結論
ドライバやライブラリはちゃんと入っていますか?
背景
偶然ローカルLLMを用いたソフトウェア開発案件に携わることになり、そこで性能テストをしていた時、奇妙なことが起こりました。簡潔に言うと良いGPUを積んでいる機体の方が処理に時間がかかりました。LLMの処理速度というものは基本的にGPUの性能に依存しているはずで、良いGPUを積んでいる方が処理時間が長いなどということはあり得ないと考えていたためです。そこでなぜこのようなことが起こったのか調べたのでまとめておきます。
試行錯誤
まずは使用したPCたちを並べる。
| ゲーミングノートPC | デスクトップPC | AWS EC2 | |
|---|---|---|---|
| CPU | intel corei7-13620H | 不明 | おそらくXeon系 |
| GPU | RTX4050 | RTX4060Ti | Tesla T4 |
| OS | Win11 | Win11 | Amazon Linux |
| VRAM | 6GB | 8GB | 16GB |
その他
・使用したOllamaのモデルサイズは4.9GB(量子化済み)
・自分が見たのはゲーミングノートPC環境のみで他は他人の報告によるデータ
・テストでは社内で開発している同じソフトの同じバージョンを使用
・自分はこの案件に途中からアサインされたため一部設定など不明な部分がある
色々試験を行っていく中で実行時間についてこのような結果が得られました。試験対象データは10000レコード程度のcsv。
・ノートPC(RTX4050):約5時間
・AWS EC2(T4):約2.5時間
この結果は直感に反するものです。RTX4050はT4より35%処理能力が高い1はずで、何かRTX4050の環境に問題があるのではと推測されました。
そこで処理中のタスクマネージャを見るとこのようになっていました。
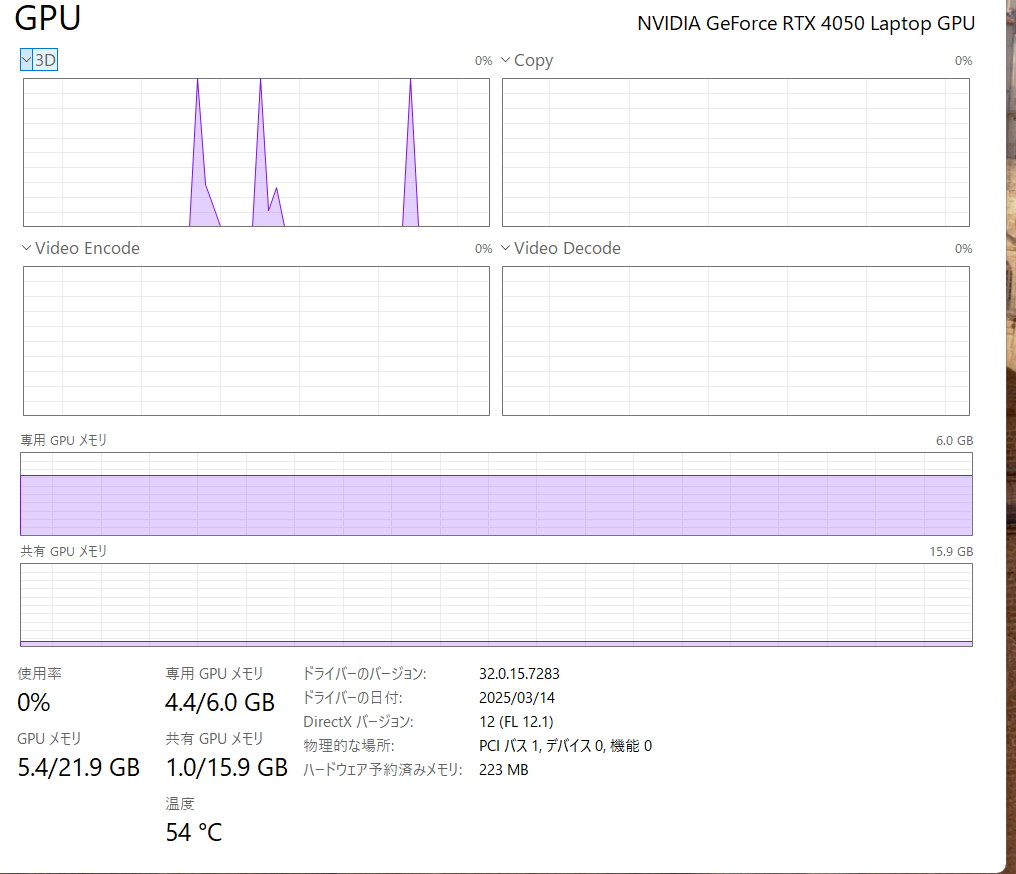
専用GPUメモリは使われているものの、これはLLMモデルのロードに使われているだけでほとんど処理には使用されていないことがわかりました。これはいけない。もっと100%に張り付いているはず。
CUDAコアを使ってもらうために以下の行動をとりました。
・NVIDIA Studio ドライバをダウンロードしてインストール
・CUDA Toolkitをダウンロードしてインストール
CUDA Toolkitはともかくグラフィックドライバがインストールされていないとは思っていなかったので盲点でした。なんでも確認はするものですね。弊社のセキュリティポリシーが厳しくインストールにもめちゃくちゃ苦労しましたが何とかなりました。さぁもう一度時間を計るぞ!
