OSは最近入れたUbuntu 12.04 LTS。
メモリも最近増やした6GB
参考にさせてもらったサイト
https://gist.github.com/cshen/6492856
Pylearn2のダウンロード
公式に書いてあるようにgitから持ってくる。
git clone git://github.com/lisa-lab/pylearn2.git
次に使うデータのパスを通す
export PYLEARN2_DATA_PATH=/data/lisa/data
export PYLEARN2_VIEWER_COMMAND="eog --new-instance" # 書いておくと後でいいことがある。
インストール
まずはPylearn2を動かすのに必要なライブラリをインストールする。
sudo apt-get install python-pip
sudo apt-get install python-numpy
sudo apt-get install python-scipy
sudo apt-get install python-setuptools
sudo apt-get install python-matplotlib
sudo pip install --upgrade --no-deps git+git://github.com/Theano/Theano.git
# sudo pip install theanoでは駄目 理由は後で解説
次にダウンロードしたPylearn2をインストール
# pylearn2/setup.pyを使う
python setup.py build
sudo python setup.py install
「import pylearn2」で成功したかテスト
import pylearn2
チュートリアルを動かす
ステップ1
公式のチュートリアルを見て動かす。
# pylearn2/pylearn2/scripts/tutorials/grbm_smd/のmake_dataset.pyを使う
python make_dataset.py
すると、エラーが出た。data_batch_1がないとのこと。これって自動でダウンロードしてくれるんじゃないんだ。
username@ubuntu:~/pylearn2/pylearn2/scripts/tutorials/grbm_smd$ python make_dataset.py
Traceback (most recent call last):
File "make_dataset.py", line 29, in <module>
train = cifar10.CIFAR10(which_set="train", one_hot=True)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/cifar10.py", line 67, in __init__
data = CIFAR10._unpickle(fname)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/cifar10.py", line 249, in _unpickle
raise IOError(fname+" was not found. You probably need to download "
IOError: /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_1 was not found. You probably need to download the CIFAR-10 dataset by using the download script in pylearn2/scripts/download_cifar10.sh or manually from http://www.cs.utoronto.ca/~kriz/cifar.html
username@ubuntu:~/pylearn2/pylearn2/scripts/tutorials/grbm_smd$
このエラーを解決するためにデータセットをダウンロードする
このページの「CIFAR-10 python version」をダウンロード
/data/lisa/data/cifar10/cifar-10-batches-py/...みたいになるよう展開する
これでエラーが消える。make_dataset.pyを続ける。
するとまたエラーが出た
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_1
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_2
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_3
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_4
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_5
loading file /data/lisa/data/cifar10/cifar-10-batches-py/test_batch
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:846: UserWarning: This ZCA preprocessor class is known to yield very different results on different platforms. If you plan to conduct experiments with this preprocessing on multiple machines, it is probably a good idea to do the preprocessing on a single machine and copy the preprocessed datasets to the others, rather than preprocessing the data independently in each location.
warnings.warn("This ZCA preprocessor class is known to yield very "
computing zca of a (150000, 192) matrix
cov estimate took 9.41569 seconds
eigh() took 0.0209 seconds
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:923: UserWarning: Implicitly converting mat from dtype=float64 to float32 for gpu
warnings.warn('Implicitly converting mat from dtype=%s to float32 for gpu' % mat.dtype)
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:925: UserWarning: Implicitly converting diag from dtype=float64 to float32 for gpu
warnings.warn('Implicitly converting diag from dtype=%s to float32 for gpu' % diags.dtype)
Traceback (most recent call last):
File "make_dataset.py", line 70, in <module>
serial.save(train_pkl_path, train)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/utils/serial.py", line 223, in save
_save(filepath, obj)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/utils/serial.py", line 293, in _save
raise IOError("permission error creating %s" % filepath)
IOError: permission error creating /usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/scripts/tutorials/grbm_smd/cifar10_preprocessed_train.pkl
今度は権限がないから「cifar10_preprocessed_train.pkl」が作れないとのこと。だけどこのまま「sudo python make_dataset.py」としてもPYLEARN2_DATA_PATHが取得できなくなる。なので強引だけどmake_dataset.pyにこう書く。他に良い方法ないかなー
