(1) 今回やりたいこと(概要)
- 介護現場から上げられたヒヤリハット報告が、予め定めた複数カテゴリの内、どのカテゴリに分類されるか判定する仕組みを、fastText を用いて構築。
- あまり整った形で整備されておらず、かつ、2500件という少なめの学習用データで、どこまでの精度が出せるのかの感触を探る。
(2) 経緯
介護の現場では、雑多なタスクが無数にあって、スタッフの人たちはマルチタスクでとにかく何かと忙しく、落ち着いたデータ入力の時間が取りづらいものです。
一方、日常的に発生しているヒヤリハットの報告・共有は、大切なことにも関わらず、どうしても後回しになり、そのまま報告せず流され忘れられていまいがちになってしまうことも有るようです。
そこで、音声入力を使って手早く簡単にヒヤリハット報告ができる仕組みを作って、複数の介護現場で集めました。
集まった大量のヒヤリハット報告を集計して、
【どこのシーンで、どんなヒヤリハットが、どれぐらいの件数発生しているか?】
を把握した上で、事故防止対策のための基礎データとしたいと考えます。
ヒヤリハット報告は様々な種類の介護施設から集めていますが、今回は、デイサービス施設の利用者を、ご自宅から施設までの送迎を行う際のヒヤリハットに限定して、分析を試みます。
(3) 報告されるヒヤリハット例
例えば、以下のようなヒヤリハット報告が入ってきます。(※ダミーサンプルです)
●●様が、走行中シートベルトを外してしまうので声がけし、つけなおしてもらった。
車に乗る際のシートベルト着用は後席含めて義務化されており、着けないで運転することは大きなリスクを伴いますが、認知症の方はよく外されてしまいます。
- 事故時の致死率:約 3.5 倍
- 後席乗員が前席乗員の頭部にぶつかって重傷事故となる確率:約 51 倍
(4) 分類処理の対象とするデータの特徴
-
主に音声入力をつかって、現場の介護職員の方々に直接入力して頂いてます。(1件あたり、短いと1分以内に報告が完了しています)
-
1件あたりの報告の文章量は、短いとほんのワンセンテンス、多くても200文字程度です。
-
新聞などのように校正された綺麗な文法の文章ではありません。
-
文章の中には比較的多くの間違い(音声認識ミスや漢字変換ミス)が混ざってますが、あえてそのままにしています。
(5) 分類の定義作業
以下の形で、送迎シーンにおけるヒヤリハット分類を定義しました。詳細定義については説明すると長い脱線になりますので割愛します。
【図:分類表】
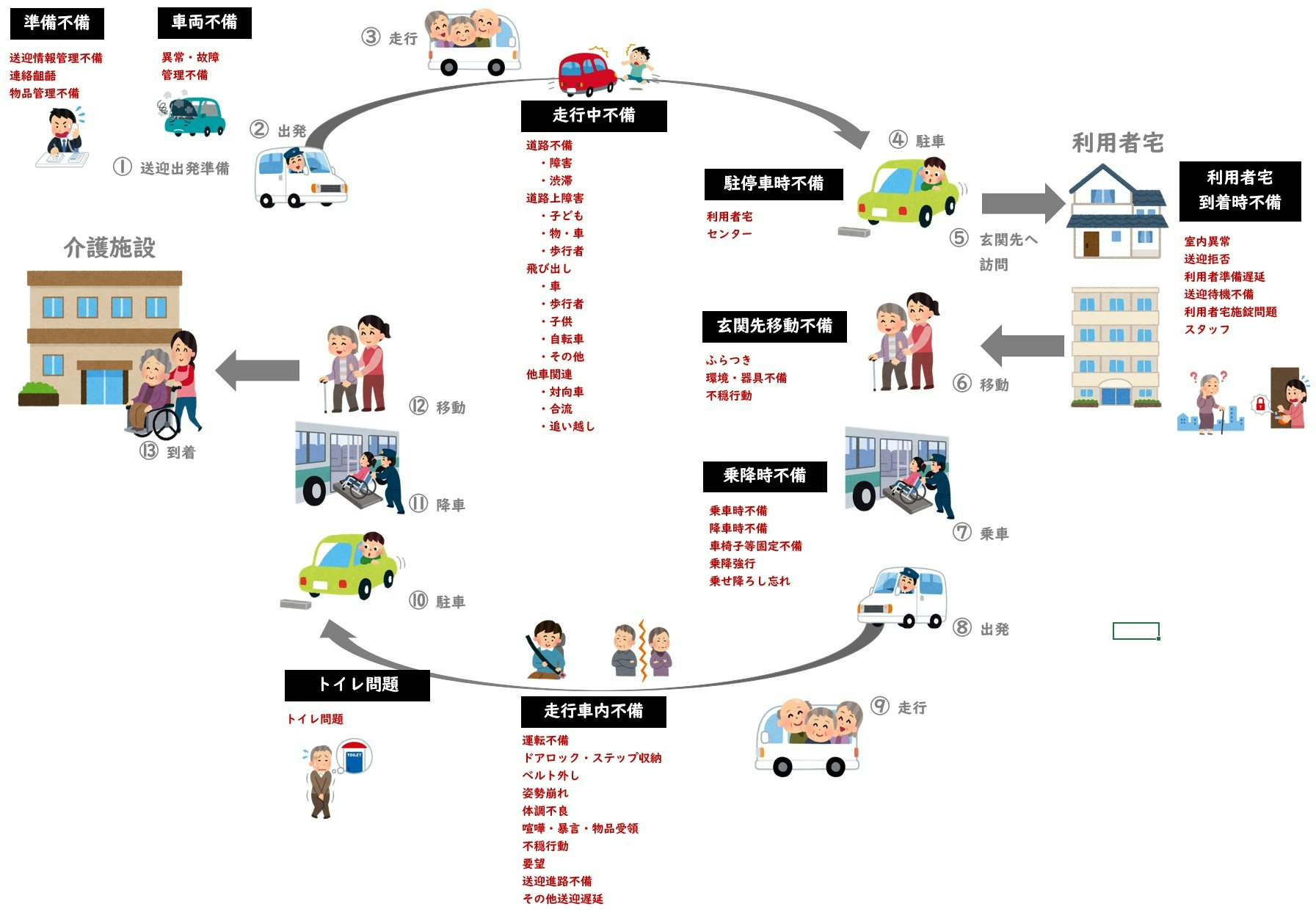
分類すべきカテゴリー数は、上図の赤文字で記した 45 種類となります。分類器に入力された文章は、45種類のいずれかに属すると判定させます。
(6) 分類の意図について
ヒヤリハット報告については、特定の利用者によって引き起こされる人依存のものが多く、現場の職員間できちんと共有することが、なによりも大事です。一方で、送迎業務のヒヤリハットについては、特定施設に依存しない、全国どこの施設でも似たようなインシデントが発生していることが想定されます。これら汎用的なインシデントについては、汎用的な対応策の検討が可能と考えています。
