はじめまして。情報工学科所属の大学三年生S.Iと申します。
Pythonの経験は大学の実験で少し扱った程度です。
私がインターンをしている、かっこ株式会社のデータサイエンス事業部では、試用期間にクローラーを作ってデータを収集、加工、可視化し、わかったことについて簡単に考察を述べるという課題が出ます。
課題
テーマ
大学の友達が一人暮らしをすることになりました。
しかし、不動産サイトを見るとあまりにも物件数が多くて選べません。
データ分析で解決してください。
制約
JR金町駅から通学時間60分圏内
背景
自身の物件探しの経験から物件を探す際に「知りたい情報」というのは、
仲介する不動産屋さんに伝える「物件探しの条件」だと考え、データ分析で解決しようと思った。
方針
- 物件サイト「スマイティ」をクローリングしHTMLファイルとして保存
- 取得したHTMLファイルから各変数をスクレイピング
- データ分析
- 物件探しの条件を提示
クローリング
今回、クローリングするのはスマイティの「通勤・通学時間検索」を利用し、金町駅まで60分圏内の検索結果となっています。
- サイトに掲載されている総物件数をテキストファイルに保存しておく
- 1ページ目のURLを指定しHTMLファイルとして保存
- ページネーションから次ページのURLを取得し遷移する
- 遷移先ページをHTMLファイルとして保存
- 次ページがなくなるまで 2,3 を繰り返す
クローリングのコードは以下のようになっています。
import requests
from bs4 import BeautifulSoup
import time
import os
import datetime
def crawling():
# htmlファイル保存用ディレクトリのパス
dirname = './html_files'
if not os.path.exists(dirname):
# 存在してなかったらディレクトリ作成
os.mkdir(dirname)
# 1ページ目をhtml化
url = "https://sumaity.com/chintai/commute_list/list.php?search_type=c&text_from_stname%5B%5D=%E9%87%91%E7%94%BA&cost_time%5B%5D=60&price_low=&price_high="
response = requests.get(url)
time.sleep(1)
# ファイルに保存
page_count = 1 # ページ数のカウント
with open('./html_files/page{}.html'.format(page_count), 'w', encoding='utf-8') as file:
file.write(response.text)
# 総物件数(理論値)の取得(検収条件とする)
soup = BeautifulSoup(response.content, "lxml")
num_bukken = int(soup.find(class_='searchResultHit').contents[1].text.replace(',', ''))
print("通学時間60分以内の総物件数:", num_bukken)
# スクレイピングの際に検収条件の確認で使うので総物件数をテキストファイルに保存しておく
path = './data.txt'
with open(path, mode='w') as f:
f.write("{}\n".format(num_bukken))
# 2ページ目以降のクローリング,次のページがなくなるまで続ける
while True:
page_count += 1
# 次のurlを探す
next_url = soup.find("li", class_="next")
