どうも、最近夜型に移行しつつある人です
前回こんな記事を書きました
この記事ではあまり言及していなかったのですが**「データをどこまで消すのか」**というのはかなり重要な話題です
ということで今回はこれについて書いていこうと思います
まずはSQLを整理しよう
大前提として、DMLの種類と性質について整理したいと思います
まずは下記の図を見てください
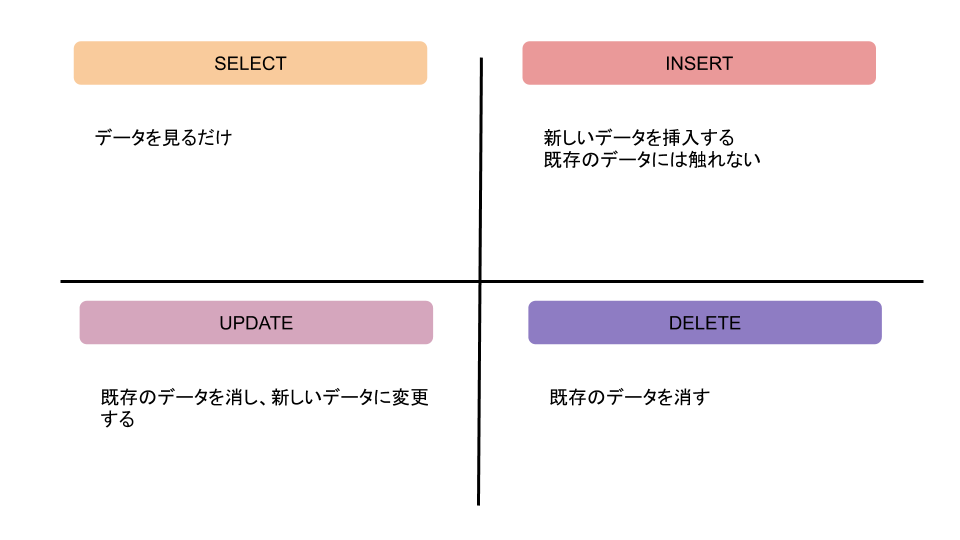
書いてあるとおりですね!
注意点はUPDATEとDELETEは既存のデータを消している、ということです
データをどこまで消すのか、というのは言ってしまえばUPDATEとDELETEをどこで使うのか、という話です
イミュータブルデータモデルとは?
まずは下記の記事を読んでみてください
めっちゃ安直に表現すると「更新日時っておかしくね?」って話です
例えば社員テーブルがあるとした場合、社員テーブルに更新日時があるのっておかしいよね?だから他のテーブルに抽出しよう!って感じです
(厳密に言えばテーブルではなくモデルですが、モデルをそのまま実装するためテーブルとほぼ同義です)
TMでは○○日付と表現できるものはevent、それ以外はresource、という分け方をしていました
※TMの詳細はココで解説してるよ!
つまり、更新日時があるってことはresourceじゃなくてeventかもしれないし、単にresourceの中にeventがある(抽出しきれていない)状態じゃね?ってことです
それでは下記の図を見てみてください
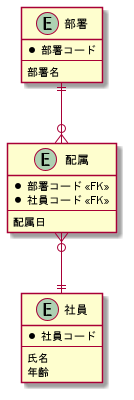
(PlantUML初めて使った…wこれめっちゃ便利)
これ、あるあるな設計だと思います
配属ではINSERTのみを使って、部署、社員ではUPDATE、DELETEを使っているとします
つまり、データを消すテーブルとデータを消さないテーブルが混在していることになります
問題ないように見えますが、実はこれだけだと問題が発生します
今のデータ頂戴!!
ある日のこと
上司「僕くん、ある社員の人の配属日を調べたいから今のデータの一覧出してもらって良い?」
僕「わかりました!部署コードとか社員コードとかもあったほうが良いですよね?」
上司「とりあえず部署名、氏名、配属日が欲しいだけだから部署コード、社員コードはなくていいよ。そんなに人もいないし」
僕「OKっす!」
出力結果は下記のようになりました
| 部署名 | 氏名 | 配属日 |
|---|---|---|
| 営業部 | 佐藤 一郎 | 2020/4/1 |
| 総務部 | 中村 次郎 | 2020/5/1 |
| 人事部 | 鈴木 三郎 | 2020/6/1 |
| ... | ... | ... |
簡単ですね!
