何万行にも及ぶApacheのアクセスログを Excelに読み込んでグラフを作っている 現場って意外と多いのではないでしょうか。R言語(以下、「R」)を使って、もっとスマートな方法で解析してみましょう。
本稿では、 1分間ごとのChromeブラウザからのアクセスをヒストグラムとして描画し、最大アクセス数とその時刻を求める ことを目標とし、Rを使用する上で必要な入門知識と構築手順、Apacheのアクセスログを解析するための処理について紹介します。
確認した動作環境
- OS: macOS Sierra 10.12.5
- プロセッサ: 1.2 GHz Intel Core m3
- メモリ: 8 GB 1867 MHz LPDDR3
なぜRは統計解析に強いのか
そもそも他のプログラミング言語と比較して、なぜRが統計解析に強い と言われているのでしょうか。主な理由は以下の通りです。
- 統計解析に特化した プログラミング言語である
- 配列(Rでは「ベクトル」と表現する)処理を前提としているため、 基本的にfor文が不要 である
- 統計分析のためのライブラリが充実している
RとPythonとの違いについて
Rと同じく統計解析に強いと言われているのが、 機械学習で注目を集めている汎用言語 Python です。以下は各言語について、それらが得意とする分野をまとめたものです。
| R | Python |
|---|---|
| 統計解析に特化したインタラクティブな処理 | 統計解析以外の機能と連携した多様な処理 |
| 都度異なるアルゴリズムによるルーティン化しにくい解析 | 毎度同じアルゴリズムによるルーティン化しやすい解析 |
| ローカル環境での処理 | サーバー環境での処理 |
今回は対象とするApacheのアクセスログを 様々な角度から解析したい ため、R言語を採用しました。
Rの実行環境を構築する
Rをインストールする
それではRをインストールしましょう。Rの公式ウェブサイトであるR for Mac OS XからR-x.x.x.pkg(x.x.xはバージョン番号。本稿執筆時点の最新版は3.4.2)をダウンロードし、インストールします。
インストールが完了したら、ターミナルを起動して以下のコマンドを入力します。
$ r
R version 3.4.2 (2017-09-28) -- "Short Summer"
Copyright (C) 2017 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin15.6.0 (64-bit)
上記のような出力が表示され、インタラクティブモードが開始されます。
続いてサンプルデータとしてデフォルトで定義されている月間旅客機乗客数データAirPassengersのグラフを描画するため、以下のコマンドを入力します。
> plot(AirPassengers)
コマンドを実行するとXQuartzが起動し、以下のような図が描画されます。

インタラクティブモードを終了するには、以下のコマンドを入力します。
> q()
Save workspace image? [y/n/c]: n
統合開発環境「RStudio」をインストールする
「RStudio」は以下のような機能を有するオープンソースの統合開発環境(IDE)であり、Rによる解析をサポートしてくれるツールです。
- コード補完
- バージョン管理
- デバッグ
- 変数ビューア
- グラフ描画
RStudioの公式配布先であるDownload RStudio – RStudio へアクセスし、「RStudio Desktop Open Source License」を選択します。
表示されたインストーラーから、RStudio x.x.x - Mac OS X 10.6+ (64-bit)(x.x.xはバージョン番号。本稿執筆時点の最新版は1.1.383)をクリックし、ダウンロードします。
ダウンロードしたdmgファイルを起動することでインストールが開始されます。
グラフィック作成パッケージ「ggplot2」をインストールする
Rのインタラクティブモードから以下のコマンドを入力し、 ヒストグラムをプロットするために必要な グラフィック作成パッケージ「ggplot2」 をインストールします。
> install.packages("ggplot2")
コマンドを実行すると、以下のようなメッセージが表示されます。
--- このセッションで使うために、CRAN のミラーサイトを選んでください ---
Secure CRAN mirrors
1: 0-Cloud [https] 2: Algeria [https]
3: Australia (Canberra) [https] 4: Australia (Melbourne 1) [https]
...
...
35: Italy (Padua) [https] 36: Japan (Tokyo) [https]
...
...
