ちょっと今更感もありますが、HBaseのAccordionプロジェクトについてまだちゃんと追えていなかったので、この機会に調べてみましたので、それをまとめます。
Accordionプロジェクトとは
Accordionプロジェクトは、HBaseの読み書きの性能を上げるために、HBase2.0から新しいアルゴリズムを導入するというプロジェクトです。
HBaseはテーブルのデータをRegionと呼ばれる単位に分割して、RegionServerが各Regionの管理をしています。パフォーマンス向上のためには、RegionServer自体の内部的なスケーラビリティはシステム全体のスケーラビリティと同様に重要です。Accordionプロジェクトでは、メモリの使用効率を上げることで、RegionServerのスケーラビリティを向上させています。より多くのデータをメモリに格納することによってディスクへの書き込み頻度を下げることもできます。Accordionによって以下の2点を実現しています。
- HBaseのディスク使用量とwrite amplificationを減らすことができる
- より多くのデータに対する書き込みや読み込みをメモリでできる(パフォーマンスの向上)
通常、この2点はトレードオフの関係にありますが、Accordionでは両方同時に改善することができているようです。
Accordionは、HBaseのストレージアーキテクチャであるLog-Structured-Merge (LSM) treeにインスパイアされています。HBaseのRegionのデータは、一連の検索可能なキー・バリューマップとして保存されています。その一番上の頂点にあたるのが、MemStoreと呼ばれるミュータブルなインメモリストアです。そして、それ以外はHFileと呼ばれるイミュータブルなHDFS上のファイルで構成されています。また、HBaseはmulti-versioned concurrency controlを採用しています。これは、MemStoreは別バージョンとしてすべてのデータの更新を格納しています。ゆえに、複数のバージョンを持つあるキーは、MemStoreとHFileにそれぞれバージョンがある可能性があります。キーによってバリューを読み込む時には、最新のバージョンを探すために、(通常はBlockCache経由で)HFileをスキャンします。ディスクへのアクセス数を減らすために、HFileはバックグラウンドでマージされます。このプロセスはCompactionと呼ばれ、冗長なCellを削除し、大きなHFileを作成します。
LSM treeは、アプリケーションレベルのランダムI/OをシーケンシャルI/Oに変換することで、優れた書き込みパフォーマンスを実現します。しかし、従来の設計ではメモリ内でデータをコンパクションする仕組みがありませんでした。これは、歴史的経緯に由来しています。LSM treeは非常にメモリが小さかった時代に設計されたものなので、MemStoreのキャパシティも小さいという前提で設計されました。しかし近年のハードウェア性能の向上により、RegionServerで管理されるMemStoreのサイズは数GBもなり、最適化のためにメモリを使うことも可能になってきました。
Accordionは、メモリ上の冗長なデータやその他のオーバヘッドを削減するために、LSMの原理をMemStoreに再適用しています(インメモリコンパクション)。そうすることで、HDFSへフラッシュする頻度を減らすことができ、write amplificationやHDFSのディスクフットプリント(ディスク容量)を減らすことができます。ディスクへのフラッシュを減らすことで、書き込みがストールする頻度も減少するので、全体的に書き込みのパフォーマンスを向上させることができます。ディスク使用量を減らせることは、ブロックキャッシュの使用効率も向上させ、キャッシュヒット率も上がり、読み込みのパフォーマンスの向上にもつながります。最終的には、HDFSのフラッシュを減らすことは、バックグラウンドで走るコンパクションを減らすことにもなります。すなわち、読み書きのパフォーマンスを阻害する要因を減らすことができます。このように、インメモリコンパクションはシステム全体を速くすることができます。
現在、Accordionは、basicとeagerという、2つレベルのインメモリコンパクションを提供しています。basicはすべての更新パターンに適した一般的な最適化を適用します。eagerは、同じキーに対して頻繁に更新をかけるユースケースに最適です。例えば、プロデューサー・コンシューマーキューやショッピングカート、共有カウンタなどです。ただし、eagerは計算オーバヘッド(メモリコピーやGCの増加)があり、書き込み量の多いユースケースではレスポンスタイムに影響する可能性があります。
Accordionの使い方
インメモリコンパクションのレベルは、グローバルにも設定できますし、カラムファミリ毎にも設定できます。サポートされているレベルはnoneとbasicとeagerです。
デフォルトではbasicが適用されます。グローバルな設定は以下のようにhbase-site.xmlで変更することができます。
<property>
<name>hbase.hregion.compacting.memstore.type</name>
<value><none|basic|eager></value>
</property>
以下のように、カラムファミリ毎にHBase shellで設定できます。
create ‘<tablename>’, {NAME => ‘<cfname>’, IN_MEMORY_COMPACTION => ‘<NONE|BASIC|EAGER>’}
Accordionの仕組み
High Level Designについて
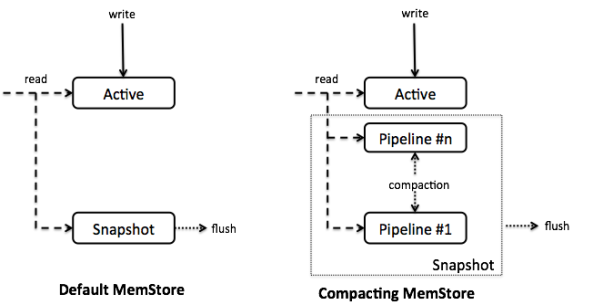
Accordionは、MemStoreの実装のCompactingMemStoreを導入しました。これは内部的にインメモリコンパクションを実行する実装になっています。すべてのデータを一つのデータ構造に格納するデフォルトのMemStoreとは違い、Accordionはデータを一連のセグメントとして管理します。一番、若いセグメントはActiveセグメントと呼ばれ、ミュータブルとなっていて、直近のputが格納されます。そして、Activeセグメントがオーバフロー(デフォルトで32MB。最大でMemStoreサイズの25%)したら、Activeセグメントはインメモリのパイプラインに移動しイミュータブルになります。これはインメモリフラッシュと呼ばれます。Getするときには、これらのセグメントとHFile(通常はBlockCache経由)をスキャンします。
CompactingMemStoreは定期的に複数のイミュータブルなセグメントをバックグラウンドでマージします。
フラッシュが発生すると、パイプライン内のすべてのセグメントがスナップショットに移動され、マージされ、新しいHFileに書き出されます。
下記の図は、デフォルトのMemStoreとCompactingMemStoreの構造を比較したものです。
セグメントのデータ構造について
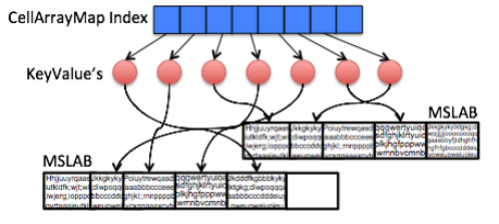
キーで高速に検索するために、デフォルトのMemStoreと同様にCompactingMemStoreはCellストレージの上にインデックスを持ちます。従来ではこのインデックスはJavaのスキップリスト(ConcurrentSkipListMap)で実装されていました。これは動的に追加/削除できるのですが、小さなオブジェクトを管理するには少し無駄の多いデータ構造です。CompactingMemStoreでは、イミュータブルなセグメントのインデックスとして、容量効率の良いフラットな構造を使います。この最適化により、冗長なデータがほとんど無い場合でも、メモリオーバヘッドを減らすことができます。セグメントがパイプラインに追加されたら、そのインデックスはCellArrayMapと呼ばれる配列に格納され、高速な二分探索が可能な状態になります。
CellArrayMapは、JavaヒープからのCellの直接割り当てと、MSLABからのカスタム割り当て(オンヒープまたはオフヒープ)の両方をサポートします。下記の図はCompactingMemStoreのセグメントのデータ構造を示しています。CellArrayMap自体は常にヒープ上に割り当てられます。
現在は、このCellArrayMapを使うことがデフォルトになっていますが、よりメモリ効率の良いCellChankMapを使った実装も進んでいるようです。将来的にはこちらがデフォルトになるようです。

