はじめに
Elasticsearchといえば検索エンジン!ということは知っていましたが、Analyzer(アナライザー)って何?どうやって使うの?からスタートした話です。
ここでは、Analyzerが何者で何をやっているのかをざっくりまとめてました。
Analyzer?
全文検索を行うために文章を単語の単位に分割する処理を、アナライザーと呼ぶ。
だそうです。以下、とある文章をとあるアナライザーで処理してみるとこうなります。
とある文章
人が恋に落ちるのは万有引力のせいではない。Albert Einstein(アルベルト・アインシュタイン)1879年 - 1955年
とあるアナライザー処理後
人 恋 落ちる 万有引力 せい albert einstein アルベルト アインシュタイン 1879 年 1955 年
確かに単語で分割されていますね。
それでは、どうしてこのようになるのか。ElasticsearchのAnalyzerでは何が行われているのかを見ていきたいと思います。
Analyzerの構成要素
Analyzerは、3つのブロックから構成されています。
矢印の順番にテキストが処理されていきます。
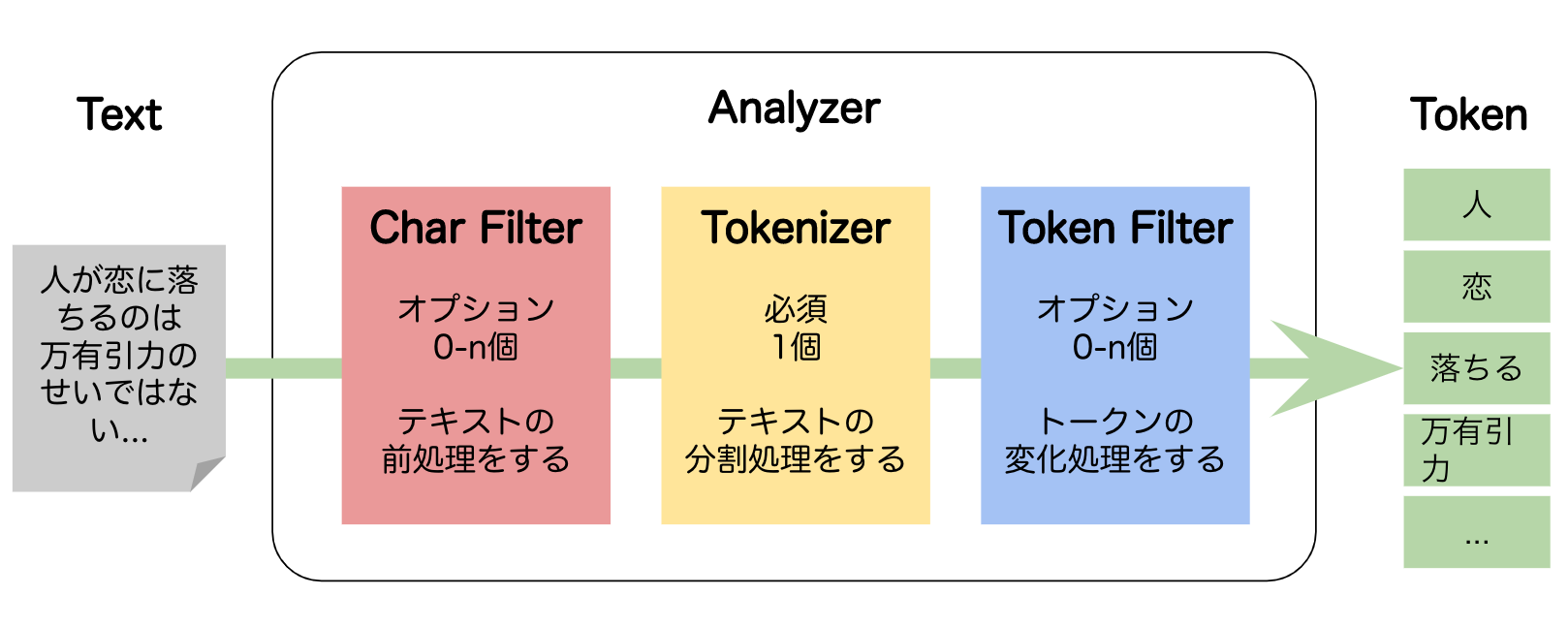
Char Filter
入力されたテキストの前処理をするフィルタ機能です。インプットもアウトプットもテキストです。
ビルトインは3種類あります。
オプションなので、必要がなければ設定しなくてもかまいません。
HTML Strip Character Filter
HTMLフォーマットを除去。見やすくなりました。
ここは<b>太字</b>です。 -> ここは太字です。
Mapping Character Filter
特定文字をルールに基づいて変換。 絵文字とかの変換に使えそうです。
:) -> _happy_
Pattern Replace Character Filter
定義されたルールに基づいて変換。 フォーマットの統一にいいですね。
2019/01/01 -> 2019-01-01
Tokenizer
テキストの分割処理を行い、トークン(単語)の列を生成します。インプットはテキストでアウトプットは単語です。
ビルトインは多くありますが、大きくカテゴリ分けして3種類あります。
ひとつのAnalyzerに一つ設定をしてください。
単語分割系
テキストを単語に分割。
Big Dog! -> Big Dog
N-gram系
連続したn個の文字で分割。こちらは2-gramです。
Big Dog! -> Bi ig gd do og
構造化テキスト分割系
メールアドレス、URL、ファイルパスなどの構造化したテキストを分割。
メアドなど分割して欲しくない項目には良さそうです。
uax_url_email使用)my email is boutan@email.com -> my email is boutan@email.com
standard使用) -> my email is boutan email.com
Token Filter
分割したトークンに対して、トークン単位で変換処理を行うもの。インプットもアウトプットも単語です。
ビルトインは多くありますが、代表的なもの4つ紹介します。
オプションなので、必要がなければ設定しなくてもかまいません。
Lowercase Token Filter
全て小文字にする。
Big Dog -> big dog
Stop Token Filter
ストップワードの除去。英語だと「the」「a」「for」などが挙げられます。
this is a pen -> pen
Stemmer Token Filter
ステミング(語幹処理)を行う。これは英語用ですが、別途プラグインで日本語に対応したものもあります。
making, maked -> make
Synonym Token Filter
類義語を正規化して1つの単語にします。これは各自での定義する必要があります。
どのワードできても、同じ単語で扱いたい時に便利ですね。
ipod, i-pod, i pod => ipod
卵, 玉子, たまご
Analyser検証
Analyserを通すとどのように返却されるかを見てみましょう。
インデックスを作成
サンプルなので、ざっくりとした設定をしました。トークンナイザーにはkuromojiを使用しています。
PUT /my_index_name
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"icu_normalizer",
"kuromoji_iteration_mark"
],
"tokenizer": "kuromoji_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"cjk_width",
"stop",
"ja_stop",
"kuromoji_number",
"kuromoji_stemmer"
]
}
}
}
},
"mappings": {
"properties": {
"sample_text": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}
検証してみる
explainをtrueにすると、詳細なレスポンスがみれます。textには検証したいテキストを入れてみます。
GET my_index_name/_analyze
{
"explain": false,
"text": "人がは<b>恋に落ちるは</b>のは万有引力のせいではない。Gravitation can not be held responsible for people falling in love. Albert Einstein(アルベルト・アインシュタイン)1879年 - 1955年",