CRAN (Comprehensive R Archive Network) とは、R本体や各種パッケージをダウンロードするためのミラーサイトです。本稿では日本国内のミラーサイトからダウンロードするため、36を入力します。入力が完了すると、インストールが開始されます。
Selection: 36
Apacheのダミーログを生成する
Rの環境構築が完了したら、次は解析対象とするデータを用意します。実際にApacheから出力されているログを使用してもよいですが、本稿ではダミーログを生成し、それを解析対象とします。
「apache-loggen」をインストールする
以下のコマンドを入力し、Ruby用のパッケージ管理システム「RubyGems」からApacheのダミーログを生成してくれるツール「apache-loggen」をインストールします。
$ sudo gem install apache-loggen -N
ここで、-Nはドキュメントのダウンロードを不要とするオプションです。
以下のように表示されればOKです。
Successfully installed apache-loggen-0.0.4
1 gem installed
ダミーログを生成する
それでは、apache-loggenを使用してダミーログを生成しましょう。apache-loggen -hコマンドを入力すれば、apache-loggenのヘルプを参照することができます。
$ apache-loggen -h
Usage: apache-loggen [options]
--limit=COUNT 最大何件出力するか。デフォルトは0で無制限。
--rate=RATE 毎秒何レコード生成するか。デフォルトは0で流量制限無し。
--rotate=SECOND ローテーションする間隔。デフォルトは0。
--progress レートの表示をする。
--json json形式の出力
任意のディレクトリ(本稿では~/dev/r/)へ移動し、以下のコマンドを入力します。
ここでは「毎秒10レコード、30分間」のログを生成するため、--limit=18000(60 [秒] × 30 [分] × 10 [レコード/秒] =18000 [レコード])を設定しています。
apache-loggen --limit=18000 --rate=10 --progress test.log
apache-loggenで出力されるログのタイムスタンプは「端末のシステム時間」であり、 30分間のログが必要であれば生成完了まで30分かかる ため、ここは少し辛抱しましょう。
- GitHub - tamtam180/apache_log_gen: generate dummy apache log.
- Rubygemsのススメ | Rubyに慣れていない初心者さんへ - Qiita
- apache-loggen を使って Apache アクセスログのダミーログを生成する - ようへいの日々精進XP
- "apache-loggen"でダミーのアクセスログを作成する | cloudpack.media
Rの処理について
解析を始めるにあたり、Rにおける基本的な処理と データの種類 を理解する必要があります。
Rにおける変数への代入と参照
Rでは代入演算子<-を用いて変数へ代入します。以下は変数xに数値1を代入する例です。
x <- 1
変数名を入力することで、変数の中身を参照することができます。
x
[1] 1
Rで扱うデータの種類
ベクトル
同じ型の要素を 1つの行または列 にまとめたオブジェクトです。
ベクトルの生成
> c(1.0, 2.0, 3.0, 4.0, 5.0)
[1] 1 2 3 4 5
行列
行と列を持つ2次元配列のオブジェクトです。
行ベクトルを結合する
> rbind(c(1,2,3), c(4,5,6))
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
列ベクトルを結合する
> cbind(c(1,2,3),c(4,5,6))
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
要素へアクセスする
> x <- cbind(c(1,2,3),c(4,5,6))
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> x[1,]
[1] 1 4
> x[,1]
[1] 1 2 3
> x[1,1]
[1] 1
-
x[m,]: m行目の行ベクトルを抽出します。 -
x[,n]: n列目の列ベクトルを抽出します。 -
x[m,n]: m行n列目の要素を抽出します。
リスト
要素数が異なる複数のベクトルをまとめたオブジェクトです。
リストを生成する
> x<-list(c("a", "b"), c(1, 2, 3))
> x[1]
[[1]]
[1] "a" "b"
> x[[1]]
[1] "a" "b"
-
x[1]: 第1成分の リスト を抽出します。 -
x[[1]]: 第1成分の 要素 (上記の例ではベクトル)を抽出します。
データフレーム
data.frameクラスを持つリストであり、異なる型のベクトルをまとめたオブジェクトです。 各行、各列はラベルを必ず持っており 、ラベルを指定した操作が可能です。
データフレームを生成する
> sex <- c("F","F","M","M","M")
> height <- c(158,162,177,173,166)
> weight <- c(51,55,72,57,64)
> x <- data.frame(SEX=sex, HEIGHT=height, WEIGHT=weight)
> x
SEX HEIGHT WEIGHT
1 F 158 51
2 F 162 55
3 M 177 72
4 M 173 57
5 M 166 64
> x$HEIGHT
[1] 158 162 177 173 166
-
x$label:labelで指定した列のベクトルを抽出します。
Apacheのアクセスログを解析する
