はじめに
本記事はDatabricks アドベントカレンダー2024 15日目の記事です。
Databricks Japanでソフトウェアエンジニアをしている渡辺と申します。業務では主にMLflowというMLOps・LLMOpsツールの開発をしています。
MLflowとは
MLflowは2018年にDatabricksの創業者であるMatei Zahariaらによって開発されたオープンソースの機械学習プラットフォームです。現在のMLflowでは主に以下の機能が提供されています。
- 実験のトラッキング: 機械学習モデルの学習や成果物を一元的に管理できます。
- モデルの管理: 学習・作成したモデルをバージョン管理することができます。また、依存パッケージや入出力形式などのメタデータもモデルと共に記録されます。
- 評価: モデルを様々な指標で評価し、結果を可視化することができます。
- 推論: モデルを1コマンドで様々な推論サーバーやコンテナにデプロイできます。
- 可観測性: トレーシング機能を活用して、複雑なモデルの内部動作を可視化・監視することができます。
これらのMLflowの主要機能はすべてオープンソース化されており、プラットフォームに依存せず利用できます。
そんなどこでも使えるMLflowですが、実はDatabricks上で用いると嬉しい機能・連携がたくさんあります。今回は、その中でも特に開発者目線で魅力的な機能を5つご紹介します。
1. サーバーの自動管理
MLflowでは、「トラッキングサーバー」というサーバーを中心に、実験、モデル、その他さまざまなアセットの管理が行われます。
個人でMLflowを利用する場合、以下の図の(1)と(2)のように、トラッキングサーバーを立てずにローカルのファイルやデータベースを直接使用することも可能です。一方、チームで開発を行う際には、図の(3)のように、モデルやデータへ共通アクセスするためにトラッキングサーバーを立てるのが一般的です。
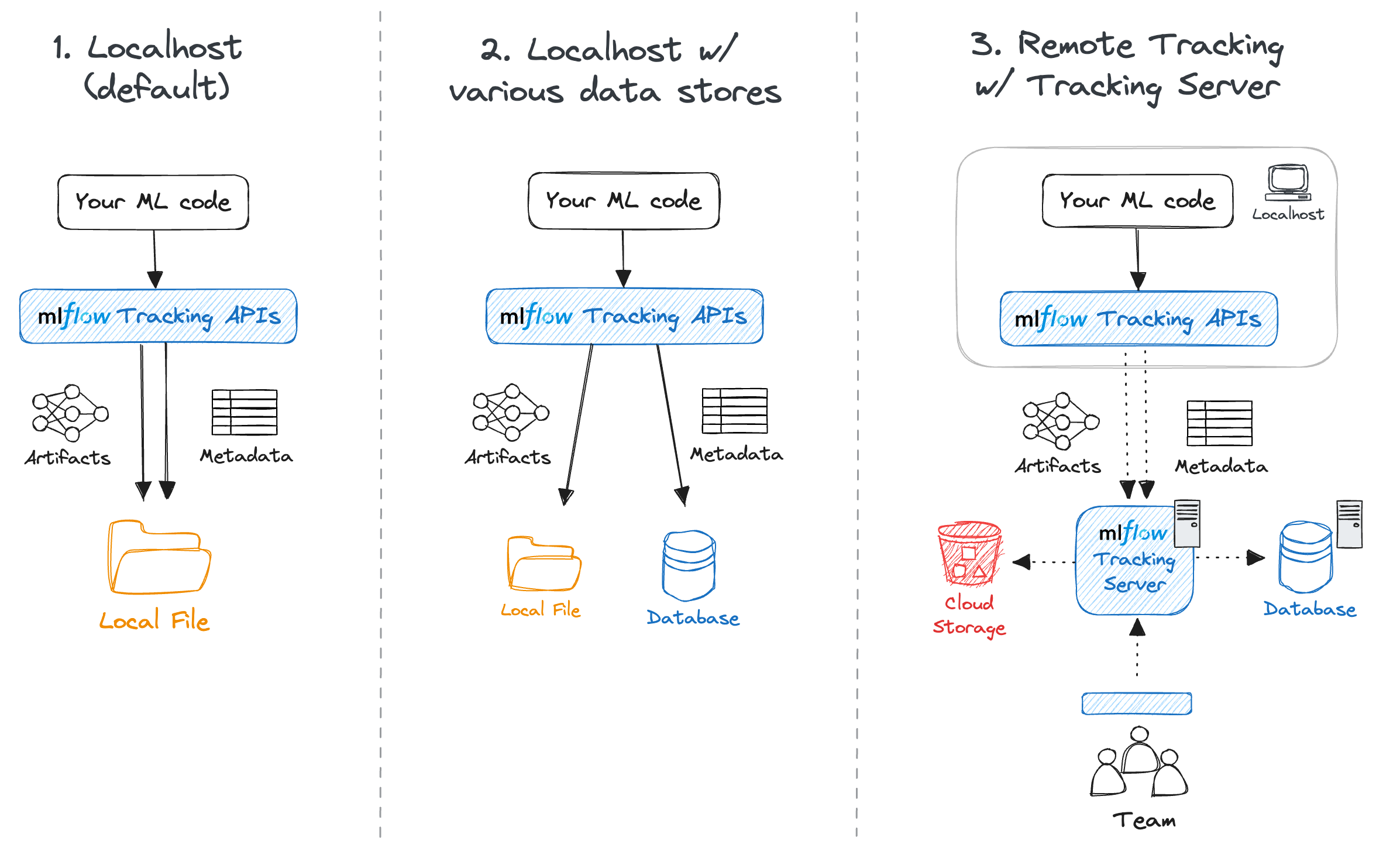
