今年の1月くらいからPythonや機械学習の勉強を始めて、およそ半年ほど経ちました。
基本的な文法理解から取り組み始め、それからデータエンジニアリングやモデル構築を写経してきましたが、そろそろ、自分の力でどこまでできるか試したくなり、Kaggleの中でも入門的なHousePricesに挑戦してみました。
なお、機械学習の素人による初めての投稿になりますので文章の稚拙さや知識の乏しさにはある程度牙を引っ込めていただき、何か間違いがあれば乳歯で噛むようなコメントを頂けると幸いです。
はじめに
本投稿は「エンジニアリングやプログラミングの知識が深くない」かつ「機械学習を始めて1年以内の初学者」を対象にした記事です。
複雑なデータ処理やモデル構築はおこなわず、あくまで雛鳥がやっと飛び立てるようになった程度の基礎的な方法論でチャレンジしています。
機械学習の基礎を理解したばかりの方が、いざ独力でデータ加工やモデル構築をおこなう際の参考にしていただけると嬉しいです。
HousePricesへ取り組んでみよう
Kaggleが開催しているコンペの一つで、住宅価格の予測をする問題です。いわゆる回帰問題です。
トピックもわかりやすく、データ量や特徴量数もそれほど多くないので、Kaggle初心者が取り組むにはうってつけのお題になってます。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview!
データを見てみよう
まず、トレーニングデータとテストデータを読み込んでみます。
read_data.ipynb
import pandas as pd
pd.set_option("display.max_columns" , 200)
pd.set_option("display.max_rows" , 100000)
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
pd.set_optionでDataFrame内の列と行の最大表示数を任意の数まで増やすことができます。
デフォルトでは、DataFrameの列数や行数が多い場合は一部非表示になってしまいますが、すべて省略せず表示させたい場合は設定しておくのがおすすめです。
トレーニングデータを表示します。
train.head()
| Id | MSSubClass | MSZoning | LotFrontage | ... |
|---|---|---|---|---|
| 1 | 60 | RL | 65.0 | ... |
| 2 | 20 | RL | 80.0 | ... |
| 3 | 60 | RL | 68.0 | ... |
こちらでは一部のみ表示してますが、ざっくり眺めた感想としては、
・数値(連続変数)と文字(カテゴリー変数)が混ざってるなー
・欠損がしてる変数があるなー
・数値同士でも大きさの尺度がバラバラだなー
こんな感じでした。
各変数の定義についてはこの段階でざっくり理解しておくのがおススメです。
data_description.txtに変数定義一覧が載っているので、英語でアナフィラキシーショックを誘発してしまう方以外は目を通しておきましょう。
この後は、どの変数で欠損値が発生しているかを一覧で確認しました。
train.isnull().sum()
Id 0
MSSubClass 0
MSZoning 0
LotFrontage 259
LotArea 0
Street 0
Alley 1369
...
他にも10数個の特徴量で欠損していました。
ここでは、欠損値が発生しているカラムをばっくり認識する程度に留めて、後ほど補完処理することにします。
あ、データ加工処理の前にトレーニングデータを説明変数と目的変数に分割したほうがいいですね。
あと、トレーニングデータの「Id」も加工には不要なので削除します。
train_X = train.iloc[:,:-1]
train_y = train["SalePrice"]
train_X = train_X.drop(["Id"] , axis=1)
dropで不要列を削除する際には、axis=1の指定も忘れずに。
カテゴリー変数を加工しよう
次はカテゴリー変数の変換処理です。
トレーニングデータ内の変数にはカテゴリー変数と連続変数の2種類がありますが、まずはカテゴリー変数の加工をおこないます。
例えば、MSZoning(A,C,FV..)やLotShape(Reg,IR1..)はカテゴリー変数ですね。
モデル構築のためには、大きさの意味を持たない数字に置き換える必要があるので、ラベルエンコーダーを適用して数値変換します。(e.g 服のサイズ:S,M,L→1,2,3)
おぞましいほどの変数リストを白目になりながら作成します。
ちなみに、最後の行でastype(str)によって各変数を文字列に変換してますが、この処理をしないと以下エラーを吐き出しますので気をつけましょう。
TypeError: argument must be a string or number
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
columns = ["MSZoning","Street","Alley","LotFrontage","Street","Alley","LotShape","LandContour","Utilities","LotConfig","LandSlope","Neighborhood","Condition1","Condition2","BldgType","HouseStyle","RoofStyle","RoofMatl","Exterior1st","Exterior2nd","MasVnrType","ExterQual","ExterCond","Foundation","BsmtQual","BsmtCond","BsmtExposure","BsmtFinType1","BsmtFinType2","Heating","HeatingQC","CentralAir","Electrical","KitchenQual","Functional","FireplaceQu","GarageType","GarageFinish","GarageQual","GarageCond","PavedDrive","PoolQC","Fence","MiscFeature","SaleType","SaleCondition"]
for col in columns:
train_X[col] = le.fit_transform(train_X[col].astype(str))
いかがでしょうか?
