はじめに
この度KaggleのBirdCLEF2024に参加しました。コンペの結果としては、Publicスコアで0.70(18位)からPrivateスコアで0.64(256位)と大幅に順位が下がるという残念な結果となりました。
多くの方が使用された公開コードのPrivateスコアが高かったため、32位から245位までが同率になってしまい、私を含め多くの銀~銅圏内の参加者がメダル圏外まで落ちる結果となりました。ある程度の順位変動は覚悟していましたが、公開コードを使わずにメダル圏内に残るには、975人の参加者のうち上位31位に入る必要があった、という厳しいコンペでした。
結果だけみると残念でしたが、コンペを通じて得られた知見も多く、振り返りと反省を込めてこの記事にまとめたいと思います。記憶を遡りつつ執筆しており、またコンペ経験が浅く誤りもあるかもしれませんが、ご容赦ください!
この記事で書くこと
- 自己紹介
- 鳥コンペ(BirdCLEF2024)の概要
- コンペにどう取り組んだか
自己紹介
私は普段、センシング技術の研究開発を行っています。ハードウェアからソフトウェアまで幅広く手掛けていますが、最近は信号処理などソフト寄りの内容が多めです。機械学習手法を業務でも試すことがあり、データ分析コンペには2〜3年前から参加しています。主にセンサデータ(画像や音のデータ)を扱うコンペに参加しており、自己研鑽と新しい技術の習得を目的としています。
鳥コンペ(BirdCLEF2024)の概要

詳しくは上記リンクをご参照ください。ざっくりいうと、鳥の鳴き声データから種別を識別するコンペです。BirdCLEF2019から続いている過去の鳥コンペのルールと比較すると、推論の制限(CPUで2時間以内)が強い点は特徴的だったのではないかと思います。また本コンペでは学習用データと推論用データの分布が明らかに異なり、CVとLBの乖離が大きいことがコンペ当初から指摘されていました。
コンペにどう取り組んだか
データのドメインが明らかにシフトしているコンペとして、最近参加したSignateのサイコロコンペに近い印象を受けました。このコンペでは、特殊なサイコロ1-3個の画像データから出目の合計(18種)を分類するという内容なのですが、学習データでは1-2個のサイコロのデータしか与えられておらず、かつ、テストデータにはノイズが付与されているのが特徴でした。
恐らく、多くのサイコロコンペ参加者は、複数のサイコロデータを組み合わせて3個の新しいデータを生成したり、データ拡張(Data Augmentation)でノイズを付与していたと思います。そのような中で、コンペ参加者が途中で公開されたノイズ模擬手法が優秀で、実際のテストデータの分布に近かったため、入賞者は(記憶では入賞された発表者全員が)こちらの手法を使われていたと思います。私にとっては、機械学習において学習用と推論用のデータの一致は重要だと改めて実感したコンペでした。
