背景
- 個人的にSoundCloudのようなオーディオプレイヤー&ビジュアライザーが必要になった。
- npmに幾つかモジュールはあったが、生憎TypeScriptに対応したものはなかった。
- audio要素をそのまま使うものはイマイチ好みではない。
- しょうがないので自分で作ることにした。
作ったもの
-
https://github.com/ckuwata/typed-audio-visualizer
- まだ完成はしていない。
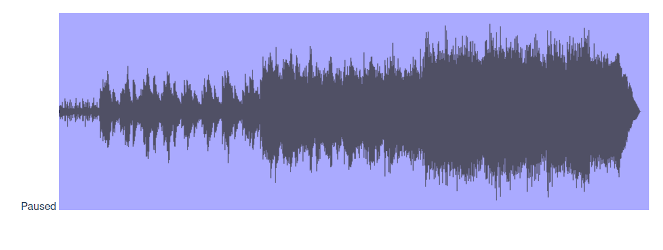
- デモは動く。(手抜き。Pausedの文字をクリックすると再生開始。)
- とりあえず動けばいいや状態なので仕様変更の可能性大。
作るに当たって調べたこと
そもそもブラウザで音声を再生するには?
A: AudioContext, AudioBufferSourceNode, AudioBufferを使う。
以下、使い方の例。
const rawAudio = await axios.get(f, {
responseType: 'arraybuffer'
})
const audioContext = new AudioContext()
const source = this._audioContext.createBufferSource();
const buffer = await this._audioContext.decodeAudioData(rawAudio)
const audioDestinationNode = this._audioContext.destination;
source.connect(audioDestinationNode)
上記コードのrawAudioはArrayBuffer型ではる必要がある。axiosで取ってくるのが簡単だが、この時responseType: 'arraybuffer'を指定する必要があるようだ。またAudioBufferSourceNodeにaudioDestinationNodeをconnectしているが、これを行わないとAudioBufferSourceNode#startを呼び出しても音声が再生されない。(これを忘れて若干嵌った。)
ビジュアライザーの波形はどうやって描画するか?
A:音声データはFloat32の配列であり、ある時点の音量xが-1.0 < x < 1.0の範囲に収まっている。描画したいCanvasの領域に対する相対的な位置をそこから求めて描画する。
以下、コードの抜粋と解説。
まずは音声データの解析から。
const multiChannelPeaks: number[][][] = []
const chunkSize = Math.ceil(buffer.length / this.canvasWidth)
for (var i = 0; i < buffer.numberOfChannels; i++) {
const data = buffer.getChannelData(i)
const _peaks: number[][] = []
for (var j = 0; j < this.canvasWidth; j++) {
const start = j * chunkSize
const end = start + chunkSize
const tmp = data.slice(start, end)
var min = 0 // 最小値
var max = 0 // 最大値
for (var c = 0; c < tmp.length; c++) {
const a = tmp[c]
min = Math.min(a, min)
max = Math.max(a, max)
}
_peaks.push([min, max])
}
multiChannelPeaks.push(_peaks)
}
const peaks = multiChannelPeaks.reduce((a, b) => {
const _peaks: number[][] = []
for (var i = 0; i < a.length; i++) {
_peaks.push([Math.min(a[i][0], b[i][0]), Math.max(a[i][1], b[i][1])])
}
return _peaks
})
最終的に得たいデータは[最小値, 最大値]のペアの配列であるが、音声データは複数のチャンネルを持ちうる(ステレオなら2チャンネル、5.1chなんてのもある)ので、ここではそれらも一旦全部配列に格納しておく。(multiChannelPeaks)
Canvasの1pxに描画したい[最小値, 最大値]のペアは、複数のフレームを読み取ってそこから最小値と最大値を求める。1pxあたりに必要なフレーム量(上記のchunkSize)は音声バッファ長さ/Canvasの横幅で求められる。
続いて実際の描画処理。
this._context.strokeStyle = this.colorNotPlayed
this._context.beginPath()
var pos = start
for (var i = 0; i < this._peaks.length; i++) {
const min = this._peaks[i][0]
const max = this._peaks[i][1]
const h = this.canvasHeight / 2
const top = h * max + h
const bottom = h * min + h
this._context.moveTo(pos, bottom)
this._context.lineTo(pos, top)
pos++
}
this._context.stroke()
Canvasは左上を原点(0, 0)とした座標形態になっているので、そのままマイナスの座標を渡しても期待した動作にならない。また、さきほど求めたpeaksの保持している値は、原点ではなくY軸中央からの相対的な距離と捉えられる。よって
- Canvasの縦幅の1/2を最小値と最大にそれぞれ掛けて相対的な量を実際のピクセルの量に変換する。
- 上記にCanvasの縦幅の1/2を加えて、「原点からの距離」ではなく「Y軸中央からの距離」に変換する。
オーディオの再生に合わせた描画はどうやって行うか?
A:requestAnimationFrameでアニメーションするよう指示し、requestAnimationFrameのコールバック関数内部でAudioContextの時刻情報から再生位置を割り出し、必要な分を描画する。
start () {
this._startTime = this._audioContext.currentTime
this._source.start()
this.state = State.PLAYING
requestAnimationFrame(this.mainLoop)
}
mainLoop () {
if (this.state !== State.PLAYING) {
return
}
const time = this._audioContext.currentTime - this._startTime
if (this._source.buffer === null) {
return
}
const playedLength = time * this._source.buffer.sampleRate
const chunkSize = Math.ceil(this._source.buffer.length / this.canvasWidth)
const playedSize = playedLength / chunkSize
this._context.strokeStyle = this.colorPlayed
this._context.beginPath()
var pos = 0
for (var i = 0; i < playedSize; i++) {
const min = this._peaks[i][0]
const max = this._peaks[i][1]
const h = this.canvasHeight / 2
const top = h * max + h
const bottom = h * min + h
this._context.moveTo(pos, bottom)
this._context.lineTo(pos, top)
pos++
}
this._context.stroke()
requestAnimationFrame(this.mainLoop)
}
再生を開始した時点のAudioContext#currentTimeを取得しているが、これはcurrentTimeプロパティがAudioContext生成時点からの時刻であり、再生開始時点からというわけではないのが理由。そのため、再生時刻は音声の再生開始時のcurrentTimeとの差分で求めている。(他に使えそうなプロパティが見つからなかった。)
音声バッファーのうち、どれだけのフレームを再生したかはサンプリング周波数と再生時間で求められる。(playedLength)上で解説した通り、音声バッファの長さとCanvasによって1pxに必要なフレーム量(chunkSize)が求められる。peaksのうちどれだけを再生済みとして描画するかは、playedLength / chunkSizeで求められる。
あとは繰り返し描画するためにmainLoopの最後で再度requestAnimationFrameを自信を引数にして呼び出している。
あまりVueの事(というかVue+rollupでのビルド)を書いていないが、これは次回以降に回すことにする。
どうでもいい宣伝
デモ用の音声ファイルには私の自作曲を使っているが、この曲の収録されたアルバムが下記にて絶賛発売中。