本記事について
音声自動文字起こし"音声認識AI whisper"について試したことをまとめたもの
誰のための記事?
- 自動文字起こしツールを探している人
- できるだけお金をかけずに文字起こししたい人
- 文字起こし後にそのまま分析したい人
音声認識AI whisperについて
OpenAIが文字起こしサービスとして公開した無料の音声認識モデルです。
Webから収集した68万時間分の多言語音声データを教師付きデータで学習させており、
高い精度で入力した音声を文字起こしすることが可能になっています。
(参考:https://openai.com/research/whisper)
whisperには下記の精度別のモデルが5種類用意されています。
今回はsmallとmediumを試してみました。

(参考:https://github.com/openai/whisper)
whisperを使用した背景
google docsなどの無償のものやsonix、easy-peasy.AIといった有償のものを試してみましたが、無償でも精度が高いものがあるのでは?と思い、whisperにたどり着きました。(本当はお金をかけたくなかっただけです)
手順
1.ライブラリをインストール
以下のコマンドでインストールします。
pip install git+https://github.com/openai/whisper.git
Successfully installed whisper-versionが表示されたら成功です!
2.音声データの準備
mp4などの音声ファイルを準備(wavなども対応可)
私は30分弱、話者3名の会議の録画データ(mp4)を使用しました。
3.スクリプトファイルを作成
meeting.pyなどの任意の名前でファイルを作成し、以下のスクリプトを書いて保存します。
モデルはsmall>medium(時間がかかるため)の順に試すのがおすすめです。
ファイルパスはmp4などの音声ファイルのパスを記載します。
import whisper
import json
model = whisper.load_model("small") #モデル指定
result = model.transcribe("ファイルパス", verbose=True, fp16=False, language="ja") #ファイル指定
print(result['text'])
f = open('transcription.txt', 'w', encoding='UTF-8')
f.write(json.dumps(result['text'], sort_keys=True, indent=4, ensure_ascii=False))
f.close()
4.ファイルを実行
ターミナルで該当のフォルダに移動して、以下のコマンドで実行します。
meeting.py部分はご自身で作成されたファイル名にて実行してください。
python meeting.py
実行すると音声の読み込みが始まります。
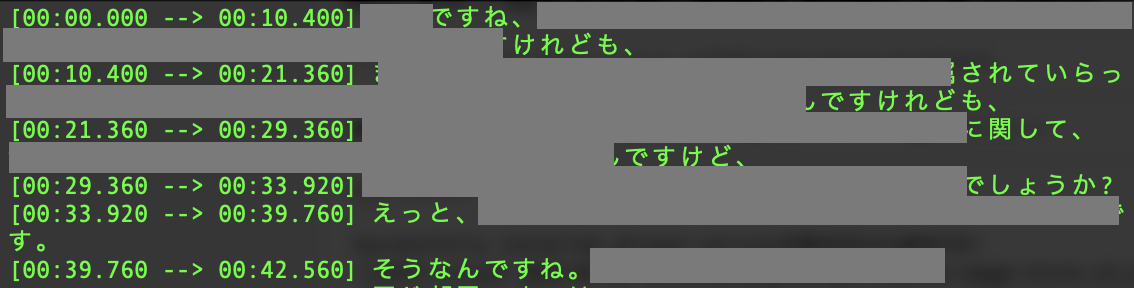
完了すると以下のようなtxtファイルが生成されます。

modelと精度について
modelはsmallとmediumを自分の耳で聞いて起こしたものと比較しました。
結論から言うとsmallで十分と言う印象です。smallでは固有名詞や漢字以外はほとんど自分の耳と一致していて、mediumになると速度も落ちて精度も下がるように思います。自分の耳は録音データの再生速度を落としたり、何度も聞き直す必要があるため時間短縮になるならsmallで文字起こしして、明らかにおかしい部分だけ再確認するのが良いと思います。
※注意点
30分弱の録音データ、話者3名なのであくまでも参考としてご確認ください。
精度の検証はdifff というwebアプリ使って検証しています。
| 評価項目 | small | medium | 自分の耳 |
|---|---|---|---|
| 精度 | 85〜90% | 70~80% | 100% |
| 速度 | 10分 | 27分 | 50分 |
ここから話者の識別まで自動化してみようと考えています。
会議だけでなく、インタビューの録音データでも形態素解析、レポート作成などまで自動化できないか検証していきます。
最後までお読みいただきありがとうございました。