そのため、今回は送迎シーンごとの分類を行っています。
分類については様々な観点の分類手法を思いつきますが、唯一絶対の正解というものはなく、分類したその後のデータ活用方法まで見据えた上での戦略立てが必要になるところでしょう。
(7) 賽の河原で石を積む
分類定義を定めたあとは、既存のヒヤリハットデータを1件づつ、ひたすら仕分け分類作業を行います。
分類しつつ、併せてデータの匿名化もしっかり行います。名前はもちろんの事、地名や施設名なども全てチェックしてダミー文字列への置き換えを行わなくてはなりません。珍しい疾患や会話記録など、特定個人を推察可能な情報が含まれている場合は、それも削除またはダミーに置き換えます。
500件もやり続けると作業感が増してきて心が磨り減ってきますが、頑張って頑張りましょう。
そうこうして、2677件の分類済みインシデントデータが出来上がりました。
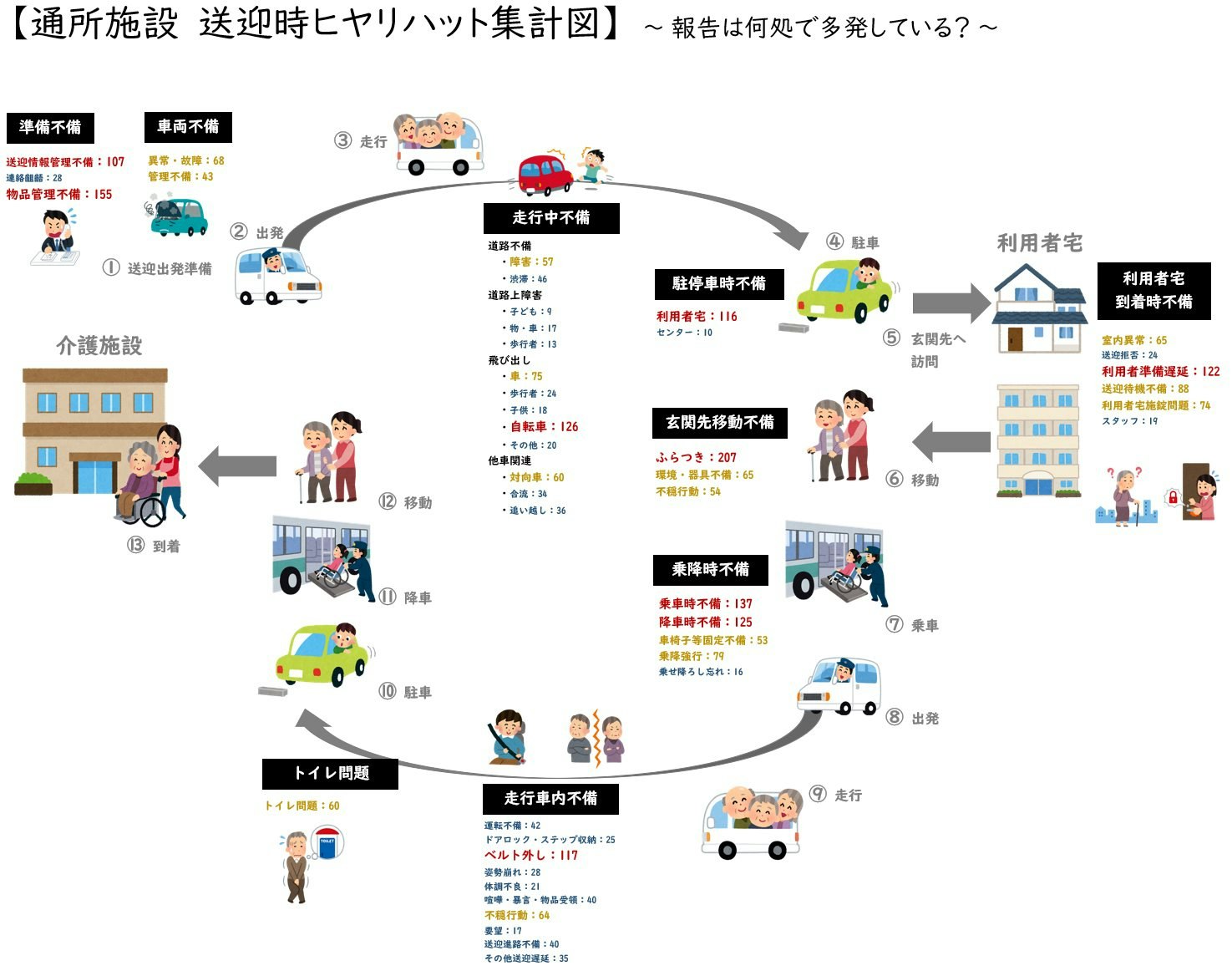
最初に述べたとおり、データ量としてはまだまだ不十分ですが、このデータを学習データとして、fastText 用トレーニングデータの作成をしていきたいと思います。
(8) 学習用データの下ごしらえ
fastText で処理するためのトレーニング用データの準備を行います。
(8-1) ヒヤリハット報告文章の分かち書き処理
fastText に読み込ませる際には、単語単位でスペースに区切ったテキストデータが必要になります。
データは全て日本語なので、形態素解析を行って、単語単位に分割処理が必要です。
mecab ( mecab-ipadic-neologd ) を使って、単語単位に分割します。
mecab -O wakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd -o <output file> <input file>
すると、こんな文章が、
●●様が、走行中シートベルトを外してしまうので声がけし、つけなおしてもらった。
単語単位にスペースで区切られて、こうなります。
●● 様 が 、 走行中 シートベルト を 外し て しまう ので 声 が けし 、 つけ なおし て もらっ た 。
一般的に、ここから更なるデータの平準化作業として、半角文字を全角文字に置換したり、助詞や句読点を除外したりします。
(8-2) ヒヤリハット報告文章にラベル付け
上で処理したテキストデータに、分類用のラベルをつけていきます。ラベルは、既に定義した45種類のいずれかを、1種類のみ張ることとします(複数種類のラベル定義も可能です)
