機械学習とパイプライン
エンジニアの皆さんは、「パイプライン」といえば何を思い浮かべるでしょうか?
恐らく多くの人は、
①最近ハッキングされたことで話題の、石油輸送管
②基本情報試験などで頻出の、CPUの並行命令実行の仕組み
を思い浮かべるかと思います。

※画像はWikipediaより
機械学習分野でも、Scikit-LearnやMLOps系のツールにおいて頻出する用語であり、
何となく、「複数の処理を連続で行う仕組み」といったイメージを持たれている方が多いかと思います。
ですが、連続処理なら各処理を順番に実装すれば同様の機能を実現できるため、正直
「メリットがよく分からん!」
と思われている方も多いかと思います。
私もそう思っていましたが、調べてみると、場面によっては必要不可欠と言えるようなメリットがある事が分かったので、
記事にまとめようと思います
パイプラインとは?
パイプラインの概要と実装例を解説します
機械学習と前処理
一般的に機械学習は、学習器(サポートベクターマシン、ランダムフォレストなど)を適用するだけでは性能を発揮できず、事前に前処理を実施する必要があることが多いです。
例えば、サポートベクターマシンは変数のスケールが揃っている必要があるため、
平均が0、標準偏差が±1となるようスケール変換する「標準化」を事前実行する必要があります
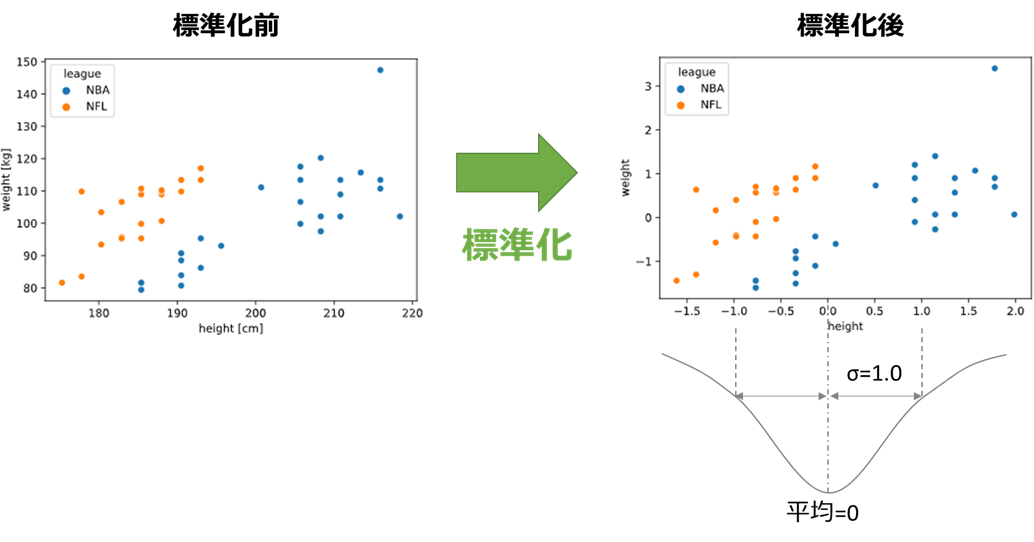
このように、機械学習は
「前処理1 → 前処理2 → ‥ → 学習器」
といった具合で、複数の処理を逐次的に進めることが一般的であり、
この一連の処理をまとめて実行できるようにする仕組みをパイプラインと呼びます。
例えば「標準化(前処理1) → 主成分分析(前処理2) → サポートベクタマシン」の一連の処理を、
最もシンプルな、「学習データ = 推論データ」で実行する場合、以下のようなフローで処理を行います
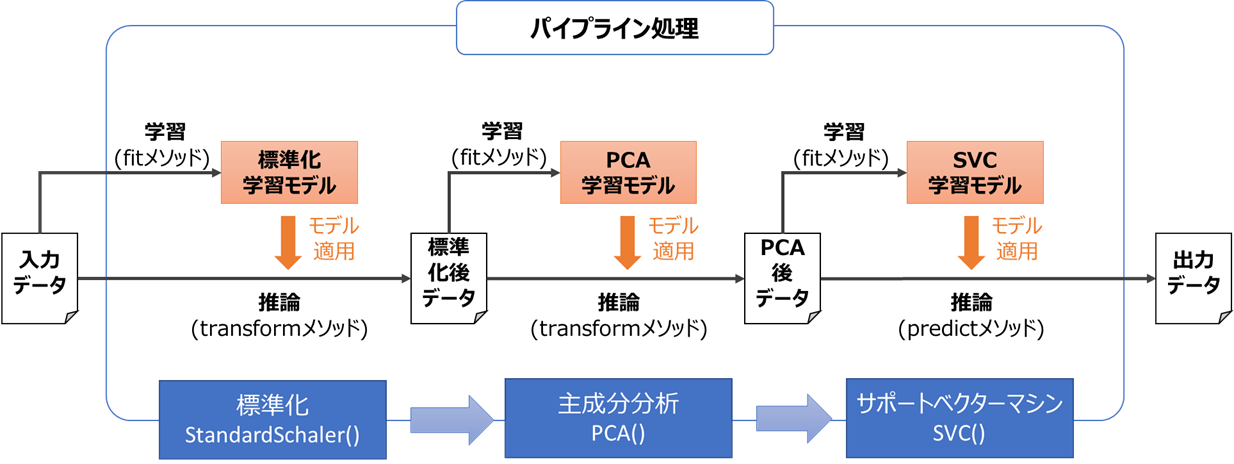
パイプライン処理のシンプルな実装
前述の「学習データ = 推論データ」の例を、実際に実装してみます。
データには以下のirisデータセットを使用します
import seaborn as sns
iris = sns.load_dataset("iris") # irisデータセットを使用
features = ['petal_width', 'petal_length', 'sepal_width'] # 説明変数
X = iris[features].values # 説明変数をndarray化
y = iris['species'] # 目的変数をndarray化
スクラッチで実装
まずは前述の例の通り、パイプライン用の特別なクラスは利用せず、素直に実装してみます
from sklearn.pipeline import Pipeline # パイプライン用クラス
from sklearn.preprocessing import StandardScaler # 標準化クラス
from sklearn.decomposition import PCA # 主成分分析クラス
from sklearn.svm import SVC # サポートベクターマシン分類クラス
scaler = StandardScaler()
pca = PCA(n_components=2)
svm = SVC()
scaler.fit(X) # 標準化の学習
X_scaler = scaler.transform(X) # 標準化の推論
