NetOpsCoding Advent Calendar 2016 12/8分のエントリーです。
はじめに
12月1日 にJuniper様の「Juniper Cloud Builder Community」というイベントにて
「Winnig with Monitoring」というタイトルで、登壇させて頂きました。
イベントの中で、有難いことに「発表資料を下さい」という声を結構頂いたので
この場を借りて、公開させて頂ければと思います。
イベントの講演時間は25分間と比較的短く、作成した資料の半分くらいを泣く泣く削る事となりましたが
せっかくですので、サマリーだけ 本エントリにて投稿させて頂きます。
イベントでの講演内容としましては
近年、Monitoring のカテゴリで語られる事が多くなったテレメトリー機能
(SNMPとは違い、ネットワーク機器自体がメトリックを送信するタイプ)を使った1つの実装である
OpenNTI(Juniper が公式サポートするという代物ではありません) というものを検証して
テレメトリー機能の有用性を確認する というものになっております。
Monitoring アーキテクチャー
おさらいとして、Monitoring アーキテクチャーについて
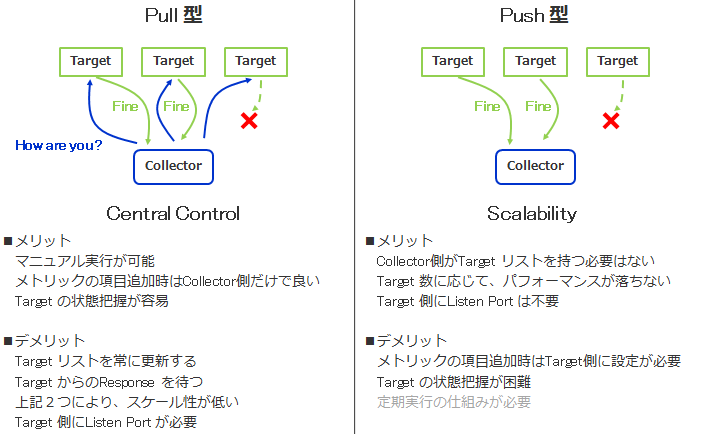
Pull型は情報収集する為にcollectorが、ネットワークノードなどのターゲットにrequestを投げて
それに対してターゲットがresponseを返すタイプとなります。
一方で、Push型はSNMP TrapやSYSLOGのようにターゲットが一方的にcollector に
情報を送りつけてくるタイプとなります。
見て分かるようにrequest/response があるPull型とは違い
Push型はリアルタイム性が強いアーキテクチャーと言えるかと思います。
ただ、個人的にはPull型、Push型 どちらが優れている という話にはしたく無く、使い分けかと思っております
(例えば、Pull型はrequest/response により遅延なども計測でき、死活監視などに向いている)。
Monitoring Systemの分類
以下は、Monitoring System の分類 となりますが、明確な分類は出来ないので
あくまでも一例ととらえて頂ければと思います。
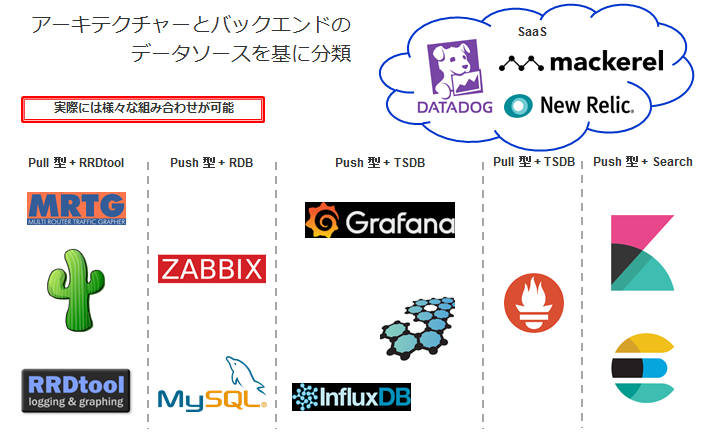
実際には様々な組み合わせがあり、バックエンドのデータソースが選択可能であったり
アーキテクチャーにしても、SNMPという存在を無視できないので
Push型のほとんどはプラグイン等でPull型をサポートしているかと思います。
SNMP
Monitoring で避けて通れないのがSNMPというプロトコル かと思います。
以下に、強み、問題点を挙げてみました。

SNMPについては語りたい事が多すぎる為、割愛します。
ネットワークベンダー各社のテレメトリー実装状況
■Cisco
・IOS XR 6.X にテレメトリー機能が実装された
(メトリックを飛ばす最短のインターバルは今のところ、5秒の模様)
・実装例
IOS XR 6.X + Streaming Telemetry Collector Stacks
■Arista
・早くからLANZ などのテレメトリー機能を実装していた
・最近では、各種Tracer機能(VM Tracer,Container Tracer)で集めた情報をNetDBで蓄積し
CloudVision で解析する という事もできるようになった
・実装例
NetDB + CloudVision
EOS Splunk Extension + Splunk Apps
LANZ + CorvilNet
■Juniper
・QFX5100 からInsight Technology(本エントリ では、Analyticsd と表現)と
呼ばれる機能でテレメトリーを実現
・MXなどでもJTI(Junos Telemetry Interface)と呼ばれる機能で実装
・実装例
Analyticsd + Cloud Analytics Engine + Network Director
Analyticsd + Contrail
docker-junos-datadog
junos-telemetry-splunk
NetReflex
BizReflex
OpenNTI ⇒ 講演資料へ
※アニメーションが多い為、docs.com にアップしております。
※補足説明が必要なスライドである為、分かりずらい箇所があるかと思います。
公開資料の補足(2016/12/16 追記)
P.6
OpenNTIの中で「Data Streaming Collector」と呼ばれる処理があり
これがネットワーク機器のテレメトリー機能を使った処理となる(Push型)。
また、「Data Collection Agent」と呼ばれる処理もあり
これはNetconf経由でデータを取るという処理になる(Pull型)。