トラッキングサーバーそのものは非常にシンプルで軽量ですが、それでも大規模な組織全体で利用したり、本番環境へのデプロイに用いる場合などは、それなりの運用コストが見込まれます。また、データセットやモデルは重要な資産であり、適切なセキュリティ管理のもとで運用する必要があります。
ところは、Databricks内ではトラッキングサーバーを一切気にせずMLflowを利用することができます。
DatabricksではManaged MLflowという形で、マネージドのサーバーが最初から提供されています。一見有料プロダクトのようですが、Managed MLflowは無料サービスで、特にセットアップや設定もありません。例えばDatabricks内でノートブックを立ち上げると、自動的にMLflowのExperimentが作成され。ノートブック内から記録したモデルや実験データは自動でこのExperimentに保存されます。もちろんファイルを保存するストレージやノートブックインスタンスの料金はかかってしまいますが、 MLflowの利用そのものに追加の課金はされません。
このように、Databricks環境ではトラッキングサーバーを意識せずに、手軽に機械学習モデルやアセットの管理を行うことができます✅
2. Unity Catalogとの統合
MLflowには「モデルレジストリ」という機能があります。この機能を使うと、学習または作成したモデルをバージョン管理し、各バージョンにさまざまなアノテーションを追加することができます。
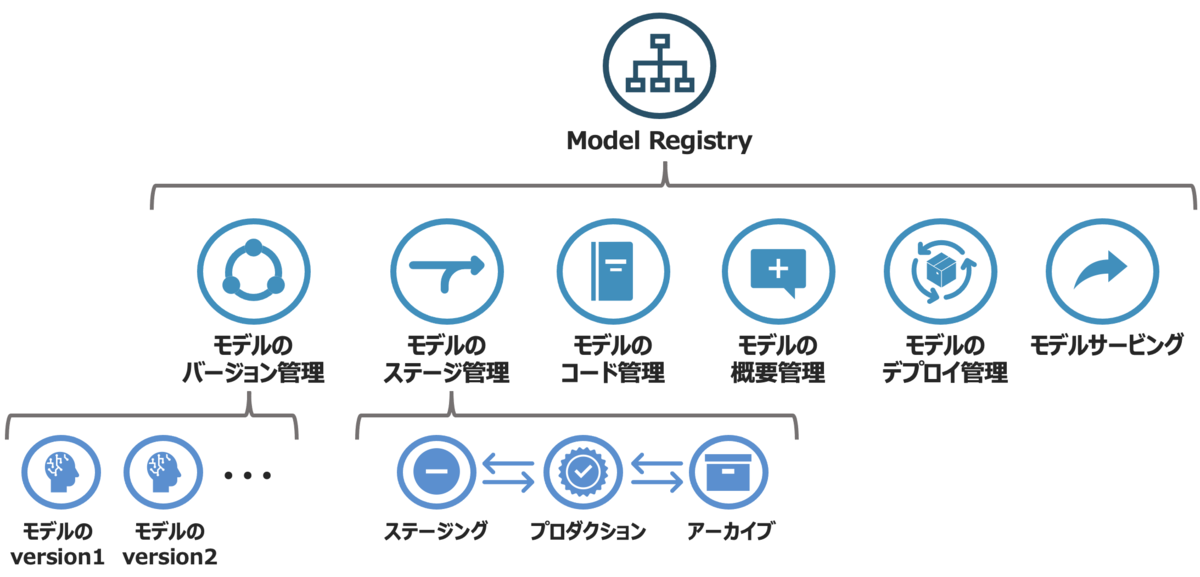
Databricksでは、このモデルレジストリがUnity Catalog上で実装されています(ただし、WorkspaceでUnity Catalogが有効化されている場合のみ利用可能です)。
この機能は一見地味ですが、非常に強力です。モデルとデータを一連の資産として、Unity Catalogの強固なガバナンスのもとで管理できます。また、データセットだけでなくモデルの推論ログ(Inference Table)も同じカタログに記録されます。Unity Catalogの高度な検索機能を活用すれば、どのチームがどのデータやモデルを運用しているかを簡単に把握できます。