ラベルエンコーダーの適用によってMSZoningの値がRL→3に変換されていると思います。
| MSSubClass | MSZoning | LotFrontage | ... |
|---|---|---|---|
| 60 | 3 | 65.0 | ... |
| 20 | 3 | 80.0 | ... |
| 60 | 3 | 68.0 | ... |
念のため、MSZoningのユニークな値も確認してみます。
train_X["MSZoning"].unique()
array([3, 4, 0, 1, 2])
RMやRLといった各値がしっかり数値にエンコードされていることがわかります。
他のカテゴリー変数でも同じように変換されていると思いますので確認してみてください。
欠損値を補完しよう
次は欠損値の補完です。
カテゴリー変数・連続変数ともに欠損している変数があるのでそれぞれ処理していきます。
改めて、以下で欠損値を確認してみます。
train.isnull().sum()
すると先ほどから大きく欠損値が減少していました。
これは、ラベルエンコーダーによって、欠損値が特定の数字に置換されたためです。
一瞬、え、いいの?と思いましたが、欠損値自体は識別されているわけなので問題ないと思います。
欠損値はLotFrontage・MasVnrArea・GarageYrBltの3つでした。
結論から言うと、
・LotFrontageは平均値
・MasVnrAreaは中央値
・GarageYrBltは0
で補完しました。
まず、上2つですが、欠損行を除外するより中央値か平均値で補完したほうがいいよね、と思ったので、とりあえずデータの分布状況を確認してみました。
# グラフを入れる枠の大きさ
plt.figure(figsize=(10, 4))
# 1行2列の枠の左側に配置
plt.subplot(1,2,1)
plt.hist(train["MasVnrArea"] , bins=30 , label="MasVnrArea")
plt.legend(loc="best")
print("【MasVnrArea】平均値:{:.2f} 中央値:{:}".format(train["MasVnrArea"].mean() , train["MasVnrArea"].median()))
# 1行2列の枠の右側に配置
plt.subplot(1,2,2)
plt.hist(train["LotFrontage"] , bins=30 , label="LotFrontage")
print("【LotFrontage】平均値:{:.2f} 中央値:{:}".format(train["LotFrontage"].mean() , train["LotFrontage"].median()))
plt.legend(loc="best")
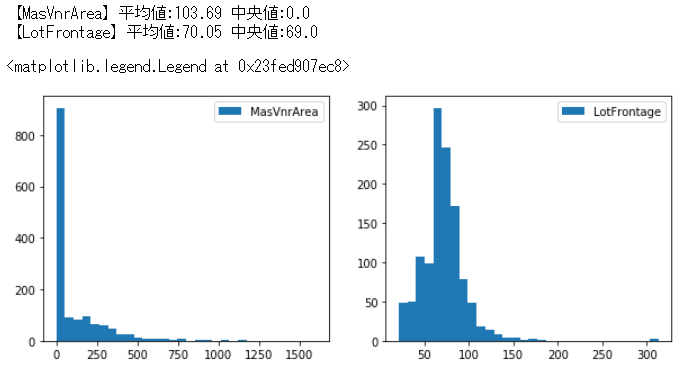 グラフおよび中央値と平均値を見ると、MasVnrAreaは中央値と平均値がだいぶ異なっています。
ほとんどの値が0なのに平均値を入れてしまうと極端な値に引っ張られてしまうことになると思ったので、MaxVnrAreaは中央値を入れることにしました。
LotFrontageはどちらの値も同じくらいですが、とりあえず平均値を入れました。
グラフおよび中央値と平均値を見ると、MasVnrAreaは中央値と平均値がだいぶ異なっています。
ほとんどの値が0なのに平均値を入れてしまうと極端な値に引っ張られてしまうことになると思ったので、MaxVnrAreaは中央値を入れることにしました。
LotFrontageはどちらの値も同じくらいですが、とりあえず平均値を入れました。
# 中央値補完
train_X["MasVnrArea"] = train_X["MasVnrArea"].fillna(train_X["MasVnrArea"].median())
# 平均値補完
train_X["LotFrontage"] = train_X["LotFrontage"].fillna(train_X["LotFrontage"].mean())
最後に、GarageYrBltですが、これは建築年ですね。
おそらくこれが欠損しているレコードはGarageを持っていない、つまり他のGarage関連の変数も元々NaNだった値が数値に置き換わっているのではないでしょうか?
確認方法は省きますが、どうやらそうみたいでした。
ということは、GarageYrBltは欠損値を「0」にしても、他のGarage関連の変数と照らし合わせれば「あ、こいつGarage持ってないやつね」ってAIは認識してくれるのでは?