"field": "sample_text"
}
レスポンス
{
"tokens" : [
{
"token" : "人",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "恋",
"start_offset" : 6,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "落ちる",
"start_offset" : 8,
"end_offset" : 11,
"type" : "word",
"position" : 5
},
{
"token" : "万有",
"start_offset" : 18,
"end_offset" : 20,
"type" : "word",
"position" : 9
},
{
"token" : "万有引力",
"start_offset" : 18,
"end_offset" : 22,
"type" : "word",
"position" : 9,
"positionLength" : 2
},
{
"token" : "引力",
"start_offset" : 20,
"end_offset" : 22,
"type" : "word",
"position" : 10
},
{
"token" : "せい",
"start_offset" : 23,
"end_offset" : 25,
"type" : "word",
"position" : 12
},
{
"token" : "gravitation",
"start_offset" : 30,
"end_offset" : 41,
"type" : "word",
"position" : 16
},
{
"token" : "can",
"start_offset" : 42,
"end_offset" : 45,
"type" : "word",
"position" : 17
},
{
"token" : "held",
"start_offset" : 53,
"end_offset" : 57,
"type" : "word",
"position" : 20
},
{
"token" : "responsible",
"start_offset" : 58,
"end_offset" : 69,
"type" : "word",
"position" : 21
},
{
"token" : "people",
"start_offset" : 74,
"end_offset" : 80,
"type" : "word",
"position" : 23
},
{
"token" : "falling",
"start_offset" : 81,
"end_offset" : 88,
"type" : "word",
"position" : 24
},
{
"token" : "love",
"start_offset" : 92,
"end_offset" : 96,
"type" : "word",
"position" : 26
},
{
"token" : "albert",
"start_offset" : 98,
"end_offset" : 104,
"type" : "word",
"position" : 27
},
{
"token" : "einstein",
"start_offset" : 105,
"end_offset" : 113,
"type" : "word",
"position" : 28
},
{
"token" : "アルベルト",
"start_offset" : 114,
"end_offset" : 119,
"type" : "word",
"position" : 29
},
{
"token" : "アインシュタイン",
"start_offset" : 120,
"end_offset" : 128,
"type" : "word",
"position" : 30
},
{
"token" : "1879",
"start_offset" : 129,
"end_offset" : 133,
"type" : "word",
"position" : 31
},
{
"token" : "年",
"start_offset" : 133,
"end_offset" : 134,
"type" : "word",
"position" : 32
},
{
"token" : "1955",
"start_offset" : 137,
"end_offset" : 141,
"type" : "word",
"position" : 33
},
{
"token" : "年",
"start_offset" : 141,
"end_offset" : 142,
"type" : "word",
"position" : 34
}
]
}
htmlタグが除去されていたり英語の大文字が小文字になったり、ストップワードが除去されたりと基本的な変換ができていることが確認できました。
まだまだ改善の余地がありそうな結果ですので、いろんなプラグイン試したいですね!
さいごに
Analyzerと一言でまとめてしまわず、中で何をやっているか少しだけ理解できたと思います。
特に日本語の解析は複雑で、ビルドインだけではうまくいかないことが多いです。
プラグインは多数存在しご紹介しきれませんでしたが、サービスにあったものを選べるようになると楽しくなるでしょう。