さて、鳥コンペの話に戻りますが、サイコロコンペの経験を活かし、学習用と推論用データの一致を重視しました。特に、テストデータのノイズを模擬することに注力し、安定して高精度を出す条件を探索しました。私が試した中では、データ同士を相互に重ね合わせるMixupが重要であり、強さのバランスを取ることで安定して高いスコアが得られました。試したモデルの中で、3種類のデータをアンサンブル(triple-mixup)する手法が特に安定してハイスコアが得られる様子でした。Mixupの係数はディリクレ分布で指定しています。複数の音データが混ざっているテストデータを模擬する意味では、triple-mixupで安定化するのは個人的には納得感があり、私が試した中では比較的安定して高いスコアが出るようになりましたので、中盤以降はtriple-mixupで統一しました。ちなみに、4つ以上でmixupすると、LBは下がる傾向でした。
また、追加で効果的だったのはunlabeled_soundscapesとのMixupです。本コンペでは推論用データと同じ場所で録音されたラベルなし音声データがunlabeled_soundscapesとして提供されており、これをどう使うかが鍵だったと思います。過学習気味であることを承知のうえで、一度全unlabeledデータに対して推論をかけてpseudo-labelを付与し、それを参照してunlabeledデータをtrainデータにMixupさせる試みを行いました。しかしながら、これはうまくいかずスコアが落ちる傾向にありました。最終的にはランダムに選んだunlabeledデータとのMixupを採用しました。ここはもっと上手く使いたかったのですが、実力不足でした。
上記の手順でMixup周りを固定し、最終的には、GeM Pooling, FocalLossBCE, CoarseDropout, HorizontalFlipなどを組み合わせ、Efficientnet, EfficientnetV2, Mobilenet, Mobileone, ConvNeXt, Mixnets, RegNetなどのモデルを試しました。各種モデルのCVとLBを比較した結果は以下の通りです。異なるモデル、foldの結果も同じグラフ上でプロットしています。
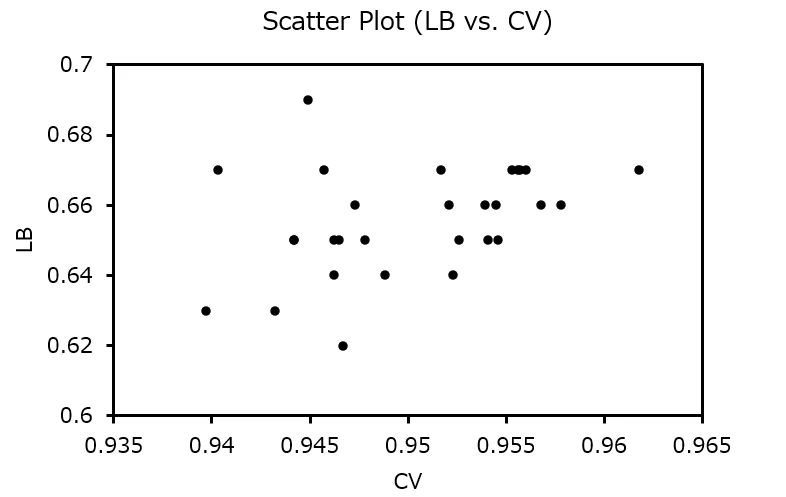
グラフの見方として、CVはローカルで計算しているため小数点以下4桁まで算出しているのですが、コンペ終了前のLBは下2桁までしか表示されないため、縦軸の値は飛び飛びの値となっています。スコア順にソートする機能はありますので、Publicのソート順もみながら確認していました。
CVとLBに弱い相関は見られましたが、中にはLBで非常に高いスコアのモデルもあり、モデル選択には悩みました。最終的に、①CVとLBで共に高いモデルのアンサンブルと②LBで最も高いモデルのアンサンブルの両方を提出しました。また上のグラフには表しきれていないですが、モデルによって演算時間が短いもの、長いものがあり、どの組み合わせにするかは最後に悩んだところです。
提出した①と②のうち、結果としては後者の方が良いスコアとなりました。戦略的に①と②を提出したことで、直近1-2か月で色々と試した中では最もPrivateスコアがよいモデル②を選ぶことができたので、その点は悔いなしです。