# 次ページがなくなったらbreakし終了
if next_url == None:
print("総ページ数:", page_count-1)
with open(path, mode='a') as f:
f.write("{}\n".format(page_count-1))
break
# 次ページurlを取得しhtmlファイルとして保存
url = next_url.a.get('href')
response = requests.get(url)
time.sleep(1)
with open('./html_files/page{}.html'.format(page_count), 'w', encoding='utf-8') as file:
file.write(response.text)
# 次ページのurlを取得するために解析準備
soup = BeautifulSoup(response.content, "lxml")
# クローリング進捗の出力
if page_count % 10 == 0:
print(page_count, 'ページ取得')
# メイン関数
if __name__ == "__main__":
date_now = datetime.datetime.now()
print("クローリング開始:", date_now)
crawling()
date_now = datetime.datetime.now()
print("クローリング終了:", date_now)
スクレイピング
以下が今回スクレイピングした変数になります。

- 物件ごとに各変数をスクレイピングしていく
- 変数が出揃ったらレコードとしてCSVファイルに追加
- 整合性がとれているかクローリングで取得した総物件数とレコードの数を照合
スクレイピングのコードは以下のようになっています。
from bs4 import BeautifulSoup
import datetime
import csv
import re
# 住所を都道府県と市区町村に分ける用の正規表現
pat = '(...??[都道府県])((?:旭川|伊達|石狩|盛岡|奥州|田村|南相馬|那須塩原|東村山|武蔵村山|羽村|十日町|上越|富山|野々市|大町|蒲郡|四日市|姫路|大和郡山|廿日市|下>松|岩国|田川|大村|宮古|富良野|別府|佐伯|黒部|小諸|塩尻|玉野|周南)市|(?:余市|高市|[^市]{2,3}?)郡(?:玉村|大町|.{1,5}?)[町村]|(?:.{1,4}市)?[^町]{1,4}?区|.{1,7}?[市町村])(.+)'
def scraping(total_page, room_num):
# 物件数の初期化
room_count = 0
# csvファイルの準備(ヘッダーをつける)
with open('room_data.csv', 'w', newline='', encoding='CP932') as file:
header = ['No', 'building_name', 'category', 'prefecture', 'city', 'station_num', 'station', 'method', 'time', 'age', 'total_stairs', 'stairs', 'layout', 'room_num', 'space', 'south', 'corner', 'rent', 'unit_price', 'url']
writer = csv.DictWriter(file, fieldnames=header)
writer.writeheader()
for page_num in range(total_page):
# スクレイピングの進捗出力
if page_num % 10 == 0:
print(page_num , '/', total_page)
# スクレイピングするhtmlファイルをBeautifulSoupで開く
with open('./html_files/page{}.html'.format(page_num + 1), 'r', encoding='utf-8') as file:
page = file.read()
soup = BeautifulSoup(page, "lxml")
# 建物ごとに情報を取得
building_list = soup.find_all("div", class_="building")
for building in building_list:
# 建物カテゴリー:マンション or アパート or 一戸建て
buildingCategory = building.find(class_="buildingCategory").getText()
# 建物名
buildingName = building.find(class_="buildingName").h3.getText().replace("{}".format(buildingCategory), "").replace("新着あり", "")
# 最寄駅と駅からの距離の候補抽出
traffic = building.find("ul", class_="traffic").find_all("li")
# 最寄駅の数
station_num = len(traffic)
# 徒歩時間が短いものを抽出する
min_time = 1000000 # 所要時間の最小値初期化
for j in range(station_num):
traffic[j] = traffic[j].text
figures = re.findall(r'\d+', traffic[j])
time = 0
for figure in figures:
# 所要時間の計算
time += int(figure)
# 最小だったら最小所要時間とインデックスを保管
if time < min_time:
min_time = time
index = j
# 駅や路線の情報がある場合
if len(traffic[index].split(' ')) > 1:
# 路線の決定
line = traffic[index].split(' ')[0]
# 最寄り駅の決定
station = traffic[index].split(' ')[1].split('駅')[0]
# 駅までの交通手段(バス・車・徒歩)の取得
if len(traffic[index].split(' ')) > 2:
if "バス" in traffic[index].split(' ')[1]:
method = "bus"
elif "車" in traffic[index].split(' ')[2]:
method = "car"
else:
method = "walk"
# 駅までの交通手段情報なし
else:
method = None
# 駅や路線の情報がない場合
else:
station = None
line = None
method = None
time = None
# 住所
address = building.find(class_="address").getText().replace('\n','')
address = re.split(pat, address)
if len(address) < 3:
prefecture = "東京都"
city = "足立区"
else:
prefecture = address[1]
city = address[2]
# 建物の詳細(築年数・構造・総階数)
building_detail = building.find(class_="detailData").find_all("td")