最後の「SYSLOG」は、ネットワーク機器全てのログを送信する訳ではなく
特定のイベント(commit complete など)のみを送信するようにしている(あとで分析に使える)。
P.8
Analyticsd の設定サンプルとなるが、設定項目 depth-threshold の値はかなり低い値なので
場合によっては、値を変える必要もある。
P.9
テレメトリー機能を使う事で実現できる事は
・パケットバッファ、通信遅延の監視
・マイクロバーストの監視
・Broad/MulticastのPPS監視
となるが、これらの利点は
サービス影響を未然に防ぐ、即 検知する、証拠を取る といったサービス提供側として問題となりやすい場面
(例えば、通信遅延が起こってきたり、瞬間的に帯域を埋める通信の証拠を押さえたり、ストームを検知したり)
で効果を発揮してくれます。
P.11
Jvisionは、設定項目 resource にInterface 以外も指定でき、JUNOS 16.1R3 から色々動作するようになり
様々な情報が取れるようになった模様です(動作未検証)。
P.17
OpenNTIが起動するとWebGUIにアクセスできるようになり、収集したデータを見る事が出来ます。
「Data Streaming Collector Dashboard」というのは、テレメトリー機能で収集したデータを
表示するダッシュボードとなります。
OpenNTI をそのまま使おうとする場合は注意して頂きたいのですが
ちょいちょい、間違いがあります。例えば、このダッシュボード名も「Data Streaming」が正しいのですが
「r」の文字が抜けて、「Data Steaming」になっていたり、表示させているデータも本当は
インターフェースのBroadcast のデータを表示させている筈がMulticast のデータを表示させていたりと
結構な箇所で間違いがあります。
P.18
「Data Collection Agent Dashboard」は、Netconf経由で取得したデータを見る事が出来ます。
JUNOSの特定のプロセスがメモリリークしていないか などの監視に使う事が可能となります。
P.20
最初のグラフはCactiから1分間隔で監視しているものとなりますが
9.4Gbps 程度のトラフィックを30秒間、20秒間、10秒間 流すと
それぞれ、4.5Gbps、2.5Gbps、1.5Gbps しか流れていない事になっております。
実際には9.4Gbps のトラフィックが流れておりますが、これがCacti が認識できる限界となります
(もちろん、Cacti のRealtimeプラグインなどでピンポイントで取れる情報もあります)。
次のグラフがテレメトリー機能で取得したもので、10秒間であろうとも正確に情報が取得できています。
短期のDDoS などで回線が埋められ、サービス不能となった場合に
本当にDDoSによって回線が埋まったのかどうか などで
ユーザーと問題になるケースが多々あり、最初のCacti のグラフで納得して頂けるケースは少ないと思います。
通常は、トラフィックグラフとxFlow 情報を合わせて 何とか解決しますが
1日・2日で火消し出来ないケースが多いので
実際のトラフィック状況を精度高く監視・保存できるのは、大きな強みになるかと思います。
P.25
上段のグラフは、QoSを適用したユーザーが出しているトラフィック
下段のグラフは、QoSの制限に引っかかり ドロップした通信となります。
通常、トラフィックは物理・論理インターフェースなどの括りで監視しますが
ルールベースでの監視が可能となります。
P.27
Netconf経由でのデータ取得はボトルネックとなりやすく
チューニングしようにも、PyEZのSSH処理はParamiko を利用しており、ControlMaster の設定等を
変更できないので、SSHセッションを束ねる事も出来ません。
よって、SSH処理の多重度を上げる(cron 登録を複数回 実施)程度の対応しか出来ておりません。
おまけ
OpenNTI の検証を実施しましたが、実際にはプロダクション環境にOpenNTIをそのまま使う事は想定しておらず
仕組みだけを流用して、ベアメタルサーバーでMonitoring System を構築する予定でいます。
理由としましては、Docker コンテナにDBを持たせるのが(今は)生理的に嫌だ という事と
Docker コンテナを使うと今度は、コンテナ自体の監視が必要になり
(今は)コンテナ管理・監視のソリューションが多々ある状況ですので
しばらくは様子をみたい という割と漠然とした理由です。
また、可視化部分だけでなく 当然、Alerting Systemとも連携させるのですが
これは当初、InfluxDBとの連携のし易さから、Kapacitor を想定しておりましたが
Grafana 4.0 からベータ版ではありますが、Alerting 機能が実装された為
こちらも候補にいれる予定であります。