体の工程でかかった時間の3/4はコーディングに当てていたと感じています。
時間を無駄にしないためにも、自分で解決すべきか、質問すべきかを判断すべき力を今後身に着けたいです。
Rを経験している僕が、pythonに苦戦していたので、この記事を読んでくださったプログラム未経験の方にはpythonがとてもハードルが高く感じるかもしれせん。
ですが、決してそんなことありません。
僕がRでやってきたことは、整形されたデータをグラフにしたり、回帰分析を行ったりすることでした。なので、この記事にあるようなクローリングやスクレイピングにあるようなfor文、if文をRで書いたことはありません。つまり、僕はRでアルゴリズムを組んだことはありませんでした。
僕はこの課題を通して感じたことは、データの取得の時は本当にプログラミングのように、アルゴリズムを組んでいく必要があり、一方で、データを可視化する際にはその必要がないということです。
僕はこのアルゴリズムでつまずくことが多かったです。そのため、多くの時間を費やしたと思います。
頂いたフィードバック
率直に、プレゼンの内容が伝わらないという意見を頂きました。1枚1枚のスライドの内容は良いが、その繋がりが見えにくい。だから、1度相手の立場になって、どういうストーリーなら伝えられるのかを考えて、スライドの「配列」を変えてみてというアドバイスでした。
スライドの配列を変えて、再度プレゼンを行ってみると、良い評価を頂けました。
配列を変えるだけで、反応がここまで変わるとは思いませんでした。
また、最初分析した際に、間取りの制限を1Rと1Kの二つにしました。それに対して、散布図上では、1DKと2Kとかは1R、1Kに負けないぐらいの物件数があるのに、何故1DKや2Kを省いたのかわからないとご指摘いただきました。大学生の一人暮らしは1Kか1Rだろうという思い込みで制限したために起きた失敗でした。 データ分析をする際に常識や主観を常に疑う姿勢が大事だと感じました。
以上が、僕の課題のまとめになります。