__label__走行車内-ベルト外し, ● 様 が 走行中 シートベルト を 外し て しまう ので 声 が けし 、 つけ なおし て もらっ た 。
ラベルの付け方は簡単で、__label__hoge, 学習用文章 のようにします。__label__ の後ろの hoge は、2byte文字でも大丈夫なようなので、わかりやすく付けられてありがたいことです。
(※要注意:__label__hoge, 学習用文章 の、カンマの後ろには、空白スペースが必須)
このようにして、2677行のテキストファイルを拵えれば、fastText に読み込ませるための学習用トレーニングデータ day1.stackexchange.txt の完成です。
(8-3) fastText 用トレーニングデータの作成
2677件のデータを、まず2500件のトレーニング用データセットと、177件の検証用データセットに分けます。2500件のほうで機械学習を行ってモデルを作り、177件のほうで精度確認(答え合わせ)を行いたいと思います。
先程用意した、day1.stackexchange.txt を、シャッフルした上で、トレーニング用データセット day1.train と、検証用データセット day1.vaild にわけます。
shuf day1.stackexchange.txt -o day1.stackexchange.txt
head -n 2500 day1.stackexchange.txt > day1.train
tail -n 177 day1.stackexchange.txt > day1.valid
(9) fastText を使ったトレーニング実行
トレーニング用データセット day1.train を使って、実際にトレーニングを実行します。トレーニングした結果のモデルは、model_day1 で出力します。
../fastText/fasttext supervised -input day1.train -output model_day1
まずはオプションとか無しの、一番単純な形で。
なお、今回の実行環境は、windows上の VirtualBox での Linux 環境、という大変計算パワーに乏しい環境ですが、データ件数が2500件と小さいこともあり、数秒でトレーニングが完了しました。
(9-1) モデルの精度を確認
2500件で学習させたモデル model_day1 を使って、残り177件を分析させて、どれぐらい正しい分類ができるか確かめてみましょう。
../fastText/fasttext test model_day1.bin day1.valid
N 177
P@1 0.0508
R@1 0.0508
P@1 は適合率、R@1 は再現率とのことですが、どっちも同じ数字が出てくるので、細かくは気にせず正答率ということにします。
正答率 5%。むう。
次に、学習の際のパラメータを色々いじって、精度がどれぐらい上げられるかを試してみます。
(9-2) パラメーターを適当に調整して再度トレーニング
../fastText/fasttext supervised -input day1.train -output model_day1 -dim 40 -lr 1.0 -epoch 100
