私がインターンをしている、かっこ株式会社のデータサイエンス事業部では、試用期間にクローラーを作ってデータを収集、加工、可視化し、わかったことについて簡単に考察を述べるという課題が出ます。
以下の試用課題に取り組んだ大学三年生のM.Kです。
情報工学科に所属しており、大学では情報系に関係することを幅広く勉強しています。
Pythonは大学の実験で少し触った程度です。
課題
テーマ
アルバイト未経験で新しく始めようと思っている友達がいるとします。その友達はアルバイトの選び方がわかりません。その友達を助けるためにデータ分析を用いて判断材料となるデータを挙げ、あなたのおすすめを教えてください。このとき対象は山手線沿線沿いとする。
使用サイト:バイトル
方針
- アルバイト選びのポイントを紹介
- 各ポイントをデータ分析によって評価
- 全ポイントから総合的にアルバイトを評価
このときアルバイト選びのポイントは主観的に選びました。
アルバイト選びのポイント
- 出勤日数
- 交通費支給の有無
- 時給
- 年齢層
- 雰囲気
- 男女比
- 駅(今回は山手線沿いの条件があったので注目していません)
これらのポイントをデータ分析したいと考え、以下の青マーカー部分をスクレイピングで取得しました。
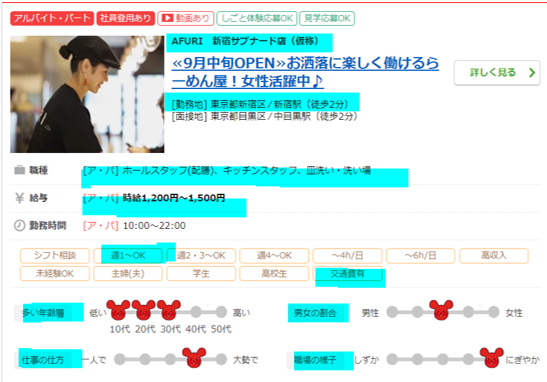
プログラミング方針
- クローリング
- 使用サイトのURLを取得
- ページネーションから対象となる総ページ数を取得
- 対象ページをすべてhtml形式で保存
- スクレイピング
- 取得したhtmlファイルを1ページずつ読み込む
- 求人ごとに変数へ保存
- 求人ごとに上記画像の青マーク部分を変数として取得
- 取得した変数をExcelで分析できるようにcsv形式で保存
コーディング
クローリング・スクレイピング共に使用したモジュールは以下の通りです。
import requests
from bs4 import BeautifulSoup
import re
import crawling
import os
クローリング
1. 使用サイトのURLを取得
