12月から株式会社Scalarという会社で働いています(入社エントリはこちらです)。Scalarは、スケーラビリティと耐改ざん性を備えた分散型台帳ソフトウェアScalar DLTの開発・販売を行っているデータベースベンダーです。今回は、自分の勉強も兼ねて、そのScalar DLTについて説明していこうと思います。
Scalar DLTは、分散トランザクションマネージャであるScalar DBと分散型台帳ソフトウェアであるScalar DLから構成されています。以下の図は、Scalarのウェブページから拝借したものですが、分散ストレージ上に分散トランザクションマネージャであるScalar DBをのせて、その上に分散型台帳ソフトウェアであるScalar DLがのっているような構成になっています。

今回、Scalar DLTを説明していくにあたり、Scalar DB編とScalar DL編の2つの記事に分けて紹介しようと思います。今回はScalar DB編です。
Scalar DBとは
Scalar DBは、ACID準拠でない分散データベース/ストレージをACID準拠にするJavaのライブラリです。Scalar DBはあくまでもライブラリなので、データは、Scalar DB自体が保持するのではなく、使用する分散データベース/ストレージに格納されることになります。
さらに、Scalar DBはACIDトランザクションをサポートしつつも、使用する分散データベース/ストレージ(例えばCassandra)のスケーラビリティやアベイラビリティ(可用性)を損なうことはありません。そこら辺の仕組みについてはこの後説明します。
Scalar DBのアーキテクチャ
Scalar DBは下の図のように、「Universal Transaction Manager」と「Storage Abstraction Layer」、そして「Storage Adapters」で構成されています。ストレージ(Storage)は「Storage Abstraction Layer」によって抽象化されているので、「Universal Transaction Manager」はどのストレージを使っているかは意識しない構造になっています。「Storage Adapters」を実際のストレージに合わせて実装することで、そのストレージをACID準拠にすることができます。ちなみに現時点(2020/12/24時点)では、Cassandra、Amazon DynamoDB、そしてAzure Cosmos DBの実装があります。
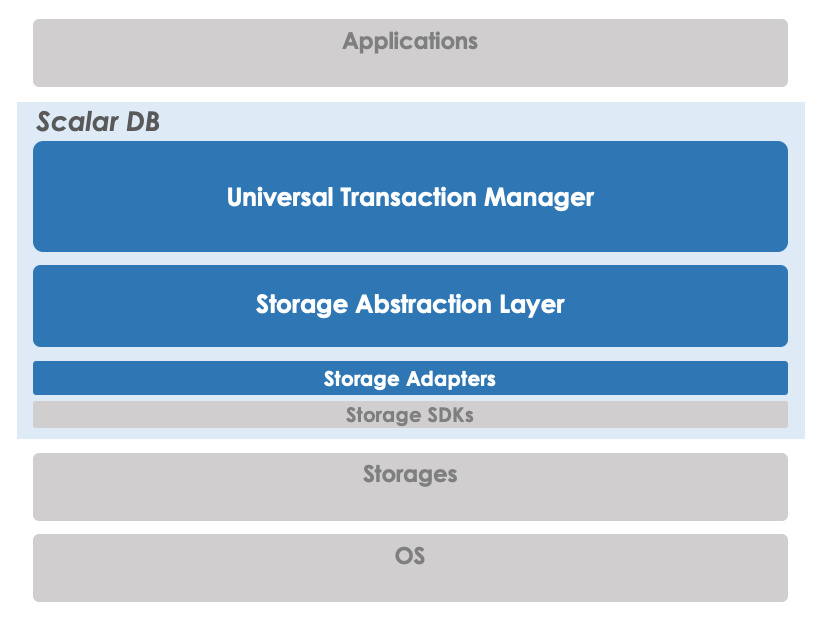
Storage Adaptersの実装について
「Storage Adapters」を実装する際には、実装したいストレージに合わせて、以下のDistributedStorageインターフェースを実装する必要があります。
ただし、Scalar DBでは、以下の条件を満たしているストレージを想定しています。
- Linearizableなレコードの読み込みができる
- Linearizable(Atomic)なコンディショナルアップデート(いわゆるCAS操作)ができる
- 各レコードにメタデータを入れることができる
Scalar DBのデータモデル
Scalar DBのデータモデルは、いわゆる多次元マップの構造になっています。1つのレコードは、パーティションキー(Partition key)とクラスタリングキー(Clustering key)があり、それに対して名前(Value name)付きの値(Value content)が複数あるという構造になっています。1つの値は、パーティションキーとクラスタリングキー、そしてその値の名前からユニークにマッピングされます。
