はじめに
こんにちは!
株式会社BTMの畑です。
今回は小さな「Mac mini」でローカルLLMを動かしてみた話です。
LLMとは
- 「Large Language Model(大規模言語モデル)」とは、膨大なテキストを学習し、人間のように文章を理解・生成できるAIのこと
- 質問応答、要約、翻訳、プログラミングなど、幅広い言語処理に対応
- 「ChatGPT」や「Gemini」などもその一種で、対話形式で情報提供や作業支援が可能
筆者はAIやLLMの専門家ではないので、不確かな情報が含まれる可能性があります。
・「Mac mini」でローカルLLMが動作するのか気になる人
・「LM Studio」やローカルLLMが気になっている人
に向けた内容となっています。
AIは便利
コードの作成からコードのレビュー、さらには環境構築なんかもAIがやってくれて、設計や要件定義だって手伝ってくれる。
雑談にものってくれて、寒いジョークも言ってくれる。
数々の創作物で書かれてきたAIが現実のものになりつつあるのを見ていると、SFの世界が目の前に来ているようでワクワクします!
AIは怖い
一方で、AIを適切に活用しないと、使用者の認識の甘さから情報が流出し、重大なインシデントにつながるおそれもあります。そのため、使用者にはより高いリテラシーや判断力が求められていると感じます。
特に昨今最も利用されているであろう「ChatGPT」や「Copilot」などの生成AIサービスは、使用者の入力した内容を一度クラウド(外部のサーバ)に送信して、クラウド上で処理を行い、処理の結果を使用者に返すといった方法が一般的です。
そのため、会社の重要機密や個人情報を含んだデータなどは外部に送信できず、中々AI活用できないといった事例もあると思います。
