記事の作成背景
- データエンジニアリングができるデータサイエンティストになりたいと思い、現在、データエンジニアリングの勉強中
- 今回は**「データ活用基盤の保守・運用」のデータ集計**との戦いについて書きます
データ活用基盤の構成
ここで紹介したいデータ活用基盤の構成の簡略したものを以下に示す。
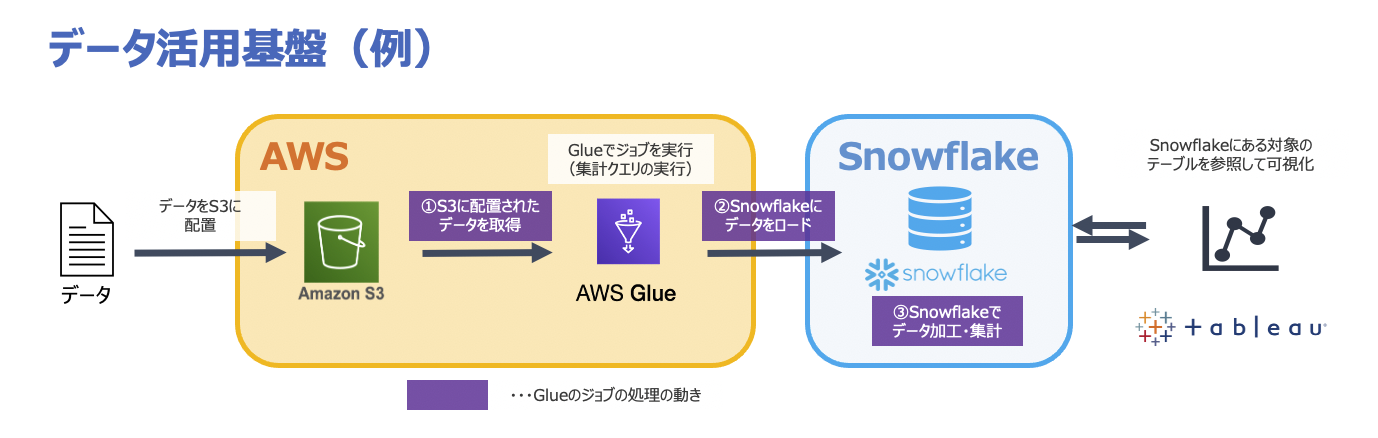
- データがAWSのS3に配置される
- AWSのGlueのジョブ実行すると以下の処理が行われる
- AWSのS3に配置されたデータを取得
- Snowflake にデータをロード
- ロードしたデータをもとにデータを加工・集計
- TableauでSnowflakeのデータベースを参照し、データを可視化
今回はデータ集計の話
- 今回はあるデータ基盤の保守・運用の引き継ぎを受け、最初にぶち当たった壁の話をします
- データ集計の処理の仕組みについての例を簡単にまとめた図がこちら↓

実際は、上記のようなジョブが25~30個近くある。
可視化したいデータがあり、可視化のために必要なテーブルがない場合は、現状の仕組みでは、集計ロジックの追加開発を行いデータを再集計する必要がある。データの再集計時にはこれらジョブを手動で実行する必要がある。
データ集計に必要なこと
- いかに再集計に要する期間を短縮できるか
- テーブル同士の依存関係を理解する(集計クエリを理解する)
- ジョブの中身を理解する
上記について順に紹介
1. いかに再集計に要する期間を短縮できるか
新しい情報をTableau画面に表示するような開発は、データを再集計して対象のデータが表示される状態で納品をする。そのため、早くその情報が見たい場合に再集計の期間をできるだけ抑えることを考える。開発だけではなく、データに不備が発覚した場合は早くデータを正常な状態にリカバリする必要がある。このような場合において、どのジョブをどの順番で実行すべきか、実行の必要がないジョブはどれか、などを考慮しなければならない。
集計を早める方法としては、主に以下の2択
- 効率よくジョブを実行する
- 集計を実行するSnowflakeに課金をして処理を早くしてもらう (次の記事でここふかぼる)
集計を早める方法として、最初に後者の課金を選択するのは賢くない
データエンジニアなら前者を考えて、できるだけベストを尽くす方が真っ当だし、スキルも上がる。
ただし、そのためには恐ろしく大変な次の2つをする必要がある。
2. テーブル同士の依存関係を理解する(集計クエリを理解する)
引き継ぎを受けたとき、理解するまっでに一番苦労したところです。
ドキュメントが特に整理されていたわけではないので、クエリを読んでテーブル同士の関係を読み解いて理解するしかない。
(鬼畜だと思ったけれど実はこれが一番自分のSQLのスキルを爆上げしてくれた)
データ集計に不備があった際に、これを理解していなければ、どこが原因箇所なのか見当すらつけることができない
「テーブル同士の依存関係を理解する」は、データ基盤の保守・運用の心理的ストレスを減らす方法の一つだ!
テーブルについて質問があったとき、引継ぎ当初の私は答えられない自分にとても落ち込み、質問されるのがとても怖くなってしまったことがありました。データの不備がわかった時は、誰かに押し付けたくなるほど、このプロジェクトに恐怖感を抱いていました。解決方法は「わからないところを理解する」ことに向き合うの一択でした。
それに努めた結果、「全部理解するぞー!」と思う心理状態に変わりました。
3. ジョブの中身を理解する
ジョブの中身を理解することは、テーブル同士の依存関係を理解することとは少し異なります。
- テーブルがそもそもS3、Snowflakeのどちらにあるのか、Athna、Snowflakeどちらで集計を実行しているのかを理解する
- ジョブ内で実行されるクエリはどれかを理解する
「2. テーブル同士の依存関係を理解する(集計クエリを理解する)」ができていれば、これはお手の物ですね。
「仕事に怯えずに、仕事を楽しくやるために、いろんな意味での成長を得るために、やるしかないのです。」
まとめ
**データ基盤の保守・運用はデータに怯えることから始まる(戦記①)**どうでしたか。
急ぎ足で書いた記事ですが、データ基盤の保守・運用で闘う世界の皆にエールをこの記事から送るぞぉお!!
補足
- なぜAWSGlueのツールの一つ「ワークフロー」を使わない?
- データの過去分を再集計する場面では、期間にもよるが、ワークフローを使用せず手動でジョブを動かした方が集計に必要な期間を短縮することができるため
- デメリット:ジョブを見張る必要がある、
- メリット:追加開発で取得したい目的のデータが得られているかを確認しながら集計ができる
- データの過去分を再集計する場面では、期間にもよるが、ワークフローを使用せず手動でジョブを動かした方が集計に必要な期間を短縮することができるため
次回は以下の3本だて
- 「AWS CLIからジョブを監視する方法: ブラウザからのポチポチ、ブラウザとの睨めっこはやめないかい? 」の巻
- 「Snowflakeのクレジット溶は、スキル成長が大前提」の巻
- 「再集計範囲を最小限に抑える方法: Viewを使え!」の巻