(Partition key, Clustering key, Value name) -> Value content
パーティションキーは文字通りパーティション(Partition)を特定するキーになっています。同じパーティションキーを持つレコードは同じパーティションに所属していることになります。そして、パーティション内のレコードはクラスタリングキーによってソートされて格納されています。
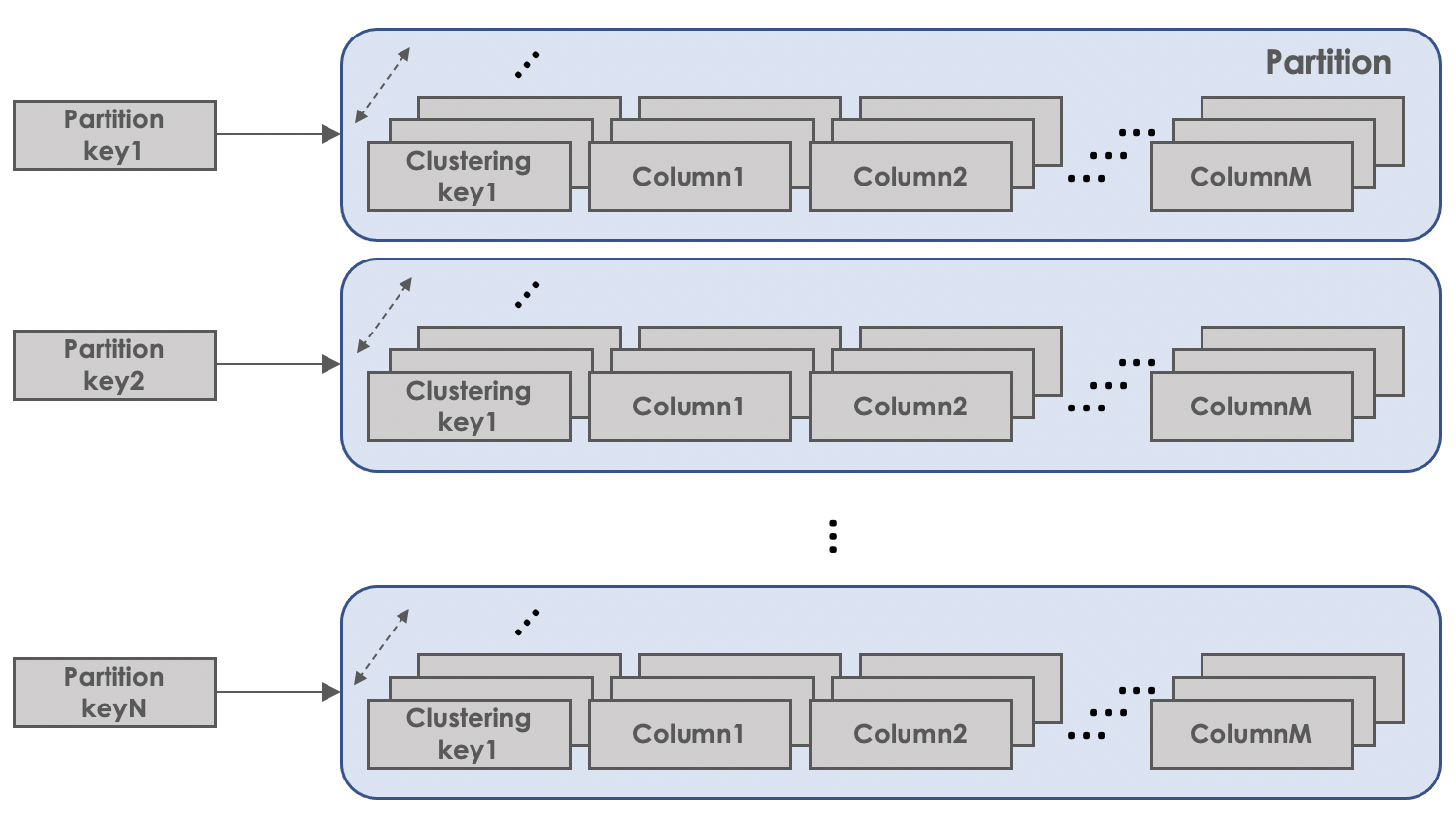
Scalar DBでは、データに対してget、scan、put、deleteのようなCRUD操作を行うことができます。getは1つのレコードを取得する操作で、scanは1つのパーティション内のレコードを、クラスタリングキーによるレンジスキャンをする操作で、putとdeleteはそれぞれレコードを追加/更新、削除する操作です。scanはあくまでも1つのパーティション内のレコードのレンジスキャンであり、パーティションをまたいだレンジスキャンはできないので注意が必要です。
また、各値にはデータ型があります。現在のところ、下記のデータ型がサポートされています。
- BOOLEAN
- INT
- BIGINT
- FLOAT
- DOUBLE
- TEXT
- BLOB
トランザクション機能について
Scalar DBでは、トランザクションはクライアント側でコーディネーションされるので、マスタ的な中央管理する役割が必要ありません。これにより、使用する分散データベース/ストレージのスケーラビリティやアベイラビリティ(可用性)を損なうことなくトランアクションを実行することができます。
また、Scalar DBでは、以下の図のように、各レコードにトランザクション用のメタデータ(青い部分)を付与します。最後に書き込みを行ったトランザクションのトランザクションID(TxID)やバージョン(Version)、そしてレコードのトランザクションの状態(PREPARED, DELETED, COMMITED)表すステータス情報(Status)が入ってます。さらに、WALとして1つ前のバージョンのアプリケーションデータとそのメタデータが入っています。これは、ロールバックする際に使われます。
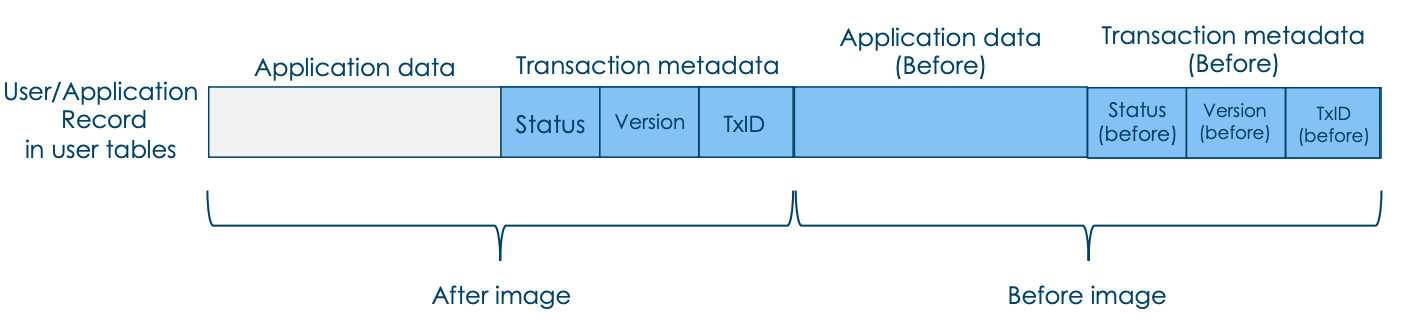
それとは別に、トランザクション(TxID)ごとのステータス(COMMITED, ABORT)等を持っているCoordinatorテーブルもあります。
トランザクションプロトコルについて
Scalar DBでは、同時実行制御方式としてはOCC(Optimistic Concurrency Control)を採用しており、コミットプロトコルとしては2フェーズコミットに似たことをします。また、Lazy Recoveryと呼ばれる、トランザクションがクラッシュした際も、クラッシュしたトランザクションが書き込みをしたレコードを別のトランザクションが読み込んだときに発動するリカバリ処理を行います。
Scalar DBのトランザクションプロトコルは以下のようになります。
- トランザクションをスタートし、データの読み書きを行います。データの読み込みに関しては、実際にストレージから読み込みを行い、そのデータをローカルメモリ上のread setに格納しておきます。データの書き込みに関しては、この時点では実際にストレージには書き込まず、ローカルメモリ上のwrite setに格納しておきます。