自分だけのAI
そこで、ローカル環境でLLMを動作させて、自分だけ(もしくは自社の中だけ)で動くAI、つまりローカルLLMを活用してみよう、というのが今回の内容です。
ローカルLLMとは
- 「ローカルLLM」とは、大規模言語モデルをクラウドではなく、手元のPCやサーバーなどローカル環境で動かすこと
- インターネット接続不要で動作し、セキュリティやプライバシーの観点での利点がある
- 軽量なモデルや専用ツール(「LM Studio」や「llama.cpp」など)を使うことで、一般のPCでも利用可能
Mac mini
今回、ローカルLLMを動作させるPCは「Mac mini」です。
文庫本3冊分くらいしかない小さなPCで何ができるのかを見ていきます。
右隣はロジクールの「ERGO M575」なので、トラックボールマウスよりちょっと大きいくらいのサイズです。(小さい!)

使用したMac miniのスペック
- CPU:Apple M4 Pro(12コアCPU,16コアGPU)
- メモリ:64GB
- SSD:1TB
今回やってみること
ローカルLLMを手早く動かすための「LM Studio」のインストールから、ローカルLLMの動作確認、ローカルLLMにサポートしてもらいながらチャットスタイルでやり取りするアプリのデモ開発までをやってみます。
準備
LM Studioのインストール
まずは「LM Studio」を公式ページからダウンロードしてインストールします。
※本記事ではVersion 0.3.16 を利用しています
インストールが完了し、「LM Studio」を立ち上げました。
「ローカル(あなたのPC上)で動くから、プライベートでセキュアですよー」と言っていますね。
