TL; DR
会議データを活用することでこんなものを作るための、学習モデルを作ります。
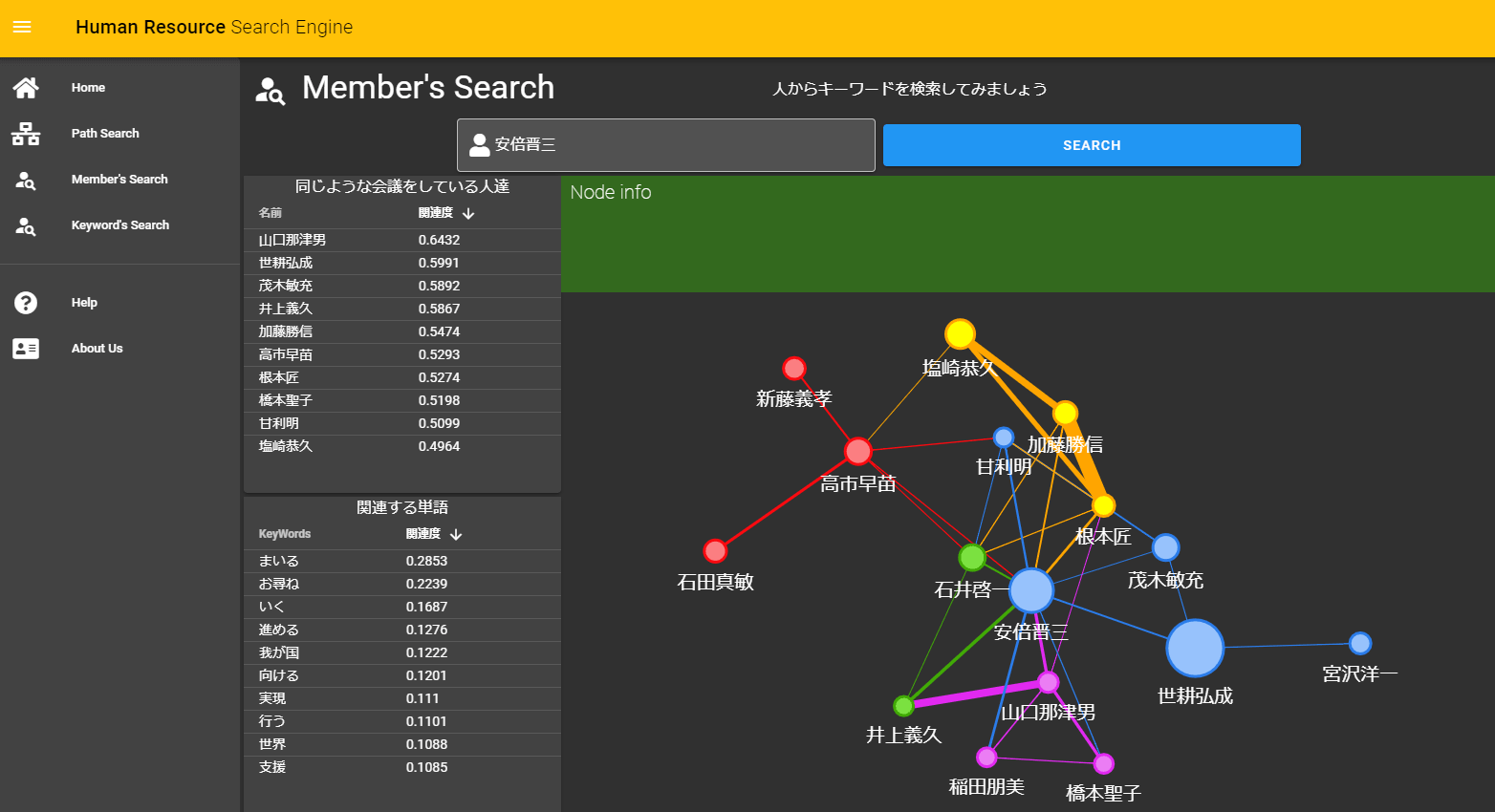
なお、記事全体はこちらです。
1. 前提
- ここを読んでいること
- その上で、以下のデータを準備してあること
- 形態素解析済の会議データ
- filterred_mecabdata.pkl
- メンバー詳細データ
- memberdict.pkl
- ただし、本記事ではこのファイルは使用しません
- 形態素解析済の会議データ
以下で使用するのは、国会議事録のデータを元にした会議データです。
2. 機械学習
各メンバに特徴的な文章と、各メンバ間の類似度を計算します。
何をもって文章間が類似していると判断するかはそれぞれ考えていただくとして、ここでは以下の2通りの方法で、類似度を評価することにします。
- TF-IDFスコアを用いる方法
- doc2vecを使う方法
ちょっと、そこあなた!