base_url= "https://www.baitoru.com/kanto/jlist/"
station_url: str = "yamanotesen/"
url: str = base_url + station_url
2. ページネーションから対象となる総ページ数を取得
page_num = bs.find("li",class_="last").get_text().strip()
print(page_num)
newdir = "crawled_file"
if os.path.exists(newdir):
print("exist.")
else:
os.mkdir(newdir)
with open('./crawled_file/page_number.txt', 'w') as file:
file.write(page_num)
3. 対象ページをすべてhtml形式で保存
#全ページをhtmlに保存
for i in range(2 , int(page_num)+1) :
page_url : str = url + "page" + str(i)
response = requests.get(page_url)
response.encoding = response.apparent_encoding
bs = BeautifulSoup(response.text, 'lxml')
time.sleep(1)
with open('./crawled_file/baitoru_{}.html'.format(i), 'w') as file:
file.write(response.text)
スクレイピング
1. 取得したhtmlファイルを1ページずつ読み込む
for i in range(1,int(page_num)+1): #全ページ
baitoru_file = open("./crawled_file/baitoru_{}.html".format(i),"r")
baitoru = baitoru_file.read()
baitoru_file.close()
bs = BeautifulSoup(baitoru, 'lxml')
2. 求人ごとに変数へ保存
#各求人をページ毎にリストに保存
job_list = bs.find_all("article", class_= "list-jobListDetail")
3. 求人ごとに上記画像の青マーク部分を変数として取得
例として給与形態(money_type)と金額(money)について取り上げます。
取得した変数に給与形態が4つあったため、そのうち時給のものにのみ注目してデータ分析を行うことにしました。
for job in job_list: #ページ内の求人ごとに
job_num = job_num + 1
job_money : str = job.find("div",class_="pt03").find_all("dl")[1].find("em").get_text().strip()
#給料形態を取得する。このとき優先順位は時給、日給、月給、完全出来高制にする。
job_money = job_money.replace(",","")
money1 = re.search(r'時給(\d{3,5})円',job_money)
if money1 is None:
money2 = re.search(r'日給(\d{3,5})円',job_money)
if money2 is None:
money3 = re.search(r'月給(.{0,5})円',job_money)
if money3 is None:
money4 = re.search(r'完全出来高制',job_money)
money_type : str = "完全出来高制"
else:
money_type : str = "月給"
else:
money_type : str = "日給"
else:
money_type : str = "時給"
if money_type == "時給":
money = money1.group(1)
elif money_type == "日給":
money = money2.group(1)