「Get your first LLM」をクリックして、早速見ていきましょう。
(かわいいアイコンがお出迎え)
設定確認
早速動かしていきたいところですが、先に右下の歯車アイコンをクリックして設定を確認しておきます。
言語設定に「日本語(Beta)」がありましたので、日本語にしておきます。
左側の「Hardware」をクリックし、メモリなどが正しく読み込まれていることを確認します。
尚、LLMを動かし始めると「Resource Monitor」に今どれだけメモリやCPUを利用しているかがリアルタイムで表示されます。
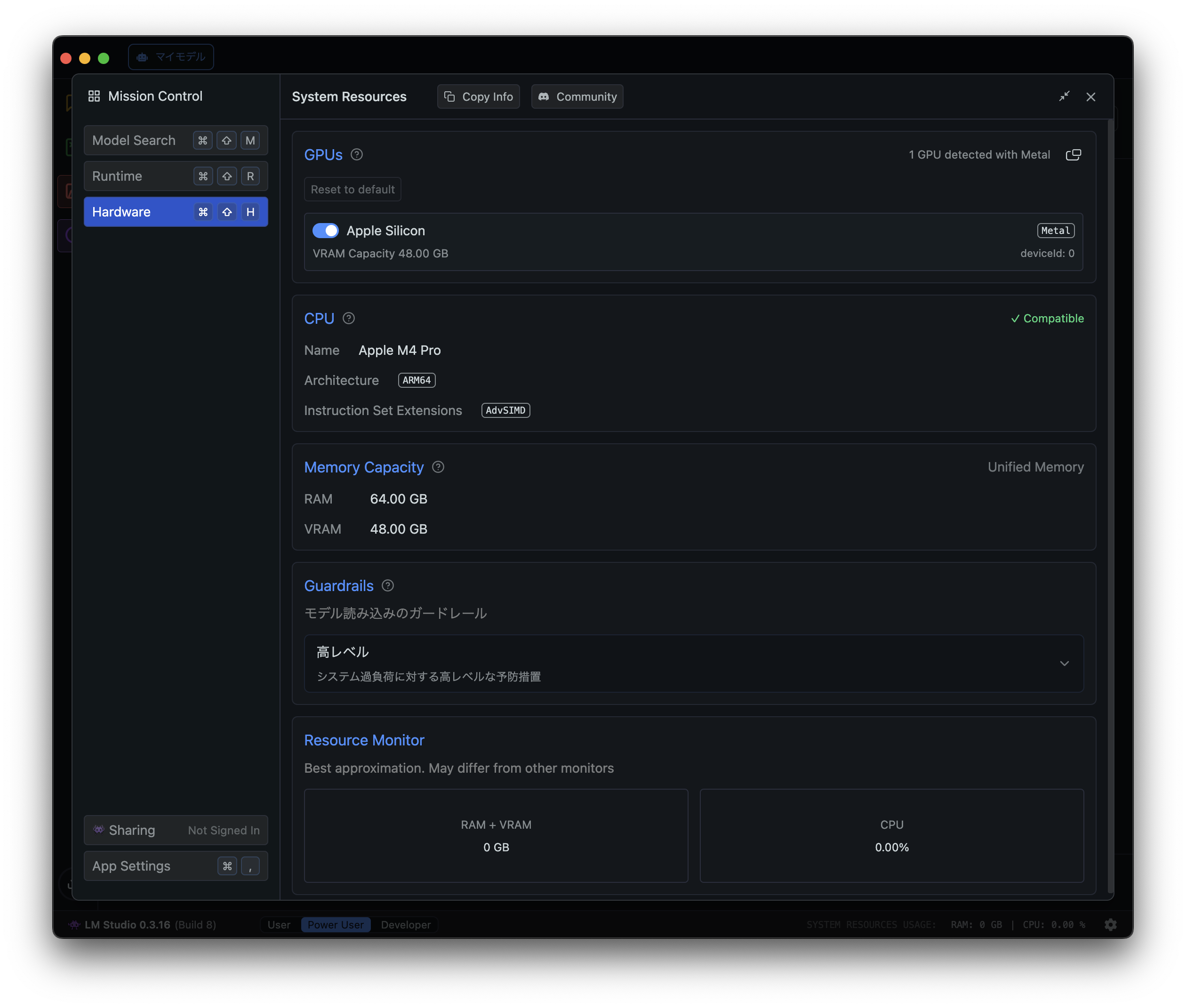
問題なく読み込まれていましたので、LLMのモデルを選択していきます。
LLMのダウンロード
左側の「Model Search」をクリックすると、LLMのモデルを検索する画面が表示されます。
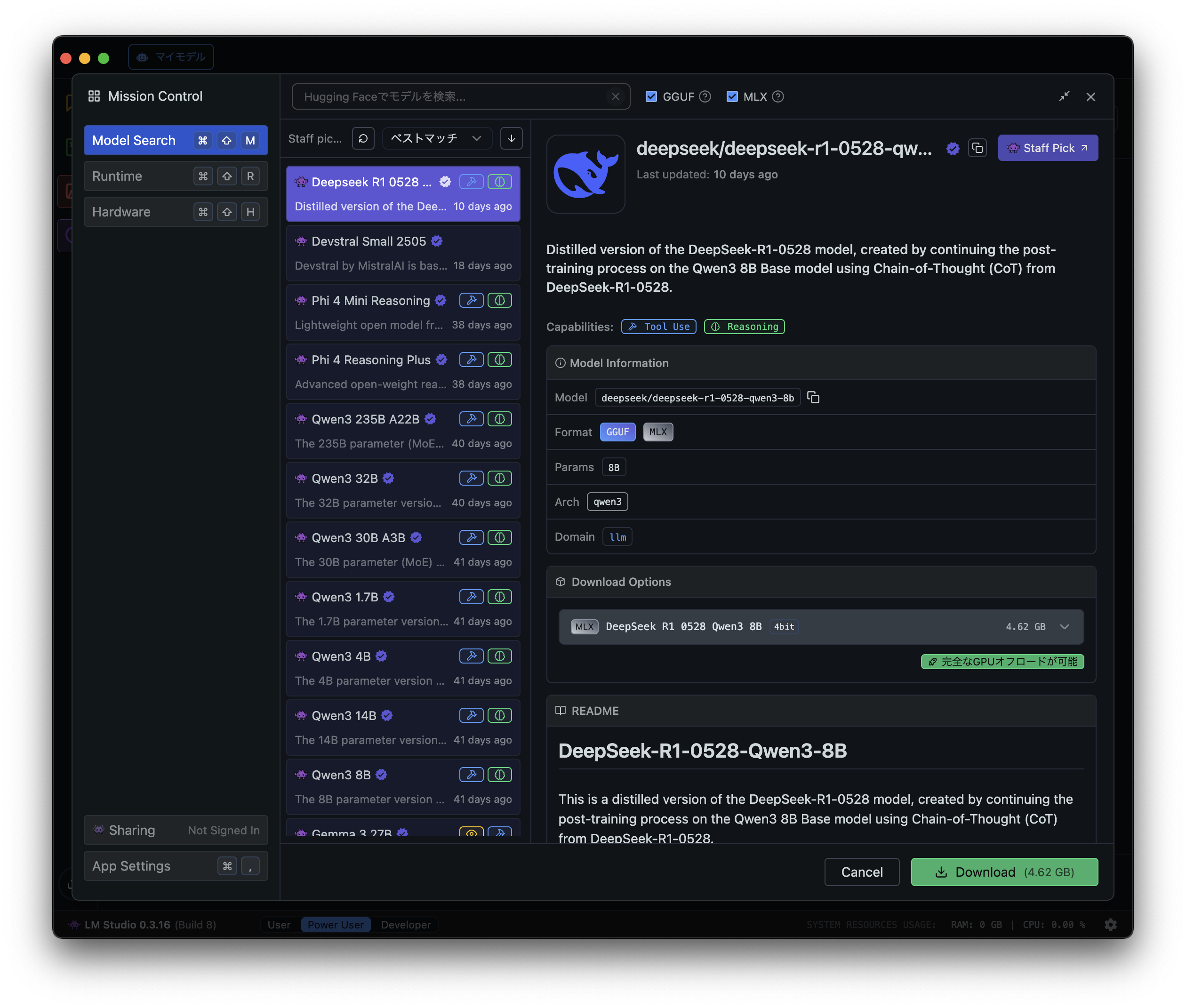
Llama
まずはMeta社が開発している「Llama」を使用してみます。
Llama(ラマ)とは
- Llama(ラマ)はMeta(旧Facebook)が開発したオープンソースのLLM
- 自然言語処理やテキスト生成の精度が高く、対話や翻訳、コード生成などさまざまなタスクに対応できる
- 特に「Llama 3」は高性能とオープンソースという特性から注目されている
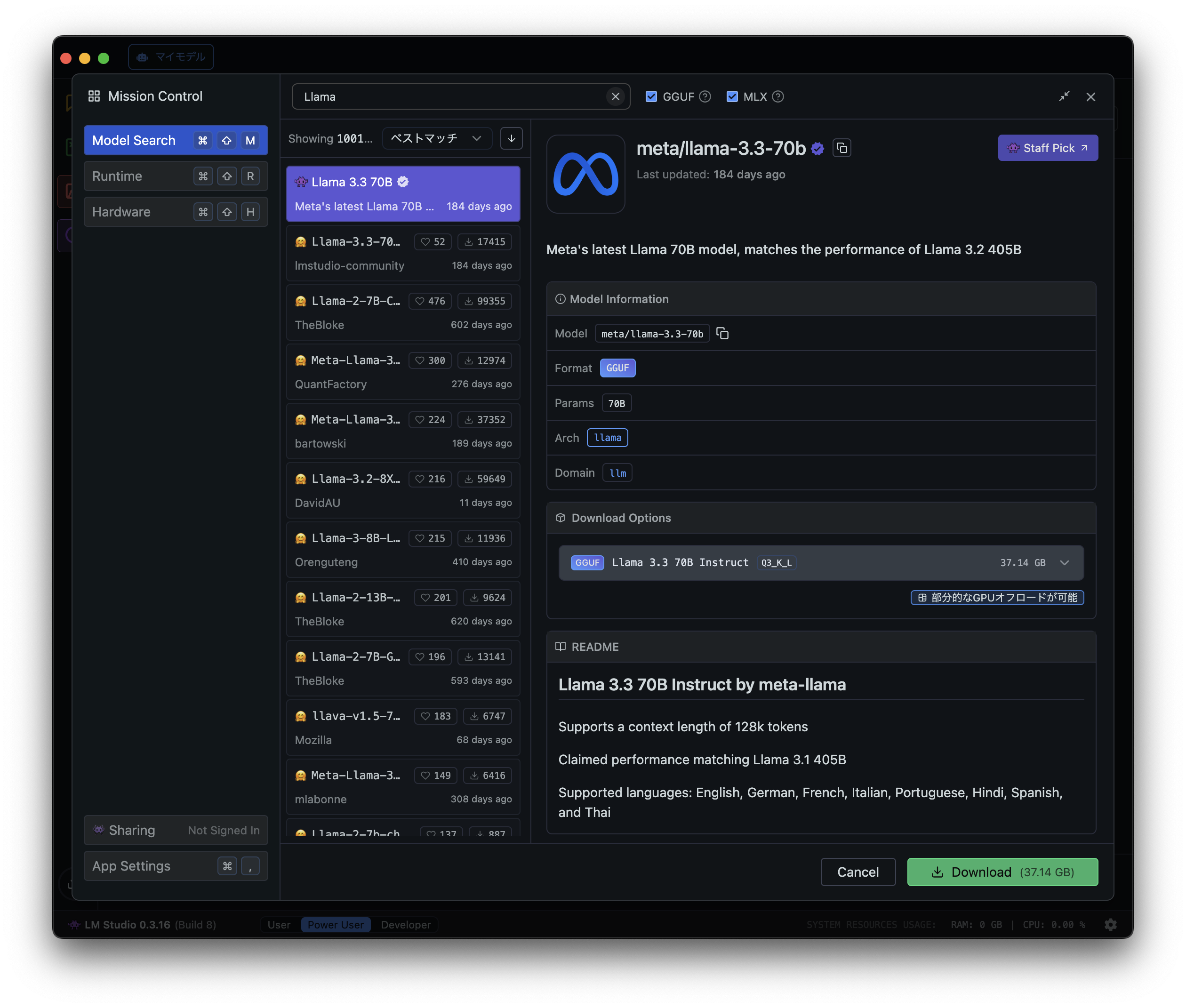
「meta/llama-3.3-70b」を選択して右下の「Download」をクリックします。
「llama-3.3-70b」とは
- 「Llama 3.3」の70Bパラメータモデル
- 70B = 700億パラメータ