for j in range(len(building_detail)):
building_detail[j] = building_detail[j].text
# ----築年数の数値だけ取得----
# 築年数不詳
if '築不詳' == building_detail[0]:
building_detail[0] = None
# 築0年
elif '未満' in building_detail[0]:
building_detail[0] = 0
# 正常な値
else:
building_detail[0] = int(re.findall(r'\d+', building_detail[0])[0])
# 総階数の数値だけ取得
building_detail[2] = int(re.findall(r'\d+', building_detail[2])[0])
# ---- 部屋の詳細取得 ----
rooms = building.find(class_="detail").find_all("tr",
{'class': ['estate applicable', 'estate applicable gray']})
for j in range(len(rooms)):
# 物件数のカウント
room_count += 1
# ---- 階数 ----
stairs = rooms[j].find("td", class_="roomNumber").text
# 数値だけ取得(「階」削除、欠損値処理)
if "-" == stairs:
stairs = None
else:
stairs = int(re.findall(r'\d+', stairs)[0])
# 家賃を整数型にする
price = rooms[j].find(class_="roomPrice").find_all("p")[0].text
price = round(10000 * float(price.split('万')[0]))
# 管理費
kanri_price = rooms[j].find(class_="roomPrice").find_all("p")[1].text
# 表記の統一(万円表記の削除、「-」と「0円」の欠損値処理)
if "-" in kanri_price or "0円" == kanri_price:
kanri_price = 0
else:
kanri_price = int(kanri_price.split('円')[0].replace(',',''))
# 部屋タイプ(間取り)
room_type = rooms[j].find(class_="type").find_all("p")[0].text
if room_type == "ワンルーム":
room_type = "1R"
# 部屋数
num_of_rooms = int(re.findall(r'\d+', room_type)[0])
# 部屋の面積、単位「m2」の削除
room_area = rooms[j].find(class_="type").find_all("p")[1].text
room_area = float(room_area.split('m')[0])
# 南向き・角部屋
special = rooms[j].find_all("span", class_="specialLabel")
south = 0
corner = 0
for label in range(len(special)):
if "南向き" in special[label].text:
south = 1
if "角部屋" in special[label].text:
corner = 1