実行時間:約6.6時間
????????????????????????????????
ドライバをいれていないだけの単純な話かと思いきや面倒な話になってきました。もしかしたらソフト内でモデルをロードandアンロードを繰り返したりしているかもしれません。そうなると解決は面倒です( 私の管轄外なので )。
とりあえずGPUがきちんと処理に使われているかどうか確認してみます。

きちんと使われていますね。ノートなので排熱が上手くいってない可能性も考えましたが温度も65℃を超えることはほとんどなく、問題だとは感じませんでした。これは単に性能不足なのでしょうか?
しかし性能不足と断言するためにはこれ1を否定するだけの根拠が必要です。スペック表によるとAIの計算に使われるCUDAコア数は、T4とRTX4050は2,560基で同じ、RTX4050の方がクロック早いしメモリも早いので普通に考えたらRTX4050のAI処理能力はT4と同等か、それ以上の計算能力を持っているはず。性能不足と結論付けられる根拠はありません。
しかし一つ懸念点が見つかり、OllamaがRTX4050を公式にサポートしていないことがわかりました。 技術選定の時に把握しとけよ~なんで誰も知らんねん~
とりあえずOllamaがRTX4050できちんと動作するかどうかから確認することになりました。またこの時に一緒に考えてくれた方が私用のPC(RTX4060Ti)でOllamaがどう動くか試してくれることになりました。当然社内の試験データは使えないので「なぜ空は青いのか?」という簡単な質問をソフトウェアを介さずllama3モデルに対して行い、処理時間を比較することになりました。
$time1 = Measure-Command {
(Invoke-WebRequest -method POST -Body '{"model": "llama3", "keep_alive": 120 }' -uri http://localhost:11434/api/generate ).Content
}
$time2 = Measure-Command {
(Invoke-WebRequest -method POST -Body '{ "model": "llama3","prompt": "Why is the sky blue?", "options": { "temperature": 0.8, "top_k": 40, "top_p":0.9, "seed": 1 }, "stream": false}' -uri http://localhost:11434/api/generate ).Content
Get-Process
}
Write-Host "ロード時間 $($time1.TotalSeconds)s"
Write-Host "AI実行時間 $($time2.TotalSeconds)s"
llama3モデルに対してなぜ空が青いのか問うており、処理に必要な時間を計測しています。
実行時間の結果は
| Tesla T4 | RTX 4050 | RTX4060Ti |
|---|---|---|
| 10.353s | 25.713s | 34.536s |
となりました。これまた不可思議な結果ですね~。
確定したこととわからないことをまとめましょう。
ollamaに対する1要求あたりの生成時間がその10000レコード性能試験結果に反映されている。
→確定 LLMモデルの違いは関係ない。ネットワーク関係ない。ロード処理も関係ない。4050の型番が載ってなくサポート外ということも関係ない(目立って性能が落ちていたり期待しない挙動をしていないため)。
→未確定 OSの違い?、 GPUの設定? RTX4060TiよりRTX4050が早いのはなぜ?(GPUに加えCPU大事?)、 CPU単体の方が処理が早い(マジでなんで?)。
なぜT4の方が早く処理が終わるのかについても考えました。
有力な要因:
WDDMモードが非効率:WindowsのGPUはディスプレイ描画と共有のため、処理にレイテンシが発生(だとしてもここまで遅くはならんと思うが)
CPU/GPUの協調処理の最適化不足:OllamaはCPU依存部分が意外と多く、前処理がボトルネックに
VRAM帯域やL2キャッシュの違い:T4は計算特化で構成が最適化されている可能性あり
他プロセスの干渉:RTX 4050ではセキュリティソフトなどが常駐しリソースを使用中。特にGPUを使うソフトもバックグラウンドで動いていたので(ポリシーの都合上止められない)少々影響はあると見た。
llama.cppのT4向け最適化の可能性:内部的にT4世代で最適化されたコードパスを選んでいるかも?