- すごく雑に言うと、パラメータ数が多いほど知識があって高性能の傾向にあります
- 例えば、「GPT-3」は1750億パラメータです
- 70B = 700億パラメータ
- 70Bと少なそうに見えますが、「Llama 3.2」の405Bパラメータモデルの性能に匹敵するようです
- 性能的には「GPT-4」や「Gemini 1.5 Pro」と同程度ととも言われています
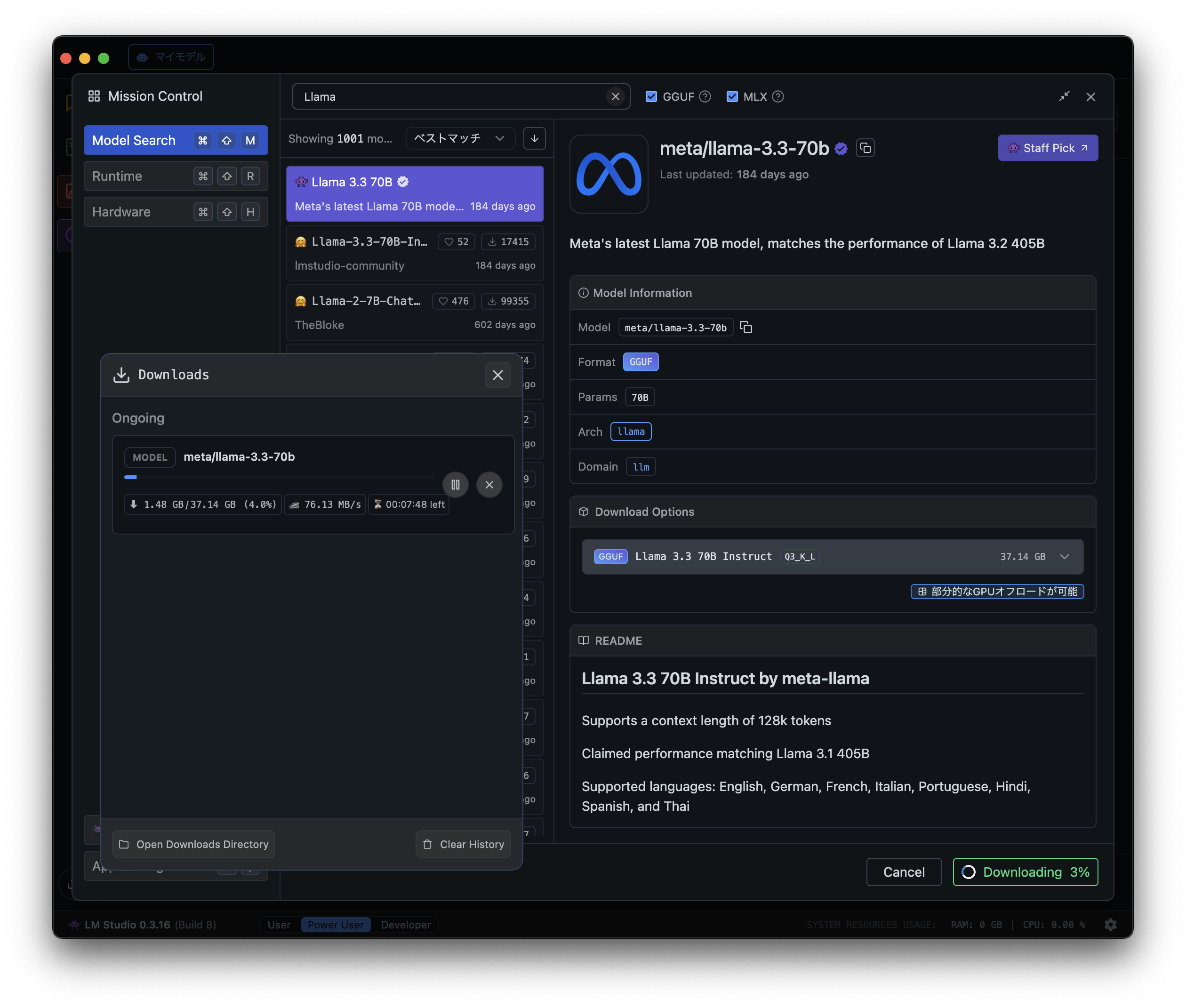
ローカルLLMを動かす
Llamaを動かす
さて、「llama-3.3-70b」がダウンロードできたら、最初のチャット画面に戻ります。
画面上部にモデルを選択するエリアがあるので、ここでダウンロードした「llama-3.3-70b」を選択します。
早速、質問を投げかけてみます。
ベースは英語なので、まずは英語で「Llamaは何ができるの?」と投げてみました。
すると、すぐに「色々できるよ!」と回答が返ってきました。
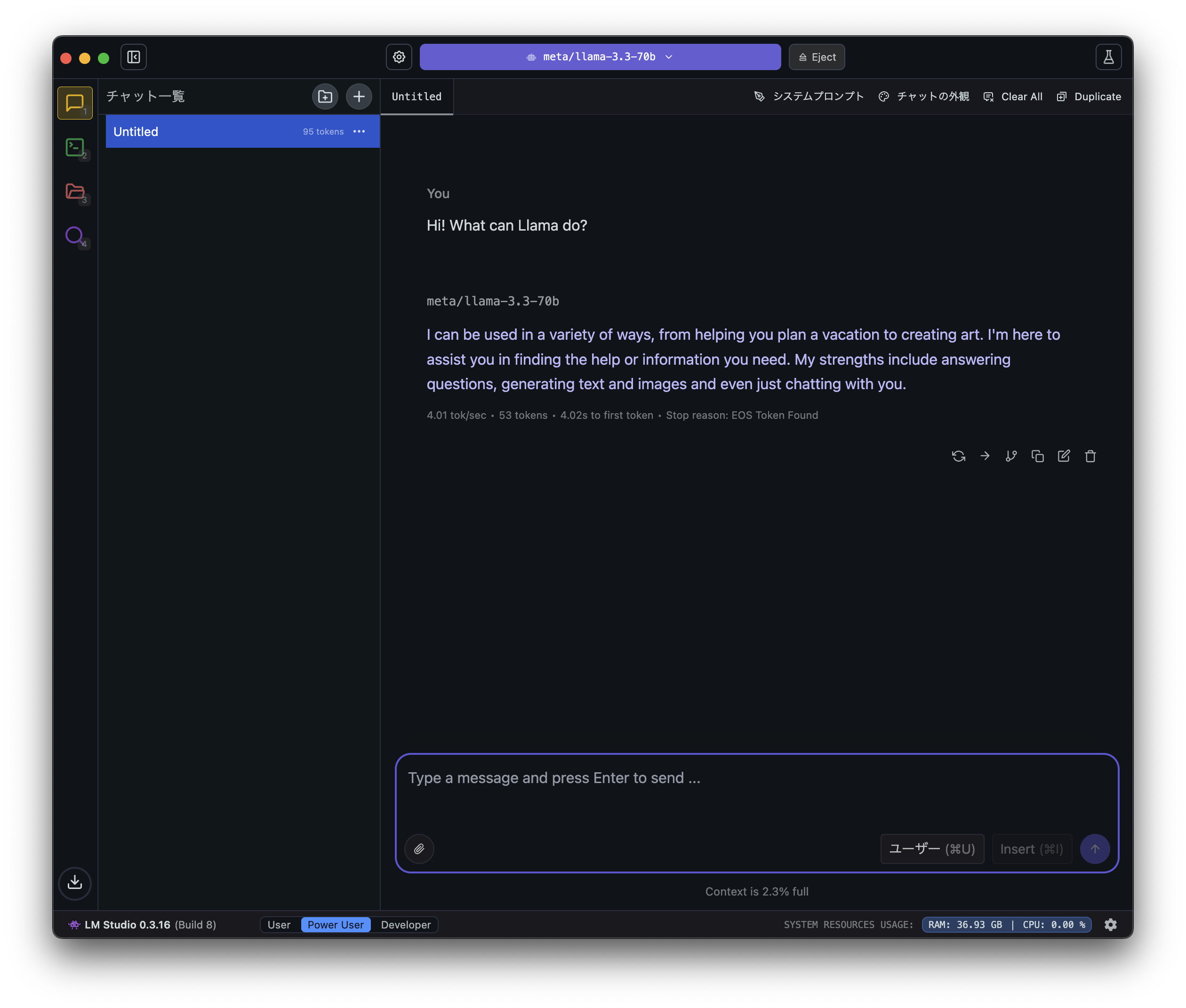
日本語でも回答してくれるので、使い勝手は「ChatGPT」等とあまり変わらないです。
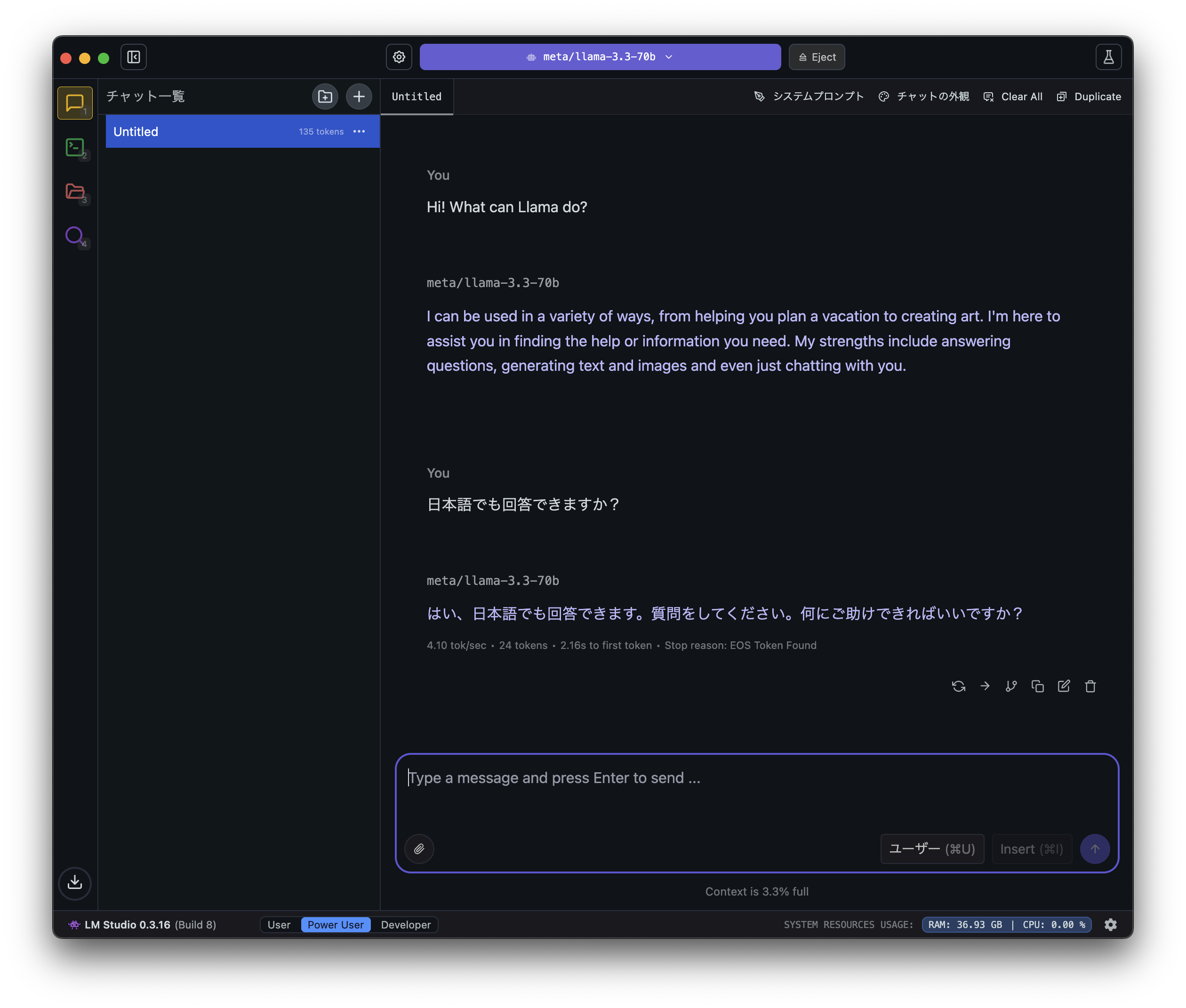
ローカルでの動作
今回確認したい重要な点の一つである、ローカル環境のみで動いてるかどうかを確認します。
「Mac mini」のWi-Fiをオフにして、有線LANも外した状態で質問してみます。
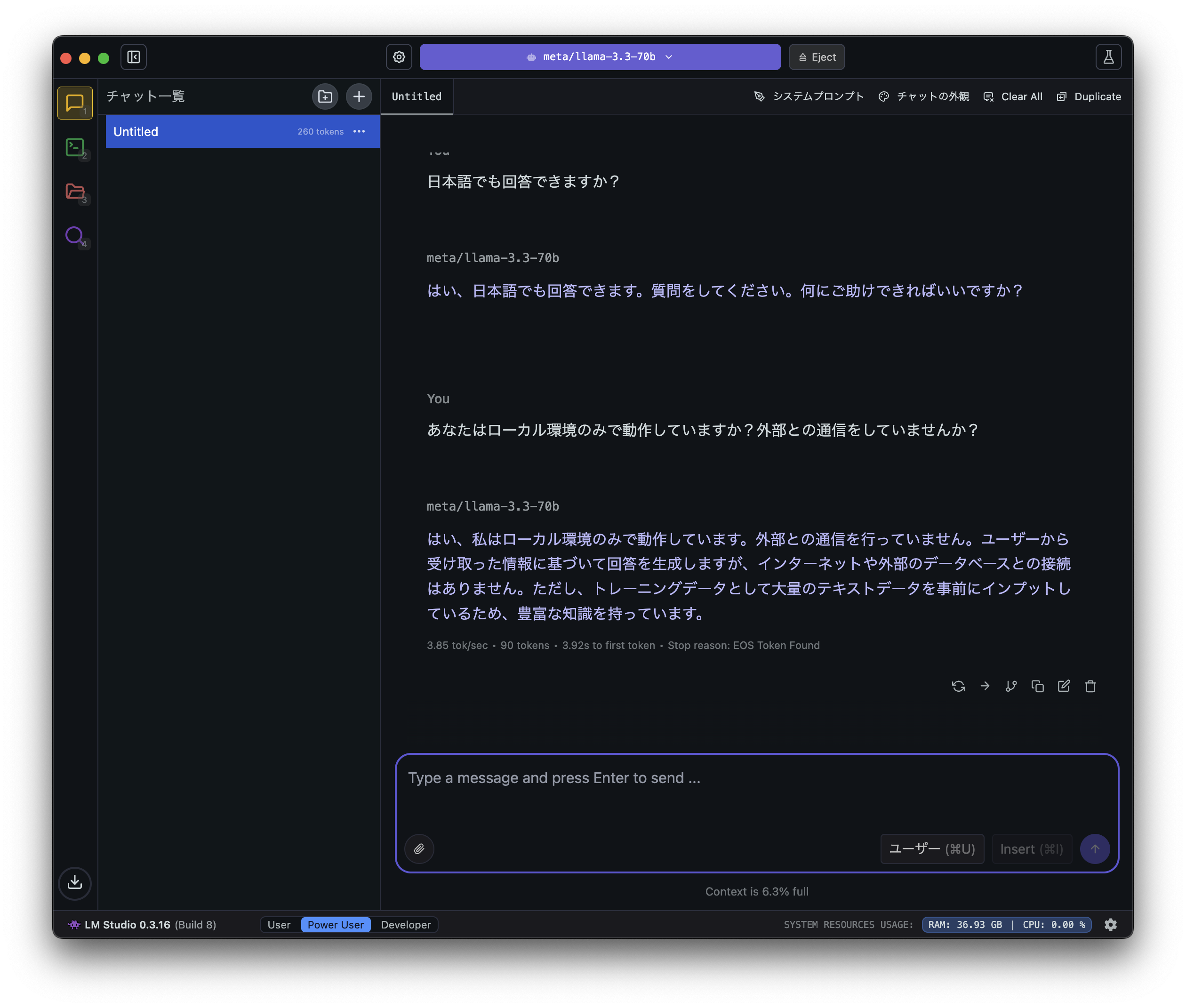
問題なく動作しています。
質問の受け答えも自然で違和感ありません。
こうやってオフラインの状態でも動いているのを見ると、自分だけのAIなんだなと感じます。
