こんにちは。大学3年でマーケティングを専攻している K.I と申します。
僕がインターンをしている、かっこ株式会社のデータサイエンス事業部では、試用期間に、クローラーを作ってデータを収集、加工、可視化し、わかったことについて簡単に考察を述べるという課題が出ます。
僕の場合は、都内のラーメン店について
ラーメン店が、どの駅にどれだけ集積していて、およそ幾らが一杯あたりの予算目安なのかを明らかにするという課題が出されました。
そこで、アウトプットとして、ラーメン店集積数トップ5の駅とそれぞれの駅の一杯あたり平均予算等、ラーメン店の傾向について発表しようと考えました。
今回、僕の課題で対象にしたサイトは、ラーメンデータベースさんです。
課題開始時のスキル
Pythonは触れたことがなく、HTML/CSSの知識があるくらいでした。
全体の手順
① 一覧ページを開く
② 詳細ページのHTMLを取得
③ 詳細ページの中から必要な情報を取得
④ データの集計・分析・考察
⑤ まとめ
※実行環境は Linux
一覧ページ
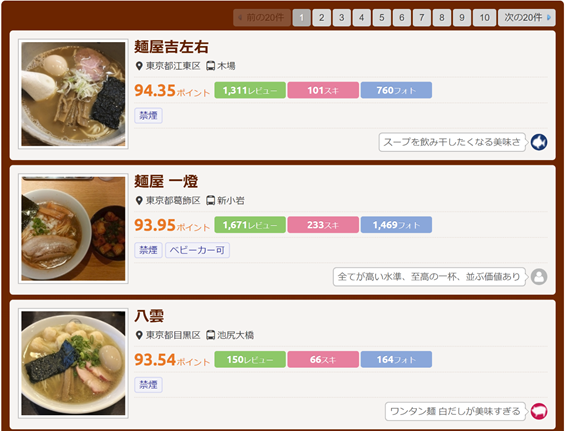
ここから「麺屋 一燈」の詳細ページに飛び、以下のページを取得します。