# pylearn2 tutorial example: make_dataset.py by Ian Goodfellow
# See README before reading this file
#
#
# This script creates a preprocessed version of a dataset using pylearn2.
# It's not necessary to save preprocessed versions of your dataset to
# disk but this is an instructive example, because later we can show
# how to load your custom dataset in a yaml file.
#
# This is also a common use case because often you will want to preprocess
# your data once and then train several models on the preprocessed data.
import os.path
import pylearn2
# We'll need the serial module to save the dataset
from pylearn2.utils import serial
# Our raw dataset will be the CIFAR10 image dataset
from pylearn2.datasets import cifar10
# We'll need the preprocessing module to preprocess the dataset
from pylearn2.datasets import preprocessing
if __name__ == "__main__":
# Our raw training set is 32x32 color images
# TODO: the one_hot=True is only necessary because one_hot=False is
# broken, remove it after one_hot=False is fixed.
# 追加したのは下の2行
import os
os.environ['PYLEARN2_DATA_PATH'] = "/data/lisa/data"
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_1
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_2
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_3
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_4
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_5
loading file /data/lisa/data/cifar10/cifar-10-batches-py/test_batch
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:846: UserWarning: This ZCA preprocessor class is known to yield very different results on different platforms. If you plan to conduct experiments with this preprocessing on multiple machines, it is probably a good idea to do the preprocessing on a single machine and copy the preprocessed datasets to the others, rather than preprocessing the data independently in each location.
warnings.warn("This ZCA preprocessor class is known to yield very "
computing zca of a (150000, 192) matrix
cov estimate took 9.5492 seconds
eigh() took 0.0213549 seconds
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:923: UserWarning: Implicitly converting mat from dtype=float64 to float32 for gpu
warnings.warn('Implicitly converting mat from dtype=%s to float32 for gpu' % mat.dtype)
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:925: UserWarning: Implicitly converting diag from dtype=float64 to float32 for gpu
warnings.warn('Implicitly converting diag from dtype=%s to float32 for gpu' % diags.dtype)
これでインストール完了
後、ちょくちょくUserWarningって出てくるけど、それはあんまり問題無いらしい。
これでステップ1は終了だが、もし「sudo pip install theano」と書いているとエラーになる
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_1
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_2
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_3
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_4
loading file /data/lisa/data/cifar10/cifar-10-batches-py/data_batch_5
loading file /data/lisa/data/cifar10/cifar-10-batches-py/test_batch
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py:846: UserWarning: This ZCA preprocessor class is known to yield very different results on different platforms. If you plan to conduct experiments with this preprocessing on multiple machines, it is probably a good idea to do the preprocessing on a single machine and copy the preprocessed datasets to the others, rather than preprocessing the data independently in each location.
warnings.warn("This ZCA preprocessor class is known to yield very "
WARNING (theano.tensor.blas): We did not found a dynamic library into the library_dir of the library we use for blas. If you use ATLAS, make sure to compile it with dynamics library.
===============================
00001 #include <Python.h>
00002 #include <iostream>
00003 #include <math.h>
00004 #include <numpy/arrayobject.h>
00005 #include <numpy/arrayscalars.h>
00006 #include <iostream>
00007 #include <time.h>
00008 #include <sys/time.h>
00009 //////////////////////
00010 //// Support Code
00011 //////////////////////
...