- データの読み書きが終了したら、Prepareフェーズに入ります。
- 書き込みをする各レコードに対してコンディショナルアップデート(条件はVersion=<前Version>かつTxID=<前TxID>)で、StatusをPREPAREDに変更し、VersionとTxIDを新しいものにし、アプリケーションデータとWALの情報を書き込みます。
- 全てのレコードに対してコンディショナルアップデートが成功した場合は、Prepareが成功したことになります。全てのレコードに対してコンディショナルアップデートが成功しなかった場合は、コンディショナルアップデートが成功したレコードをロールバックし、トランザクションをアボートさせます。
- Prepareが成功したら、Commitフェーズに入ります。
- Coordinatorテーブルに、新TxIDのレコードをStatusをCOMMITEDとしてコンディショナルアップデート(条件はそのTxIDのレコードが存在しなかったら)で入れます。
- 1が成功したら、各レコードのStatusをコンディショナルアップデート(条件はStatus=PREPAREDかつTxID=<新TxID>)でCOMMITEDに変更します。1が失敗したら全てのレコードをロールバックします。
このプロトコルのポイントは、コンディショナルアップデートを使っている部分だと思います。例えば、Prepareフェーズで各レコードへコンディショナルアップデートを行うことで、同時に同じレコードに対して書き込みを行おうとするトランザクションが複数あったとしても、1つのトランザクションしか成功しないことになります。Coordinatorテーブルへの書き込みも同様に、トランザクションやLazy Recoveryから同時に書き込みを行おうとしてもどちらかしか成功しません。これにより、矛盾した状態になることを防ぐことができます。
文章だけだと分かりにくい場合は、以下の資料も参考にしてみてください。
https://www.slideshare.net/scalar-inc/making-cassandra-more-capable-faster-and-more-reliable-at-apacheconhome-2020/14
Lazy Recoveryについて
Lazy Recoveryは、トランザクションプロトコルの1の最中にコミットされていない(StatusがCOMMITEDでない)レコードを読み込んだときに発動します。
Lazy Recoveryの手順は以下になります。
- リカバリ対象のレコードのTxIDをもとに、Coordinatorテーブルを参照し、そのトランザクションのStatusを調べます。
- StatusがCOMMITEDなら、ロールフォワードを実行し、トランザクションプロトコルの3-2と同様に、リカバリ対象のレコードのStatusをCOMMITEDに変更します。
- StatusがABORTEDなら、ロールバックを実行し、WALの情報から前のバージョンへリカバリ対象のレコードのデータを切り戻します。
- CoordinatorテーブルにそのTxIDのレコードが存在しなかった場合は、
- Coordinatorテーブルに、そのTxIDのレコードをStatusをABORTとしてをコンディショナルアップデート(条件はそのTxIDのレコードが存在しなかったら)で入れます。
- リカバリ対象のレコードに対してロールバックを実行し、WALの情報から前のバージョンへリカバリ対象のレコードのデータを切り戻します。
トランザクションのクラッシュ時のリカバリについて