という仮説のもと、0で置き換えます。
train_X["GarageYrBlt"] = train_X["GarageYrBlt"].fillna(0)
これですべての変数から欠損値がなくなり、数値に置換することができました。
これで機械学習モデルに投入することはできますが、なんとなく思いました。
「変数が多すぎない?絞ったほうがいい?」
ということで変数を絞ってみようと思います。
変数を絞り込もう
今回は、目的変数となるSalePriceと各変数の相関係数が一定値以上であればその変数を採択する、というフローを採ってみます。
まず、相関関係を視覚的にざっと捉えたかったので、seabornのヒートマップを使います。
plt.figure(figsize=(20,15))
sns.heatmap(train.corr() , cmap="Blues" , annot=True)
figsizeでヒートマップの大きさを設定しています。
各引数は、corr()は相関係数を出力するためのメソッド、cmapはヒートマップの色、annotは各マスに相関係数を出力するか否か、です。

SalePriceと各変数の相関係数は一番右列を見ればわかりますが、ぱっと見0.3以上の変数が重要そうですね。
なので、相関係数の大きい変数を降順に出力し、0.3以上の変数のみピックアップしてみます。
train.corr()["SalePrice"].sort_values(ascending=False)
SalePrice 1.000000
OverallQual 0.790982
GrLivArea 0.708624
GarageCars 0.640409
GarageArea 0.623431
...
降順に出力するとこのような形式になりますが、変数名を抽出するにはDataFrame型にする必要があるみたいです。
# データフレームに変換し、カラム名をリスト化
df = pd.DataFrame(train.corr()["SalePrice"].sort_values(ascending=False))
df = df.query("0.3 <= SalePrice < 1.0")
columns_needed = np.array(df.index)
train_X = train_X[columns_needed]
2行目のdf.queryで特定の相関係数を持つレコード(変数+値)を抽出しています。
1以下も条件に入れているのはSalePriceを抜くためです。
3行目のdf.indexでインデックスとなっている変数名を抜き出し、配列に置き換えることで、相関係数0.3以上の変数のみを入れた配列ができます。
4行目でトレーニングデータを上記変数のみのデータフレームへ変更します。
ようやく、トレーニングデータの加工が終了しました。
しかし、忘れてはならないのがテストデータの加工です。
テストデータも加工しよう
ちなみにですが、私はテストデータの加工を忘れてそのままモデルを作ったらエラーになり、そこでテストデータの加工をしてないことに気づきました。
1回目の絶望です。
とはいえ、トレーニングデータと同じ加工すればいいんじゃね?と思い、ほぼそのまま加工したらまたまたエラー。
2回目の絶望です。
なんでやねん!!!!!
エラーを見ると、どうやら欠損値のせいみたいだったので落ち着いてテストデータ内の欠損値を確認してみました。
Id 0
MSSubClass 0
MSZoning 4
LotFrontage 227
LotArea 0
Street 0
Alley 1352
...
どうやらトレーニングデータと欠損値の数や欠損している変数が異なるみたいです。
はぁ...初心者にはつらいですが一つひとつ処理していきましょう。
序盤はトレーニングデータと同じ処理です。
# テストデータからIDを削除
test_X = test.drop(["Id"] , axis=1)
# カテゴリー変数にラベルエンコーダーを適用
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
columns = ["MSZoning","Street","Alley","LotShape","LandContour","Utilities","LotConfig","LandSlope","Neighborhood","Condition1","Condition2","BldgType","HouseStyle","RoofStyle","RoofMatl","Exterior1st","Exterior2nd","MasVnrType","ExterQual","ExterCond","Foundation","BsmtQual","BsmtCond","BsmtExposure","BsmtFinType1","BsmtFinType2","Heating","HeatingQC","CentralAir","Electrical","KitchenQual","Functional","FireplaceQu","GarageType","GarageFinish","GarageQual","GarageCond","PavedDrive","PoolQC","Fence","MiscFeature","SaleType","SaleCondition"]
for col in columns:
test_X[col] = le.fit_transform(test_X[col].astype(str))
次に欠損値の処理です。
ラベルエンコーディング後も、トレーニングデータより多くの連続変数で欠損値が見られます。
先ほどと同じ要領で欠損値を補完していきましょう。
※各変数の分布を見ながら中央値や平均値の補完を考えたのですが、モデルを作成した結果、結局GarageYrBlt以外は平均値での補完が良さそうでした。
# 平均値補完
test_X["LotFrontage"] = test_X["LotFrontage"].fillna(test_X["LotFrontage"].mean())
test_X["BsmtUnfSF"] = test_X["BsmtUnfSF"].fillna(test_X["BsmtUnfSF"].mean())
test_X["BsmtFullBath"] = test_X["BsmtFullBath"].fillna(test_X["BsmtFullBath"].mean())
test_X["GarageArea"] = test_X["GarageArea"].fillna(test_X["GarageArea"].mean())