ただ、初歩的な問題は捨てきれません。特に自分が訝しんでいたのはCPUのみで処理したときより処理時間が短縮されていない点です。GPUを使っているように見えるが実は使っていないんじゃないかと考えました。そこでOllama実行時にGPUを使っているかをログで確認することにしました。
1.このコマンドを実行
ollama run llama3
2.実行直後、コンソールに下記のような「バックエンド」情報が表示されるはず
llm_backend: using backend: cuda
または
llm_backend: using backend: cpu
llm_backend: using backend: directml
正常GPUを使っている場合、cudaが出力されるはず。
しかし表示が一瞬で消えてしまうように見えたので標準出力をファイルに保存するようにしました。
ollama run llama3 > llama3_output.txt 2>&1
結局文字化けしたりしてログをきちんと確認したわけではないですが、
・llama3_log.txt に llm_backend: の表示が出ていない
OllamaがCUDAを使っている場合、必ず llm_backend: using backend: cuda のような表示が初期化時に出る
・応答は返ってくるが、エンコードの影響で変な記号が出ている
これはPowerShellのロギングまわりの影響だが、それ以外の初期化ログが完全に出ていないことの方が重大
・処理が異常に遅い(T4より遅い)
GPUを使っていれば、RTX 4050や4060 Tiが T4 に負けるのはあり得ない
→ CPUで処理しているとしか考えられない
以上の3点から期待通りにGPUが働いていないと断定しました。
しかしGPUの使用率をリアルタイムでチェックしたところ、
nvidia-smi -l 1
これで1秒ごとにリアルタイム表示されるので、Ollama起動→入力→GPUが反応するか確認できます。その結果以下のことがわかりました。
・GPU-Util: 25%〜57% → 明らかに推論中でGPUが動いている(最初数秒しか出力していないので値は低め)
・Memory-Usage: 約4.8GB → llama3モデルがメモリにロードされている
・ollama.exe が GPUプロセス一覧に出現 → GPU使用中プロセスとして確認済み
以上の三点からGPUはOllamaによって使われていることが確定しました。
ならばすごく効率悪くGPUを使っている?空回りすることがあったりするのか?などと考えて寝ました。
そして目が覚めると事態は一気に解決します。
cuDNNがインストールされていないんですね。
cuDNN(CUDA Deep Neural Network library)はNVIDIA公式の深層学習向け高速化ライブラリでTensorコアを活用して畳み込み、行列積、正規化などを高速に実行できます。これがないと確かに悪影響ありそうですね。
これをいれて再度試してみました。
| RTX 4050 | RTX 4060Ti | AWS T4 |
|---|---|---|
| 25.7s → 14.5s | 34.536s → 6.8s | 10.353s |
まぁ妥当な結果でしょう。あとで聞いた話、RTX4060にはCUDA Toolkitも入ってなかったようです。性能がRTX 4050(CUDA Toolkitあり)>RTX 4060Ti(CUDA Toolkitなし)だったということになります。
Tesla T4よりRTX 4050が遅い原因はたぶんGPUメモリ不足です(もしかしたらT4はXeon系なのでそれも関係あるかもしれない)。 タスクマネージャを見ると共有GPUメモリが1.6GB使われているのでメインメモリとGPUメモリ間でスワップが発生しボトルネックになっています。VRAM6GBでは4.9GB程度のローカルLLMを動かすのはやはり厳しいようですね。
結論
10000レコードの性能試験は6.6時間→5.5時間と期待したほどではないものの短縮されました。VRAMが足りないので思ったより速くなりませんでした。
(追記)RTX5060Tiで試したら2.5時間になりました。やったね!まだ全然遅いが
ollamaを動かすとき、NVIDIAドライバをインストールすることで単にGPUの演算機能を利用できるようになるが、LLMの計算を効率的に行うため、CUDA Toolkitによる並列処理に加え、DNN(深層学習)用のライブラリを追加する必要があった。
ローカルLLMの実行速度に大きく影響を与えるのはVRAM容量である。生成AIに特化したPCを組むのであれば1枚の高性能GPUより2枚のそこそこGPUでメモリ2倍の方が良いと思われる(消費電力は考えないものとする)。
AWSのT4サーバーは「AI推論のためにハードウェアごと最適化された環境」だから、見かけのGPUスペック以上に速かった。ハードウェア構成の部分も案外無視できないというわけですね。
CPUだけでも案外早く終わったのは…………なんでだろうね?
おまけ
AMDのRadeon系では、AMDドライバに加え、ROCmライブラリのインストールが必要。
ただし、Windowsの場合に限っては、PytorchがAMDのROCmをサポートしていないようなので、MicrosoftのDirectMLライブラリによる演算となり、本来の性能があまり出せないとのことで要注意。
最後に
必要なドライバ、ライブラリは本当に全部そろっていますか?