elif money_type == "月給":
money = money3.group(1)
else:
money = "完全出来高制"
4. 取得した変数をExcelで分析できるようにcsv形式で保存
"""
各変数を保存する
data1 = 企業名 勤務地 勤務形態 仕事内容
data2 = 給与形態 金額 最低勤務日数(週1日~:1, 週2,3~:2.5, 週4~:4) 交通費支給(有:1, 無:0)
data3 = 年齢層(5段階) 男女比(5段階) 仕事の仕方(5段階) 職場の雰囲気(5段階)
"""
data1 : str = "," + job_name.replace(',','') + "," + job_traffic + "," + job_tipe + "," + job_point
data2 : str = "," + money_type + "," + str(money) + "," + str(job_day) + "," + str(trafic_money)
data3 : str = str(age_mark) + "," + str(mw_mark) + "," + str(work_mark) + "," + str(atm_mark)
data4 : str = str(job_num) + data1 + data2 + data3
data4 = data4.replace('①','')
data4 = data4.replace('②','')
data4 = data4.replace('③','')
data4 = data4.replace('[','(')
data4 = data4.replace(']',')')
data4 = data4.replace('~','~')
# データ保存
print("{}ok".format(job_num))
with open('./result_file2/result.csv', 'a' ,encoding="shift-jis") as file:
file.write(data4)
file.write("\n")