この詳細ページの中から{①店名、②最寄り駅、③価格、④メニュー名}を取得していきます。
クローリング時の条件
下のように「提供終了」店舗が562ページに出てくるまでクローリング(2019/04/10時点)
スクレイピング時の条件
・今回はメニュー欄の1番上に表示されたものを各店のおすすめラーメンとし、そのメニューの価格を1杯あたりの平均予算としていく
・価格は300円以上に設定(誤って替え玉を取得することを防ぐため)
クローリング
使用するモジュール
クローリング、スクレイピングにはrequestsとBeautifulsoupのモジュールを使いました。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin #urlを解析するため
import os
import time
'https://ramendb.supleks.jp/search?page=X&state=tokyo&city=&order=point&station-id=0'
page=X (X=1~562まで)
front = 'https://ramendb.supleks.jp/search?page='
behind = '&state=tokyo&city=&order=point&station-id=0'
# 562ページまで最新情報が更新されているページのため
for r in range(562):
response = requests.get(front + str(r + 1) + behind)
time.sleep(1)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'html.parser')
詳細ページをクローリングしていきます。
for a_detail in a_details:
# 提供終了と記載された店が発見された場合
n_tags = a_detail.select('span[class="status_plate without"]')
if bool(n_tags) == True:
break
else:
# 詳細ページのURLを取得
a_tag = a_detail.find('a')
href = a_tag['href']
detail_url = urljoin(url, href)
detail_response = requests.get(detail_url)
time.sleep(1)
スクレイピング
使用するモジュール
from bs4 import BeautifulSoup
import csv #csv操作のため
import os
import re #正規表現操作を行うため
from tqdm import tqdm #処理の進捗状況を表示するため
店舗名・最寄り駅をスクレイピングしていきます。
# 店舗名
store = ramen_html.findAll('span', itemprop="name")[0].text.strip()
store = store.encode('cp932', 'ignore').decode('cp932')
# 最寄り駅
station_first = ramen_html.findAll('a', href_="")
for station_url in station_first:
if 'search?station-id' in station_url.get('href'):
station = station_url.text.encode('cp932', 'ignore').decode('cp932')
価格・メニューをスクレイピングしていきます。
手順
① メニュー欄の一覧を抜き出す
② メニュー欄がないページの処理
③ メニュー欄にのっているキーワードリストを作る
④ リストに入っている中で、一覧の先頭に来たメニューの数値のみを取り出す ⇒ 価格取得完了
⑤ メニュー名から不要な数値・記号を削除 ⇒ メニュー取得完了
# メニュー:一覧
menu_all = ramen_html.findAll('p', class_="more")
# メニュー欄がそもそもない場合の処理
try:
menu = menu_all[0].text.split('\n')
cr_count += 1
except IndexError as e:
menu = ("")
no_count += 1
pass
# メニュー:キーワード
keyword_list = ['つけ麺', 'らーめん', 'らぁめん', 'ワンタン麺', 'ラーメン', '拉麺'
, '冷やし中華', '冷し中華','そば', '醤油', '塩', '豚骨', '味噌', '担々麺', 'ソバ'
, 'スペシャル', 'ブタ', 'ラ-メン', 'ぶた2','小豚', '普通', '通常', '蕎麦', '琥珀'
, '冬', 'ぬーどる','白丸','担担麺','湯麺','クエッティオ','タンメン', '豚王', 'つけめん'
, 'まぜまぜ', 'たんたん', '蘭州', 'らうめん', 'カラツケ', 'ちゃんぽん','じゃんがら', 'AKA'
, 'とんこつ', 'かけ', 'SOBA', '白湯', 'Regular','坦々麺','しょうゆ','しょう油']
# 最初に出力された値段を含むメニューのみ表示
flag = False
menu_first = ''
for keyword in menu:
for more in keyword_list:
keyword = keyword.replace('¥', '¥').replace(' ',' ')
if re.search(more, keyword) and re.findall(r'[0-9]{3,4}', keyword) and (('円' in keyword) or ('¥' in keyword)):
menu_first = keyword
raw_price = re.sub("[:,]", "", menu_first) # 記号削除
#数値以外削除
if ('円' in raw_price):
price = re.findall(r'[0-9]{3,4} {0,1}円', raw_price)
price = price[0].replace('円', "")
if ('¥' in raw_price):
price = re.findall(r'¥ {0,2}[0-9]{3,4}', raw_price)
price = price[0].replace('¥', "")
if len(price) != 0:
price = price
price = price.encode('cp932', 'ignore').decode('cp932')
else:
price = None
#300円以上かつ、以下の文字を含まないようにする
if (re.search('セット', menu_first) or re.search('限定', menu_first) or re.search('コース', menu_first) or (int(price) < 300)):
menu_first = ''
price = ''
pass
else:
flag = True
break
if flag:
break
## メニュー名
menu_first = re.sub('[円¥¥g元に戻す㌘…◎●■◆★*+.・、:他⇒→/:,-_]', "", menu_first) # 不要な記号等削除
menu_first = re.sub(r'[0-9]{3,6}', "", menu_first) # 不要な数値削除
menu = menu_first.encode('cp932', 'ignore').decode('cp932')
以上の結果、csvに出力されたデータである11229件のラーメン店の各項目が出力されます。
妥当性の検証
サイトに表示された件数と集計した件数の整合をスクレイピング時に確認します。
・今回のサイト(ラーメンデータベース)にはサイト合計件数が表示されていないため1ページごとの表示件数(20件)にページ数をかけて計算していきます。
・Try構文の中でメニュー欄のなかった店舗が2412件ということも分かりました。

可視化
[価格]
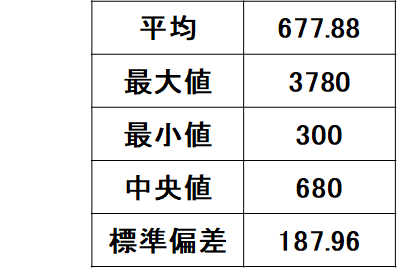
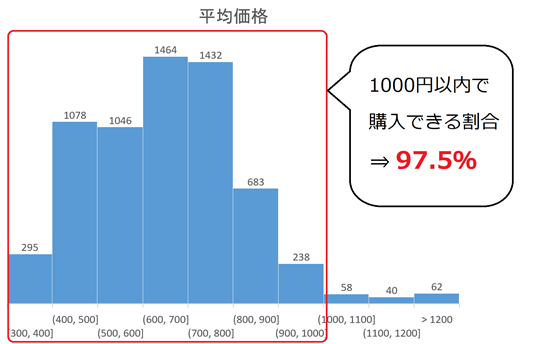
[集積数と平均価格]


