個人開発で食事管理サービスを作っています。
「食品の栄養成分表示の画像から栄養素の名前と含有量を取れたらいいなあ」と思い、OCRを使うことにしました。
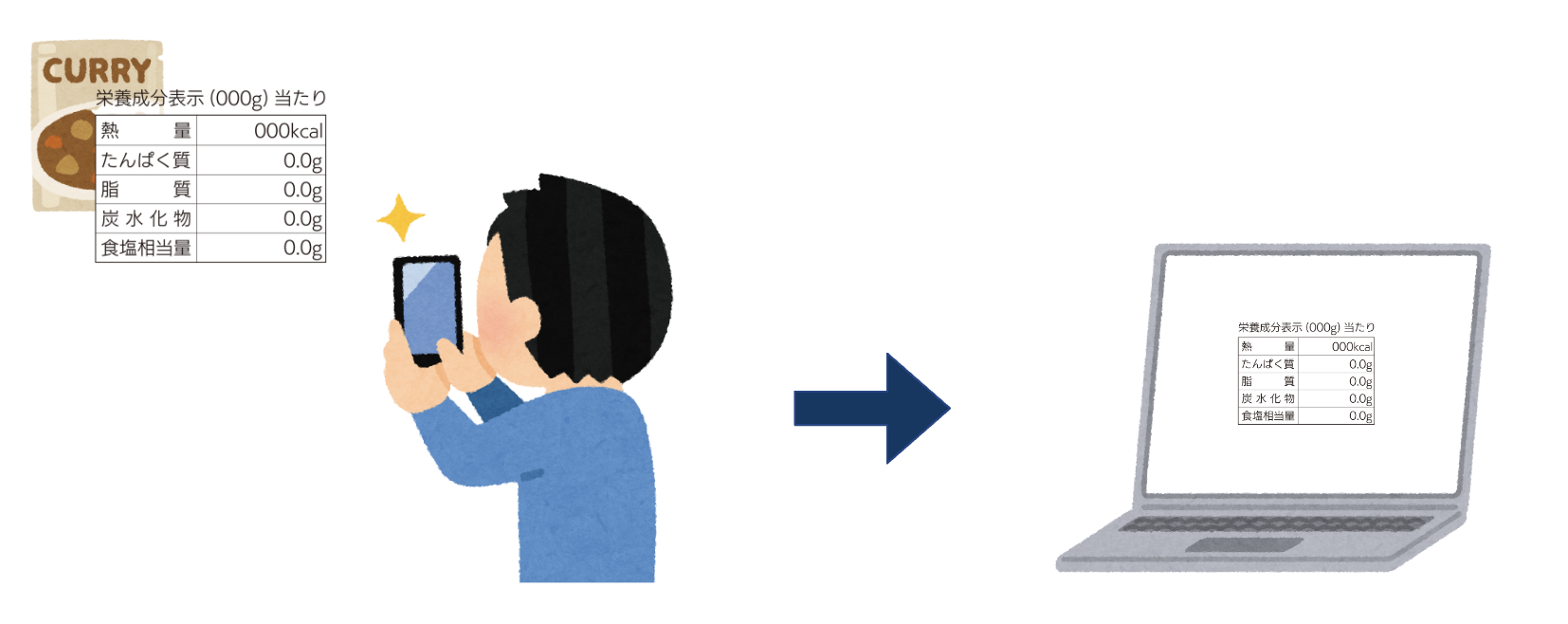
この記事では、Pythonで扱えるOCRツールを比較し、もっとも精度が高かったものを紹介します。
はじめに
やりたいこと
やりたいことは、画像から所定の文字列を抽出すること。より具体的には、
- 日本語の文字列を取得すること
- 平面以外の物体に記載された文字列を抽出すること
この記事で書くこと
- やりたいことを達成するにあたり、もっとも精度の高いOCRツールは何か
- 各OCRツールの精度を比較した結果と経緯
この記事で書かないこと
各OCRツールのインストール方法等の詳細な取り扱い手順
どのOCRツールを比較したか
以下4つのサービス・ライブラリを比較しました。
- AWS Textract
- PyTesseract
- pyocr
- GCP Vison AI
どのOCRツールがもっとも高精度か
GCP Vison AIがもっとも精度が高かったです。
▼比較まとめ
| AWS Textract | PyTesseract | pyocr | GCP Vison AI | |
|---|---|---|---|---|
| 日本語の文字列を正しく取得できるか | × | ⚪ | × | ⚪ |
| 平面以外の物体に記載された文字列を正しく取得できるか | × | △ | × | ⚪ |
※⚪:できる、△:ちょっとできる、×:できない
※結果は個人の力量と観察に基づくものです
各OCRツールの精度の判定方法と実行結果
どのように精度を判定したか
判定方法
各ORCツールをPythonで実行し、出力結果が以下の要件を満たすかを確認する。
- 日本語の文字列を正しく取得できること
- 平面以外の物体に記載された文字列を正しく取得できること
使用する画像の条件
いずれのOCRツールを実行する際も、以下の2種類の画像を読み込む。
以下、項目をクリックすると、画像が表示されます。
平面に文字が記載された画像

凹凸のある物体の画像

各OCRツールの実行結果
※以下、プログラムを実行時に使用するPythonのバージョンは、Python 3.10.1
AWS Textract
プログラム
# AWS Textractは日本語未対応
# https://aws.amazon.com/jp/textract/faqs/
import boto3 # バージョン: 1.34.7
def extract_text(image_file):
# AWSクライアントを作成
client = boto3.client('textract',
region_name='XXXXX',
aws_access_key_id='XXXXX',
aws_secret_access_key='XXXXX')
# 画像ファイルを読み込む
with open(image_file, 'rb') as file:
img = file.read()
# AWS Textractで画像解析
response = client.detect_document_text(Document={'Bytes': img})
# 抽出されたテキストを表示
for item in response['Blocks']:
if item['BlockType'] == 'LINE':
print(item['Text'])
# 画像ファイルパスを指定して関数を実行
extract_text('../path/to/image.jpg')
判定
1.日本語の文字を取得できるか
できない。2023年12月時点で日本語に対応していないそう(参考)
クリックして実行結果を見る
#
()
=
R
=
= (1°C~10°C)
N
=
=
N
=