01009 PyMODINIT_FUNC init2cefc1167b7fca6a2ad00f367f828a17(void){
01010 import_array();
01011 (void) Py_InitModule("2cefc1167b7fca6a2ad00f367f828a17", MyMethods);
01012 }
01013
===============================
Problem occurred during compilation with the command line below:
g++ -shared -g -O3 -fno-math-errno -Wno-unused-label -Wno-unused-variable -Wno-write-strings -Wl,-rpath,/usr/lib -D NPY_NO_DEPRECATED_API=NPY_1_7_API_VERSION -D NPY_ARRAY_ENSURECOPY=NPY_ENSURECOPY -D NPY_ARRAY_ALIGNED=NPY_ALIGNED -D NPY_ARRAY_WRITEABLE=NPY_WRITEABLE -D NPY_ARRAY_UPDATE_ALL=NPY_UPDATE_ALL -D NPY_ARRAY_C_CONTIGUOUS=NPY_C_CONTIGUOUS -D NPY_ARRAY_F_CONTIGUOUS=NPY_F_CONTIGUOUS -m64 -fPIC -I/usr/lib/python2.7/dist-packages/numpy/core/include -I/usr/include/python2.7 -o /home/username/.theano/compiledir_Linux-3.2.0-48-generic-x86_64-with-Ubuntu-12.04-precise-x86_64-2.7.3-64/tmpQvg112/2cefc1167b7fca6a2ad00f367f828a17.so /home/username/.theano/compiledir_Linux-3.2.0-48-generic-x86_64-with-Ubuntu-12.04-precise-x86_64-2.7.3-64/tmpQvg112/mod.cpp -L/usr/lib -lpython2.7 -lblas
/usr/bin/ld: cannot find -lblas
collect2: ld はステータス 1 で終了しました
Traceback (most recent call last):
File "make_dataset.py", line 58, in <module>
train.apply_preprocessor(preprocessor=pipeline, can_fit=True)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/dense_design_matrix.py", line 552, in apply_preprocessor
preprocessor.apply(self, can_fit)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py", line 141, in apply
item.apply(dataset, can_fit)
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/datasets/preprocessing.py", line 1082, in apply
new_x_symbol)
File "/usr/local/lib/python2.7/dist-packages/theano/compile/function.py", line 223, in function
profile=profile)
File "/usr/local/lib/python2.7/dist-packages/theano/compile/pfunc.py", line 512, in pfunc
on_unused_input=on_unused_input)
File "/usr/local/lib/python2.7/dist-packages/theano/compile/function_module.py", line 1312, in orig_function
defaults)
File "/usr/local/lib/python2.7/dist-packages/theano/compile/function_module.py", line 1181, in create
_fn, _i, _o = self.linker.make_thunk(input_storage=input_storage_lists)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/link.py", line 434, in make_thunk
output_storage=output_storage)[:3]
File "/usr/local/lib/python2.7/dist-packages/theano/gof/vm.py", line 847, in make_all
no_recycling))
File "/usr/local/lib/python2.7/dist-packages/theano/gof/op.py", line 606, in make_thunk
output_storage=node_output_storage)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cc.py", line 948, in make_thunk
keep_lock=keep_lock)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cc.py", line 891, in __compile__
keep_lock=keep_lock)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cc.py", line 1322, in cthunk_factory
key=key, fn=self.compile_cmodule_by_step, keep_lock=keep_lock)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cmodule.py", line 996, in module_from_key
module = next(compile_steps)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cc.py", line 1237, in compile_cmodule_by_step
preargs=preargs)
File "/usr/local/lib/python2.7/dist-packages/theano/gof/cmodule.py", line 1971, in compile_str
(status, compile_stderr.replace('\n', '. ')))
Exception: ('The following error happened while compiling the node', Dot22(Elemwise{sub,no_inplace}.0, P_), '\n', 'Compilation failed (return status=1): /usr/bin/ld: cannot find -lblas. collect2: ld \xe3\x81\xaf\xe3\x82\xb9\xe3\x83\x86\xe3\x83\xbc\xe3\x82\xbf\xe3\x82\xb9 1 \xe3\x81\xa7\xe7\xb5\x82\xe4\xba\x86\xe3\x81\x97\xe3\x81\xbe\xe3\x81\x97\xe3\x81\x9f. ', '[Dot22(<TensorType(float64, matrix)>, P_)]')
ただメッセージを見ても何が悪いのか分からない
ここは調べてみる。するとこんなページが見つかった
# 念のためアンインストールしてから
pip uninstall theano
pip install --upgrade --no-deps git+git://github.com/Theano/Theano.git
するとエラーが消えた。
ステップ2 解析?してみる
今度はpylearn2/scriptsにパスを通す。
export PATH=$PATH:~/pylearn2/pylearn2/scripts
# ディレクトリはpylearn2/pylearn2/scripts/tutorials/grbm_smd/のまま
# この操作は結構重かった
train.py cifar_grbm_smd.yaml
実行するとまたエラーになる
Exception: Couldn't open 'cifar10_preprocessed_train.pkl' due to: <type 'exceptions.IOError'>, [Errno 2] No such file or directory: 'cifar10_preprocessed_train.pkl'. Orig traceback:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/utils/serial.py", line 111, in load
with open(filepath, 'rb') as f:
IOError: [Errno 2] No such file or directory: 'cifar10_preprocessed_train.pkl'
cifar10_preprocessed_train.pklが見つからない。このファイルは
「/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/scripts/tutorials/grbm_smd」
にある。これには迷った
このファイルをpylearn2/pylearn2/scripts/tutorials/grbm_smd/に移動させる。
今渡こそ開始
username@ubuntu:~/pylearn2/pylearn2/scripts/tutorials/grbm_smd$ train.py cifar_grbm_smd.yaml
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/costs/ebm_estimation.py:14: UserWarning: Cost changing the recursion limit.