MLflowのモデルレジストリは主にモデル管理のための機能ですが、Unity Catalogと組み合わせることで、組織全体のデータ・ML資産を一元管理するプラットフォームとして機能するのです ✅
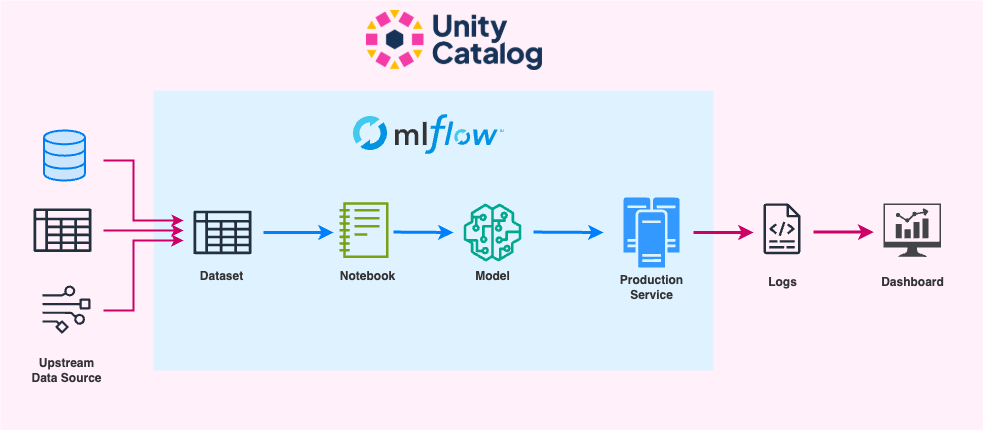
3. End-to-endのリネージ
MLプロジェクトでよく起こる失敗として、成果物の所在が分からなくなる問題があります。例えば、以下のような状況です:
- 半年前に本番デプロイしたモデルの精度が落ちてきたので再学習しようとしたが、学習に使ったノートブックが見つからない。
- ノートブックは見つかったが、どの時点のコードを使用したかが不明瞭。
さらに、モデルだけでなく、学習に使うデータセットの出所も重要です。機械学習のデータセットは、さまざまなデータソースを組み合わせ、複雑な特徴量エンジニアリングを行って作成されます。たとえモデルの学習コードが管理されていても、データセットを再現できなければ同じモデルは得られません。
他にも、一般的な機械学習プロジェクトでは以下のように次々と成果物が作成されます。
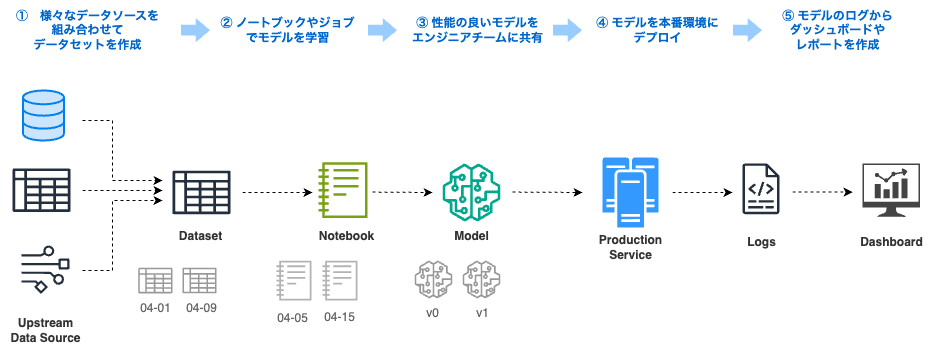
これらの成果物とステージ間の関係を記録し続けるのは大変です。さらに、データ、ノートブック、モデルなど異なるタイプの成果物は別々のシステムで管理されることが多く、複数システムをまたいだメタデータ管理が必要になります。
Databricksでは、データプロダクトにリネージ(追跡可能性)が標準で備わっています。これにMLflowを組み合わせることで、データ、モデル、コードを一貫して追跡できる環境が構築できます。
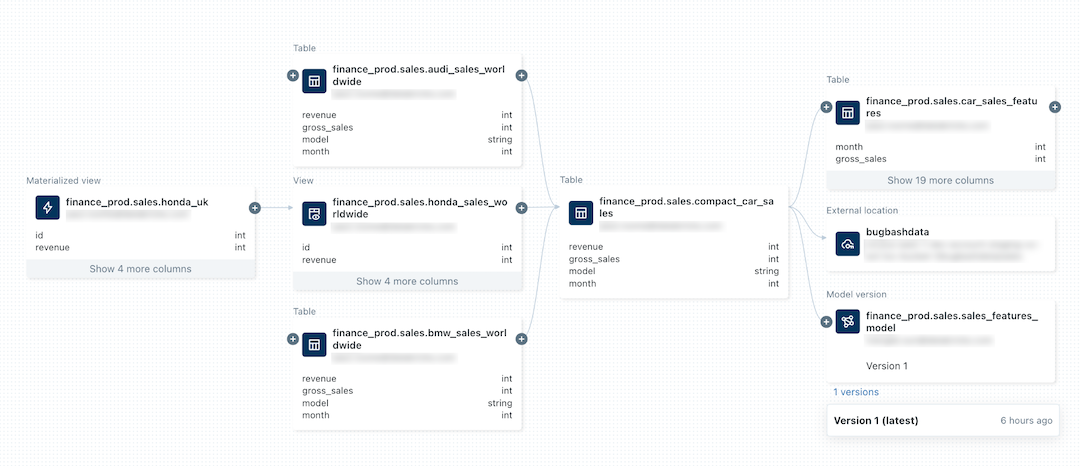
データセットやダッシュボードの作成などに用いるクエリやETLパイプラインでは、Unity Catalogが列レベルでのリネージを記録してくれます。またモデル周りのステップでは、MLflowが間を埋めてくれます。例えば、モデルを保存する際、学習・作成したノートブックのスナップショットがメタデータとして保存されます。さらに、モデルの推論エンドポイントにはデプロイされたモデルのバージョン(MLflow モデルレジストリ)が記録され、そこから生成される推論ログ(Inference Table)内でもエンドポイントとモデルの名前がメタデータとして記録されます。