- 37kcal/th 3.0g/ 0.8g/
5.6g 3.0g/ 2.6g)/
0.1g
)
#
()
=
R
=
= (1°C~10°C)
N
=
=
N
=
- 37kcal/th 3.0g/ 0.8g/
5.6g 3.0g/ 2.6g)/
0.1g
)
2.平面以外の物体に記載された文字列を正しく取得できるか
できない
クリックして実行結果を見る
THE
500ml
.
0
:
IIF- 0kcal/tch
12< 0g/ 0g/
0g(
0g)
PyTesseract
プログラム
from PIL import Image # バージョン: 9.5.0
import pytesseract # バージョン: 0.3.10
def extract_text(file_path):
# 画像を読み込む
image = Image.open(file_path)
# Tesseractを使って画像内のテキストを抽出する
text = pytesseract.image_to_string(image, lang='jpn')
return print(text)
if __name__ == "__main__":
extract_text('../path/to/image.jpg')
出力結果
判定
1.日本語の文字を取得できるか
できる。ただし、取れる文字とそうでない文字がある。また、中国語のような変な文字列に解釈されている箇所が存在する
クリックして実行結果を見る
質 0.⑧⑨/
炭 水 化 物 ⑤.⑥g ( 糖 質 ③.0⑨/ 食 物 繊 維 ②.⑥⑨)/ 食 塩
メ ー
材 料 名
内 容 量
浦
乞"._
装 造 者
剛
っ | o
る ) E
錬關關臨蝿ー 団 阿
ン 電 琴 琴 ピ ご ー ① ま
ぃ 世 畜 圧 二 直 に 報 | さ
小 圓 固 驚ー e ま
も 磁 槌 槌 朱 に
ト 塁 _
佐 焉 茂 | 為 | 荒 さ
國
咎 H
栄 養 成 分 表 示
ー マ
ル ー
2.平面以外の物体に記載された文字列を正しく取得できるか
できる。ただし、平面の場合よりも、取得できる情報量が少ない
クリックして実行結果を見る
ー
W | 高 温 多 湿 を さ け て 、 保
| 戻 て く だ さ い e
pyocr
プログラム
import sys
from PIL import Image # バージョン: 9.5.0
import pyocr # バージョン: 0.8.5
def extract_text(image_file):
# 利用可能なOCRツールを取得
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("OCRツールが見つかりませんでした。")
sys.exit(1)
# 利用するOCRツールを選択
tool = tools[0]
print("使用するOCRツール: pyocr(%s)" % (tool.get_name()))
# 画像を読み込み
img = Image.open(image_file)
# OCRを実行してテキストを抽出
text = tool.image_to_string(
img,
lang="jpn",
builder=pyocr.builders.TextBuilder()
)
# 結果の出力
print(text)
# 画像ファイルパスを指定して関数を実行
extract_text('../path/to/image.jpg')
出力結果
判定
1.日本語の文字を取得できるか
できる。ただし、他のツールに比べて取得できる情報量は少ない
クリックして実行結果を見る
使用するOCRツール: pyocr(Tesseract (sh))
エ ネ ル ギ ー ③⑦kcal/ た ん ば ぱ く 質 ③.0g/ 脂 質 0.⑧⑨/
炭 水 化 物 ⑤.⑥g ( 糖 質 ③.0⑨/ 食 物 繊 維 ②.⑥⑨)/ 食 塩