warnings.warn("Cost changing the recursion limit.")
/usr/local/lib/python2.7/dist-packages/theano/sandbox/rng_mrg.py:772: UserWarning: MRG_RandomStreams Can't determine #streams from size ((Elemwise{add,no_inplace}.0,)), guessing 60*256
nstreams = self.n_streams(size)
/usr/local/lib/python2.7/dist-packages/theano/sandbox/rng_mrg.py:772: UserWarning: MRG_RandomStreams Can't determine #streams from size (Shape.0), guessing 60*256
nstreams = self.n_streams(size)
Parameter and initial learning rate summary:
W: 0.1
bias_vis: 0.1
bias_hid: 0.1
sigma_driver: 0.1
Compiling sgd_update...
Compiling sgd_update done. Time elapsed: 3.526216 seconds
compiling begin_record_entry...
compiling begin_record_entry done. Time elapsed: 0.046751 seconds
Monitored channels:
bias_hid_max
bias_hid_mean
bias_hid_min
bias_vis_max
bias_vis_mean
bias_vis_min
h_max
h_mean
h_min
learning_rate
objective
reconstruction_error
total_seconds_last_epoch
training_seconds_this_epoch
Compiling accum...
graph size: 83
Compiling accum done. Time elapsed: 1.150050 seconds
Monitoring step:
Epochs seen: 0
Batches seen: 0
Examples seen: 0
bias_hid_max: -2.0
bias_hid_mean: -2.0
bias_hid_min: -2.0
bias_vis_max: 0.0
bias_vis_mean: 0.0
bias_vis_min: 0.0
h_max: 0.00165399100786
h_mean: 1.88760476563e-05
h_min: 9.81922087086e-07
learning_rate: 0.1
objective: 15.1039446295
reconstruction_error: 74.2614943235
total_seconds_last_epoch: 0.0
training_seconds_this_epoch: 0.0
/usr/local/lib/python2.7/dist-packages/pylearn2-0.1dev-py2.7.egg/pylearn2/training_algorithms/sgd.py:545: UserWarning: The channel that has been chosen for monitoring is: objective.
str(self.channel_name) + '.')