"-dim 40 -lr 1.0 -epoch 100" の部分がパラメータです。詳細は割愛しますが、このパラメータの調整が、よりよいモデル作成のためのキモになるようです。
トレーニングが完了するまでの時間は、数倍程度に膨らみます。
(9-3) 再トレーニングしたモデルの精度を再確認
../fastText/fasttext test model_day1.bin day1.valid
N 177
P@1 0.605
R@1 0.605
(0.56~0.60 ぐらいの範囲で、試行するごとに精度が微妙に変わります)
正答率6割程度。ちょっと上がりすぎじゃないでしょうか? まあいい感じの結果です。
ただ、所詮177件の検証データに対する局所的な成果なので、現段階で数字に拘り過ぎないほうがいいかもしれません。
(10) 精度に関する雑感
6割の正解率ということは、残り4割は不正解なの?と思われるでしょう。
回答としては、イエスでも有りノーでもあります。
一つには、分類基準の曖昧さがあるためです。人間が直接見て判断する場合でも、分類Aに仕分けるべきか分類Bに仕分けるべきかで迷って、エイヤで分類Aに仕分けたりすることがあります。コレを、分類Bに仕分けても、まあそっちでも許容範囲内でしょうとなることがあります。これが、4割の内、半分ぐらい含まれてます。つまり、ニアピン賞も含めると正解率8割。
残りの2割は、ヒヤリハット文章を杓子定規に解釈しても正解にたどり着くことは困難で、空気や行間を読んで文脈理解が必要なあいまいな報告です。現場の業務知識があって運転免許を取得したドラえもんなら正しく解釈できるでしょう、的な。つまり、これに関しては、単純な機械判定は困難、と割り切るしか無いやつです。
ただ、7~8割がた正しく分類してくれるのであれば、残り2割は引き続き手作業でチマチマ分類しても良いんじゃないか、そう思える水準です。
(11) 新しい文章の自動分類
作ったモデルを使って、実際に新しい文章を分類させてみます。
../fastText/fasttext predict model_day1.bin -
コマンドラインで標準入力待ちの状態になるので、試しに分類しやすい素直なヒヤリハット報告文章を、
センター に 戻る 際 に 小道 から 自転車 に 乗っ た 子供 が 飛び出し て き まし た 。
とインプットしてみると…
__label__飛び出し-自転車,
自転車の飛び出しに関する報告として、正しく分類されました!
(11-1) おまけの使い方1:テキストファイルを分析
分類対象のヒヤリハット文章群を、day1.text としてまとめて、一括処理させてみます。
../fastText/fasttext predict model_day1.bin day1.text
結果は、ラベルの形でつらつらと出力されます。