詳細は以下をご覧ください。
https://issues.apache.org/jira/browse/HBASE-16421
インメモリコンパクションのアルゴリズムについて
前節で説明したとおり、パイプライン内のセグメントの上に単一のフラットなインデックスを構築します。 これはディスクのスペースを節約するので、特に1つのデータが小さい場合に、ディスクへのフラッシュの頻度を減らすことができます。(ConcurrentSkipListMapと比較して)一つのインデックスを検索するだけで済むので、テイルレイテンシー(レイテンシの99%点)の向上につながります。
Activeセグメントがメモリにフラッシュされると、コンパクションパイプラインにキューイングされ、バックグラウンドのマージタスクが直ちにスケジュールされます。インメモリコンパクションでは(ディスク上のコンパクションと同様に)パイプライン内のすべてのセグメントを同時にスキャンし、それらのインデックスを1つにマージします。コンパクション・ポリシーのbasicとeagerの違いは、Cellデータをどのように扱うかにあります。basicでは、物理的なコピーを避けるために、冗長なバージョンを削除しません。KeyValueオブジェクトの参照を並べ替えるだけです。対して、eagerは、データの重複を除外します。これは、余分な計算とデータ移行を犠牲にして行われます。たとえば、MSLABストレージでは、残っているCellは新しく作成されたMSLABにコピーされます。このオーバーヘッドがあるため、データが非常に重複する場合にのみメリットがあります。
将来的には、basicとeagerのコンパクションの実装が自動的に選択されるようしたいようです。例えば、eagerコンパクションをしばらく試行して、除外したデータの割合によって次のコンパクションポリシーをスケジュールするような感じです。このようにすることで、システム管理者が最初にコンパクションポリシーを選ばなくてよくなり、アクセスパターンの変化にも対応できるようになります。
Accordionのパフォーマンスについて
ここからは、パフォーマンスについて説明します。ここでの内容は以下の資料から抜粋したものです。
https://www.slideshare.net/HBaseCon/accordion-apache-hbase-beathes-with-inmemory-compaction
環境のセットアップは以下です。ワークロードはYCSBを使ったようです。