Time this epoch: 0:01:50.317007
Monitoring step:
Epochs seen: 1
Batches seen: 30000
Examples seen: 150000
bias_hid_max: -0.272866563291
bias_hid_mean: -1.75659325702
bias_hid_min: -2.51777410634
bias_vis_max: 0.153457422901
bias_vis_mean: 0.00176315332845
bias_vis_min: -0.237732403732
h_max: 0.610667377089
h_mean: 0.0563938573299
h_min: 9.35136301756e-06
learning_rate: 0.1
objective: 3.7911270731
reconstruction_error: 29.6729947003
total_seconds_last_epoch: 0.0
training_seconds_this_epoch: 110.317007
monitoring channel is objective
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.110872 seconds
Time this epoch: 0:02:04.662160
Monitoring step:
Epochs seen: 2
Batches seen: 60000
Examples seen: 300000
bias_hid_max: -0.246065235441
bias_hid_mean: -2.01199273594
bias_hid_min: -2.80764297057
bias_vis_max: 0.18772020839
bias_vis_mean: -0.000339412708619
bias_vis_min: -0.187033129545
h_max: 0.598067247
h_mean: 0.0492958969179
h_min: 6.29718290456e-06
learning_rate: 0.1
objective: 3.52647040247
reconstruction_error: 29.4993278159
total_seconds_last_epoch: 110.48161
training_seconds_this_epoch: 124.66216
monitoring channel is objective
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.116746 seconds
Time this epoch: 0:02:12.847753
Monitoring step:
Epochs seen: 3
Batches seen: 90000
Examples seen: 450000
bias_hid_max: -0.217807592013
bias_hid_mean: -2.12349417946
bias_hid_min: -3.06315685204
bias_vis_max: 0.209034461753
bias_vis_mean: 0.000870083812334
bias_vis_min: -0.179624583448
h_max: 0.576599923191
h_mean: 0.0469544715944
h_min: 4.2071605178e-06
learning_rate: 0.1
objective: 3.37623778883
reconstruction_error: 29.2305192806
total_seconds_last_epoch: 124.834175
training_seconds_this_epoch: 132.847753
monitoring channel is objective
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.116925 seconds
Time this epoch: 0:02:17.842619
Monitoring step:
Epochs seen: 4
Batches seen: 120000
Examples seen: 600000
bias_hid_max: -0.248029915286
bias_hid_mean: -2.1915198152
bias_hid_min: -3.22054069844
bias_vis_max: 0.262918509995
bias_vis_mean: 0.000191742870546
bias_vis_min: -0.173778387514
h_max: 0.554194658923
h_mean: 0.0458009309099
h_min: 3.77548228177e-06
learning_rate: 0.1
objective: 3.26947615424
reconstruction_error: 29.8005568223
total_seconds_last_epoch: 133.019077
training_seconds_this_epoch: 137.842619
monitoring channel is objective
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.118880 seconds
Time this epoch: 0:02:34.845050
Monitoring step:
Epochs seen: 5
Batches seen: 150000
Examples seen: 750000
bias_hid_max: -0.282424217896
bias_hid_mean: -2.23634235523
bias_hid_min: -3.37966150939
bias_vis_max: 0.227035163956
bias_vis_mean: -0.000246034347711
bias_vis_min: -0.160823731668
h_max: 0.552645148762
h_mean: 0.0452473206913
h_min: 2.83635672249e-06
learning_rate: 0.1
objective: 3.30908132011
reconstruction_error: 29.058447262
total_seconds_last_epoch: 138.016547
training_seconds_this_epoch: 154.84505
monitoring channel is objective
shrinking learning rate to 0.099000
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.134288 seconds
Saving to cifar_grbm_smd.pkl...
Saving to cifar_grbm_smd.pkl done. Time elapsed: 0.159221 seconds
username@ubuntu:~/pylearn2/pylearn2/scripts/tutorials/grbm_smd$
ステップ3 画像にして見る
ディレクトリはそのままで
# ここで
# export PYLEARN2_VIEWER_COMMAND="eog --new-instance"
# がなかったらエラーになる
show_weights.py cifar_grbm_smd.pkl
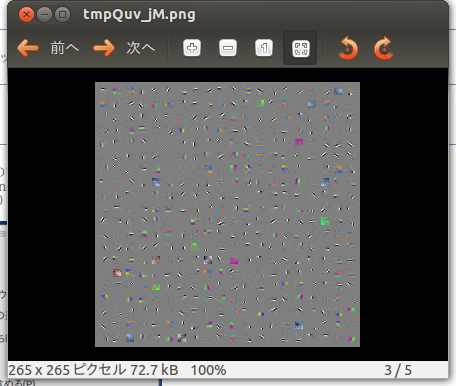
これでいいのかな?
Windowsでのインストール
他のライブラリはインストール出来たけど
theanoが無理だった
出来ないことはないと思うけど、linuxを使った方がいいと思う。
Mac
持ってないので分からない。