このように、MLflowとDatabricksを組み合わせることで、データソースから監視まで一貫してリネージを追跡することができます✅
4. 細かなアクセス管理
モデルや実験結果は、組織にとって非常に重要な資産です。極端な例ではありますが、大規模言語モデルのように学習に数億円単位のコストがかかるような場合もあり、そのようなモデルが万が一にでも漏出してしまった場合、非常に大きい損失が見込まれます。
また、アクセス管理は外部へのセキュリティ対策だけでなく、内部での意図しないミスを防ぐためにも重要です。例えばデータサイエンティストがモデルを学習し、デプロイのためにエンジニアチームにモデルの重みファイルの場所を共有したとします。この時、エンジニアがファイルをダウンロードするつもりで誤って削除してしまうと、1からモデルを再学習する必要があります。こうした人為的なミスは、エンジニアチームにはモデルの読み取り権限のみを付与する、といった適切なアクセス管理によって防ぐことができます。
MLflowでも、記録したモデルや実験に対してアクセス権限を設定することができます。ただし、MLflow自体では簡単なHTTP認証のみがサポートされており、セキュリティ運用面では物足りないことがあると思います。
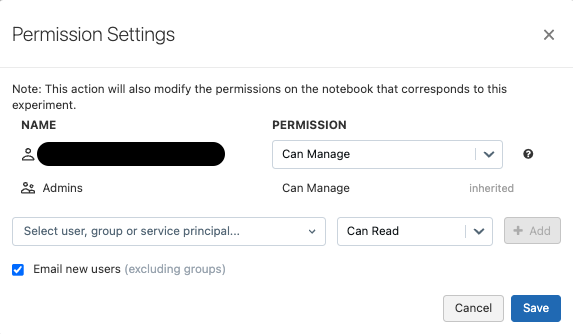
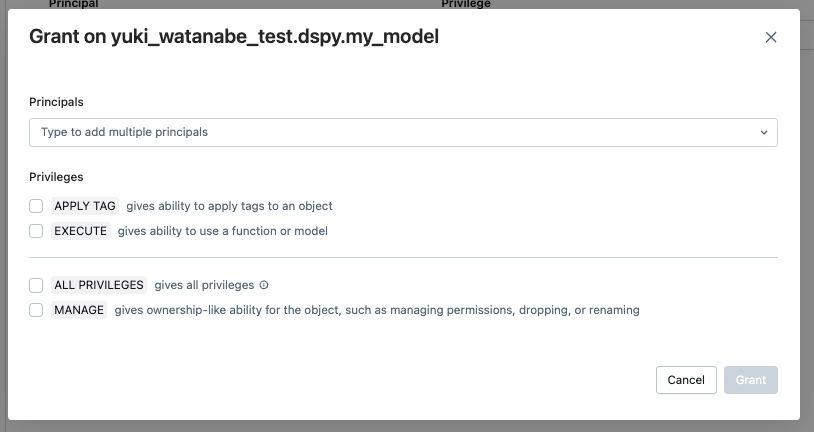
Databricks内でMLflowを利用する場合、アクセス管理がさらに強化されます。具体的には実験単位でロースベースのアクセス設定が可能であり、またUnity Catalogのモデルレジストリに登録されたモデルは、カタログ内の他のオブジェクトと同様に、細かい権限設定が可能です。
Experimentのアクセス権限設定:
モデルアクセス権限設定:
このように、MLflowがDatabricksの強固なセキュリティ基盤と組み合わさることで、機械学習の成果物をより安全かつ柔軟に管理することができます。✅
5. Mosaic AI Agent Evaluation