test_X["TotalBsmtSF"] = test_X["TotalBsmtSF"].fillna(test_X["TotalBsmtSF"].mean())
test_X["MasVnrArea"] = test_X["MasVnrArea"].fillna(test_X["MasVnrArea"].mean())
test_X["BsmtFinType2"] = test_X["BsmtFinType2"].fillna(test_X["BsmtFinType2"].mean())
test_X["BsmtFinSF1"] = test_X["BsmtFinSF1"].fillna(test_X["BsmtFinSF1"].mean())
test_X["BsmtFinSF2"] = test_X["BsmtFinSF2"].fillna(test_X["BsmtFinSF2"].mean())
test_X["BsmtHalfBath"] = test_X["BsmtHalfBath"].fillna(test_X["BsmtHalfBath"].mean())
test_X["GarageCars"] = test_X["GarageCars"].fillna(test_X["GarageCars"].mean())
# 0補完
test_X["GarageYrBlt"] = test_X["GarageYrBlt"].fillna(0)
最後にトレーニングデータと同様、相関係数が0.3以上の変数に絞ります。
columns_neededはトレーニングデータ加工時に作成した相関係数0.3以上の変数の配列です。
test_X = test_X[columns_needed]
テストデータも完成しました。
いよいよモデル構築に入ります。
モデルを構築しよう
今回はランダムフォレストでモデルを作ってみました。
ランダムフォレストとは?の細かい話は本記事では省きますが、選定した理由は「線形回帰やSVMより精度が良さそうで、自分で作れそうなモデル」だからです。
一応モデルの理論的な話は凡そ理解してますが・・・まぁ初心者はこんなもんです。
さぁ作りましょう。
ランダムフォレストのインポート後は、グリッドサーチするためのパラメータのリストを作成します。
# ランダムフォレストでモデル構築
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
# パラメータをグリッドサーチ
from sklearn.model_selection import GridSearchCV
parameters = {"n_estimators":[10,30,50,70,100,130],
"criterion":["mae","mse"],
"max_depth":[3,5,7,10,15],
"max_features":["auto"],
"random_state":[0],
"n_jobs":[-1]}
グリッドサーチも他記事を参考いただきたいのですが、ざっくり説明すると「複数のパラメータから適切なパラメータの組み合わせを取捨選択して最高のモデルを作ってくれる」と言ったとこでしょうか。
細かなパラメータはsklearnのヘルプサイトを見ながら最適化が必要そうなものを選択してみました。
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
上記のパラメータリストを活用してグリッドサーチでモデルを作成します。
# グリッドサーチでモデル作成
clf = GridSearchCV(rf , parameters , scoring="neg_root_mean_squared_error" , cv=5)
clf.fit(train_X , train_y)
# ベストパラメータを取得
print(clf.best_estimator_)
GridSearchCVの引数は、scoringはKaggleの評価指標であるRMSE、交差検証の分割数を意味するCVは5を指定します。
それぞれ下記を参考に設定しましたが、これが適切なパラメータとは限らないことにご留意ください。
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mae',
max_depth=15, max_features='auto', max_leaf_nodes=None,
max_samples=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=130, n_jobs=-1, oob_score=False,
random_state=0, verbose=0, warm_start=False)
出力にはやや時間がかかりますが、無事ベストパラメータが取得できました。
いよいよテストデータを予測したいと思います。
テストデータを予測しよう
いよいよここまで来ました。
最後はテストデータを予測してみましょうう。
pred_y = clf.predict(test_X)
pred_y
array([122153.44615385, 149360.57692308, 174654.18846154, ..., 160791.61538462, 106482.30769231, 236272.41923077])
無事出力されました。
あとはこの予測データが高スコアを出せることを祈って提出用データを作ります。
test["SalePrice"] = pred_y
test[["Id","SalePrice"]].head()
import csv
test[["Id","SalePrice"]].to_csv("submission.csv" , index=False)
ロカールにsubmission.csvというファイルができました。
ちなみに、indexをTrueにしてしまうと不要なindexの数字も提出ファイル内に作成されて提出に必要なフォーマットとマッチしなくなるので注意してください。
スコアを確認しよう
結果はこちら。

スコアは0.15453で順位は3,440位。(全体の67%くらいの位置)
いやー低い...データ加工とモデル構築を独力でこなせたことへの達成感は大きいですが、いざ結果を見るとやはり悔しい。
しかし・・・
この後、いろいろ試行錯誤した末、スコア0.13576の2,074位にランクアップしました。(全体の40%くらい)
この後どんな処理をおこなったのか、続きは後編で書き綴りたいと思います。