これは提出後に分かる話ではありますが、私が作成した全モデルのPublicとPrivateのスコアを比較した結果は以下のようになり、比較的相関していたようです。あくまで結果論としてですが、Publicを信用した方がよいスコアになりやすかったようです。
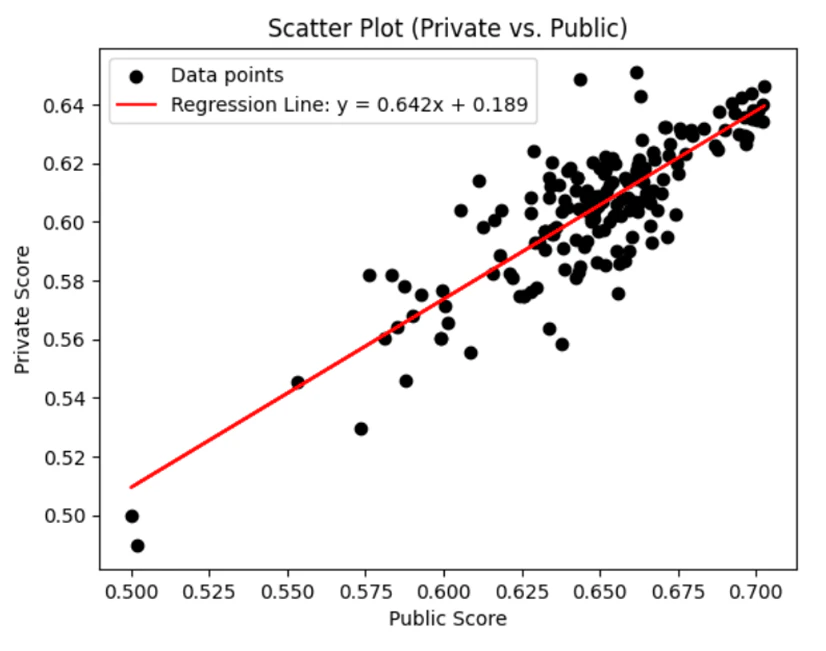
ちなみに、上のグラフ中で外れ値のように回帰直線よりも上振れしている点(Private Score = 0.65)があります。これは私がコンペ序盤に作ったモデルで、あくまで結果論としてですが、銀圏上位につけるモデルもあったようでした。ただし、この結果は非常に不安定なようで、少しだけパラメータを変えたモデルでは大きくスコアを落としていました。たまたま良い乱数にあたるとPrivateに対してオーバーフィッティングできたようですが、不安定なモデルを選ぶことはできなかったので致し方なしです。コンペ序盤に試していたときは、スコアも安定化せずに苦しんでいたのですが、Triple Mixup+Unlabeled mixup以降は比較的安定して高いスコアが得られたので、納得感のあるモデルを提出できてよかったです。
感想・反省点
長々と書きましたが、本コンペを通じて学習用データと推論用データを揃えることの重要性を実感しました。様々なモデルを試し、地道な努力が結果に結びつくことを経験しました。また、戦略的にアンサンブルモデルを作ることも良い経験でした。
本コンペではfoldやseedを変えるだけでスコアがぶれやすく、終始シェイクダウンを懸念していました。LBやCVではたまたま良いスコアであるだけで、Privateで落ちるのはKaggleの定番です。しかし、先ほどのグラフをみると、Private = Public*0.642 +0.189で相関性があり、選んだモデルのPublic=0.702792をこの式に代入するとPrivate = 0.640でした。実際のPrivateスコアは0.646254とほとんど一致しており、期待されるスコアを維持できたのは良かったと思います。
記事の最初に触れた、同率32位から245位となったモデルは、Privateで0.649998, Publicで0.654307であり、他のコンペ参加者のスコアと比較しても、良い乱数にあたったのだと考えています。最初にシェイクダウンと書きましたが、どちらかというと他の大勢の方のシェイクアップという方が正しいかもしれません。
自分のシェイクダウンは警戒していましたが、多くの方がシェイクアップする展開は予想できなかったので、致し方なしです。
反省点として、コンペ中盤からあまり公開Notebookを見ていなかった点があります。もう少し他の方のソリューションを見る時間を増やすべきでした。また、前処理に多くの時間を割いたため、コンペ終盤でONNX等のモデルを試す時間が取れませんでした。推論時間を圧縮できれば、複数のモデルをアンサンブルでき、もう少しスコアを伸ばせたかもしれません。
ここまで読んでくださった方、ありがとうございます。本コンペに参加された方もそうでない方も、もしよければ一緒にチームを組んでいただけると嬉しいです。また、どこかのコンペでご一緒できるのを楽しみにしています!