2024年に入ってから、DatabricksではMosaic AI Agent Frameworkという旗のもと、Agent開発のためのプロダクトが次々とリリースされました。これらの機能は基本的に全てMLflowと連携しているのですが、その中でも特に個人的に推しているのがAgent Evaluationです
MLflowにはmlflow.evaluate()というAPIで様々なモデルを評価し結果を可視化する機能があります。例えばScikit-learnのモデルとデータセットを入力することで、PrecionやRecallのような一般的な指標や、SHAPを用いた特徴量の重要度などの情報をプロットしてくれます。
Agent Evaluationは、Databricksで利用できるこのmlflow.evaluate()の拡張機能です。データセットとモデルを用意し、model_type="databricks-agent"を指定することで、LLM-as-a-Judgeを用いた様々な指標で自動的にモデルを評価してくれます。
評価結果はMLflow上に記録され、下のようなリッチなUIで1つ1つの出力に対する評価結果を確認することができます。また、モデルのトレースが自動で生成されることで、質の悪い出力があった場合、原因をすぐに究明することができます。

このように、DatabricksではMLflowのコアとなるトラッキングや評価機能を基盤としつつ、エージェント開発に欠かせない様々な機能が提供されています✅
まとめ
今回の記事では、OSSであるMLflowをDatabricksで使うとどんなメリットがあるのか、改めてまとめてみました。Databricksを使っているけどMLflowはあまり意識していないという方や、OSS版のMLflowを使っているけどDatabricksのことは知らなかったという方にとって、Databricks+MLflowの組み合わせに興味を持っていただけるきっかけになれば幸いです。
またMLflowチームではContributorやFeature Requestを随時募集しております!ご興味のある方は、ぜひ以下のGithubレポジトリからコンタクトください🙌