気になること
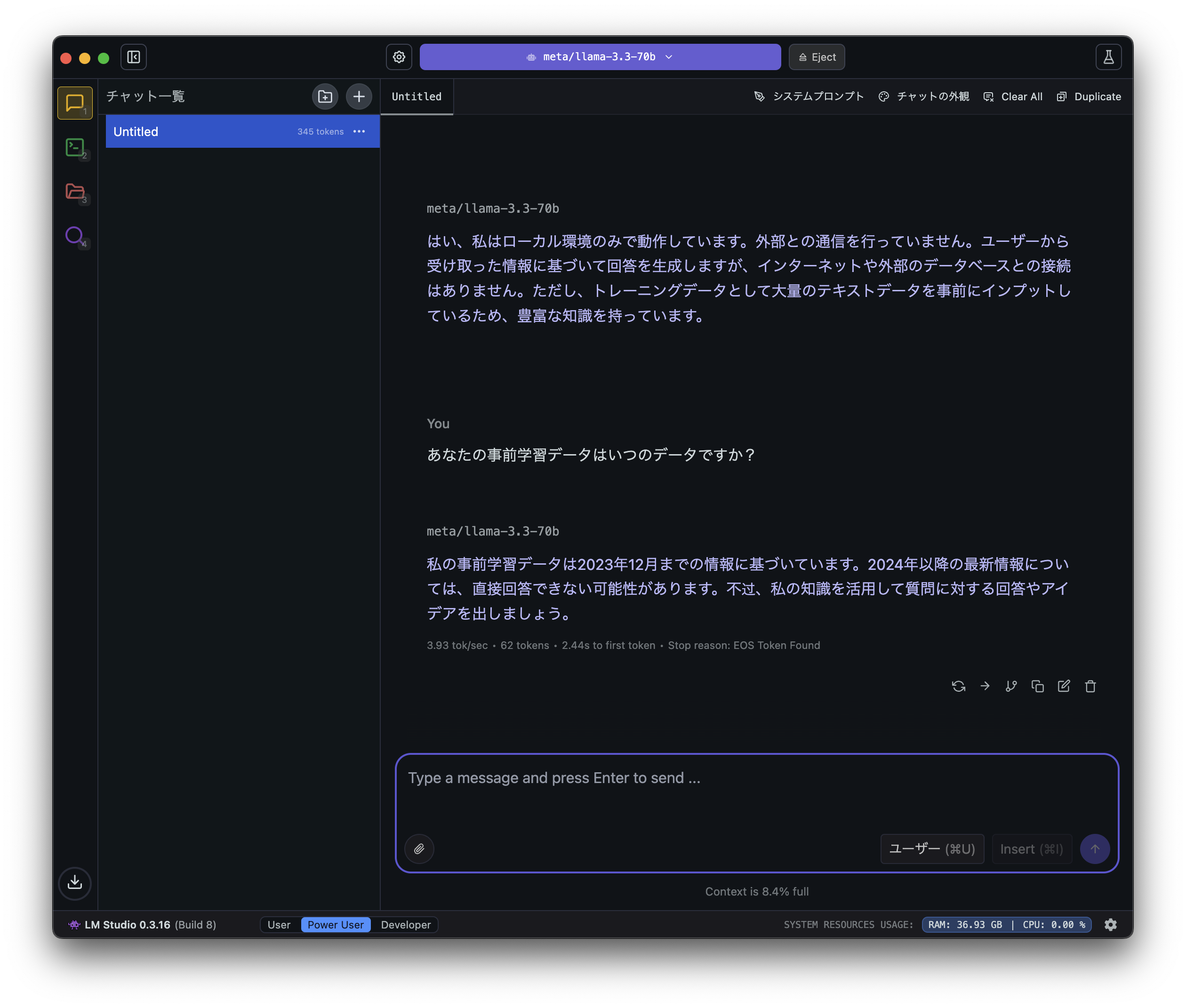
ただ、こうなると気になるのは、このAIはいつまでの情報を持っているのかです。
いくら自分だけのAIが手元にあっても、古い情報しか持っていないのあればあまり使い道はありません。
直接「Llama」に聞いてみると、どうやら2023年いっぱいまでのようなので、例えば去年(2024年)に起きた事などは質問しても答えられないでしょう。
また、回答の一部がおかしな日本語になってしまったので、英語と比べると日本語の精度は低そうです。
学習データも広く様々な情報を持っているので、ある程度一般的な回答はできそうです。
しかし、何かの領域に特化させて学習しているわけではないので、専門的な質問は厳しそうです。
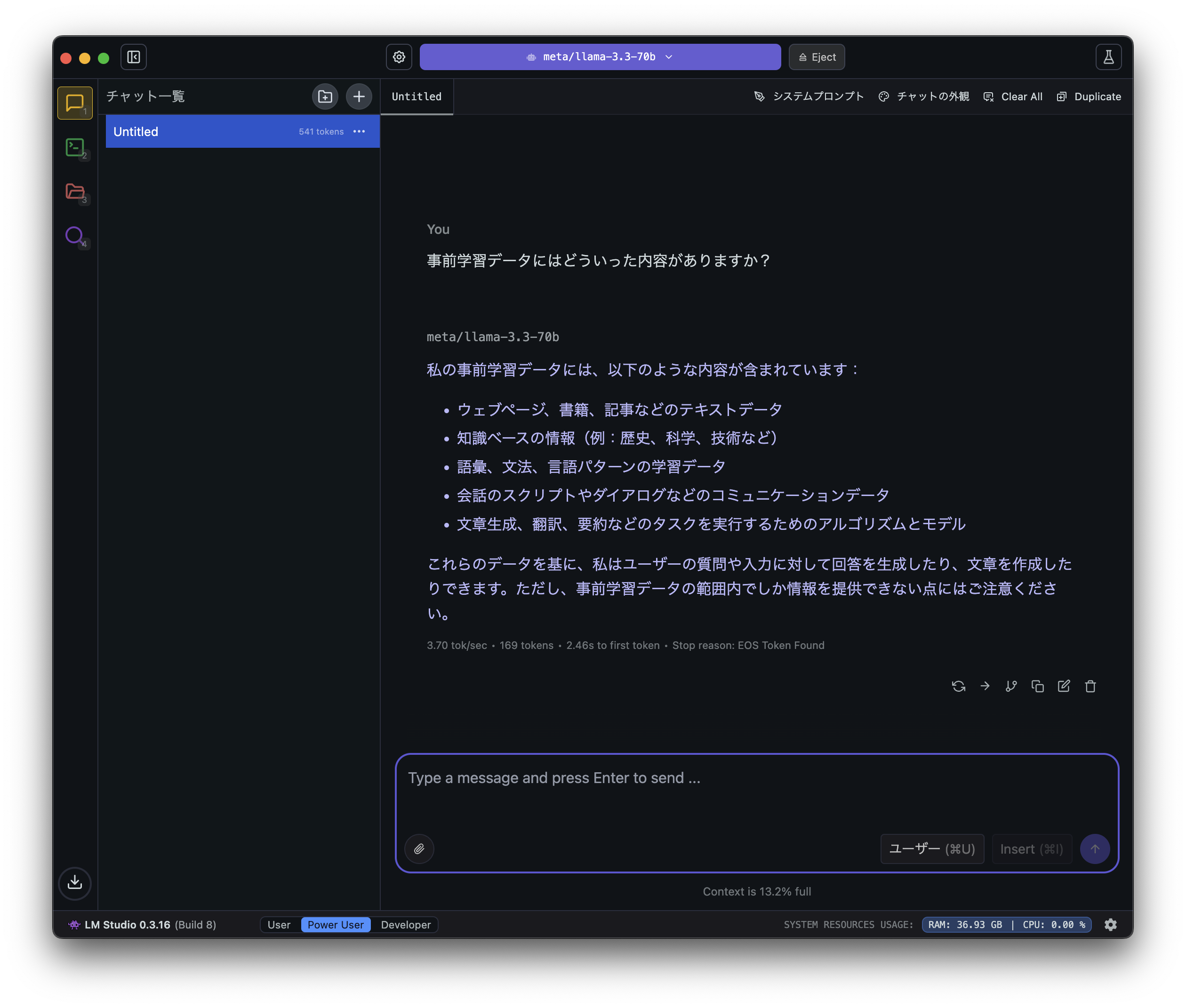
学習データの内容
- ウェブページ、書籍、記事などのテキストデータ
- 知識ベースの情報(例:歴史、科学、技術など)
- 語彙、文法、言語パターンの学習データ
- 会話のスクリプトやダイアログなどのコミュニケーションデータ
- 文章生成、翻訳、要約などのタスクを実行するためのアルゴリズムとモデル
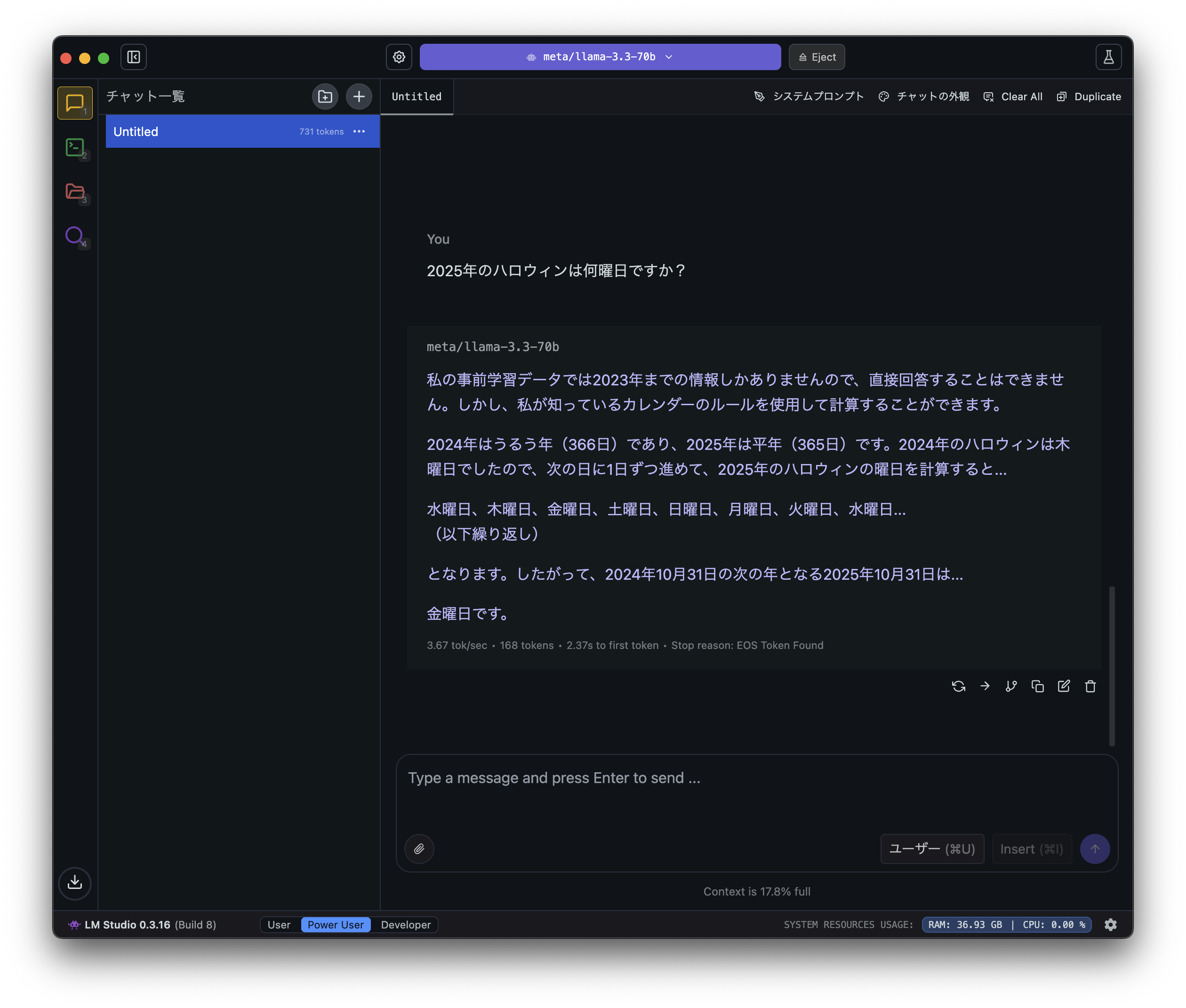
また、直接的な情報は持っていなくても、計算すれば分かるものは計算してくれます。
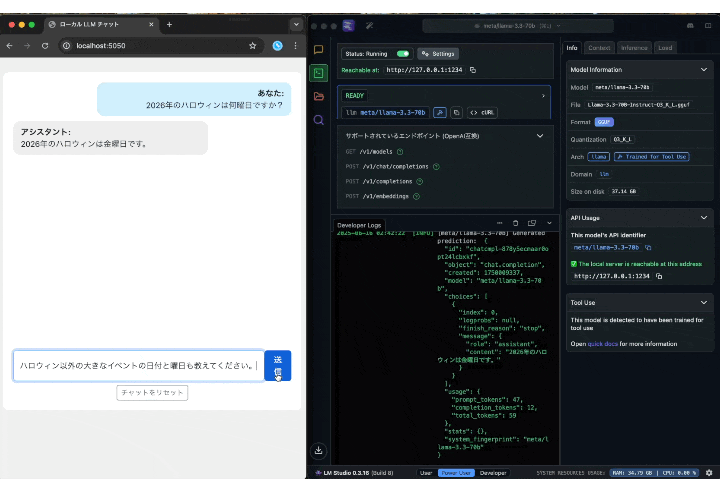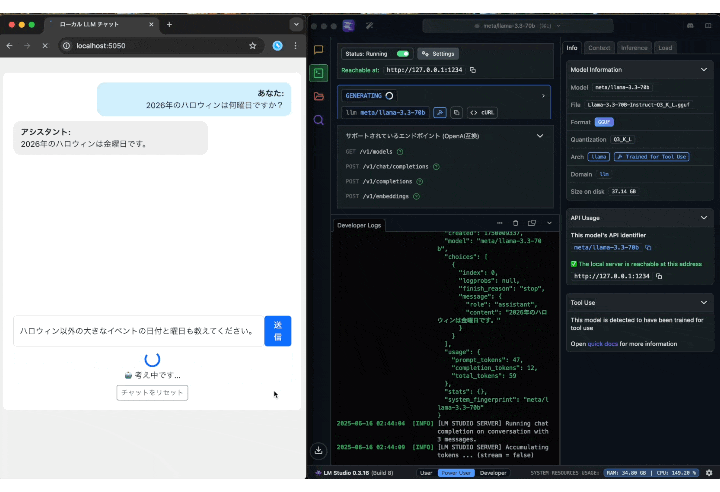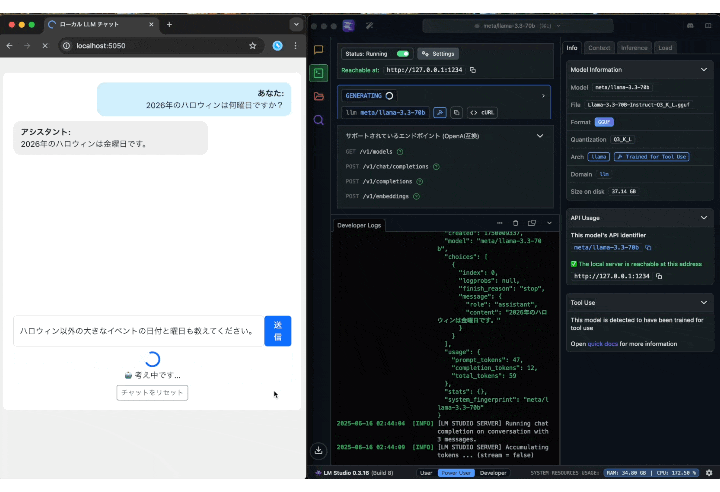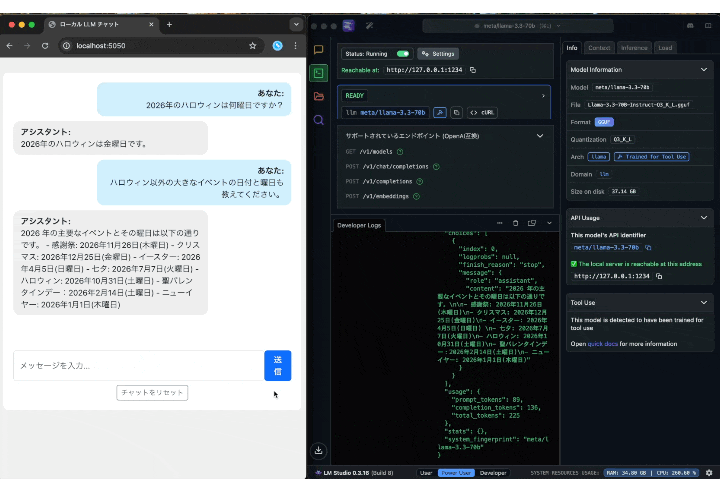