pca.fit(X_scaler) # 主成分分析の学習
X_pca = pca.transform(X_scaler) # 主成分分析の推論
svm.fit(X_pca, y) # SVMの学習
pred = svm.predict(X_pca) # SVMの推論
Scikit-LearnのPipeLineクラスで実装
Scikit-Learnには、パイプラインを実装するためのPipeLineクラスが存在します。
こちらを使って実装してみます。
from sklearn.pipeline import Pipeline # パイプライン用クラス
from sklearn.preprocessing import StandardScaler # 標準化クラス
from sklearn.decomposition import PCA # 主成分分析クラス
from sklearn.svm import SVC # サポートベクターマシン分類クラス
pipe = Pipeline([("scaler", StandardScaler()),
("pca", PCA(n_components=2)),
("svm", SVC())])
pipe.fit(X, y) # 学習
pred = pipe.predict(X) # 推論
スクラッチのときと比べ、コードが短くまとまりましたが、それほど大きな差ではありません。
むしろ処理の流れが分かりにくくなり、これだけではデメリットすら感じてしまいます。
パイプラインのメリット
前述のように、「学習データ = 推論データ」の条件では、パイプラインのメリットを感じる事ができませんでした。
一方で実際の機械学習においては、学習データと推論データ(テストデータ)を分ける事が多いです。
Scikit-Learnなどのライブラリでは、パイプライン用クラスは学習メソッドと推論メソッドから構成されており、
それぞれ以下のように動作します。
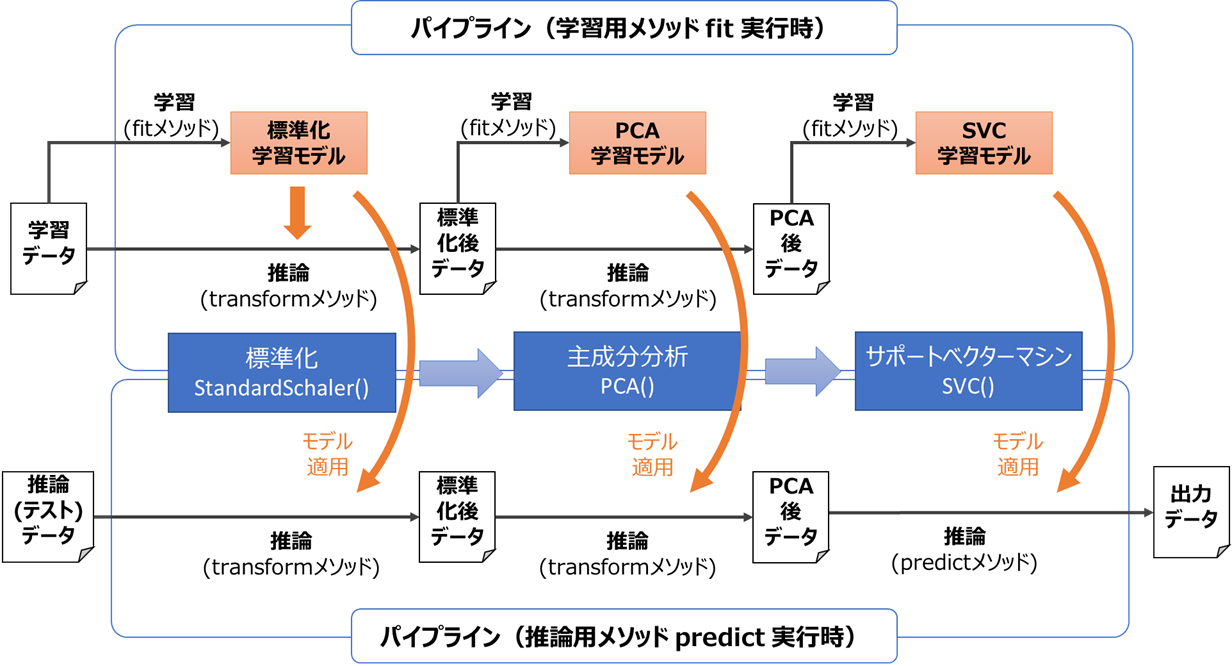
要約すると
・学習用メソッドは、最後の処理(学習器)以外の学習と推論を実行し、最後の処理は学習のみ実行する
・推論用メソッドは、全ての処理の推論を順番に実行する
となります。
この構成は、学習データと推論データを分けた場合の実装がシンプルになるというメリットがあります。
どのようなデータの分け方をしても、パイプラインの学習・推論用メソッドを、あたかも学習器単体の学習・推論用メソッドのように扱えるからです。
学習・推論データを分けた場合のパイプライン処理実装
上記のメリットを実感するために、パイプライン用クラスを使用した場合としない場合で、
学習・推論データを分けた場合の実装を比較してみます
パイプライン用クラスを使用しない場合
from sklearn.model_selection import train_test_split # データ分割用メソッド
scaler = StandardScaler()
pca = PCA(n_components=2)
svm = SVC()
# 学習データと推論データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 学習データに対して学習実行
scaler.fit(X_train) # 標準化の学習
X_train_scaler = scaler.transform(X) # 標準化の推論
pca.fit(X_train_scaler) # 主成分分析の学習