2.平面以外の物体に記載された文字列を正しく取得できるか
できない。画像から文字を取得できなかった
クリックして実行結果を見る
使用するOCRツール: pyocr(Tesseract (sh))
GCP Vison AI
プログラム
import os
from google.cloud import vision # バージョン: 3.5.0
def extract_text(image_file):
"""Detects text in the file."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./gcp-signature.json"
client = vision.ImageAnnotatorClient()
with open(image_file, "rb") as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
result = texts[0].description if texts else None
if response.error.message:
raise Exception(
"{}\nFor more info on error messages, check: "
"https://cloud.google.com/apis/design/errors".format(response.error.message)
)
print(f'Text: {result}')
# 画像ファイルパスを指定して関数を実行
extract_text('../path/to/image.jpg')
判定
1.日本語の文字を取得できるか
できる
クリックして実行結果を見る
Text: 名 称 = サラダ (惣菜)
原材料名=表面右側に記載
内容量 : 表面左側に記載
消費期限 =表面右側に記載
保存方法=冷蔵(1℃~10℃)
製造者=
お問い合わせ先=
I
製造日=表面右側に記載
栄養成分表示 : 1袋120g当たり
エネルギー 37kcal/たんぱく質 3.0g/脂質 0.8g/
炭水化物 5.6g (糖質3.0g/食物繊維 2.6g)/食塩
相当量 0.1g
(推定値)
2.平面以外の物体に記載された文字列を正しく取得できるか
できる
クリックして実行結果を見る
Text: 国産名称 炭酸飲料 ●原
材料名 ナチュラルミネ
ラルウォーター/炭酸
●内容量 500ml●賞
味期限 キャップに記載
●保存方法 直射日光・
高温多湿をさけて、保
存してください。
賞味期限右側は
製造所固有記号
栄養成分表示:100ml当たり
エネルギー0kcal/たん
ぱく質 0g/脂質 0g/炭水
化物 0g(糖質0g/食物
繊維 0g)/ 食塩相当量0g
ここからはがせます
〇. Stro
100
まとめ
前述の通り、GCP Vison AIがもっとも精度が高いと判断しました。
各OCRツールの精度を比較すると、以下のようなイメージです。
| AWS Textract | PyTesseract | pyocr | GCP Vison AI | |
|---|---|---|---|---|
| 日本語の文字列を正しく取得できるか | × | ⚪ | × | ⚪ |
| 平面以外の物体に記載された文字列を正しく取得できるか | × | △ | × | ⚪ |
※⚪:できる、△:ちょっとできる、×:できない
最後まで読んでくださり、ありがとうございました。
今回は基本的な使用方法のみ使って各OCRツールを比較し、GCP Vison AIが高精度としました。ただ、設定を調整したりやオプションをうまく使えば、他のツールでも期待どおり機能するかもしれないです。
また、今回は食品の包装画像を使って単語を取得しようとしたわけですが、別の目的では他のツールでも十分機能するであろうことはお伝えしておきます。