ようやく全ての準備が整ったので、RでApacheのアクセスログを解析してみましょう。RStudioを起動し、Consoleペインからコマンドを入力していきます。以下ではそれぞれのコマンドについて順を追って説明します。
ロケールを変更する
Rで使用するロケールをen_US.UTF-8に変更します。
Sys.setlocale("LC_ALL", "en_US.UTF-8")
本環境のロケールはデフォルトで日本語形式ja_JP.UTF-8となっていました。一方、 Apacheのログで出力されるタイムスタンプは英語形式(例:03/Nov/2017:12:34:05)である ため、ロケールを英語形式en_US.UTF-8に変更する必要があります。
Apacheのアクセスログを読み込む
ファイルを読み込む
以下のコマンドを入力し、Apacheのアクセスログを読み込みます。
d <- read.table("~/dev/r/test.log", quote="\"", fill = TRUE)
-
read.table(file):fileで指定された表形式のテキストファイルを読み込み、データフレームとして返却します。-
quote: 文字列の引用符を設定します。Apacheのアクセスログは"GET /category/books HTTP/1.1"のように引用符として"が使われているため、\"を指定します。 -
fill:TRUEを設定すると、欠損のある(1行に含まれる列数が各行で異なる)要素にNA(欠損値)を代入して読み込み処理を継続します。オプションを指定しなかった場合は処理を中止してエラーを出力します。
-

文字列を「年月日時分秒」オブジェクトに変換する
d$V4 <- strptime(d$V4, "[%d/%b/%Y:%H:%M:%S")
-
strptime(x, format): 「年月日時分秒」を表す形式formatで表現された文字列ベクトルxを、「年月日時分秒」を表すPOSIXltオブジェクトのベクトルに変換します。データフレームdの文字列ベクトルd$V4は[03/Nov/2017:12:34:05のような形式であるため、formatに[%d/%b/%Y:%H:%M:%Sを指定します。
- read.table function | R Documentation
- read.table()によるテキストファイルの読み込み - jnobuyukiのブログ
- strptime function | R Documentation
- 日付、時間関数Tips大全 - RjpWiki
特定のユーザーエージェントからのアクセスを抽出する
本稿ではChromeブラウザからのアクセスのみを解析対象とするため、データフレームdから、ユーザーエージェントにChromeが含まれる行のみを抽出します。また EdgeのエージェントにもChromeが含まれている ため、Edgeが含まれない行も検索条件に加えます。
dChrome <- subset(d, grepl("Chrome", d$V10))
dChrome <- subset(dChrome, !grepl("Edge", dChrome$V10))
-
grepl(pattern, x): 正規表現による検索条件patternと一致した文字列ベクトルxの論理型ベクトルを返却します。ユーザーエージェントはデータフレームdのV10列に格納されているため、V10ベクトルからChromeが含まれるものを検索条件としています。 -
!: 論理型ベクトルの否定(TRUEとFALSEを逆にしたもの)を返却します。 -
subset(x, subset): データフレームxからsubsetで指定された条件に一致した要素のみを抽出したものを返却します。
- grep function | R Documentation
- subset function | R Documentation
- 【R】Rのsubsetで文字列の検索を掛ける方法 - Qiita
- 使用してるブラウザを判定したい - Qiita
- ! grep in R - finding items that do not match - Stack Overflow
ヒストグラムを描画する
ヒストグラムを生成する
以下のコマンドを入力し、ヒストグラムを生成します。
library("ggplot2")
histChrome <- qplot(V4, data = dChrome, geom = "histogram", binwidth = 60)
-
library(package):packageで指定されたパッケージを読み込みます。 -
qplot(x):xで指定された列のグラフィックオブジェクトを生成します。-
data: データフレームを指定します。 -
geom: グラフィックオブジェクトの種類を指定します。 -
binwidth: 描画するヒストグラムのbin幅を 秒単位 で指定します。
-
特定の時間内のヒストグラムを抽出する
以下のコマンドを入力し、特定の時間内のヒストグラムを生成します。
histChrome = histChrome + xlim(c(as.POSIXct("2017-11-03 12:40:00", format="%Y-%m-%d %H:%M:%S"),
as.POSIXct("2017-11-03 13:00:00", format="%Y-%m-%d %H:%M:%S")))
-
xlim(): グラフィックオブジェクトから、ベクトルで指定したx軸の範囲を抽出します。 -
as.POSIXct(x):xで指定した文字列をPOSIXct型の数値に変換します。-
format:xで指定した文字列のフォーマットを指定します。
-
ヒストグラムを描画する
以下のコマンドを入力し、ヒストグラムを描画します。
print(histChrome)
-
print(x):xで指定したオブジェクトを出力します。

- print function | R Documentation
- r - How to adjust time scale axis for ggplot histogram - Stack Overflow
- ggplot2のqplot関数のまとめ - ぬいぐるみライフ?
