インデックス(索引)とは
処理を高速化させるデータ構造のことです。
よく出される例として、本を探すときに索引があると全てのページを探さなくても、索引を目印にして探すページを減らすことができるから早く見つけられるよねって話があります。
実際には、メモリに保持される容量がテーブル全体ではなく、インデックスのみになるため処理効率が上がっています。
注意点
処理が早くなるならとりあえず全部インデックスをつけとけ!となりそうですが、幾つか注意点があります。
1.データ追加時の処理が重くなる
インデックスを設定した場合、通常のテーブルとは別にインデックスに値を保持するので、データ追加時に処理が重くなります。
2.データ量が少ない場合やindexのつけ方が悪い場合にはindexは使用されない
先ほどの本の例で考えてみてもわかるのですが、10ページしかない本に対して索引をつけてもあまり意味はありませんよね。
また、インデックスがあるからと言ってインデックスが使用されるとは限りません。
インデックスを使用した場合と使用しなかった場合を比較して、処理効率が早い方が実際に使用されるので、あまり効率的でないインデックスの張り方をしてしまうと実際に内部ではインデックスは使用していないということが起きます。
インデックスの構造の種類
インデックスの内部構造にはいくつか種類が存在します。
(wikipedia参照)
・B木(B-tree)
・ハッシュ索引
・ビットマップ索引
・多次元索引
・転置インデックス
全ての構造について理解はできていませんが、それぞれ向き不向きがあるので気になる人は調べてみてください。(今後勉強してみます)
一番メジャーなB木については下でまとめます。
部分インデックス
条件に一致する行のみをインデックスとして設定することができます。
問い合わせされることのない値をインデックスから取り除くことができるので、設定できる場合には設定した方が処理効率は上がりそうです。
複合インデックス
複数のカラムを組み合わせて一つのインデックスとすることができます。
姓と名でカラムが分かれている場合で検索される場合に姓名で検索されることが多い場合などに、姓名のカラムを合わせて一つのインデックスとすることで、処理効率が向上します。
B木(B-tree)
B木もデータ構造の一つで、wikipediaによると「多分岐の平衡木(バランス木)」であるそうです。
多分岐と平衡木(バランス木)に分けて考えて見ると良さそうです。
多分岐
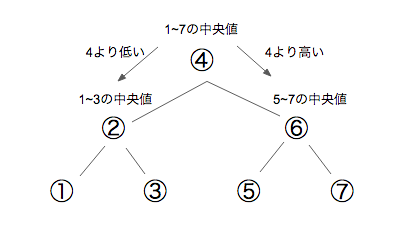
1~7の中からある数字を探すときどのように探すと効率が良いか考えてみましょう。
7つを手当たり次第に見ていく場合、7回確認をする必要があります。(インデックスがない場合にはこのような感じです)
しかし実際には1~700万の中から探さなければならなかったりするので、700万回確認をするのは処理が大変ですね。
処理効率を上げるために条件で分岐させてみましょう。
わかりやすいのは一番真ん中の値(中央値)である4を基準にして、それより高いか低いかで分けて考えると、すべての値を確認しなくてすみそうです。
また、4より小さい場合考えられる値は1,2,3なので、ここでも中央値の2を基準にそれより大きいか小さいかで分岐させることができます。
しかし値が700万あった場合に中央値の350万をとって高いか低いかの判定をしていると、末端まで行くのに処理回数がかなり多くなってしまいます。
そのため最初に判定する数字(上記では4)を一つではなく、複数にすることにより確認する回数を減らしてみましょう。
1~200なら100の部分を、201~400なら300の部分を確認するようになっています。
(実際には2番目の50,150の部分も2つ以上に分岐されます)
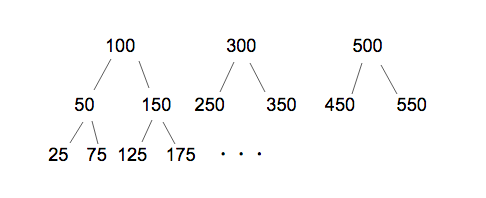
このようにいくつにも分岐させて値を確認する構造が多分岐です。
平衡木(バランス木)
上記のようなツリー構造のうち、末端構造までの深さが等しくなるように設計された構造のことを平衡木(バランス木)と言います。
末端構造までの深さが等しくなる
ここが理解できれば問題はなさそうです。
「末端構造までの深さ」とは最初に判定をする値から、これ以上分岐できない値までの深さのことです。
また、「深さが等しくなる」とは各分岐先の深さのことです。
下記の場合2つに分岐され、両方が最初に判定をする値から見て2段階深くなっているため「末端構造までの深さが等しくなる」状態です。
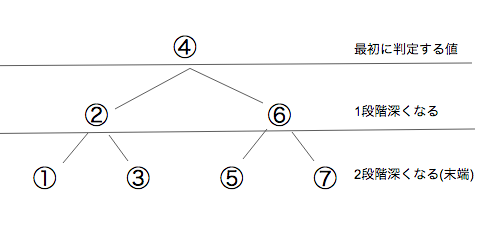
仮に7がさらに分岐していて、3段階深くなっていたとしたら「末端構造までの深さが等しくなる」状態ではなくなります。
まとめ
実際には判定をする数字が増えるごとにB木がどんどん大きくなっていくような感じらしいのですが、最初にそれを読んだ時に意味がわからなかったので、それを読む前に知っておきたい概念をまとめました。