- 論文
- 日本語情報
サマリ
- 環境の遷移そのものを予測するのではなく、VAEの潜在空間の遷移をRNNで予測するという形で、環境モデルを学習
- 学習された環境モデルをシミュレータとして用いて強化学習することもできる
感想
- 連続空間上の遷移に対する強化学習にのみ使える? mixture of Gausian distribution とか仮定してるし。
Introduction
- RLには小さなネットワークしか使われていない。大きなRNNは計算大変。
- Agentを、大きな world model と小さな controller model に分割することで実現するというアイデアを提唱
- まず、教師なし学習の枠組みで、大きな world model を学習
- 次に、学習した world model を用いて controller model を学習
- これにより、controler model は小さな探索空間上でpolicyを学べばよくなる
- RNN-based な model-based reinforcement learning
- Agentを、大きな world model と小さな controller model に分割することで実現するというアイデアを提唱
Agent Model
- Vision(V), Memory(M), Controller(C) の3つのコンポーネントから成る
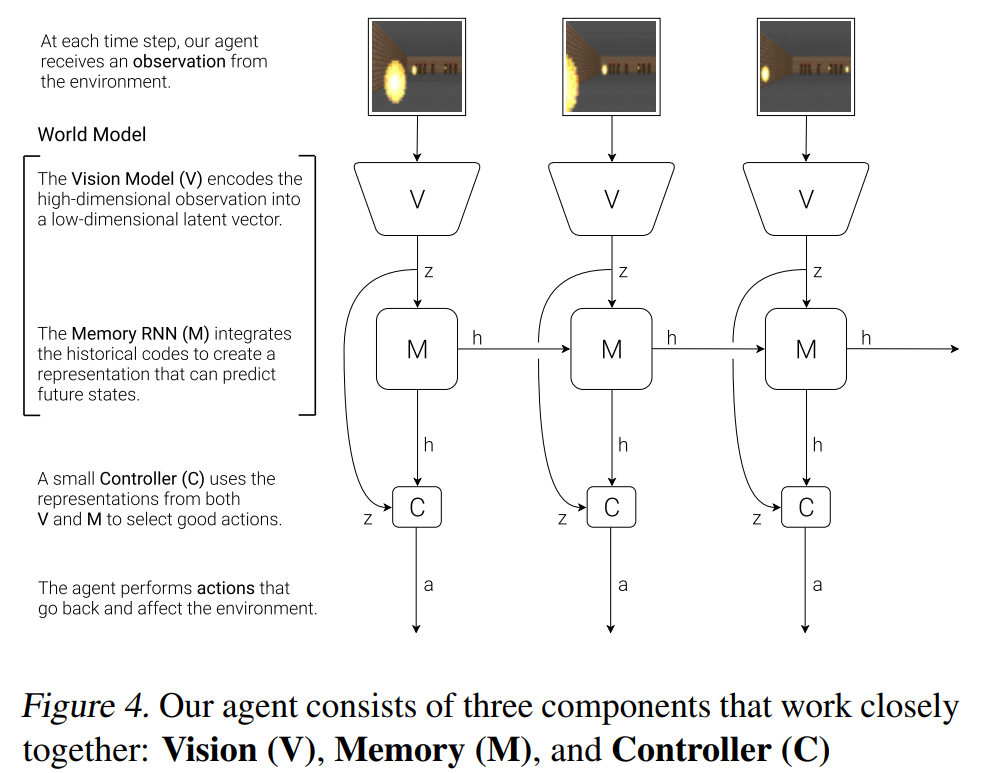
- それぞれのコンポーネントについて説明した後、Agent Model 全体について改めて説明する
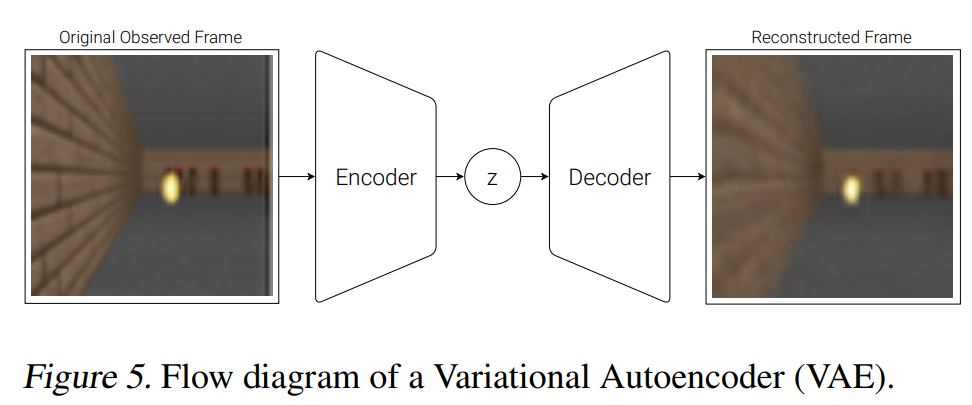
VAE(V) Model
- V の役割は、高次元な入力を抽象的な表現に圧縮すること
- 今回はシンプルなVAEを用いた
MDN-RNN(M) Model
- M の役割は、未来を予測すること
-
V によって抽象化された z に対して未来を予測する
- z を直接当てに行くのではなく、p(z) を当てに行く。自然環境は複雑であり遷移は確率的だから。
- mixture of Gaussian distribution で p(z) を近似。結局、Mixture Density Network として知られる MDN-RNN の枠組み
- MDN-RNN https://arxiv.org/abs/1704.03477
- ちゃんと読めてないが、多分、τは学習時は1で適用時に選択するパラメタだと思う
- z を直接当てに行くのではなく、p(z) を当てに行く。自然環境は複雑であり遷移は確率的だから。
Controller(C) Model
- C の役割は、rolloutしたときの期待累積報酬が最大となるような行動を決定すること