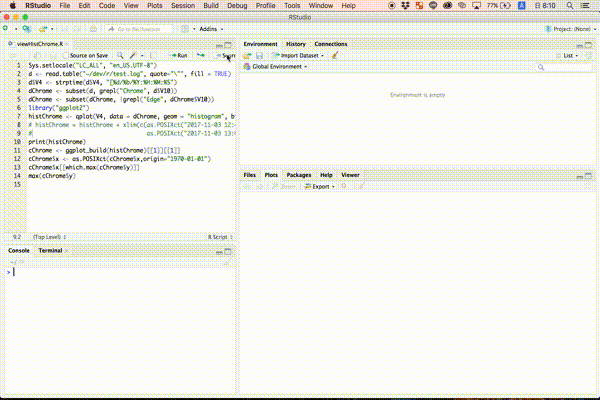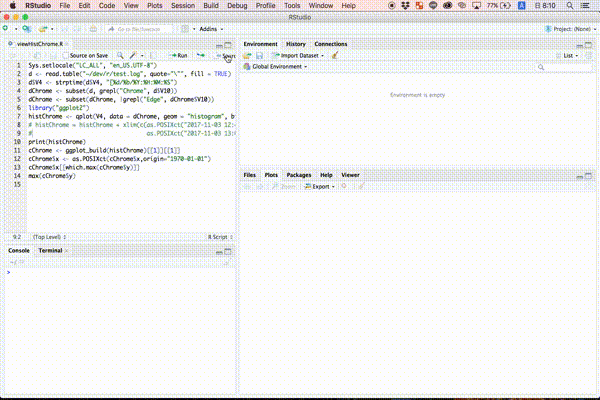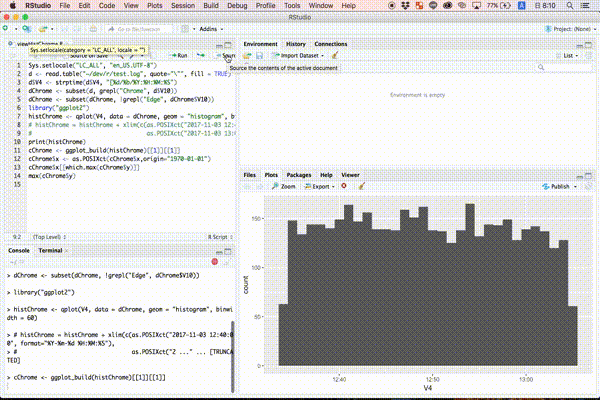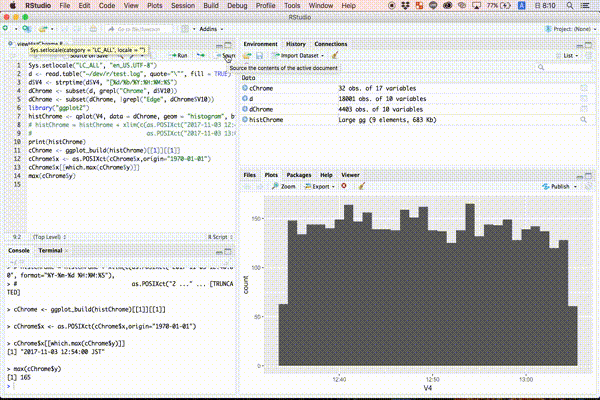
ヒストグラムから最大アクセス数とその時刻を求める
以下のコマンドを入力し、ヒストグラムの最大値を出力します。
cChrome <- ggplot_build(histChrome)[[1]][[1]]
cChrome$x <- as.POSIXct(cChrome$x,origin="1970-01-01")
cChrome$x[[which.max(cChrome$y)]]
max(cChrome$y)
-
ggplot_build(plot):plotで指定したグラフィックオブジェクトのデータが格納されたリストを返却します。x軸とy軸のデータが格納されたデータフレームへは[[1]][[1]]でアクセスできます。 -
as.POSIXct(x): 数値xをPOSIXct型のDate-Timeオブジェクトに変換します。-
origin: 基準とする時刻を指定します。
-
-
which.max(x): ベクトルxの最大値の行番号を返却します。 -
max(x): 列ベクトルxの最大値を返却します。
> cChrome$x[[which.max(cChrome$y)]]
[1] "2017-11-03 12:54:00 JST"
> max(cChrome$y)
[1] 165
上記のような結果がコンソールに出力されます。本稿で使用したデータでは、2017年11月3日12時40分〜13時00分の間におけるChromeブラウザからのアクセスは以下であることが分かりました。
- 1分間あたりの最大アクセス数: 165 [アクセス/分]
- 最大アクセスのあった時刻: 2017年11月3日 12時54分
- ggplot_build function | R Documentation
- which.min function | R Documentation
- as.POSIX* function | R Documentation
- Extremes function | R Documentation
- RのPOSIXct的な数値からdate-time objectを作る | あすき備忘録
- r - ggplot2 find number of counts in histogram maximum - Stack Overflow
R Scriptで処理を実行する
これまではRStudioのコンソールからコマンドを入力して処理を実行してきましたが、Rでは「R Script」と呼ばれるスクリプトを使用することも可能です。以下のviewHistChrome.Rは、これまでの処理を一つのスクリプトにまとめたものです。(本稿では、Apacheのログファイルと同じパス ~/dev/r/に保存しています。)
~/dev/r/viewHistChrome.R
Sys.setlocale("LC_ALL", "en_US.UTF-8")
