完成形
延々とHTMLを出力し続けローディングが終わらないページを作成します。
なぜこんなものを作ったか?
同様なページをスクレイピングしたかったので、そのテスト用に。
スクレイピング方法はこの記事に書きました。
無限スクロールとは違うの?
無限スクロールページの実装はjavascriptで行うことが多く、ソースは有限(終わりがある)であるため、curlやrequests.getでソースを取得できます。対して今回紹介する構成はソースのローディングが終わらないため、いつものcurlやrequests.getではタイムアウトとなってしまいます。
環境
- python3.7.4
コード
inf_page.py
import sys
import http.server
from http.server import SimpleHTTPRequestHandler
from http.server import BaseHTTPRequestHandler
from time import sleep
class infiniteHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.send_header('Transfer-Encodeing', 'chunked')
self.end_headers()
inc = 0
while(True):
try:
self.wfile.write(f"<p>Hello World ! {inc}</p>".encode("ascii"))
self.wfile.flush()
print("wrote")
sleep(2)
inc += 1
except:
break
return
server_address = ('127.0.0.1', 8000)
infiniteHandler.protocol_version = "HTTP/1.1"
httpd = http.server.HTTPServer(server_address, infiniteHandler)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
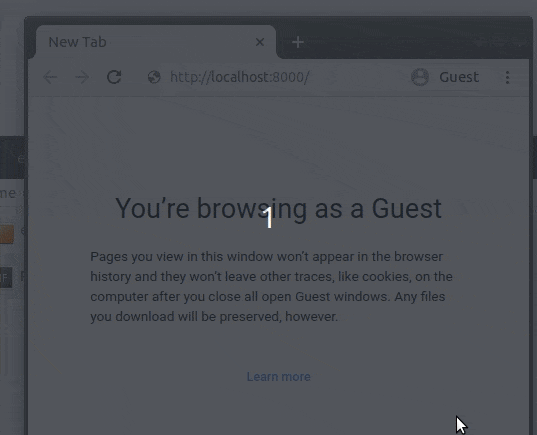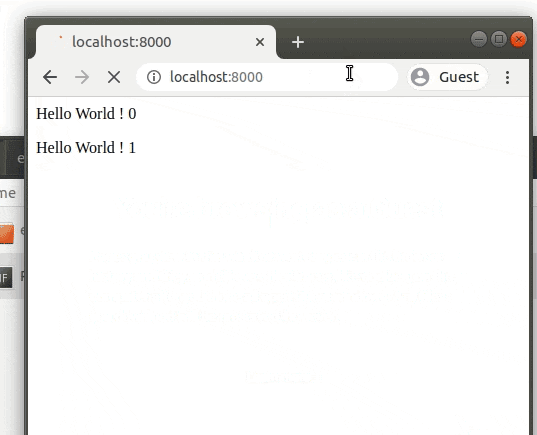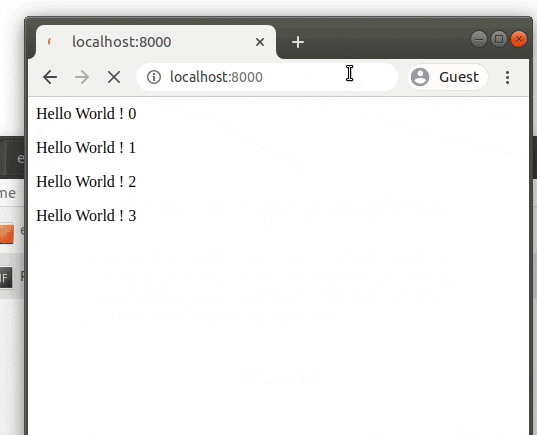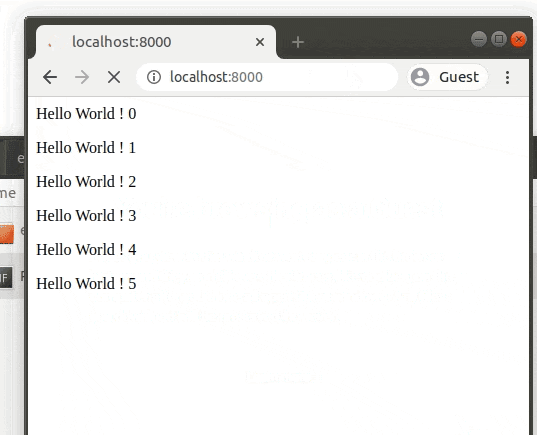
動作を見る
手元のブラウザでhttp://localhost:8000を閲覧してください。
以上。
スクレイピング方法はこの記事に書きました。