検収条件
検収結果
取得した件数は13720、実際の件数は13712なので件数は一致しませんでした。
一致しなかった原因
クローリング完了時間よりもサイトの更新時間の方が早いためクローリング中にデータ数が変化してしまうためと考えられます。
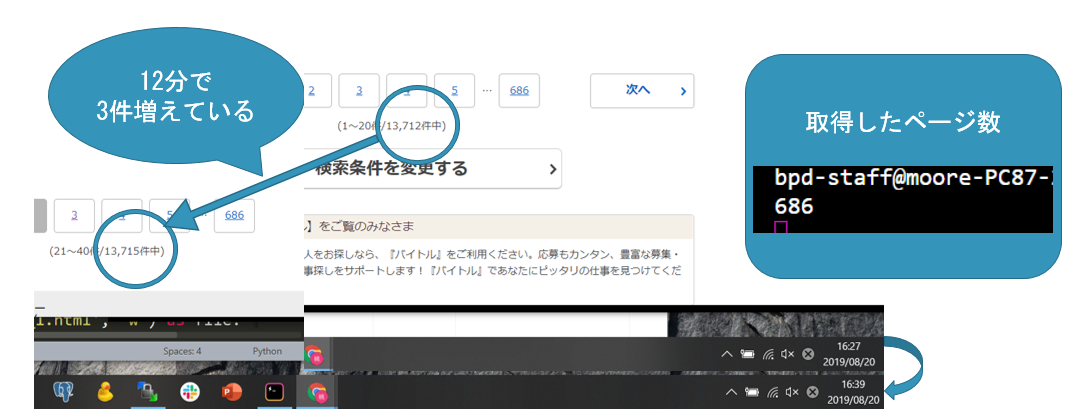
検収条件は満たしているのか
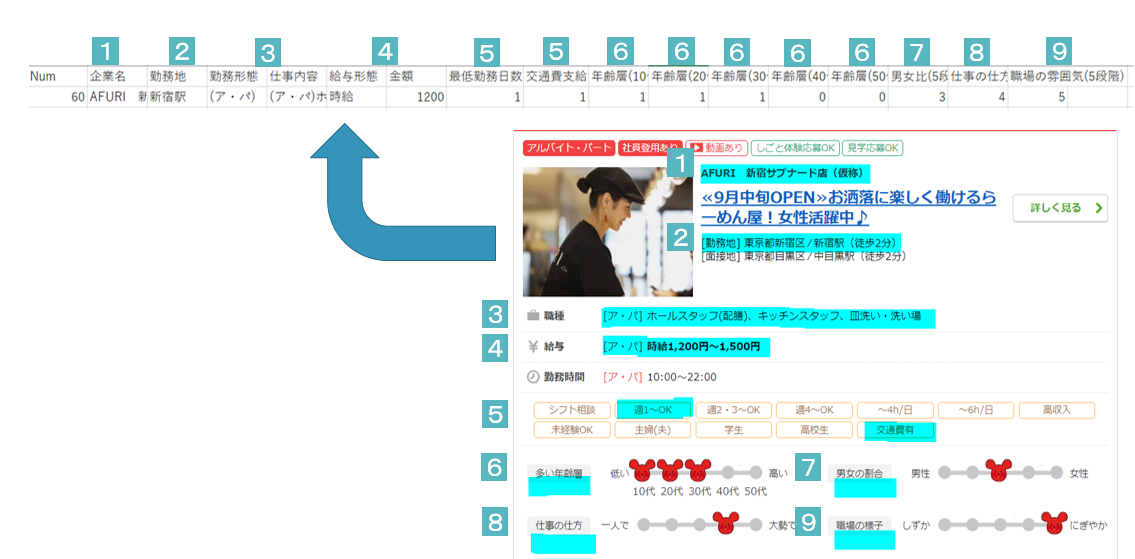
取得ページ数は一致していること、また1~9の各番号の変数が正しく取得できていることが確認できたため検収条件は満たされているものとします。
可視化
仕事内容ごとに取得した各変数についてそれぞれ評価、分類します。
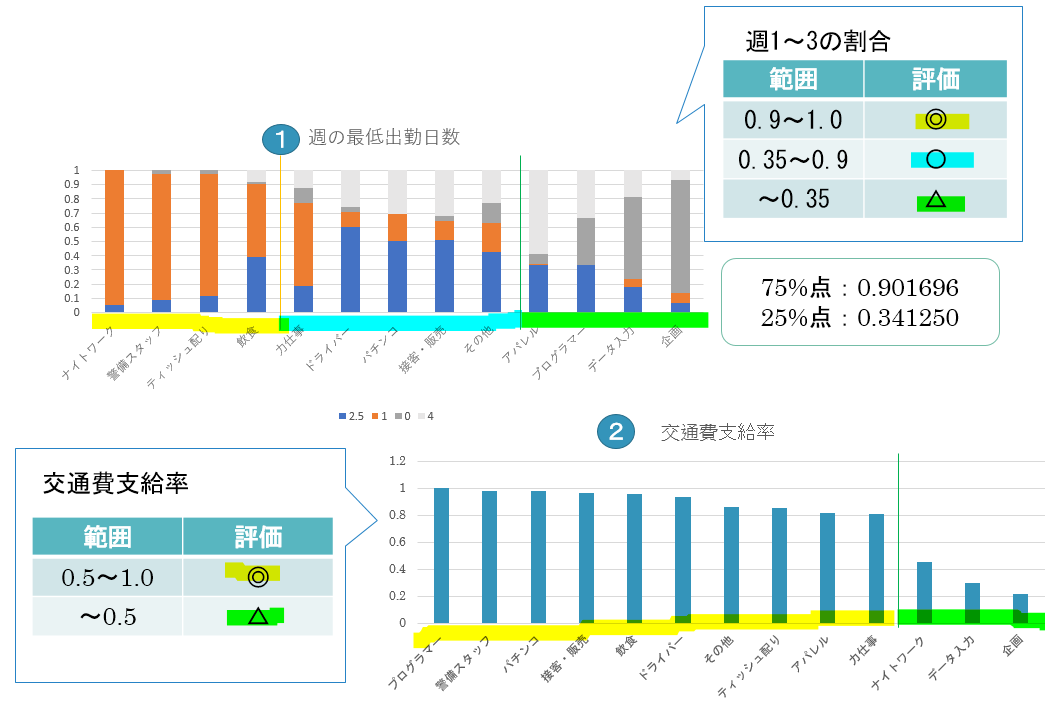
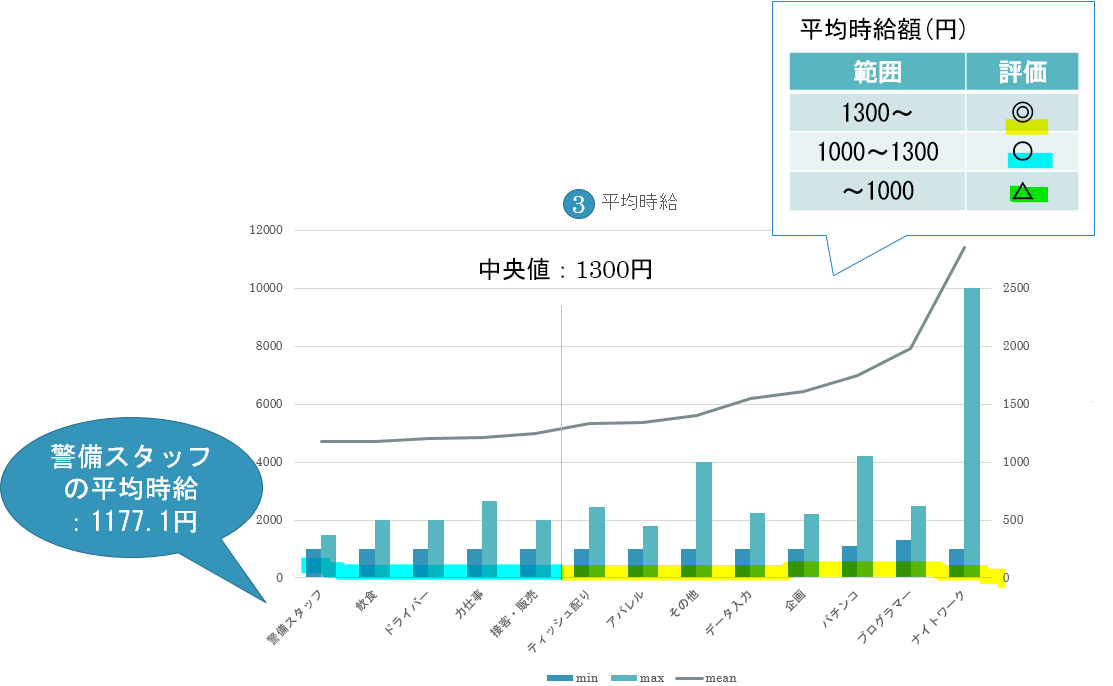
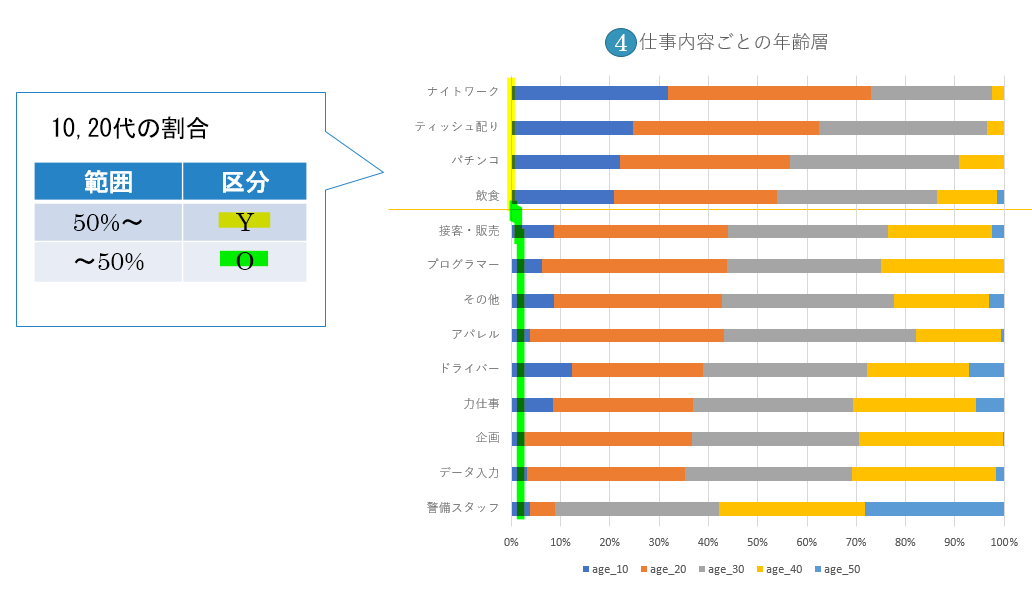
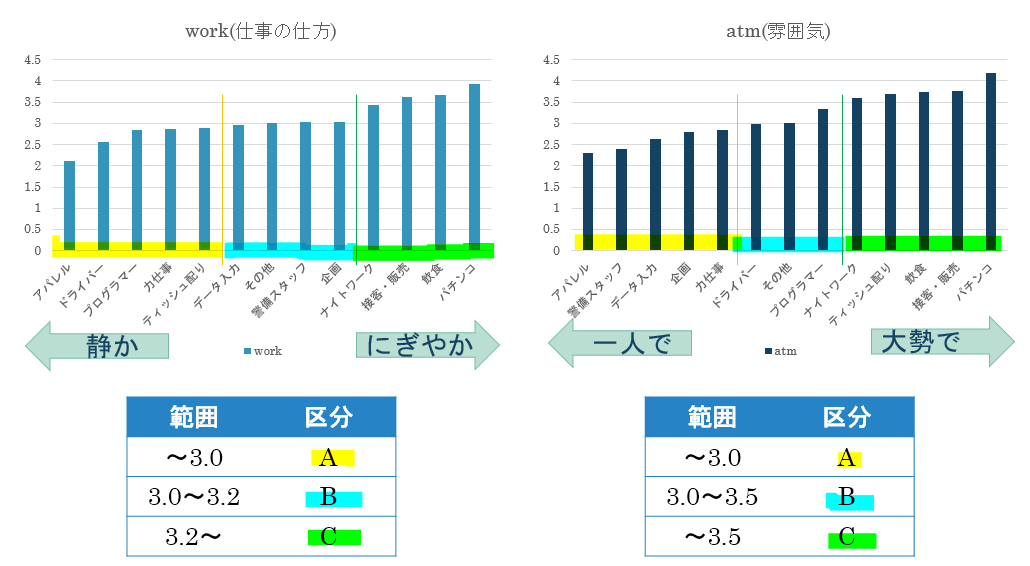
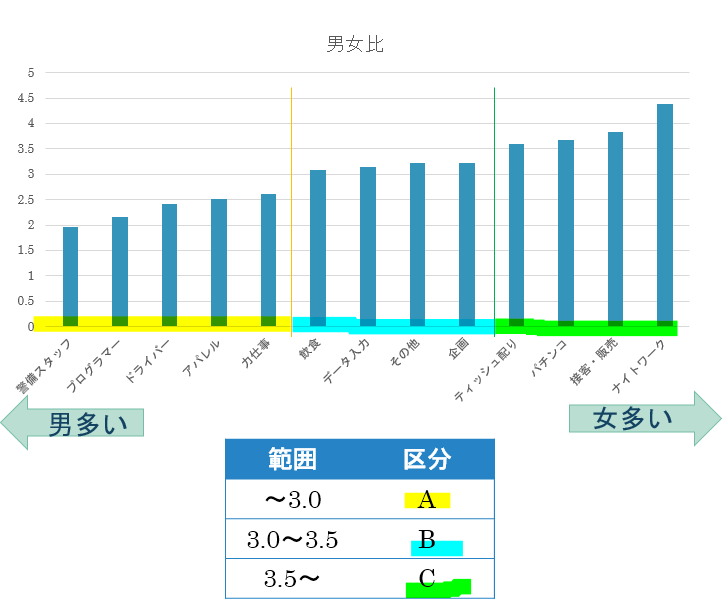
仕事内容ごとに全ての変数の評価、分類結果をまとめた結果が以下の表になります。
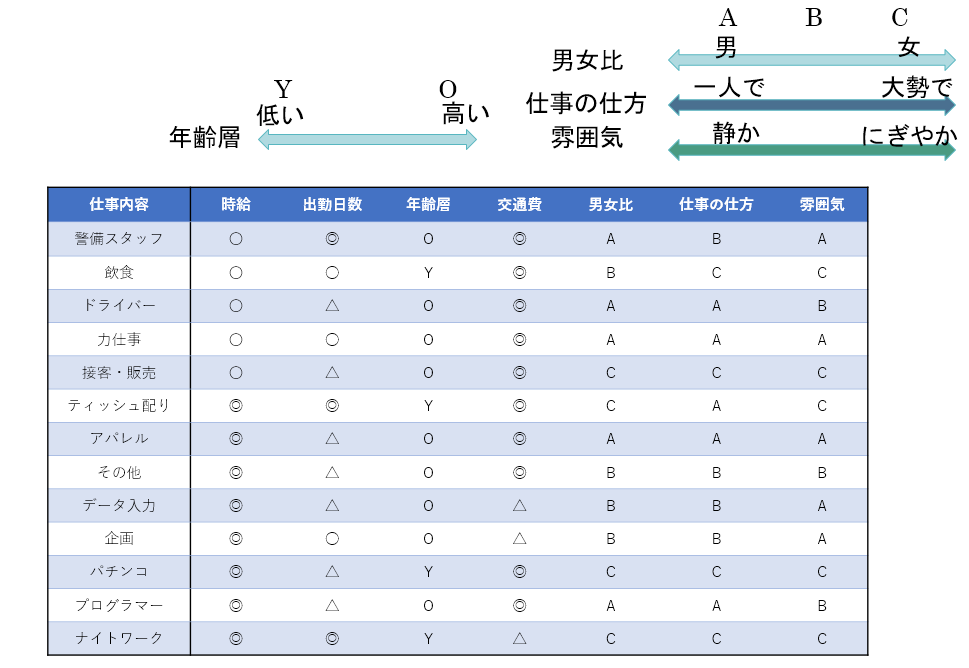
この表に基づいて各ポイントごとに自分の希望を反映させていくことで自分の要望に合う仕事内容を決めることができます。今回の分析結果で意外だったのはティッシュ配りの好条件ぶりです。ちなみに私が大学1年生のときにアルバイトを探そうと考えたときの条件で上記の表に当てはめて仕事内容を探した結果、飲食になりました。

反省点
『職種』という変数があり、自由記述であったため自分で主観的に13個におおまかに分類し『仕事内容』という変数に変更して扱いましたが、その分類の仕方が本当に正しいのかという妥当性を証明できませんでした。仕事内容は正規表現を用いて
- ティッシュ配り
- サンプリング・ティッシュ配り・チラシ配り/ビラ配り、イベントスタッフ、アンケートモニター