d <- read.table("~/dev/r/test.log", quote="\"", fill = TRUE)
d$V4 <- strptime(d$V4, "[%d/%b/%Y:%H:%M:%S")
dChrome <- subset(d, grepl("Chrome", d$V10))
dChrome <- subset(dChrome, !grepl("Edge", dChrome$V10))
library("ggplot2")
histChrome <- qplot(V4, data = dChrome, geom = "histogram", binwidth = 60)
histChrome = histChrome + xlim(c(as.POSIXct("2017-11-03 12:40:00", format="%Y-%m-%d %H:%M:%S"),
as.POSIXct("2017-11-03 13:00:00", format="%Y-%m-%d %H:%M:%S")))
print(histChrome)
cChrome <- ggplot_build(histChrome)[[1]][[1]]
cChrome$x <- as.POSIXct(cChrome$x,origin="1970-01-01")
cChrome$x[[which.max(cChrome$y)]]
max(cChrome$y)
RStudioからR Scriptを実行する
-
File > Open Fileから~/dev/r/viewHistChrome.Rを選択します。 -
SourceペインからSource > Source with Echoを選択すると、スクリプトを実行することができます。
RのコンソールモードからR Scriptを実行する
ターミナルからRのコンソールモードを開始し、以下のコマンドを入力することでスクリプトを実行することができます。
$ r
> source("~/dev/r/viewHistChrome.R")
- 14. R の入出力画面を経由せずに実行:他のプログラムからの呼び出し | Rプログラム (TAKENAKA's Web Page)
- コマンドラインではグラフが描画されるのにスクリプトファイルでは描画されない: Golden State
ターミナルからR Scriptを実行する
以下のコマンドを入力することでターミナルからスクリプトを直接実行することができます。ただし XQuarzが起動しないため、グラフィックを描画することはできません。
$ rscript viewHistChrome.R
まとめ
Rを使うのは今回が始めてでしたが、 必要な環境を簡単に構築することができ、また言語の学習コストがとても低い ことを実感しました。プログラマーでなくても比較的簡単に使えるようになるのではないでしょうか。本稿で紹介した解析はかなり単純なものでしたが、それでも たった14行で処理を記述できるのは驚きです。何万行にも及ぶデータをExcelで解析することははっきり言って 時代遅れ です。皆さんもRを使ってスマートに解析しましょう!

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。