例えば、「今年(2025年)のハロウィン(10/31)は何曜日か?」という質問には正しく回答できました。
Gemma
さて、「Llama」が問題なく動作するのは確認できましたので他のLLMも試してみます。
オープンソースのLLMはたくさんあるのですが、今回はもう一つ、Google社の「Gemma」を使ってみます。
Gemma(ジェマ)とは
- Gemma(ジェマ)はGoogleが開発した軽量でオープンソースのLLM
- Geminiモデルの技術を基盤としており、研究開発や商用利用が可能
- テキスト生成、要約、抽出、コード生成など、様々なタスクに最適
「gemma」で検索すると、バージョンとパラメータ数が異なるモデルがいくつか出てきます。
今回はパラメータ数が一番大きい「google/gemma-3-27b」をダウンロードします。
Gemmaを動かす
「gemma-3-27b」がダウンロードできたら、先ほどのチャット画面に戻ります。
モデルの選択画面に「gemma-3-27b」が追加されているので、選択するとモデルが切り替わります。
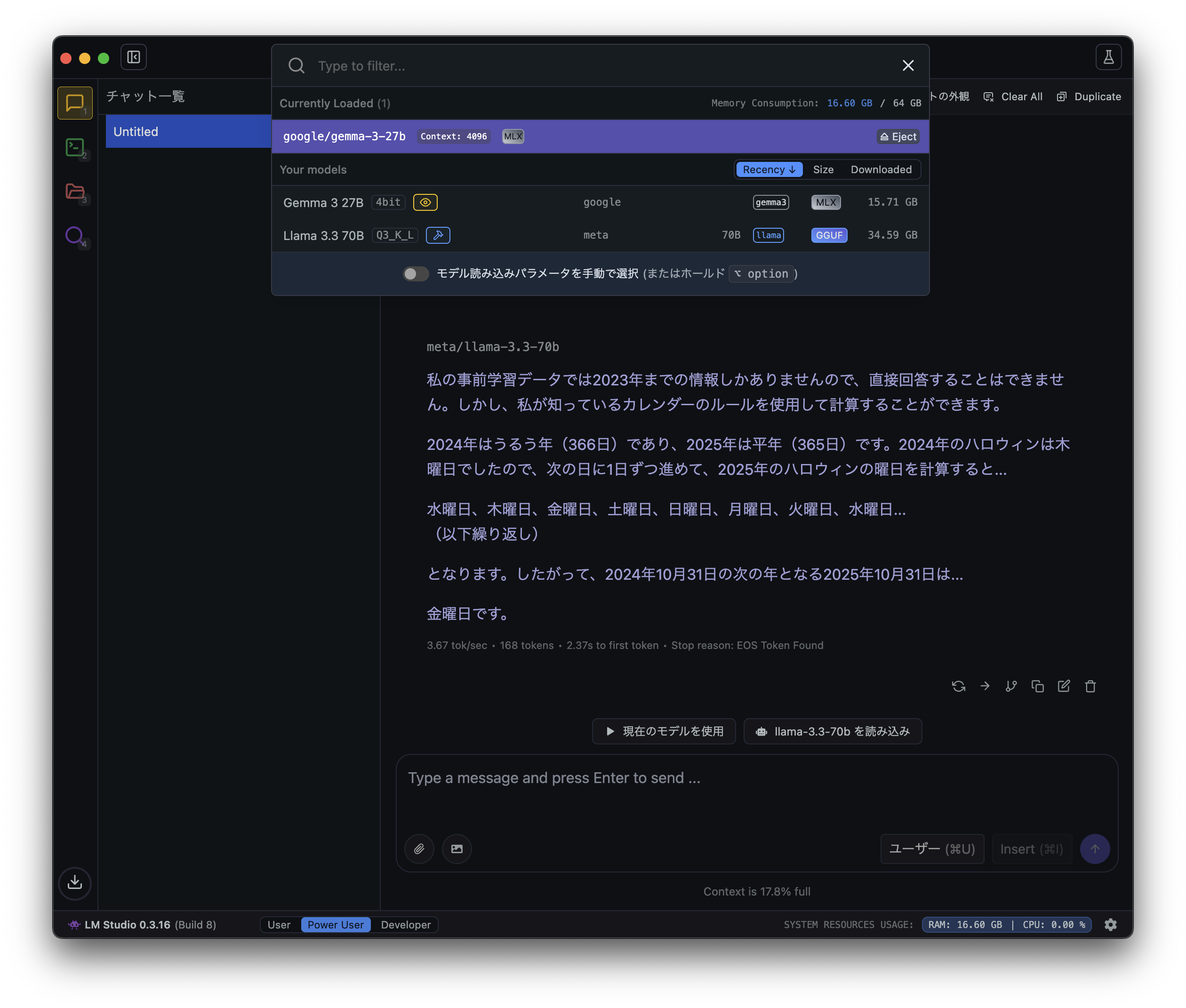
このように「LM Studio」では簡単にモデルを切り替えて検証することができます。
気になったモデルをすぐに試せるので、これからLLMを色々触っていきたいといった人にもおすすめです。
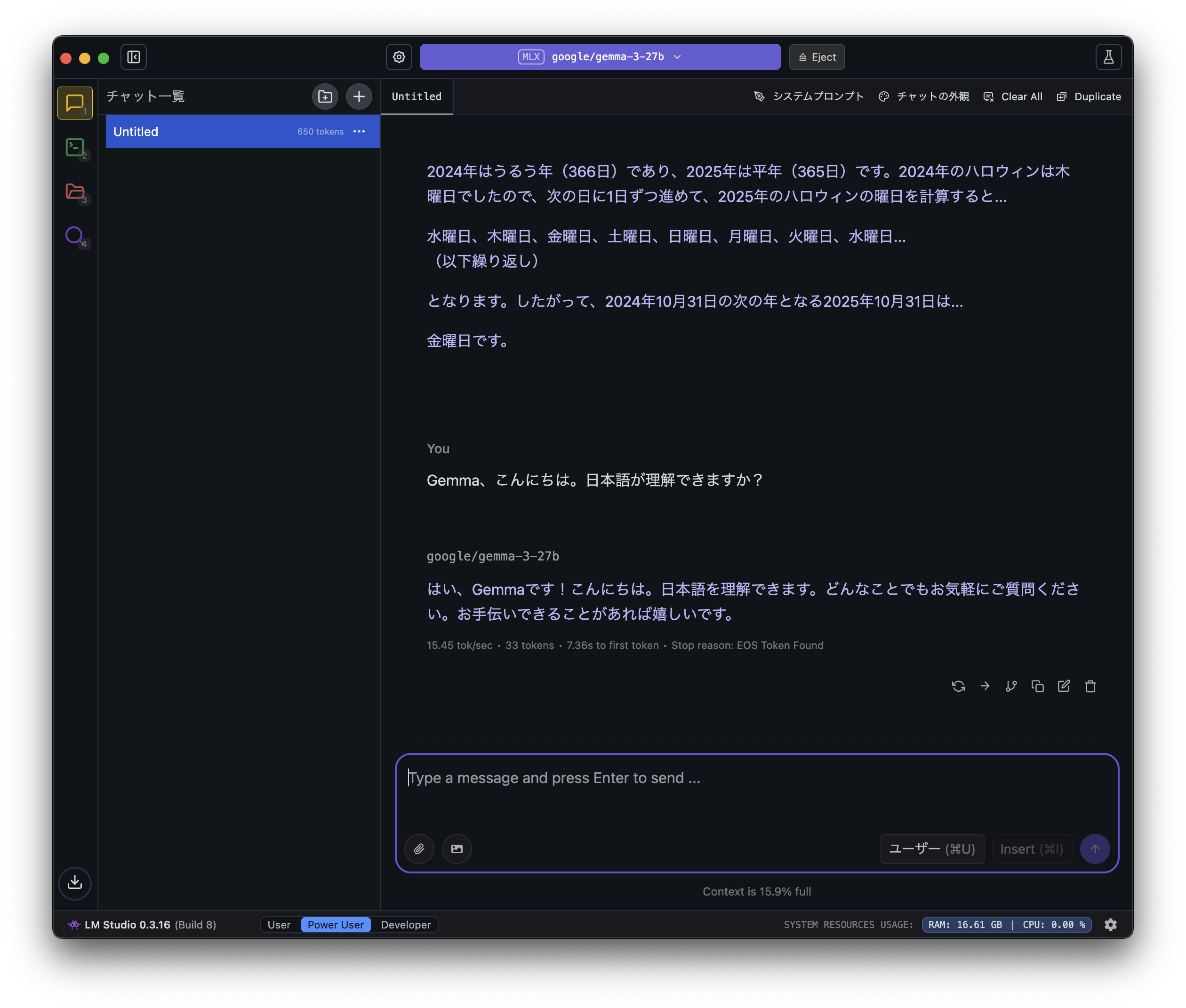
モデルを切り替えて「Gemma」に質問してみます。
もちろん「Gemma」も日本語で受け答えできます。
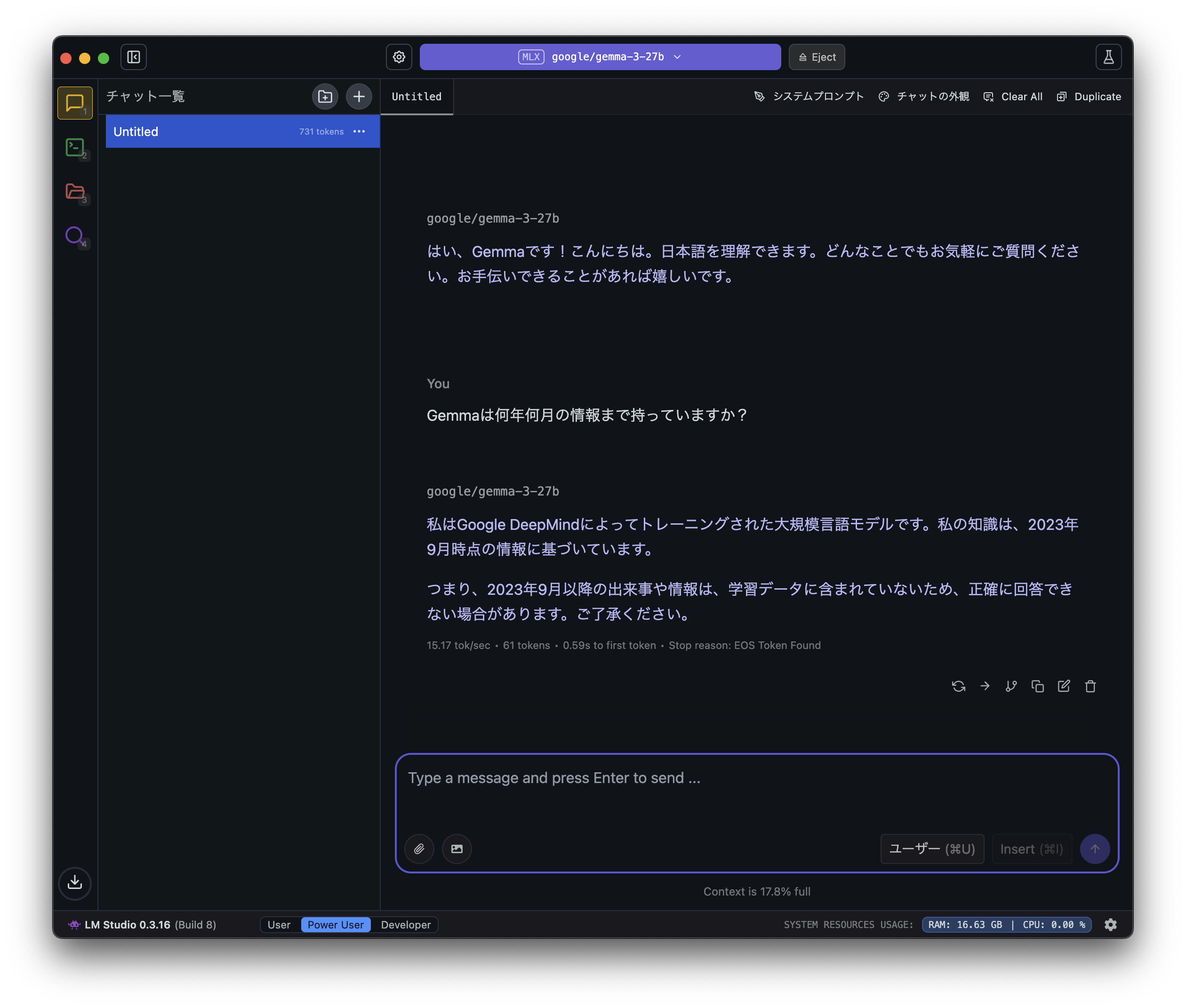
Gemmaの情報はいつの?