# 詳細urlを取得
room_url = rooms[j].find("td", class_="btn").a.get('href')
# 家賃 = 賃料+管理費 を求める
rent = price + kanri_price
# 1m^2ごとの家賃(単価)を求める
unit_price = rent / room_area
# csvファイルへの出力:encordingデフォルトは"utf-8"、windowsで日本語扱うなら"cp932"
with open('room_data.csv', 'a', newline='', encoding='CP932') as file:
writer = csv.DictWriter(file, fieldnames=header)
writer.writerow(
{'No':room_count, 'building_name':buildingName, 'category':buildingCategory, 'prefecture':prefecture, 'city':city, 'station_num':station_num, 'station':station,
'method':method, 'time':min_time, 'age':building_detail[0], 'total_stairs':building_detail[2], 'stairs':stairs,
'layout':room_type, 'room_num':num_of_rooms, 'space':room_area, 'south':south, 'corner':corner, 'rent':rent, 'unit_price':unit_price, 'url':room_url})
print("{}件の物件データを取得しました。".format(room_count))
#検収条件の確認
if room_count == room_num:
print("検収条件をクリア")
else:
print("{}件の差異があります。検収条件をクリアしていません。".format(abs(room_count-room_num)))
if __name__ == "__main__":
date_now = datetime.datetime.now()
print("スクレイピング開始:", date_now)
# 総ページ数と物件数をスクレイピング関数に渡す(検収条件)
path = './data.txt'
with open(path) as f:
data = f.readlines()
scraping(int(data[1].replace("\n","")), int(data[0].replace("\n","")))
date_now = datetime.datetime.now()
print("スクレイピング終了:", date_now)
データの可視化
まずは、家賃がどのように分布しているのかヒストグラムを確認し、家賃が高すぎる物件は一人暮らしにはそぐわないとみなし除去しました。
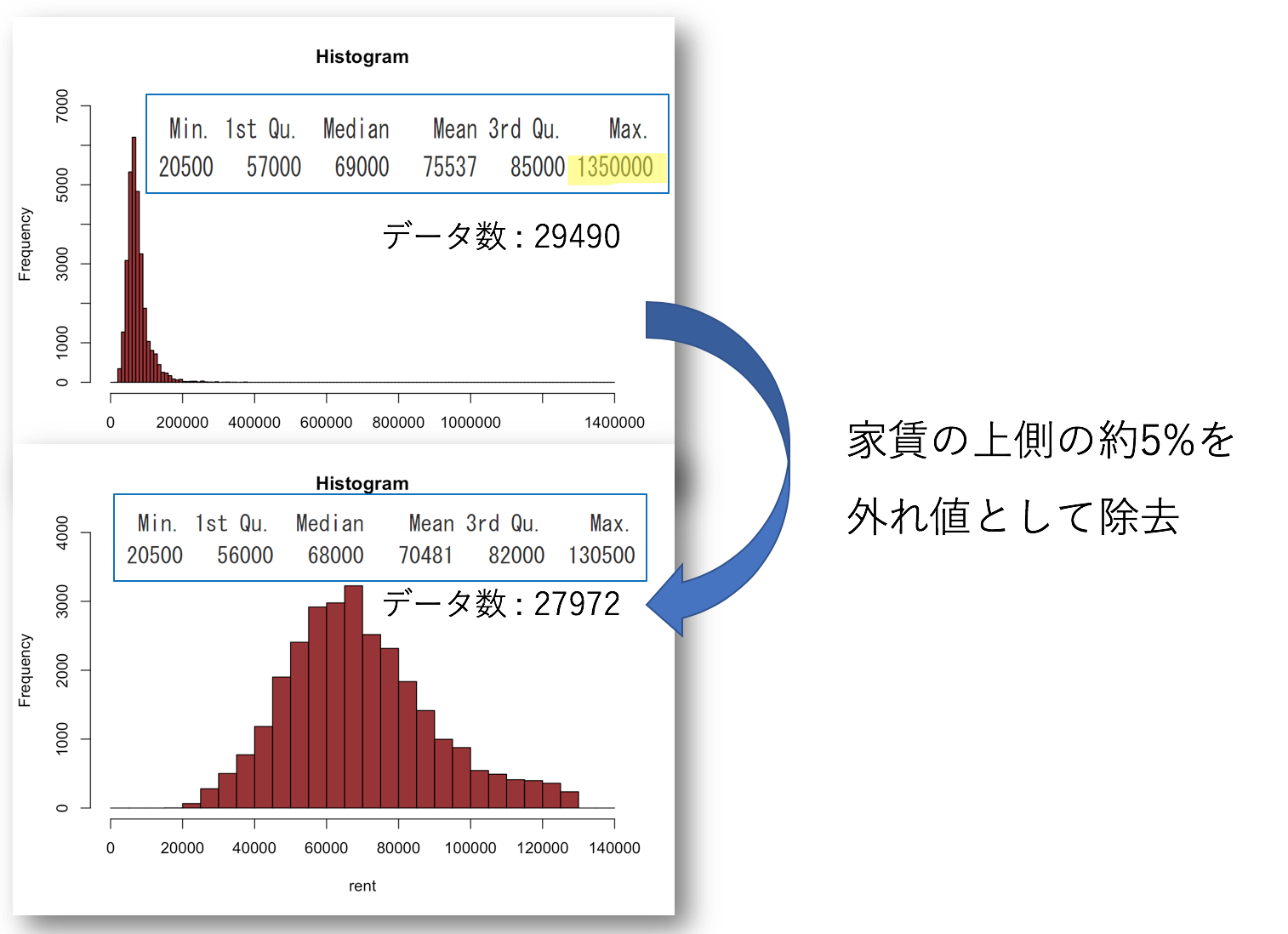
ここから、それぞれの変数がどのように家賃に影響を与えるのかみていきます。
間取り
間取りごとの物件数と家賃の分布をみていきます。
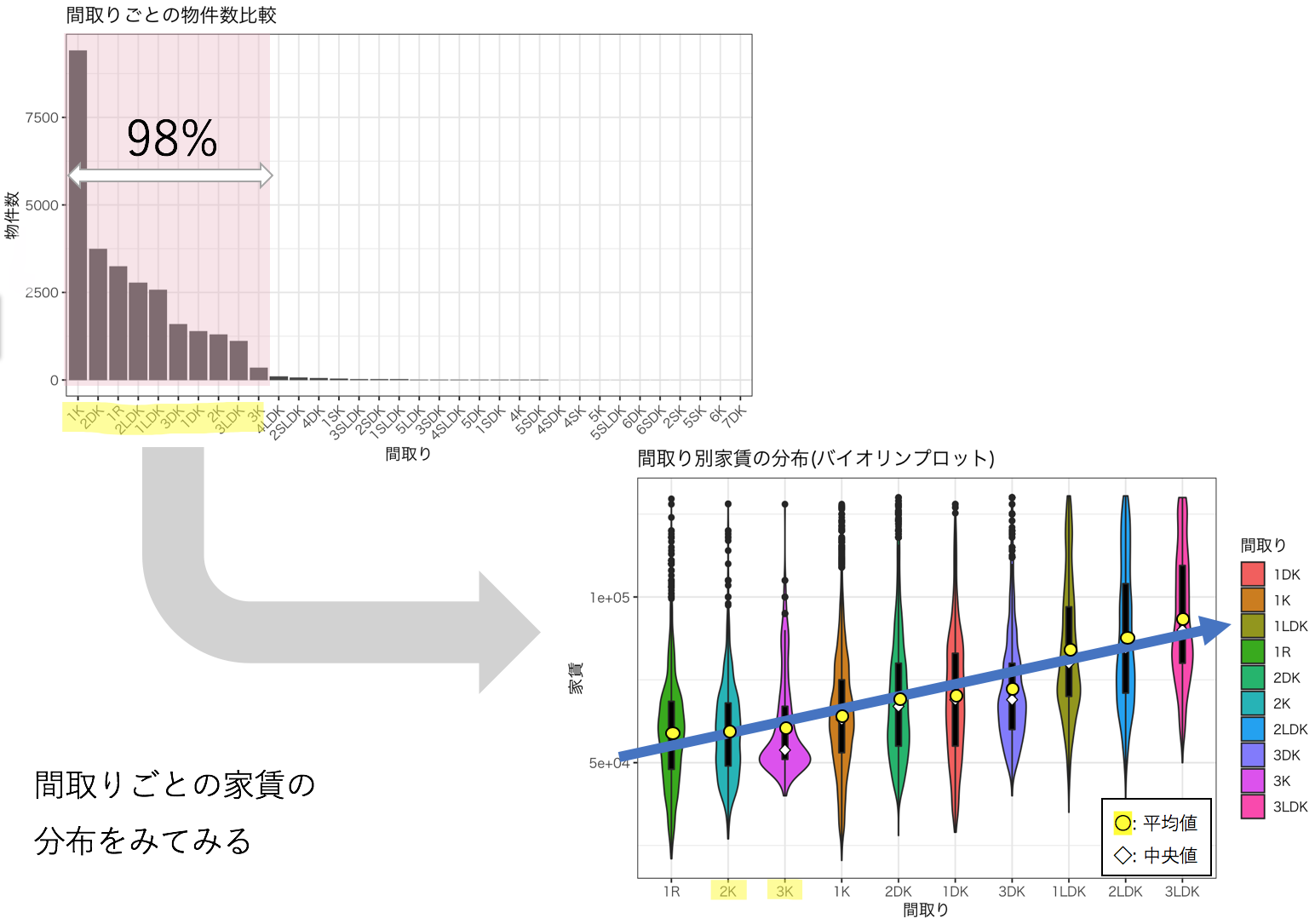
間取りごとの物件数を棒グラフにすると1R~3LDKまでの間取りが全体の98%を占めていることがわかりました。それらの間取りの家賃の分布をバイオリンプロットでみてみると、間取りごとに家賃の分布が異なることがわかります。よって、間取りは家賃に影響を与える変数となりそうです。
場所
物件がどこに多くあるのかみていきます。
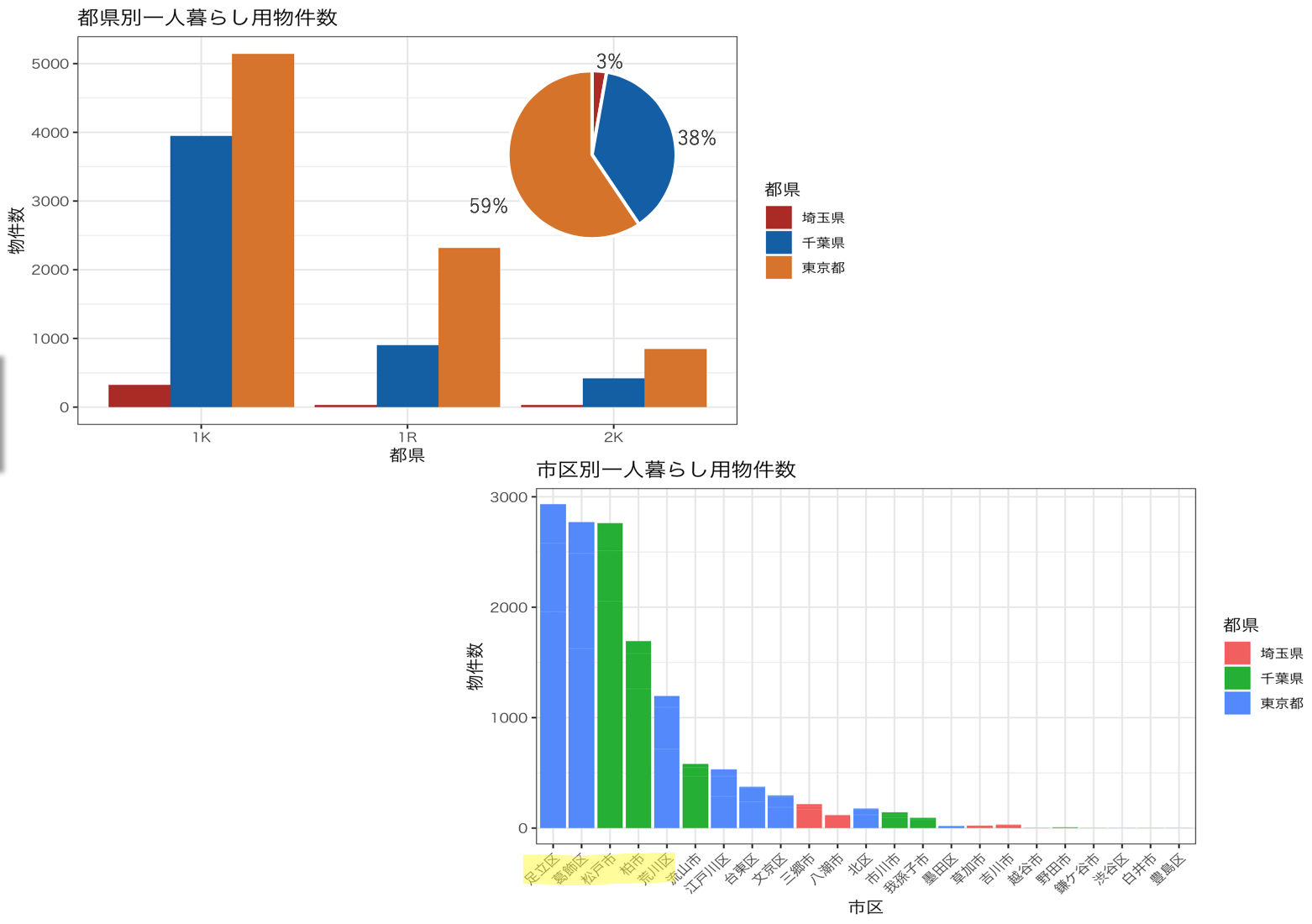