[ジャンル]
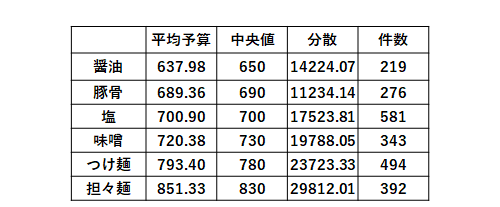

分析結果
・ジャンル別の価格を見ると担々麺が平均予算・中央値ともに高く、ばらつきは大きい。反対に醤油の価格が最も低い。東京では塩ラーメンの店が多い。
・山手線より内側はラーメン店は多くない傾向にある。
山手線より外側では東のほうが西よりラーメン店は多い傾向にある。
平均価格は恵比寿駅が高く、小岩駅・新小岩駅が安い。
・1000円以内でラーメンが買える割合は97.50%
・最高額は「銀座アスター プティシーヌ上野店」の「鮑とタラバ蟹と海老のあんかけ麺 3780円」
以上のことが分かりました。
考察
・恵比寿駅の平均価格が高い要因は担々麺の割合が多いことが考えられる。
・手持ちがなくてラーメンが食べたくなったらとりあえず醤油ラーメンのお店を探してみるのが得策であろう。
・ラーメン店の多い小岩駅・新小岩駅あたりは財布にも優しく、気軽に行きやすい環境にある。
・23区内では東のほうが平均価格が安くて、店舗数も多い傾向にある。
→乗降客数と地価が関係しているのではないか?
・東京でラーメンが食べたいと思った場合、とりあえず1000円持っていれば食べることができるであろう。
以上の考察となりました。
考察も含めた反省点
・今回はExcelのみで可視化を行ったが、pandasなどを使えるようになるとより楽になると思いました。
・ラーメン店の傾向を見つける作業で、今回はメニュー欄の1番上とした。店舗名に「塩ラーメン○○」という店があったが、メニューの詳細が無かったため、可視化でのジャンルには含めなかったものを含めると、さらに正確なデータに近づくと感じました。(下図は例)

その他
新しく学んだこと
PythonとLinuxはゼロから学びました。
難しかったこと、苦労したことおよび、それをどう乗り越えたか
・スクレイピング・クローリングはもちろんPythonを触ったことがなかったため、どう進めていけばいいかという点でまず苦労しました。
そのため、Python(スクレイピング等)における参考書を購入し、インプットとアウトプットを繰り返しました。
・ラーメンデータベースというサイトはスクレイピングを行う上で、手間のかかる作業であり、難しさもありました。(例えばメニュー欄が店舗によって大きく形式が違うなど)自分の知識がない面も多分にあり、今回のスクレイピングが効率的かつ正確性のあるアプローチで行えていたのか自信はありません。しかし、地道に行い、時間をかけつつ、少しでも分析を行いやすいように不要な情報を消していくことができたと思います。
課題過程での質問とフィードバック
・メニュー欄が複雑で必要なデータを取得できなかった
⇒半角と全角両方の不要な文字が含まれているので、まずは半角に統一した方がよい
・csvに出力されたローデータを少しでもきれいにすること
⇒正規表現を使って修正した方がよい
・パワーポイントでの発表の仕方に関して
⇒説明を一通り行ったら、まとめのスライドをつくるとわかりやすい
⇒一番はじめに結論となる結果・考察をもってくるという選択肢もある
以上のようなアドバイスをいただきました。
最後に
初めてデータを収集・分析し、そこから考察を行うという一通りの流れを体験しましたが、データを収集する時間がこんなにも大変なことだとは思いませんでした。
研修課題ながら、非常に貴重な体験ができました。