-
C は可能な限りシンプルかつ小さくした
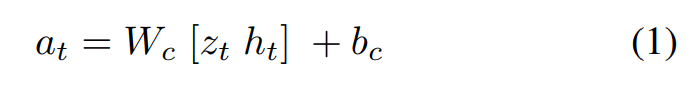
Putting V, M, and C Together
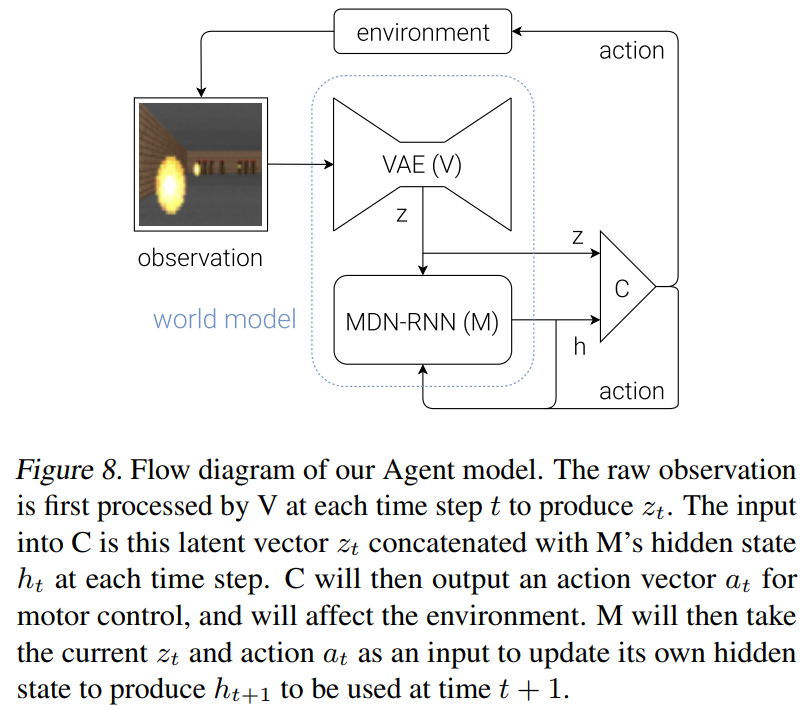
- V や M はGPUで backpropagation を用いて学習
-
C は Covariance-Matrix Adaptation Evolution Strategy(CMA-ES)を用いてCPUで並列処理して学習
- CMA-ESについての日本語参考情報: http://satuma-portfolio.hateblo.jp/entry/2017/12/09/025009
- V, M, C はそれぞれ別々に学習される
Car Racing Experiment
- 学習手順は論文中の下記サマリの通り

-
V だけから C を決めることも原理的には当然できる
- でも M を入れないと急カーブ曲がれない
- (個人感想)そりゃあそうだろう。V は1フレームの情報だけで、スピードとかの情報持たないわけだから。と思ったけど、それでもA3Cより良いのか。
- 下表のように、M を入れた Full World Model にすると Gym Leaderboard を超えた

- あとは、VAEで画像を復元した結果を見たりしている(Dreams)
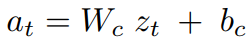
VizDom Experiment
- Dreams から学習してみた。つまり、Cの学習の際に、実環境ではなく M を利用
- 学習手順は論文中の下記サマリの通り

- 注意点として、Dreams から学習するためには、M は $ z_{t+1} $ を当てるだけでなく、エピソードが終了かどうか ($ done $) も当てる必要がある。
- (個人感想) $ done $ は連続値じゃなくて0/1だけど、混合正規分布を仮定で良いのだろうか
- Dreams で C を学習する時はzとhがあればよいので、C の学習には V を使う必要がない
-
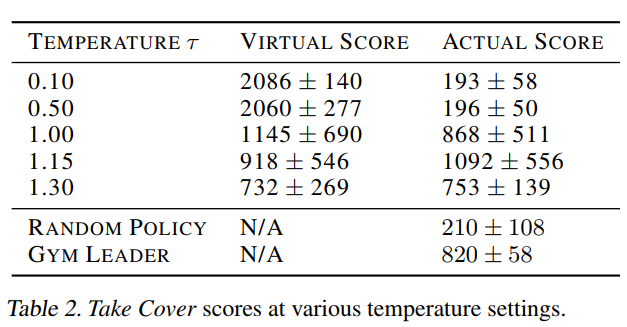
Dreams で学習する時はτを高くする必要がある。なぜなら、Dreamsに対してAdverasarialなpolicyを学習してしまう可能性があるが、Dreams と Real は完全に同じではないから。つまり、Dreams が Realを再現できていないゆえに有効な、変なpolicy(Cheating)を学習してしまうと、Realで同じpolicyを用いてもうまくいかない
- この話は Model-based RL の世界では長らく問題である。決定的ではなくBayesianなModelを用いたPILCOでは少し解決されているが完ぺきではない。今の主流は、Model-basedな方法でpolicyをpre-trainして、Real でModel-freeな方法でpolicyをfine-tuneすることだ
- τを変えて実際に実験した結果が下表。わかりやすい
Iterative Training Procedure
- 枠組みとしては以下のようになるはず

- World Modelの改善にとって有用なデータをReal Worldから取得する必要があるが、そのためには、Mは次のactionやrewardまで予測しないといけない。これはなかなかハードなタスクだ。
- (個人感想)VizdoomでDreamsから学習した時にこれらが不要なのは何故だっけ?確定的なrewardにしたから?だとしたらこれは Iterative Training だからという話ではなく、単により汎用的にするためにはという話?
Discussion
あとでかく