まずは書き込みのスループットについてですが、100GBのデータセットで、100%の書き込みワークロードで、一つのデータサイズは100B、そして各書き込みは一つのカラムに対してのみ行っています。書き込みのスループットは以前と比べて10〜40%くらいは向上しているように見えます。

次に、シングルキーの書き込みレイテンシについてですが、これも100GBのデータセットで、100%の書き込みワークロードで、一つのデータサイズは100Bでのテストです。こちらに関しても全体的に多少の改善があるように思います。

そして、シングルキーの読み込みのレイテンシです。こちらは、30GBのデータセットで、50%ずつの書き込み・読み込みワークロード、一つのデータサイズは100Bでのテストです。中央値や75%点では改善があるようですが、なぜか95%点や99%点でレイテンシが上がってしまってるようです。

最後にパフォーマンスではないですが、ディスク容量についても期待通り減少していることがわかります。

さいごに
このインメモリコンパクションはHBase2.0でGAになる予定です。現在進行中のものとしては、本文中にもあったCellChanMap Indexとオフヒープサポートになります。
参考
https://issues.apache.org/jira/browse/HBASE-14918
https://blogs.apache.org/hbase/entry/accordion-hbase-breathes-with-in
https://blogs.apache.org/hbase/entry/accordion-developer-view-of-in
https://yahooresearch.tumblr.com/post/161742308886/hbase-goes-fast-and-lean-with-the-accordion
https://www.slideshare.net/HBaseCon/apache-hbase-accelerated-inmemory-flush-and-compaction
https://www.slideshare.net/HBaseCon/accordion-apache-hbase-beathes-with-inmemory-compaction