X_train_pca = pca.transform(X_train_scaler) # 主成分分析の推論
svm.fit(X_train_pca, y) # SVMの学習
# 推論データに対して推論実行
X_test_scaler = scaler.transform(X) # 標準化の推論
X_test_pca = pca.transform(X_test_scaler) # 主成分分析の推論
pred = svm.predict(X_test_pca) # SVMの推論
学習データと推論データそれぞれにpredictメソッドを適用する必要があるため、
「学習データ=推論データ」のときと比べ行数が増えています
Pipelineクラスを使用する場合
from sklearn.model_selection import train_test_split # データ分割用メソッド
pipe = Pipeline([("scaler", StandardScaler()),
("pca", PCA(n_components=2)),
("svm", SVC())])
# 学習データと推論データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 学習データに対して学習実行
pipe.fit(X_train, y_train)
# 推論データに対して推論実行
pred = pipe.predict(X_test)
「学習データ=推論データ」のときと同様、学習(fitメソッド)と推論(predict)が1行ずつで済んでおり、行数の増加を防げています。
このように、学習データと推論データを分けた場合でも実装がシンプルになるというパイプラインのメリットを、実感する事が出来ました。
クロスバリデーションとパイプライン
パイプラインが真価を発揮するのが、クロスバリデーションを実施するときです。
クロスバリデーションとは、機械学習の性能評価を行う代表的な手法で、
データをN等分した上で、1つのグループをテストデータとし、残りを学習データとするよう分割し、
それぞれのテストデータから算出したスコアを平均して、最終的なスコアとします。
クロスバリデーションの分割イメージは、下のWikipediaの図が分かりやすいです

クロスバリデーションにおいても、パイプライン用クラスを使用しない場合とする場合での実装を比較してみます。
パイプライン用クラスを使用しない場合
from sklearn.model_selection import KFold # クロスバリデーション分割用クラス
from sklearn.metrics import accuracy_score # スコア(accuracy)算出用クラス
import numpy as np
scaler = StandardScaler()
pca = PCA(n_components=2)
svm = SVC()
# スコア保持用のリスト
scores = []
# クロスバリデーション実行
cv = KFold(n_splits=5, shuffle=True, random_state=42) # クロスバリデーション用クラス
for train, test in cv.split(X, y):
X_train, X_test = X[train], X[test]
y_train, y_test = y[train], y[test]
# 学習データに対して学習実行
scaler.fit(X_train) # 標準化の学習