__label__道路上障害-子ども,
__label__駐停車時-利用者宅,
__label__乗降時-乗降強行,
(11-2) おまけの使い方2:テキストファイルを分(ラベル判定確率もセットで出力)
predict-prob を使うと、fastText がその文章をどれぐらいの確信を持って分類判断をしたか、確率値もラベルと合わせて出力されます。
../fastText/fasttext predict-prob model_day1.bin day1.valid 1
__label__駐停車時-利用者宅, 0.998701
__label__利用者宅到着時-利用者準備遅延, 0.996834
__label__利用者宅到着時-利用者準備遅延, 0.992327
__label__乗降時-降車時不備, 1.00001
ざっくりの雑感ですが、分析結果をざっと見たところ、1.0 でも分類を間違ってたり、逆に 0.5 以下でも正解だったりするので、この数字を当てにしてこの先の処理をどうこうする、というのは、今回のモデルではやらないほうが良さそうです。(サンプル数が多くなると違ってくるのかな?)
(12) 判定困難サンプル
機械判定が困難なサンプルです。形態素レベルでどうこうじゃなく、意味解析まで踏み込まないと無理でしょうね。
●●さまを助手席に乗せたが、降車がやや困難。乗車はスムーズにおこなえる
(「乗車がスムーズ」という正のフィートバックと、「降車が困難」という負のフィードバックが混在)
(13) 今後の予定
今回の試行では、約2700件のデータで学習を試しました。
現在未分類のインシデントを含めて約6000件ほどは溜まっているので、教師データの規模を拡大した上で、再度学習を試してみたいと予定しています。
(14) 参考
fastText
https://fasttext.cc/
MeCabのコマンドライン引数一覧とその実行例
http://www.mwsoft.jp/programming/munou/mecab_command.html#dictionary-info
fastTextでカテゴリ分類してみた
https://techblog.istyle.co.jp/archives/1618
【ソースコード付き】日本語テキストマイニングを行うために必要な前処理
https://boomin.yokohama/archives/634
機械学習のfastTextをCentOS7環境のPython3を使って20万件の文章分類を実施してみる(mecabを利用)
https://developer-collaboration.com/2019/06/13/fasttext/
pythonでfasttextを使って文書分類してみた
https://qiita.com/ezmscrap/items/b8124324189fc46d9512
fastTextで自然言語(日本語)の学習モデルを生成する手順まとめ
https://dot-blog.jp/news/fasttext-natural-language-machine-learning-tutorial/