データ分析の際にJupyter Notebookを利用することも多いですよね。ここでは、Google ColaboratoryからTiDB Serverlessを利用する方法について書いていきます。
接続
Colaboratoryにノートブックを作成して、実際に接続していきます。
ライブラリのインストール
Jupyter NotebookでSQLディレクティブを利用出来るようにするライブラリにはipython-sqlがありますが、ここではそのforkである jupysqlを利用します。開発が活発なのと、いくつかの機能拡張をしているので選びました。ただ、どちらでもTiDB Serverlessとの接続に利用可能です。(接続文字列を使った初期化方法に違いがあります)
まずは、必要なライブラリをインストールし、sqlディレクティブを利用できるようにします。ここではmysql接続ライブラリにPyMySQLを使います。先に述べた接続文字列を使った初期化のために、SQLAlchemyを利用します。
!pip install PyMySQL jupysql sqlalchemy --quiet
%load_ext sql
TiDB Serverlessへの接続
TiDB Serverlessの接続画面から、接続に必要な情報を取得します。

この情報を使い、接続文字列を作成します。パスワードを直接notebookに埋め込まないように、getpass() を利用しているため、実行時にテキストボックスにパスワードを入力します。
また、jupysql は独自のプロット関数を持っているのですが、一部MySQLに対応していません。後ほどプロットに利用するために、結果セットを汎用のDataFrameに変換します。
from getpass import getpass
from sqlalchemy import create_engine
password = getpass()
user = "<ユーザー名>"
port = "4000"
host = "gateway01.ap-northeast-1.prod.aws.tidbcloud.com"
database = "<DB名>"
connection_string = f"mysql+pymysql://{user}:{password}@{host}:{port}/{database}?ssl_verify_cert=true"
# jupysqlは %sql $connecton_string の形式の初期化を許可していない
engine = create_engine(connection_string)
%sql engine
# for MySQL, jupysql plotting function has some limitation. use DataFrame
%config SqlMagic.autopandas = True
これで接続はOKです。
クエリの実行
さて、実際にクエリを実行していきましょう。
SQLセル
%%SQL を利用することで、セルにSQLを記述し結果を取得できます。
%%sql
SELECT
`start_station`,
`member_type`,
COUNT(*) AS `count`
FROM
`trips`
GROUP BY
`start_station`,
`member_type`
ORDER BY
`count` DESC;

SQL文とプロットの利用
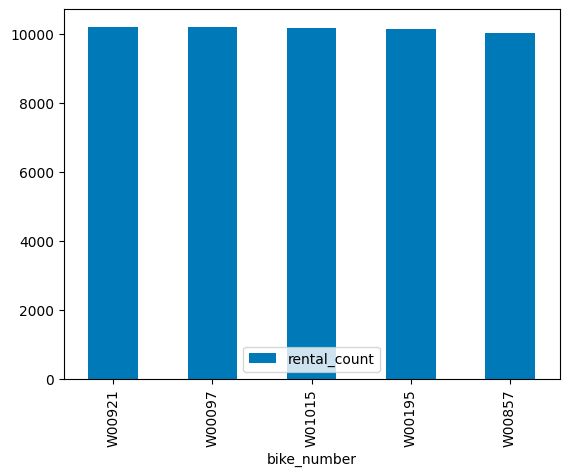
%SQL で結果を変数に格納することができて、後続の処理で利用することができます。
これを利用してグラフの描画などを行えます。
bike_count = %sql SELECT trips.bike_number, COUNT(*) AS rental_count FROM trips GROUP BY trips.bike_number ORDER BY rental_count DESC LIMIT 5
bike_count.plot.bar(x="bike_number")
TiDB Serverlessは無料帯でも5GB程度のデータを扱えるので、色々ためしてみてください!