X_train_scaler = scaler.transform(X) # 標準化の推論
pca.fit(X_train_scaler) # 主成分分析の学習
X_train_pca = pca.transform(X_train_scaler) # 主成分分析の推論
svm.fit(X_train_pca, y) # SVMの学習
# 推論データに対して推論実行
X_test_scaler = scaler.transform(X) # 標準化の推論
X_test_pca = pca.transform(X_test_scaler) # 主成分分析の推論
pred = svm.predict(X_test_pca) # SVMの推論
# スコア算出
accuracy = accuracy_score(y, pred)
scores.append(accuracy)
# スコアを平均して最終指標とする
score = np.mean(scores)
データの分割がループ実行となり、スコアの算出も加わるので、実装がかなり長くなりました。
パイプライン用クラスを使用する場合
from sklearn.model_selection import KFold, cross_val_score # クロスバリデーション指標算出用クラス
import numpy as np
pipe = Pipeline([("scaler", StandardScaler()),
("pca", PCA(n_components=2)),
("svm", SVC())])
# クロスバリデーション実行
cv = KFold(n_splits=5, shuffle=True, random_state=42) # クロスバリデーション用クラス
scores = cross_val_score(pipe, X, y, scoring='accuracy', cv=cv)
# スコアを平均して最終指標とする
score = np.mean(scores)
クロスバリデーション用のcross_val_scoreメソッドを利用する事で、ビックリするくらい短い実装が実現できます。
このcross_val_scoreメソッドは、Pipelineクラスなしでは前処理を含めたモデルを正しくデータ分割する事ができないので、
まさにパイプラインの恩恵を受けた形となります。
Scikit-Learnのような機械学習ライブラリには、cross_var_score以外にもクロスバリデーションを利用した便利なメソッドが多数用意されており、パラメータチューニングに利用されるグリッドサーチ(GridSearchCV)はその代表例です。
パイプラインがなければ、前処理を含むモデルでは上記の便利なメソッドを利用する事ができず、スクラッチで多大な手間を掛けて実装する必要があります。
そのため、実用上は前処理を含めてクロスバリデーションを利用するためには、パイプライン処理が必要不可欠と言えます。
まとめ
以上まとめると、
パイプラインの概要およびメリットは、以下のようになります。
・機械学習パイプラインは、複数の処理を結合し、あたかも1つの学習器のように学習・推論を行える仕組み
・パイプラインのメリットは、学習データと推論データを分けた際に、実装をシンプルにできること
・クロスバリデーション実行時に、特に大きな効果を得られる
最近流行りのMLOpsにおいても、「パイプラインで効率的に開発・運用しよう!」という考え方は根幹の一つを占めているので、覚えておいて損はないかと思います!
以上、最後まで読んで頂きありがとうございました!