TF-IDFは機械学習じゃないって思ったでしょ!!
はいその通りです。でも巷の人はその違いは知らないので、結果が何となくいい感じなっていれば気付かれません。ので、
「AIが頑張りました!(にっこり)」
と言っておけば、ほぼ問題はないでしょう。AIのイメージなんて、人の数だけありますしね(キリッ!
2.1 TF-IDFを用いた人物間の類似度算出
こちらをご覧ください。
ちゃんscipyライブラリ使えば、大きくなりがちな疎行列でもストレスない速度で処理が終わります。
2.2 doc2vecで人物間の類似度算出
こちらをご覧ください。
gensimパッケージを使えば、簡単に学習できます。
3. ネットワーク分析
Network Graphを作り、louvain法という手法を使ってNetowrk Graphから似たような発言の人同士でクラスタリングします。
可視化すると、こんな結果が得られます。
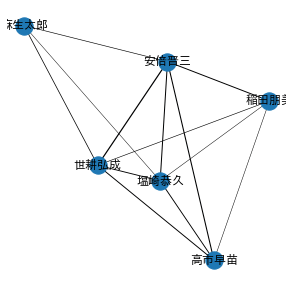
このNetowrk GraphをJsonで記述すると、具体的な内容は以下のようになります。
{
"directed": false,
"multigraph": false,
"graph": {},
"nodes": [
{
"size": 3,
"cluster": 1,
"id": "稲田朋美"
},
{
"size": 54,
"cluster": 3,
"id": "麻生太郎"
},
{
"size": 142,
"cluster": 0,
"id": "世耕弘成"
},
{
"size": 39,
"cluster": 4,
"id": "塩崎恭久"
},
{
"size": 30,
"cluster": 1,
"id": "高市早苗"
},
{
"size": 95,
"cluster": 1,
"id": "安倍晋三"
}
],
"links": [
{
"weight": 0.5984722375869751,
"source": "稲田朋美",
"target": "世耕弘成"
},
{
"weight": 0.9666371941566467,
"source": "稲田朋美",
"target": "安倍晋三"
},
{
"weight": 0.48173508048057556,
"source": "稲田朋美",
"target": "塩崎恭久"
},
{
"weight": 0.4896692633628845,
"source": "稲田朋美",
"target": "高市早苗"
},
{
"weight": 0.7263149619102478,
"source": "麻生太郎",
"target": "世耕弘成"
},
{
"weight": 0.6178034543991089,
"source": "麻生太郎",
"target": "安倍晋三"
},
{
"weight": 0.46518972516059875,
"source": "麻生太郎",
"target": "塩崎恭久"
},
{
"weight": 0.8961162567138672,
"source": "世耕弘成",
"target": "塩崎恭久"
},
{
"weight": 1.2007122039794922,
"source": "世耕弘成",
"target": "安倍晋三"
},
{
"weight": 0.945235550403595,
"source": "世耕弘成",
"target": "高市早苗"
},
{
"weight": 0.9955565333366394,
"source": "塩崎恭久",
"target": "安倍晋三"
},
{
"weight": 0.9067516922950745,
"source": "塩崎恭久",
"target": "高市早苗"
},
{
"weight": 1.053189754486084,
"source": "高市早苗",
"target": "安倍晋三"
}
]
}