都道府県別にみると東京千葉がほとんどで埼玉は3%程度でした。さらに詳しく市区町村別にみてみると足立区葛飾区松戸市柏市荒川区あたりが物件数1000件を超えており物件を探すのに良さそうです。
これらの地区ごとの家賃の分布を見ていきます。
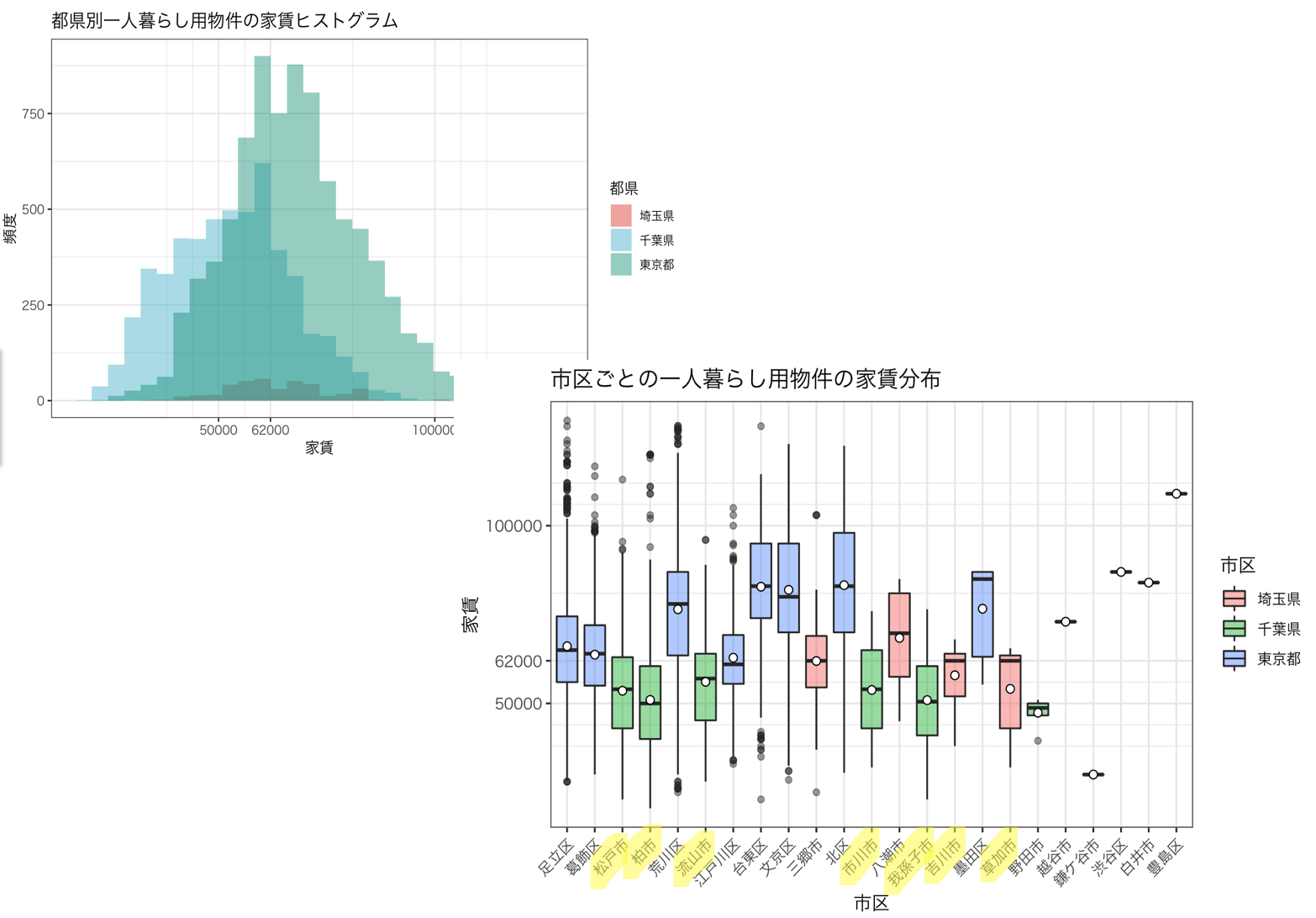
都道府県別の家賃ヒストグラムをみると、東京は物件数が多いものの家賃の高い物件が多く、千葉の方が安い物件が多いことがわかります。詳しく市区町村ごとの家賃の箱ひげ図を見ていくと、緑色の千葉の地区の箱が下の方に位置しているのがわかります。
松戸や柏、流山、市川、我孫子、吉川、草加に安い物件を探せそうです。
箱ひげ図をみてみると地区ごとに家賃の分布が異なることが分かるので、物件がどこにあるかということも家賃に影響を与えそうです。
駅からの所要時間とその手段
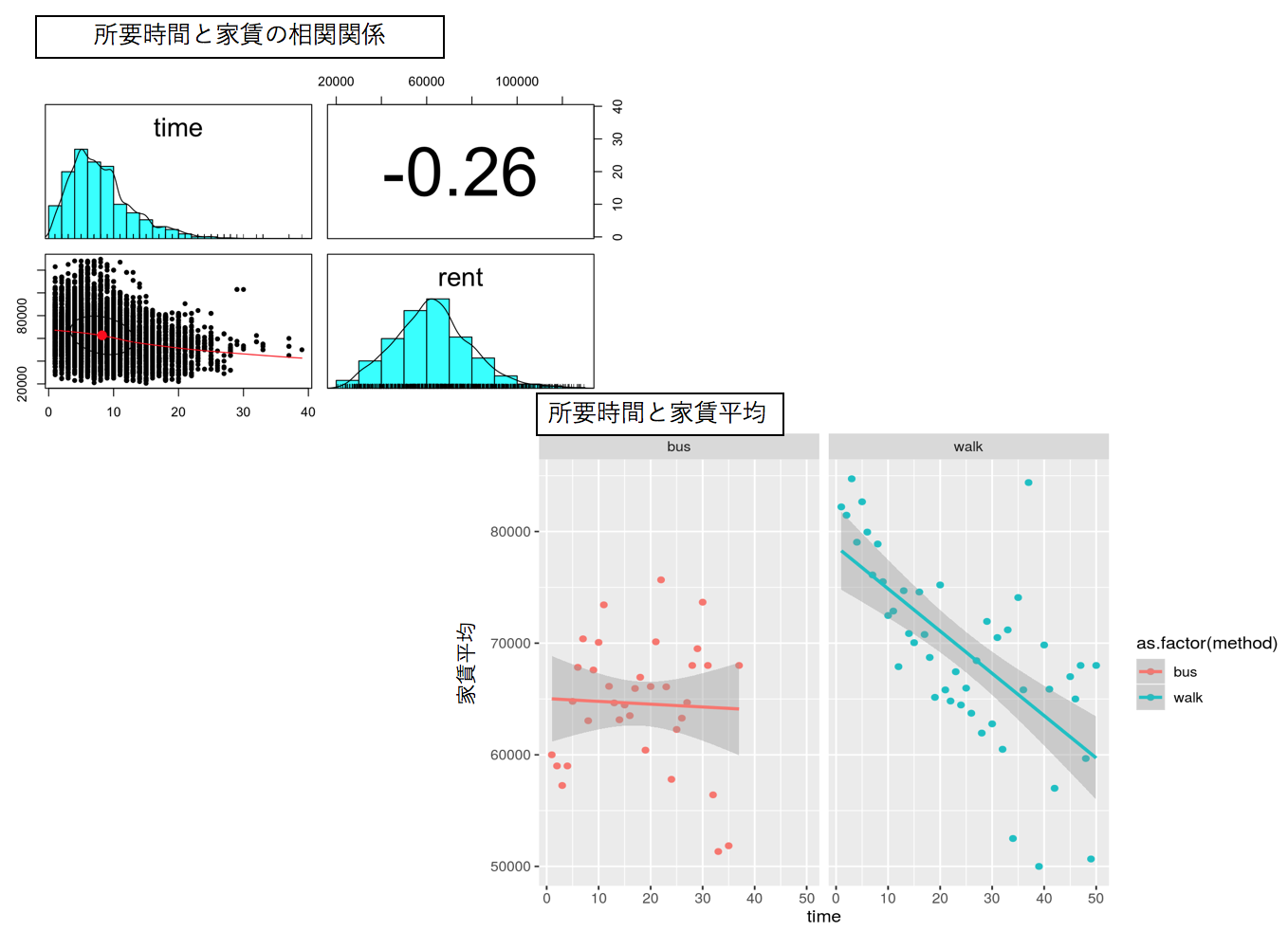
所要時間と家賃には弱い負の相関があり所要時間が長くなると家賃が安くなるようです。
またその時に利用するバスや徒歩といった交通手段による家賃の違いを図示しました。
全体的に青色の徒歩の方がバスよりも家賃が高いことがみてとれます。
よって、交通手段、所要時間共に家賃に影響を与えそうです。
築年数
築年数を5年ごとにグルーピングし家賃の箱ひげ図を出しました。
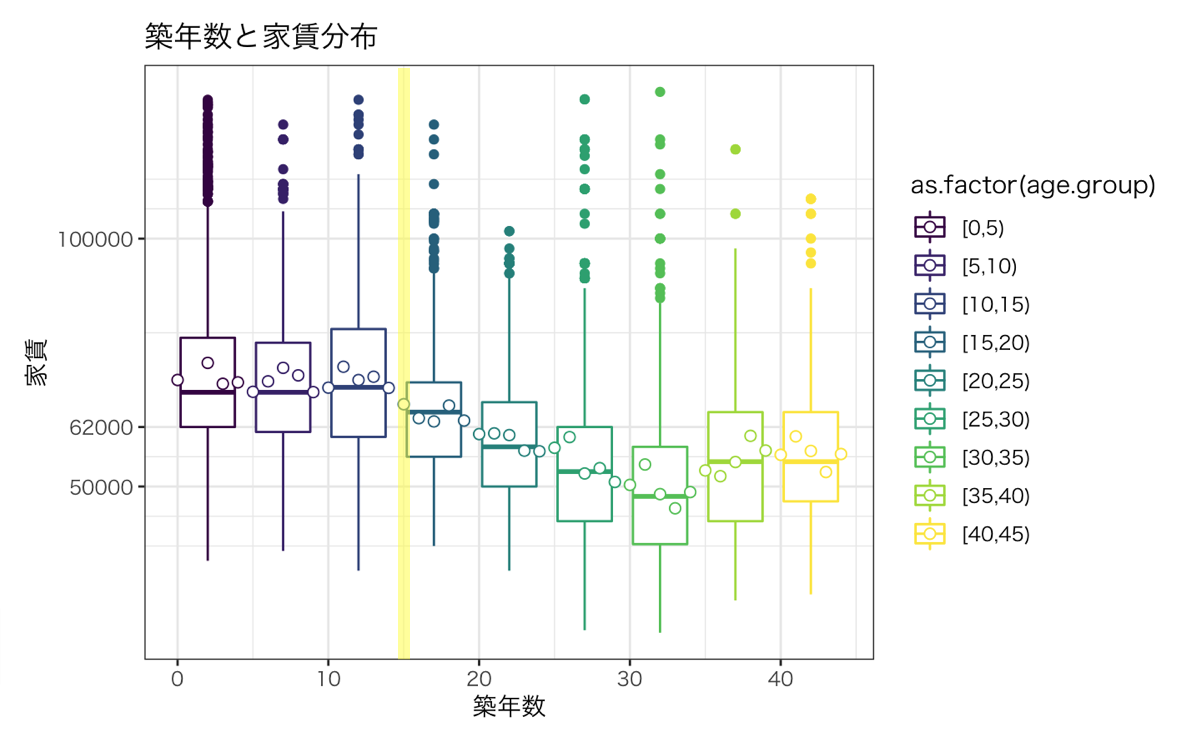
築15年以降の物件から徐々に家賃が安くなってくることがわかります。
よって、築年数も家賃に影響を与える変数となりそうです。
建物の総階数と種類
建物の総階数別の家賃の分布と総階数のヒストグラムをみていきます。
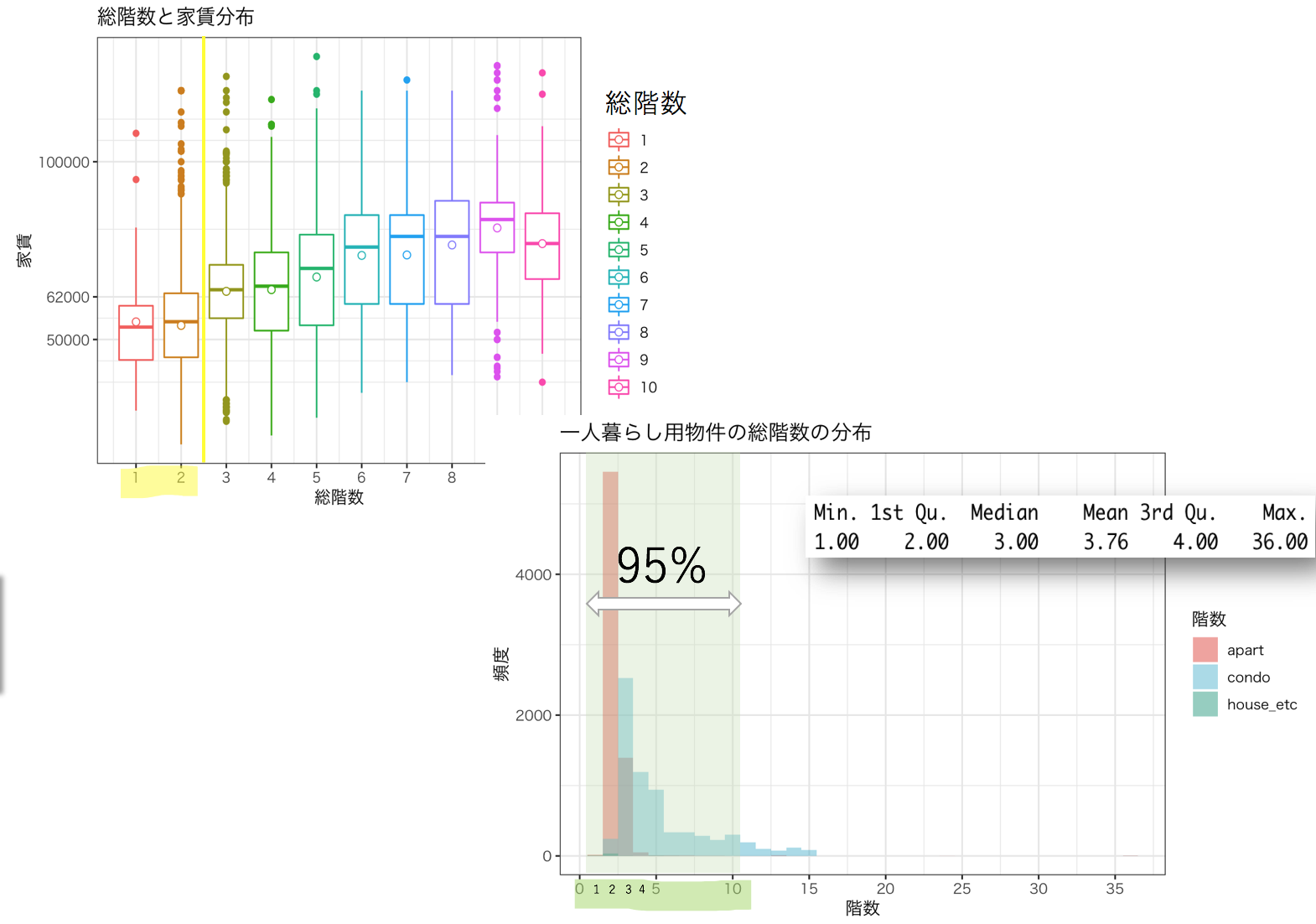
総階数と家賃の分布を見てみると2階建てまでの物件の家賃が安いようです。
総階数のヒストグラムを確認すると、2階建ての物件というのはアパートがほとんどでした。
それに、95%の物件が10階建て以内だったので、初めての一人暮らしで高層階物件に憧れを持つかと思いますが一人暮らし用の物件となると難しいようです。
以上の結果から、建物の情報も家賃に影響を与えることがわかりました。
南向き
物件の特徴である南向きというのが、家賃に影響を与えるのかみていきます。
南向きの物件とそうでない物件のヒストグラムをそれどれだしました。

ヒストグラムを見てみると分布が同じようであるので、家賃の差異が有意なものであるのか検定をおこないました。南向きとそうでない物件の家賃平均には有意な差異がありました。この際にF検定で等分散性の検定をおこない等分散であることが棄却されなかったので、等分散を仮定したt検定をおこないました。その結果、南向き物件の方が1500円ほど安くなりました。以上の事から、南向きであるかないかというのは家賃に影響を与えていることがわかりました。
角部屋
同様に角部屋についても影響をみていきます。
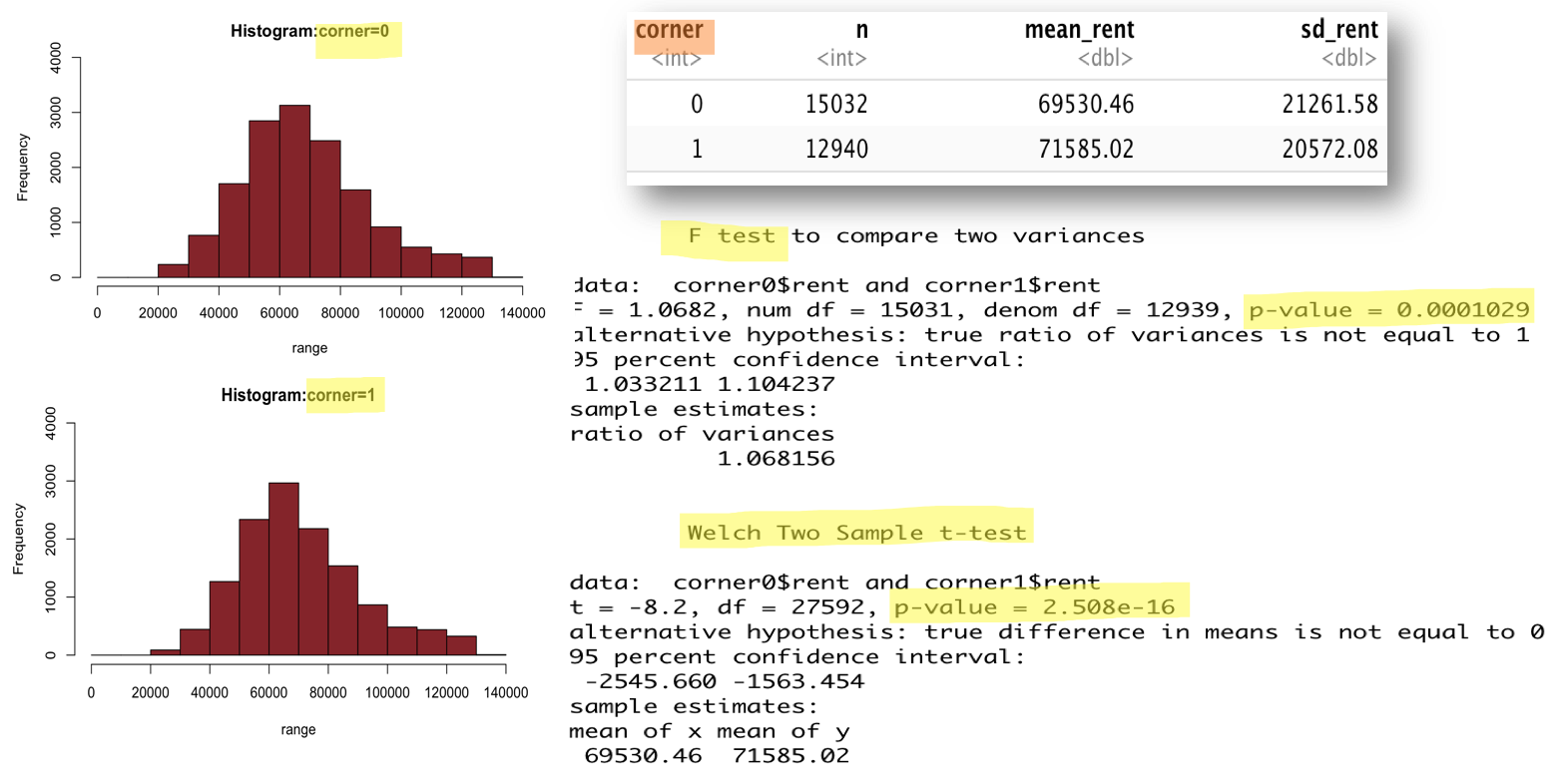
F検定で等分散性の検定をおこない等分散であることが棄却されたので、分散が等しくないことを仮定したt検定をおこないました。その結果、有意な差であることがわかり、角部屋の方が2000円ほど高かったです。
以上の事から、角部屋も家賃に影響を与えていることがわかりました。
データ可視化2
これまでの結果をもとに再度分析し、実際に困っている大学の友達におすすめする物件の条件を具体的に定めたいと思います。
実際にどこの地区で物件を探せばよいのか?
物件数と家賃平均の関係性を市区ごとにプロットしました。
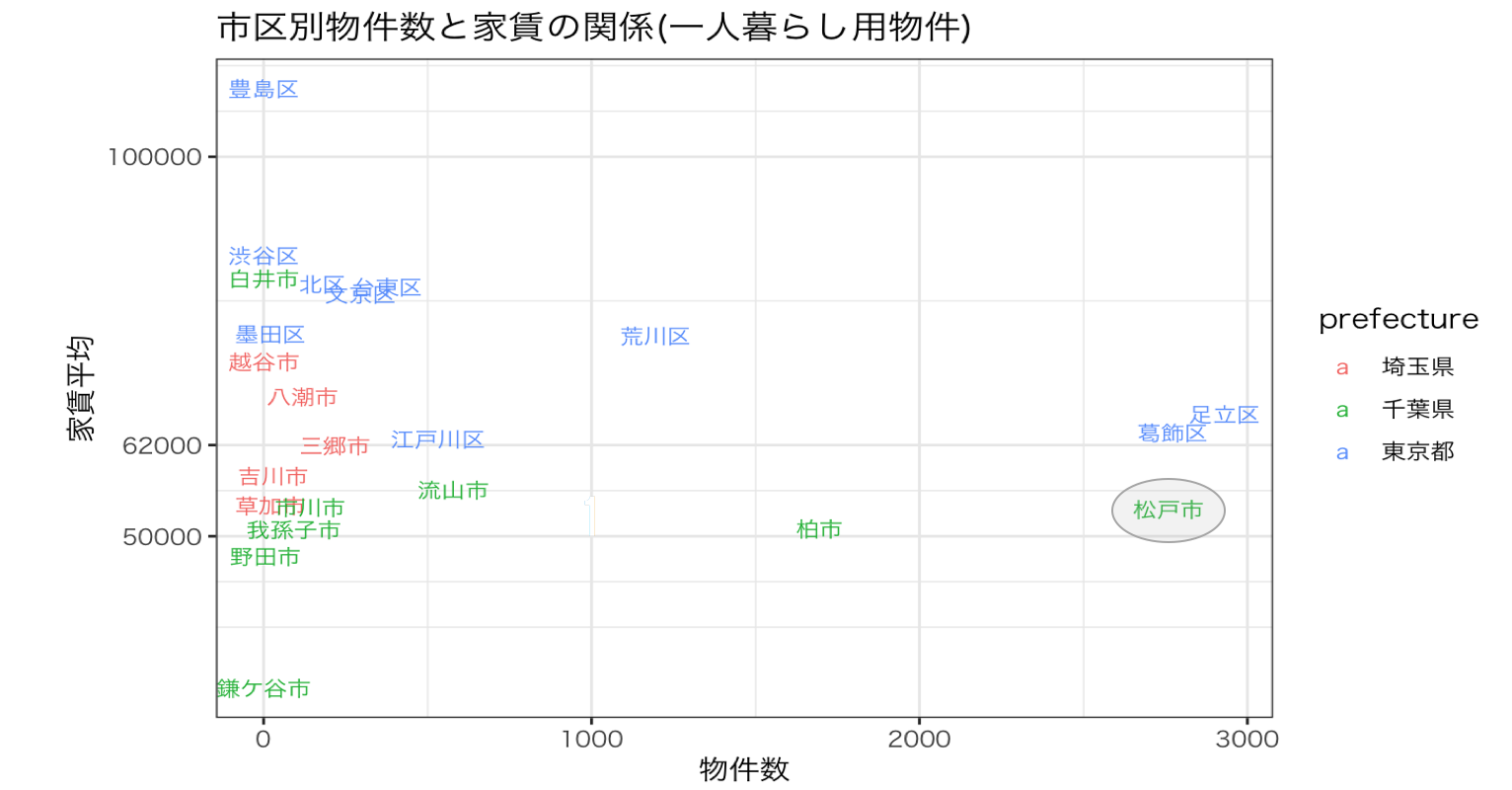
松戸市は物件数も多く平均家賃も低いことがわかります。
間取りは?