トランザクションプロトコルの1の最中にトランザクションがクラッシュした場合は、この時点では何もストレージに書き込みを行っていないので何もする必要がありません。
トランザクションプロトコルの2で一部のレコードに対するコンディショナルアップデートが成功した後にトランザクションがクラッシュした場合は、リカバリ対象レコードが他のトランザクションによって読み込まれたときにLazy Recoveryが発動し、そのレコードはロールバックされ、クラッシュしたトランザクションは正式にアボートされます。
トランザクションプロトコルの3-1で、Coordinatorテーブルに、新TxIDのレコードをそのStatusをCOMMITEDとして入れた後でクラッシュした場合は、リカバリ対象レコードが他のトランザクションによって読み込まれたときにLazy Recoveryが発動し、ロールフォワードされます。
つまり、トランザクションの途中でクラッシュが発生し、中途半端な状態のレコードがあったとしてもLazy Recoveryによって、文字通りLazyにリカバリがされるという仕組みになっています。
分離レベルについて
Scalar DBでは、分離レベルとしてSnapshot Isolation(以下、SI)とSerializableをサポートしています。ただし、Scalar DBのSIはANSIで定義されているそれとは少し違っていて、SQL Serverで使われているRCSI (Read Committed Snapshot Isolation)に近いものになっています。Scalar DBのSIでは、Write Skew anomalyやRead-Only Transaction anomalyのように、SIで通常発生するのanomalyの他にRead Skew anomalyも発生する可能性があります。これらのanomalyについては、こちらの記事が参考になります。
Serializableでは、現在はExtra-writeとExtra-readという2つのアプローチが実装されており、それらを選択することができます。これらは、両方ともに、SIで起こりうるanomalyの原因であるanti-dependencyを避けるアプローチになっています。Extra-writeでは基本的にreadをwriteに変換することでanti-dependencyを排除し、Extra-readではCommitフェーズでread setにあるデータを再度読み直し実際にanti-dependencyが発生しているかをチェックします。
まとめ
今回は、Scalar DLTの1つの構成要素であるScalar DBについて説明しました。次回は、もう1つの構成要素であるScalar DLについて説明していく予定です。
We are hiring!
Scalarでは、一緒に働くメンバーを募集中です!詳細は以下をご覧ください。
https://angel.co/company/scalar-inc/jobs
この記事を読んで少しでもScalarに興味が湧いて働きたくなった方は上記URLからエントリーしてください!
それ以外にも質問や相談等ありましたら私のTwitterアカウントまでDMしていただければと思います!
参考
Scalar DB
Scalar DB design document
Scalar DB: A library that makes non-ACID databases ACID-compliant
Making Cassandra more capable, faster, and more reliable (at ApacheCon@Home 2020)