僕「できましたよ!」
上司「お、早いね!ありがとう。どれどれ…」
上司「… … …」
僕「どうしました?なんか問題ありました?」
上司「んー、なんか予想と違うというか…」
僕「???」
上司「この営業部の佐藤 一郎くんって最近結婚して苗字変わったんだよね。でも結婚したのは2020年8月だから、この配属日の一覧には旧名が入っていてほしいんだよね。旧名でもう一度一覧出してもらっても良い?」
僕「え?あ… 社員テーブルって多分UPDATEしてますよね?」
上司「そういう設計だね」
僕「そしたら過去のデータは上書きしてるんでデータ無いです。佐藤 一郎さんの分だけ出力結果を修正することはできますが、DBに入ってるデータはいじれないですね…」
上司「あっ(察し)」
僕「今のデータと言えば今のデータですけど…w」
そうなんです!
データを消しているテーブルとデータを消していないテーブルをまとめて扱ってしまうとおかしなことが起こります
何が起こったのか整理してみましょう
先ほどの図をもう一度載せておきます
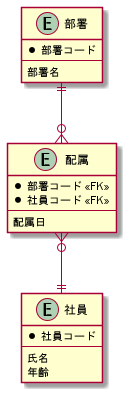
まず、配属はINSERTしかしていないため、過去のデータが全て存在していることになります
そのため、部署コード、社員コード、配属日の紐づけは問題ありません
次に、部署はどうでしょう
部署名が変わったり統廃合があったときにはUPDATEやDELETEが使われるため、過去のデータが無いことがあります
社員も氏名(主に苗字)が変わったり、年齢は誕生日を迎える度に変わっていきます
つまり、UPDATEが使われています
退職するとしたらDELETEが使われるかもしれません
社員も部署と同じく過去のデータを全て保存している訳ではありません
(今回は例として年齢をあげていますが、通常は生年月日等にしたほうが良いです)
FKを使って参照整合性を確保していたとしても、過去データの一覧を取得しようとするときには問題が発生してしまうんですよね…
UPDATE使っちゃダメじゃん!!!
そうなんです、一般の人の感覚でいうとデータは全部保存されていてほしい訳です
Gitでブランチを切って開発を続けたとしても、ブランチ切る前のデータって全部残ってますよね?
でも、UPDATEは全部上書きしてしまいます
UPDATEをするっていうのは本当はめちゃくちゃ気を付けなきゃいけないことなんです!
ここ最近はビッグデータって言葉が流行ったりしてますよね
大きい企業はデータを全部保存しておくのがスタンダードになっている感じがします(実際に中身を見た訳ではないですが、サービスを使っていると更新前のデータが出てきたりする)
前回の記事でも言っていますが、データというのはビジネスをしていくのには不可欠なものです
それを消すって…どれだけ重大なことをしているのか分かった上でUPDATE使ってますか?って話です
データには色々な可能性があります
データを消すというのは、大げさに言ってしまえば将来的なビジネスを潰している、ということなんです
確かに、大量のデータを全て保存していくというのはお金も手間も掛かります
でもそれこそが一番効率の良いお金の使い方ではありませんか?
時代によって売れるものは変わってきます
米だったり、車だったり、ソフトウェアだったり…
時代の移り変わり(環境の変化)についていくにはデータが不可欠です
紙資源からデジタル資源に変えようという動きがありますが、データを保存する、という観点だけで言えば紙のほうが優秀です(現に1000年以上前の資料が見つかったりしてます)
デジタル資源にすることで大量のデータを高速に処理できるようになったとしても、大元のデータを消してしまったら意味ないんです
デジタル資源は紙資源よりも丁寧に扱う必要があります
データ残したい場合はどうすんの?
めっちゃ簡単です
UPDATEもDELETEもしなければ良いんです
解決策①
こんなのはどうでしょう
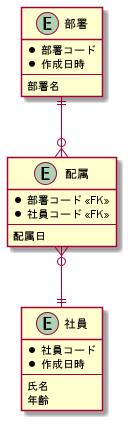
resourceに作成日時を入れてみました
全てのテーブルはINSERTしか使いません
部署、社員は実質的に履歴を保持するテーブルとなります
問題点
作成日時が○○コードとで複合キーになるように追加しましたが、これをするとPKの意味がなくなります
PKというのは一意であることを保証し、nullでないことも保証する、というものですが、日付型と複合キーにしてしまうとPK違反のエラーがほぼなくなりますw
何故なら、作成日時が同じになることはないからです
勿論nullを入れようとしたらエラーは出ますが…
これは本来の複合キーの使い方ではないですよね(エラーが出ない制約って何???)