- ナイトワーク
- フロアレディ・カウンターレディ(ナイトワーク系)、ガールズバー・キャバクラ・スナックその他(ナイトワーク系)、コスチューム系その他(ナイトワーク系)
- データ入力
- データ入力、タイピング(PC・パソコン・インターネット)、一般事務職、受付
- 飲食
- ホールスタッフ(配膳)、キッチンスタッフ
のように分類していき、どれにも当てはまらないものをその他としました。さらに正確な分類ができればその他の数を減らすことができ、また違う結果が得られたのではないかと思います。
その他
コードレビュー
pythonのコード規約に乗っ取った書き方をすること、正規表現ではより条件を狭めた書き方をする方がよいという指摘を頂きました。
発表レビュー
課題について最終的に何を伝えたいのかという点について考え直すこと、各変数毎への評価について妥当であるのか検討すること、本当に駅について注目しなくてよいのかその理由についてきちんと説明できるようにしておくことなどの指摘を頂きました。
新しく学んだこと
- データ分析の基礎となるスクレイピング、クローリングの技術について
- pythonの書き方の基礎
- 変数毎に適した可視化をすることで第三者にわかりやすく結果を伝えることができるということ
- コードの書き方で今まで自分のことだけを考えて変数名をつけていたが、コードレビューをしていただく機会があったことでコメントの大切さやコードの書き方を他の人と統一する必要性を学びました。
難しかったこと、苦労したことおよび、それをどう乗り越えたか
- pythonをほとんど触ったことがなかったため、やりたいことは明確なのに書き方がわからず苦労しました。他の人のコードを読んだり様々なサイトを参考にし、実際にコードを書いて実行することで書き方を学んでいきました。
- 与えられた課題がやや抽象的だったので何を問われているのか読み解くことが難しく感じました。繰り返し発表レビューをしていただいたことで課題で問われていることが明確になり、発表の仕方を理解することができました。課題が抽象的であったぶん自由度が高かったため幅広い分析ができて良かったと思います。