間取りごとの物件数と平均家賃はこのようになっています。
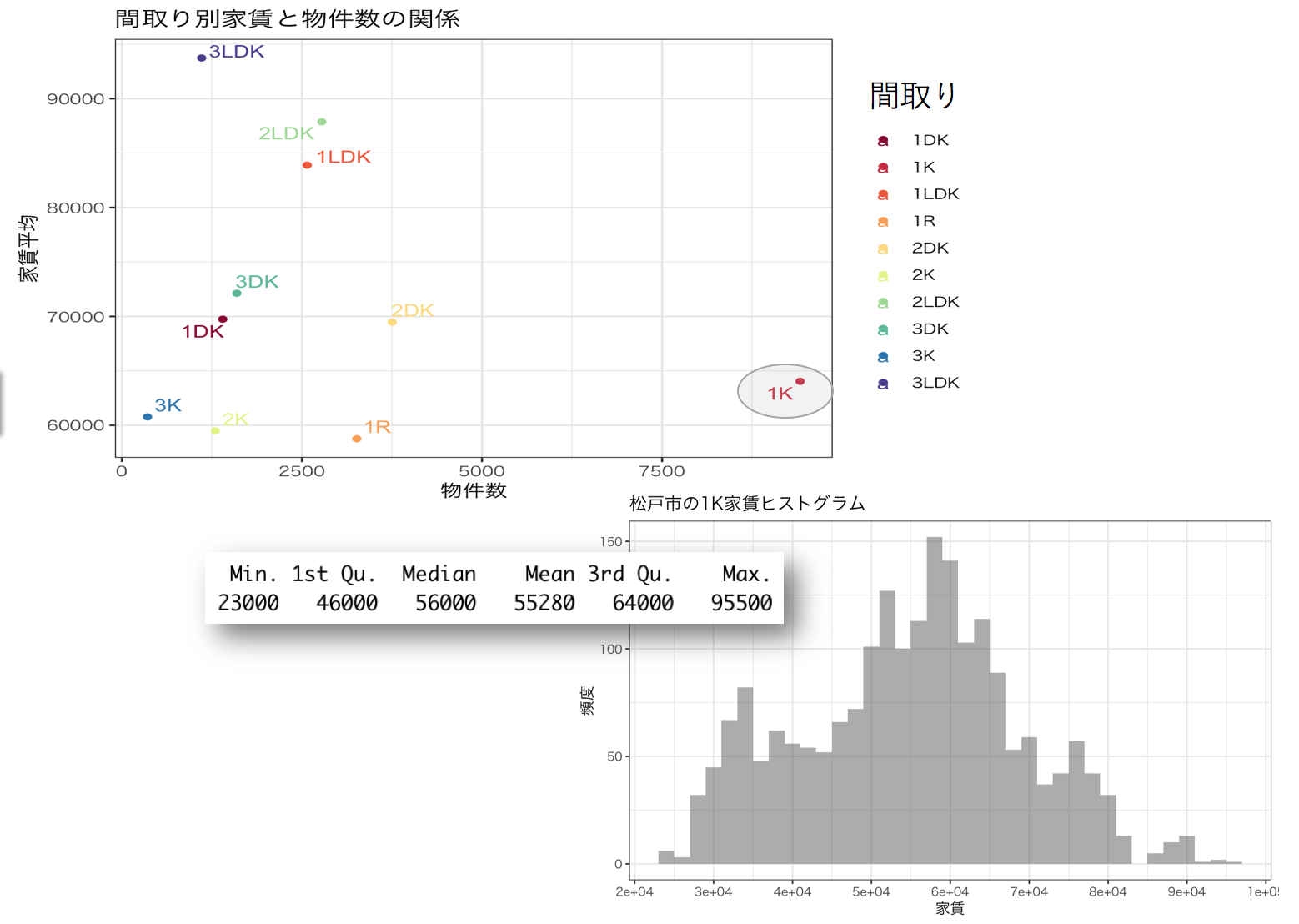
1R,2K,3Kの家賃平均が安くなっていますが、1Kの物件数が圧倒的です。一人暮らしであればそこまでの広さは必要ないので、間取りは1Kが良いと思います。松戸市1K物件の家賃相場は中央値を利用すると56000円でした。
築年数は?
松戸市の1K物件の築年数による家賃の分布変化を箱ひげ図にしました。
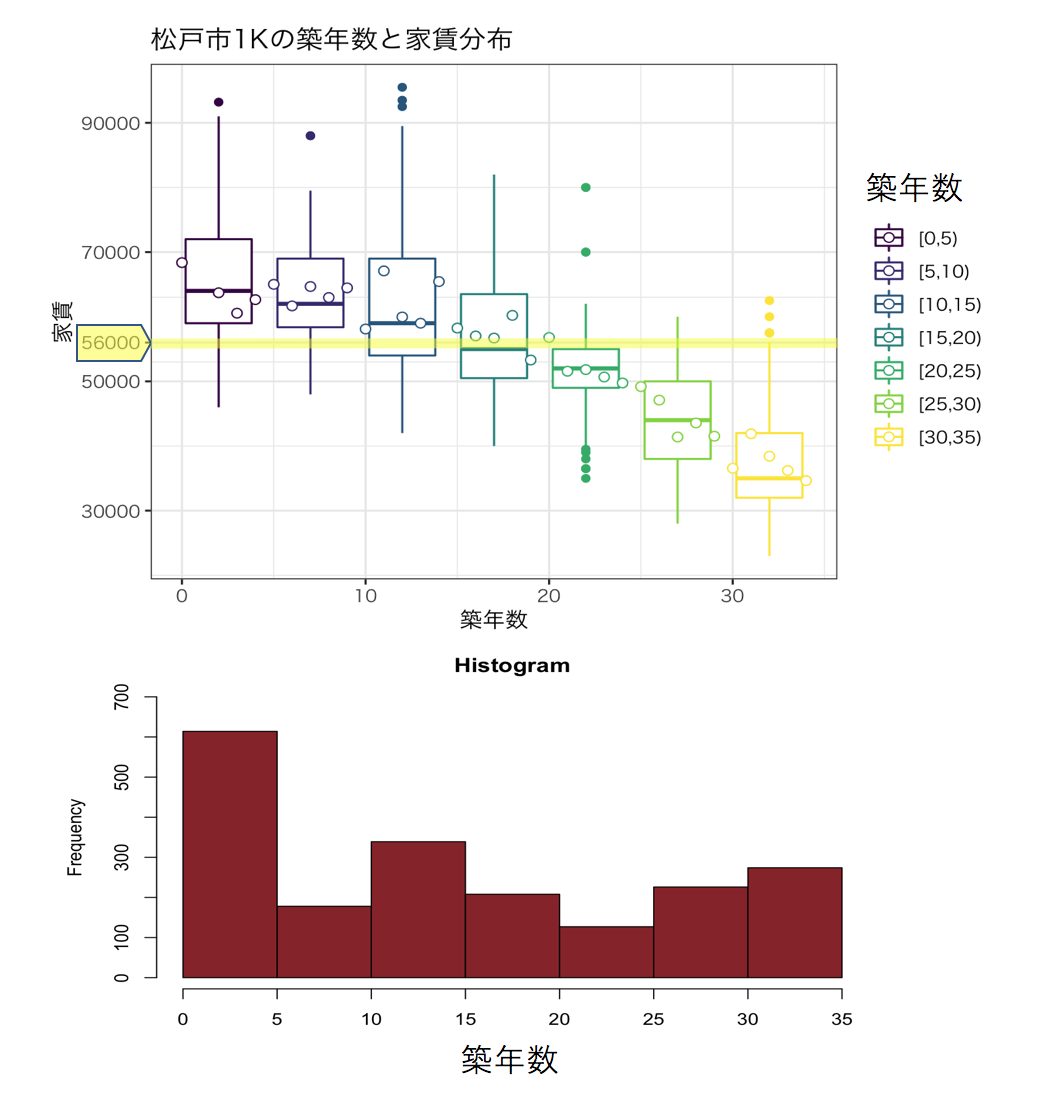
築15年以降の物件であれば相場以下の物件がおおくなることが分かります。
築年数は15年程度で探すとよいと考えます。
所要時間は?