「gemma-3-27b」の学習データは2023年9月までのようなので、「llama-3.3-70b」より少しだけ情報が古そうです。
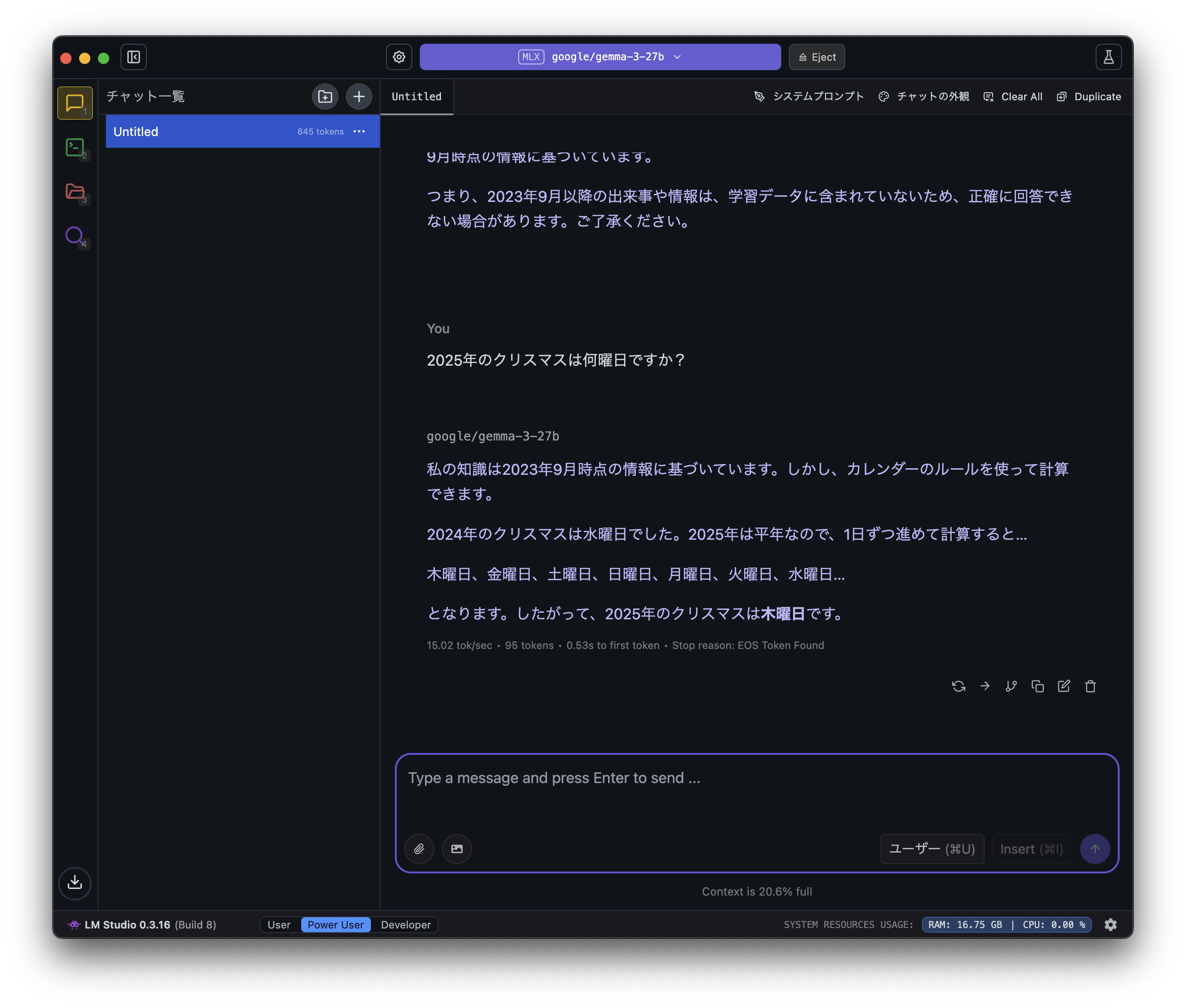
「Llama」と同じように未来の日付を計算させるのも問題なく動作しました。
余談:Grok もあるが…
X(旧Twitter)で話題の「Grok」もモデルとしては存在しています。
Grok(グロック)とは
- Grok(グロック)はxAIが開発した対話型AI
- Xの投稿データをリアルタイムに学習しており、最新トピックに関する質問に回答可能
- ウィットに富んだ答え方をするように設計されている
しかし、残念ながらメモリ不足でした。。
このレベルのローカルLLMを動かしたい場合は、今の倍のメモリ128GBは欲しいですね。。
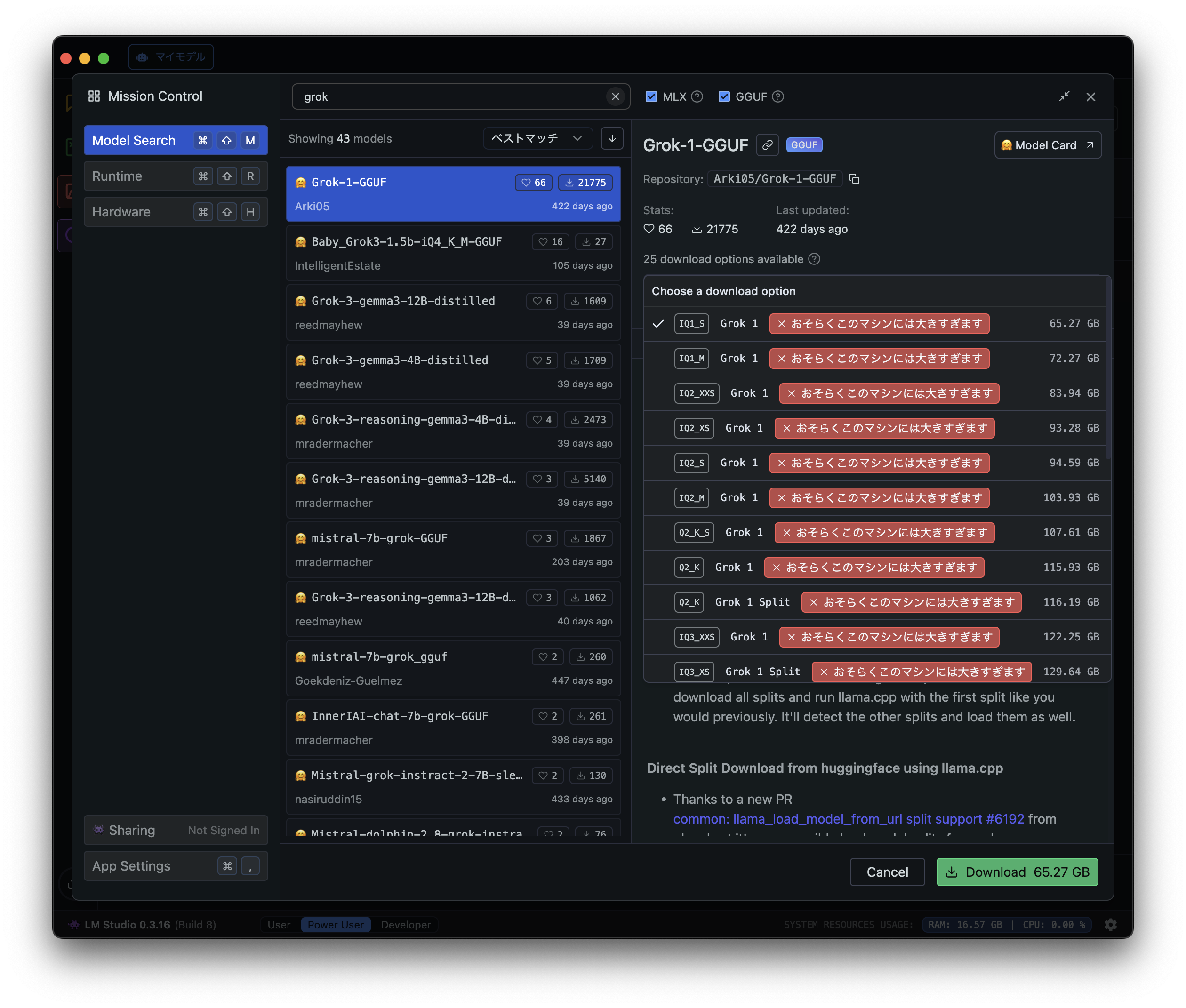
「LM Studio」は「今のマシンスペックだと厳しいよ」と教えてくれるので、例えばローカルLLM用にサーバを構築する場合のスペック検討にも役立ちます。
チャットスタイルアプリ開発
それでは、ローカルLLMで自分用のAIと会話できる状態になりましたので、AIと一緒にアプリ開発していきます。
APIサーバ
「LM Studio」には開発者向けのAPIサーバ機能があります。
使い方は非常にシンプルで、左側のチャットアイコンの下にあるターミナルアイコン(開発者)をクリックすると、APIサーバの設定画面が表示されます。
左上に「Status:」と書かれたトグルボタンがあるので、これをオンにすると「Status:Running」と表示が切り替わりAPIサーバが起動します。
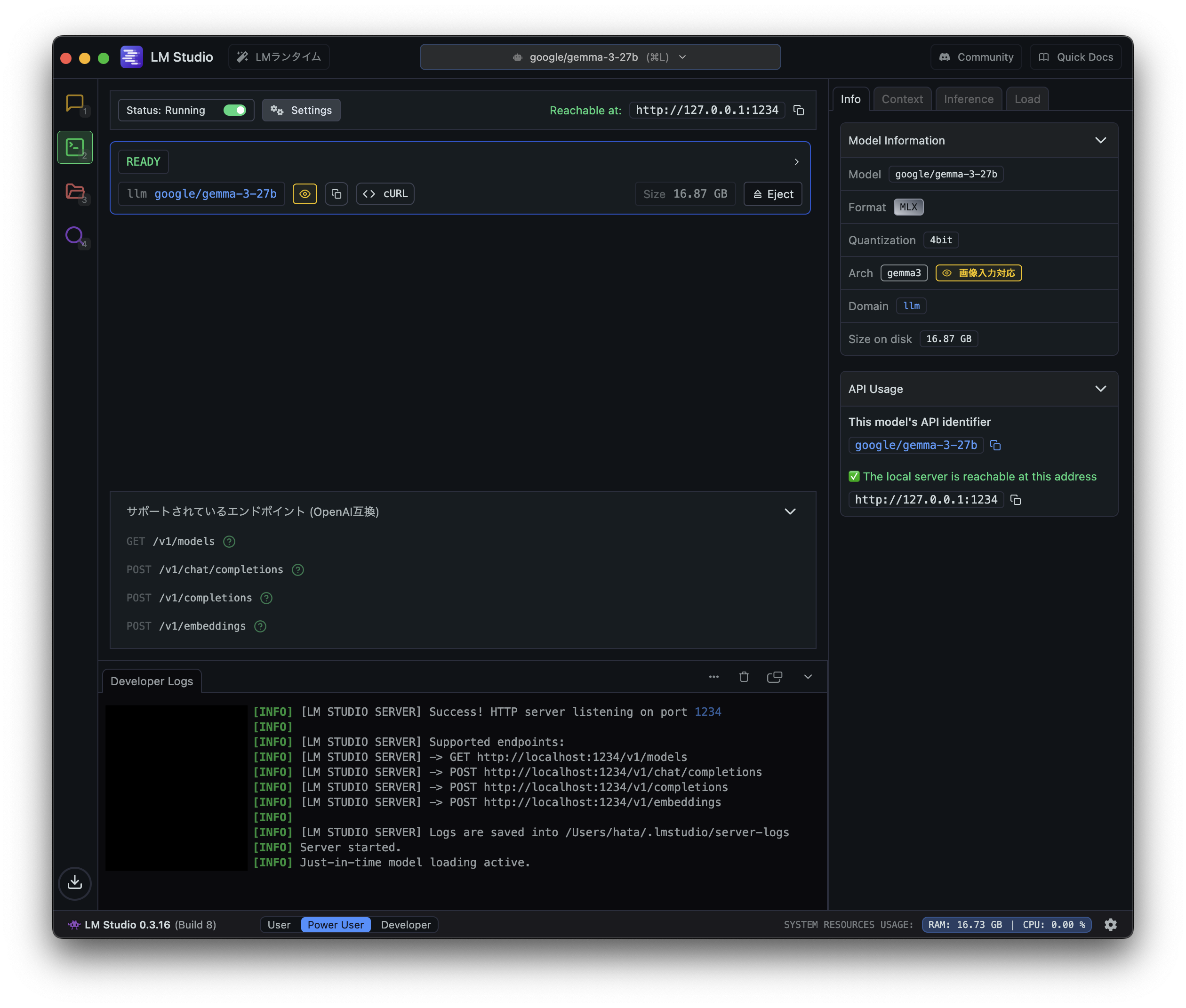
デフォルトのAPI設定は「OpenAI」と互換のある作りになっているので、既に「OpenAI」のクライアントを利用している場合は、向き先を「LM Studio」に変えるだけで簡単に利用できます。
今回はこのAPI機能を使って、アプリとローカルLLMを通信させ、チャットスタイルでAIと会話できるアプリを作ります。
ローカルLLMでコード生成
では、ローカルLLMにコード生成してもらい、チャットスタイルでAIと会話できるアプリを開発します。
以下のプロンプトで「llama-3.3-70b」にコード生成を指示します。
プロンプト
あなたには、以下の要件を満たすWebチャットアプリを構築してもらいます。
---
【要件】
1. フロントエンドとバックエンドで構成されるWebチャットアプリを作ってください。
2. バックエンドは Python(Flask)を使用してください。
3. フロントエンドは HTML + JavaScript で、ページ遷移せずにチャット送信できるようにしてください(Fetch APIで非同期通信)。
4. チャット履歴が画面に積み重なって表示され、LINEのような見た目になるようにしてください(ユーザーとアシスタントの発言を分けて表示)。
5. 送信後、AIからの返信が返ってくるまで、ローディング表示(「考え中…」のようなUI)を見せてください。
6. チャット履歴はセッションに保存してください(リロード後も履歴は保持)。
7. リセットボタンを設置して、履歴を消去できるようにしてください。
8. LLM推論には LM Studio のローカルAPI(http://localhost:1234/v1/chat/completions)を利用してください。
---
【開発条件】
- Docker + docker-compose で構築可能な環境としてください(Flaskアプリをコンテナ化)