解決策②
ちょっと改良版です
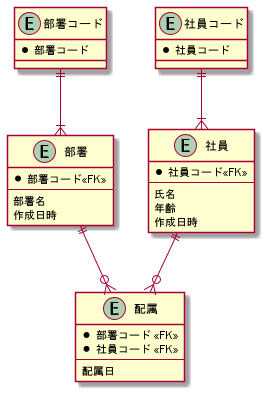
○○コードを完全に独立させましたw
すると部署、社員ではデータの不整合を気にする必要はなくなります
全てのテーブルはINSERTしか使いません
部署、社員では作成日時が最新のものを取ってくるようにすればOKです
なんか問題ありそうな雰囲気は感じますが、データを全て保存する、という要求はクリアできます
解決策③
こんなのはどうでしょう
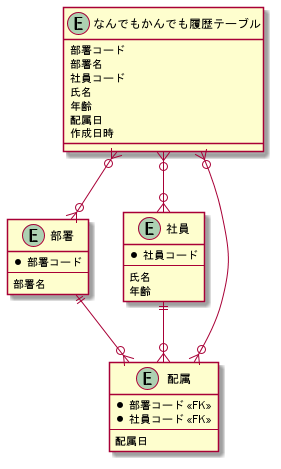
訳わからないことになってますがw
アイディアとしては、部署、社員がUPDATEされたときに関係性のあるテーブルを全てJOINさせ、一覧を保存する専用のテーブルにINSERTする、というものです
配属となんでもかんでも履歴テーブルではINSERTのみを使い、部署、社員ではUPDATE、DELETEを使っています
もし部署、社員がUPDATEされたときにはなんでもかんでも履歴テーブルにも新しいデータがINSERTされます
RDBの機能であるTRIGGERを使うために部署、社員に専用のフラグを作っても良いかもしれませんね
最新のデータが欲しい時には部署、社員、配属、に問い合わせ、昔のデータが欲しい時にはなんでもかんでも履歴テーブルに問い合わせる、というやり方でいけます
解決策④
解決策③を軽量化したパターンです
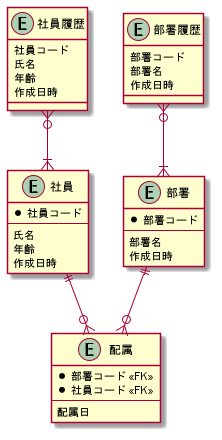
resourceに履歴テーブルをくっつけただけです
(というかこれを真っ先に考える人が多いかも…)
部署、社員ではUPDATE、DELETEを使い、配属、部署履歴、社員履歴ではINSERTしか使いません
部署、社員がUPDATEされたときに部署履歴、社員履歴に新しいデータをINSERTします
履歴テーブルの○○コードではFKを使っていません
元のテーブルが触られることによって影響を受けたくないためです
ただ、このまま実装してしまうと部署、社員がDELETEされた、というデータが履歴テーブルに残らなくなってしまいます
(いちいち履歴との差分を確認しないとどれが削除されたのかがわからない)
DELETEが発行されたときには先に履歴テーブルに書き込み、作成日時を9999...みたいにするか、専用のカラムを設けないといけなくなるかもしれません
最新のデータを見たい時には部署、社員、配属に問い合わせ、過去のデータを見たい時には部署履歴、社員履歴、配属に問い合わせます
どれが良いの?
ケースバイケースで考えてくださいw
個人的には解決策②か解決策④が良いかなと思ってます
社員が退職したかどうかであれば退職テーブルを作れば良いと思いますが、住所等であるとこれができません
(一個前の住所、二個前の住所…となってしまうため)
それをUPDATEを使わないで表そうとすると結局履歴テーブルが簡単な感じがしちゃいます
データを消さない想定で話してきてしまいましたが、実際にはデータを消す、という判断をすることもあると思います
その時にはどこまでデータを消すのかしっかり考えてください
将来的な要求に答えられなくなる可能性があります
まとめ
どうだったでしょうか
ちょっと最近モヤっとしてた部分を書いてみました
他のやり方もあると思いますので是非ご意見お待ちしています!
(PlantUML使い方ミスってるの気付いたけどそっとしておいて…w)