駅からの所要時間はどれくらいの物件が多いのか、交通手段によって色分けして棒グラフにしました。
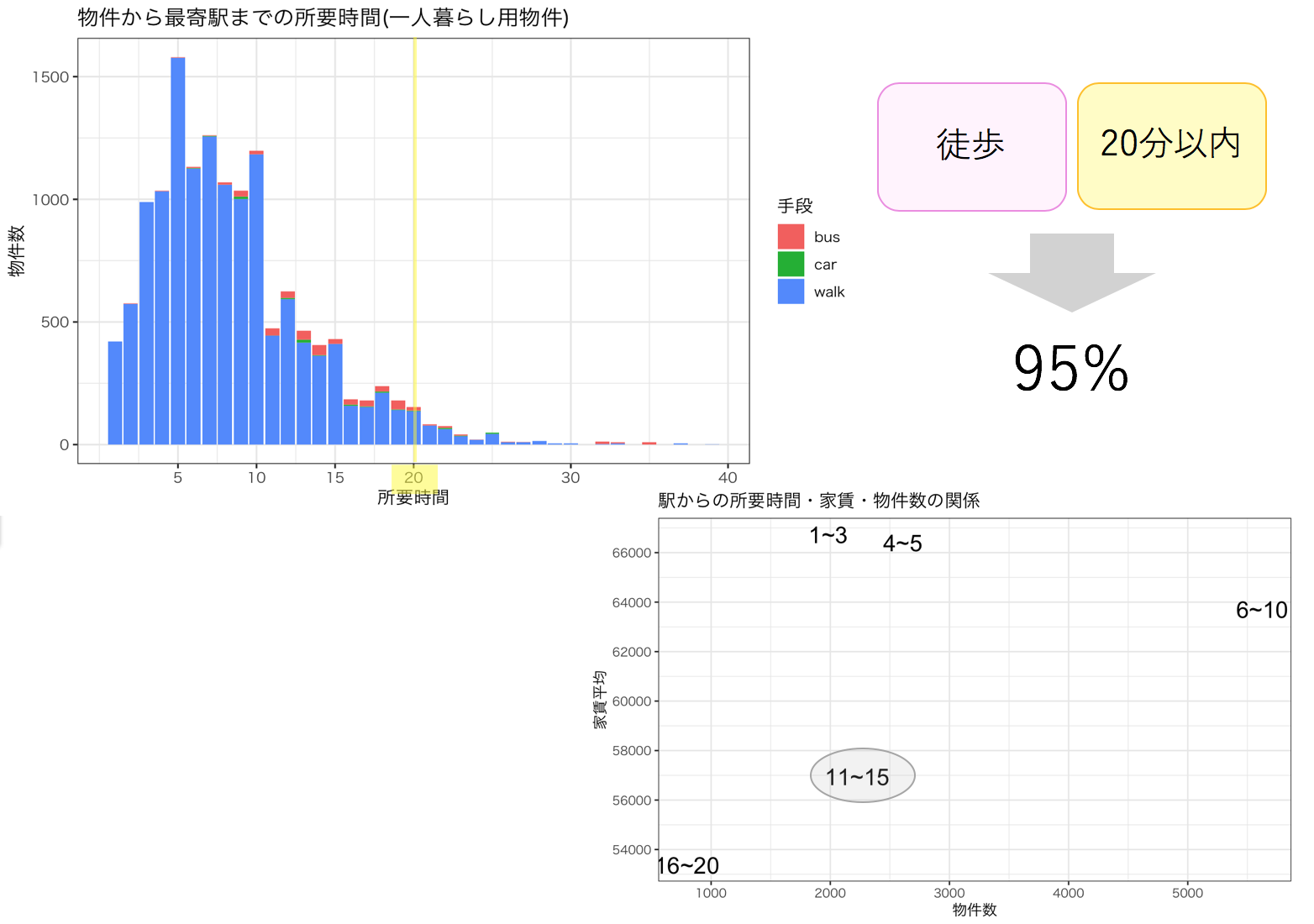
一人暮らし用物件は、徒歩20分以内の物件が95%とほとんどであることがわかります。
駅からの所要時間ごとに物件数と家賃平均をプロットしました。15分以内まで伸ばすと家賃が安くなることがわかります。
結果
上記を踏まえて、友人に伝える物件探しの条件は次のようになります。
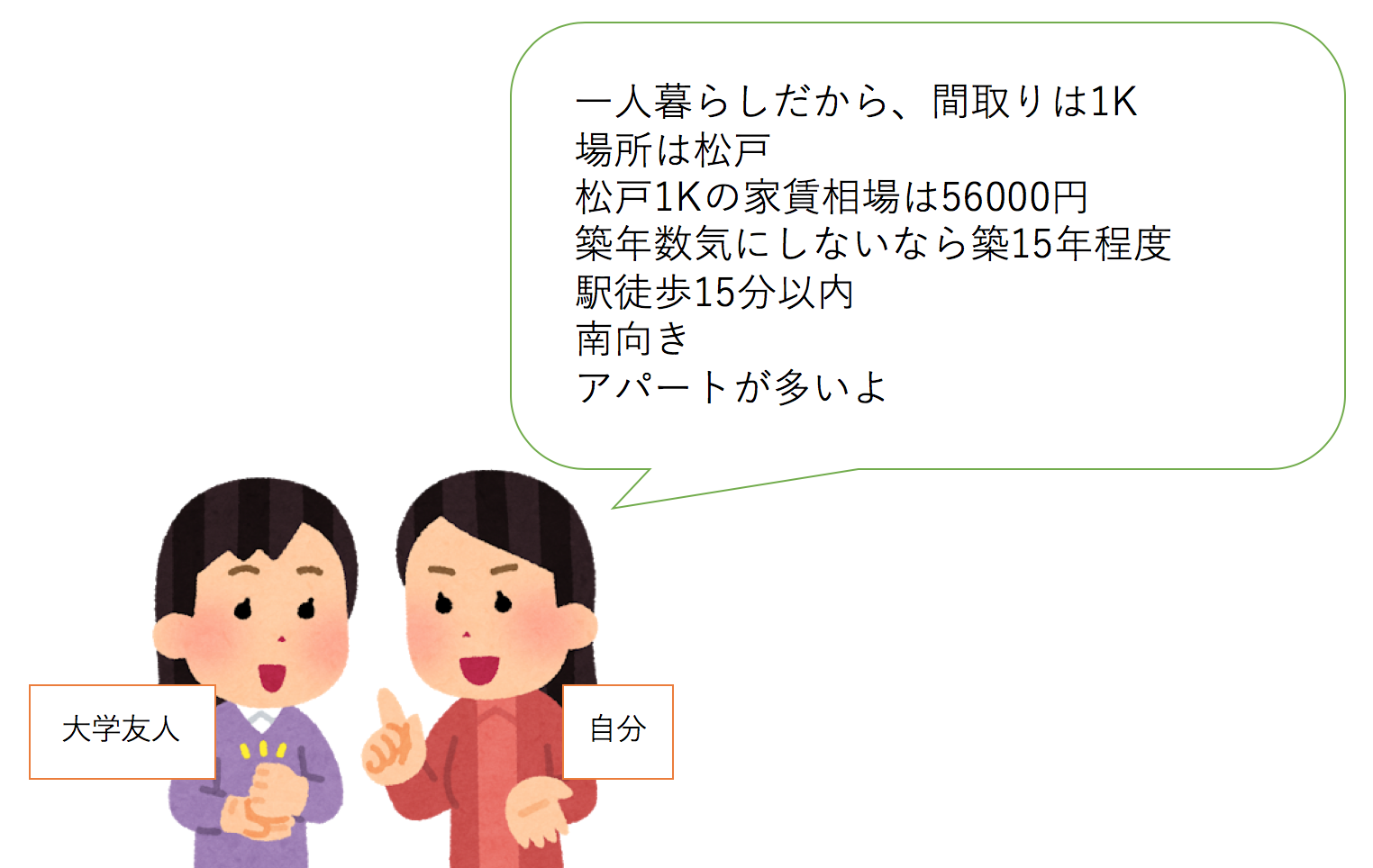
- 一人暮らしでそこまでの広さは必要ないということを加味し、家賃と物件数を考慮すると間取りは1K
- 物件の立地は金町のとなりであること、家賃相場が56000円で全体の1K家賃相場は63000円と比べると安いこと、物件数を考慮すると松戸
- 築年数15年程度としていますが、築年数をきにしないのであれば15年以上で探すと家賃が安いのが多いからおすすめ
- 駅徒歩は10分以内だと家賃が高いから15分以内までのばす
- 南向きはオプションとしてつけても家賃が高くならないことがわかった
以上の条件で探すと、アパートタイプの部屋になるとおもいます。
この条件をもって、松戸の不動産屋さんにいけば良い部屋探しができると考えます。
おわりに
反省点
反省点は、方針が定まらないままにデータ分析を行なっていた点です。趣味でやるならいいけれど、それを行なってしまうと、どこに使うかもわからない図ができあがったりして非常に時間の無駄になるので目的を持ってデータ分析をしなければいけない。
フィードバックから学んだこと
-
コードレビュー
コメントの挿入やコーディング規約に則った記述をすることで可読性を高める -
発表レビュー
自分が生み出した結果をどういったアプローチで発表するか、同じ内容でもアプローチの仕方によって良いものにも悪いものにもなってしまう。きちんと目的に対する結果が出ているのか?というのをストーリーをたててわかりやすいように発表しなければいけない
その他
今回の課題は、分析だけでは終わらず資料をつくって発表までしてフィードバックをいただけたので貴重な経験ができたなと感じています。データを収集して分析できる形にするまでにこんなにも時間がかかることや結果を相手に伝える難しさだったり、さまざまな気づきがありましたのでこれからに活かしていきたいと思っています。
以上です。