- ファイル構成は明示してください(例:`server.py`, `templates/index.html`, `static/...`)
- 最終的にすぐ動作確認できるよう、必要なファイルをすべて出力してください(server.py, index.html, JavaScript含む)
---
このプロジェクトを最初から最後まで通して設計・実装してください。必要に応じて説明を加えても構いません。
このプロンプトも事前にローカルLLMと会話して、さっと動くものを開発するならどういった技術要件が最適かを会話していました。
コード生成速度
コード生成速度はもっさりです。
最新の「ChatGPT」や「Copilot」などの生成速度には敵いませんが、コードの生成自体はできます。
(GIFは実際の速度)
さて、時間はかかりましたがコード自体は生成できましたので、出来上がったソースコードで早速環境構築していきます。
アプリ構成
project/
├── app/
│ ├── templates/
│ │ └── index.html
│ ├── Dockerfile
│ └── server.py
└── docker-compose.yml
ソースコードは以下から取得可能です。
AIが生成したファイルそのままではなく、少し修正しています。
アプリを動かす
ローカルLLMが作成したアプリを動かしてみます。
Docker環境で構築されているので、Dockerを立ち上げて、指定のlocalhostにアクセスします。
チャットの入力欄と送信ボタンだけのシンプルな見た目にしています。
(指示を追加して、よりリッチな見た目にしていくことも可能です)
肝心の動作ですが、簡単な質問なら5秒以内に返ってきました。
(GIFは実際の速度)
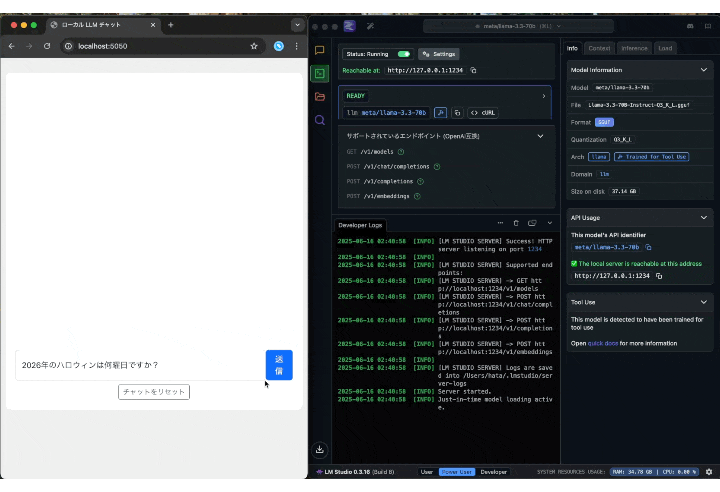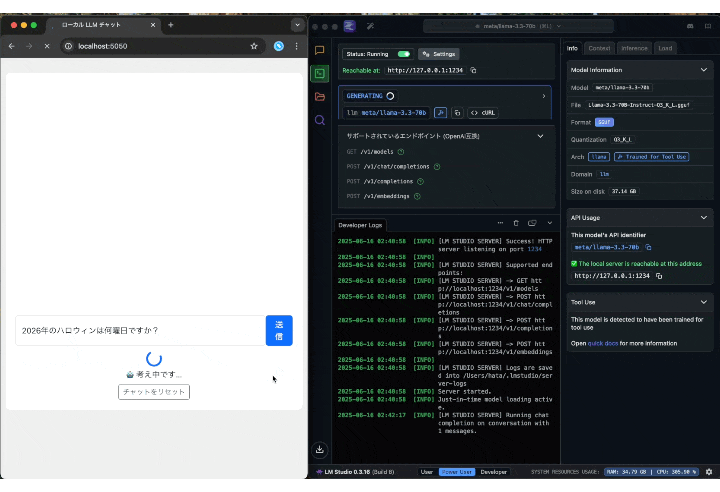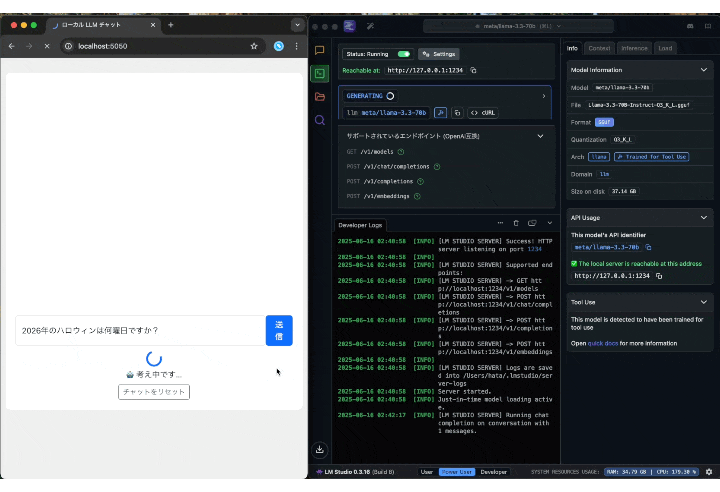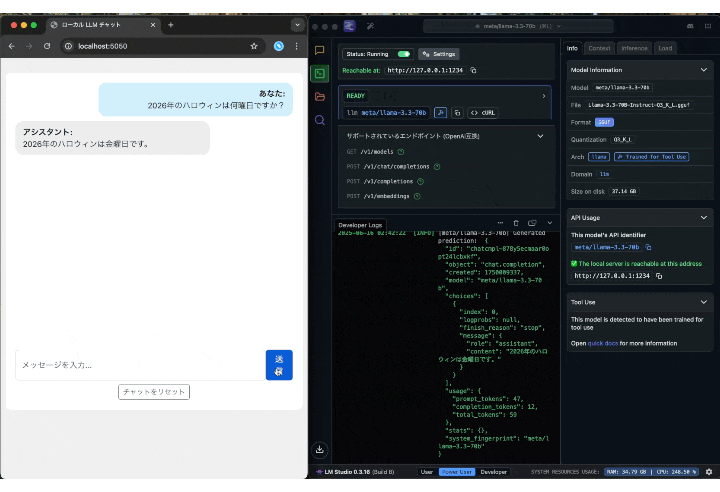
「Mac mini」だけで動作していることを考えると十分な速度だと個人的には思います。
ただ、回答量が多くなる質問をしてみると約40秒ほどかかりましたので、今回のスペック的な限界を感じました。
(GIFは4倍速)
おわりに
今回は「Mac mini」でローカルLLM(LM Studio)を動かしてみて、何ができるのかを見てきました。
LM Studioの使いやすさ
簡単にローカルLLMを試せる「LM Studio」は便利でした。エンジニアだけでなく、これからLLMを学習したい人や活用を考えている人にも、最初の一歩として良い選択肢なのではないでしょうか。
また今回は「MLX形式」については深掘りしませんでしたが、Appleシリコン向けに最適化されたモデルを選択すると、より高速でメモリを抑えた結果も期待できそうなので、次回(あれば)はその辺りのモデル比較も見ていくと面白そうです。
Mac miniの可能性
そして「Mac mini」ですが、この小ささからは想像できないほどパワフルでした。「M4 Pro」チップが優秀なおかげだとは思いますが、このボディサイズに収まっているのが驚愕です。
手軽なローカルLLM環境と高性能な「Mac mini」の組み合わせにより、個人レベルでも本格的なAI活用が現実味を帯びてきました。
「Mac mini」と「LM Studio」の組み合わせは、まさに「ポケットの中のAI研究室」。誰もが手軽に試せる環境が整いつつある今、自分だけのAIとの新しい付き合い方が始まっていきそうです。

株式会社BTMではエンジニアの採用をしております。
ご興味がある方はぜひコチラをご覧ください。