この記事はTiDB Advent Calendar 2023の7日目です。
TiDB CloudのData Service機能について
TiDB CloudはTiDBをクラウド上で提供するマネージドデータベースなのですが、単にデータベースを提供するだけではなく、クラウド上にあることを生かした機能拡張も提供しています。その一つが今日ご紹介するData Serviceです。
Data Serviceは、SQLを使ってRESTエンドポイントを作成するローコードプラットフォームです。また、APIの定義はOpenAPI形式となっており、Githubと連携してCDも可能となっています。
チュートリアル内容
このチュートリアルでは、TiDB Serverlessのクラスタを起動して、CSVファイルからデータベースを作成し、そのデータを取得、更新できるAPIを公開します。公式BlogのEffortlessly Transform CSV into a REST API with TiDB Cloud Data Servicesをベースにしています。
サクサク進めば10分程度で完了すると思います。
画面の流れをstorylaneでも公開しています。実際の操作の流れが分かるので、是非ご覧ください。

1. TiDB Serverlessクラスタの起動
TiDB cloudのサインアップがまだの方は、サインアップを行います。コンソールのUIに慣れるにはこちらのチュートリアルを見ながら進めていただくのが良いと思います。
今回のチュートリアルのためにクラスタを一つ立ち上げます。Clustersメニューから、Create Clusterボタンを押し、クラスタを作成します。リージョンはどこでも構いません。また、今回のチュートリアル範囲は無料帯で可能ですので、Spending Limitも $0.0 のままで問題ありません。

2. CSVファイルの読み込み
作成したクラスタに、CSVファイルを読み込みます。テーブル定義もCSVファイルをベースに作ってしまいます。
2.1 ファイルの取得
対象となるCSVファイルを用意します。今回は上記Blogにあるサンプル従業員テーブルを利用します。CSV形式でダウンロードしてください。
2.2 Import画面と設定
先ほど作成したクラスタを開き、左側のメニューのDataのImportを選択します。出てきた画面のDrag&Dropエリアに先ほどダウンロードしたファイルをアップロードします。
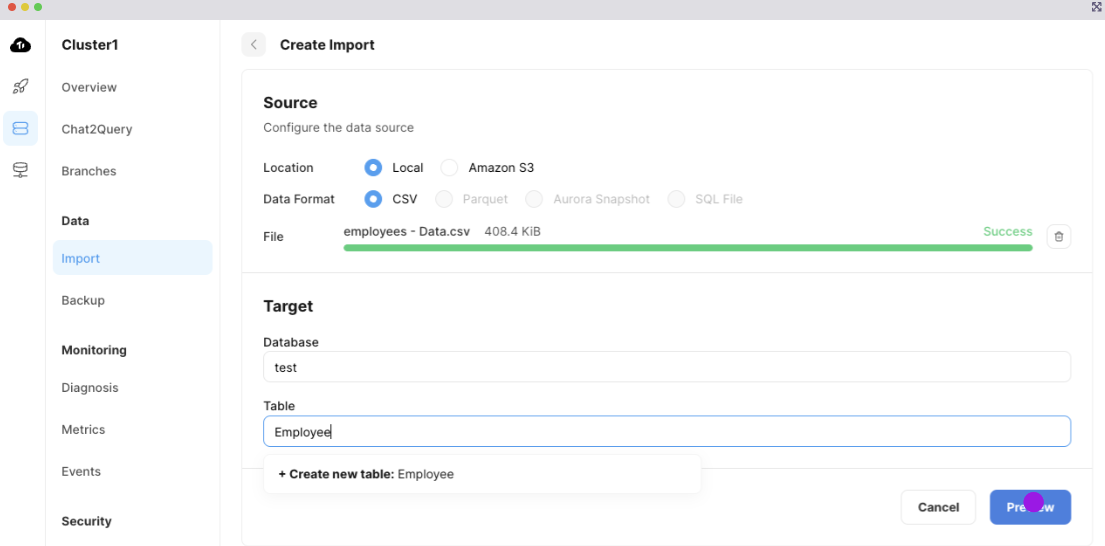
正常に読み込まれた後、データベースとテーブルを指定します。データベースはデフォルトのtest、テーブル名は任意ですがここではEmployeeとしておきます。
Previewを押しプレビューに進みます。デフォルトでCSVのヘッダがカラム名にマップされていると思います。
ここでempidをプライマリーキーにしておきます。empidの行のPrimary Keyにチェックを入れておきます。

ここまで出来たらStart Importを押して、インポート開始です。
2.3 確認
インポート自体はすぐに終わると思います。終わったらそのまま右下の Explore your data with Chat2Query ボタンを押します。Web IDEに遷移すると最初の10件を表示するSELECT文が出来ているので、その行にカーソルを合わせてCtrl+Enterを押すと実行されます。
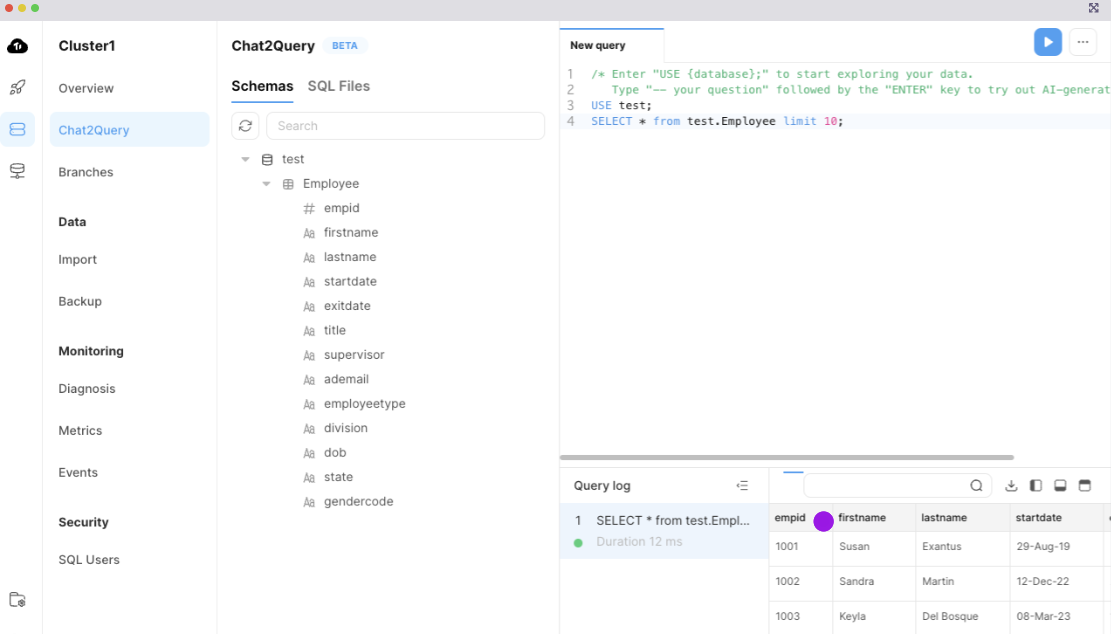
画面下部に取得したレコードが表示されているのを確認します。
3. APIの作成
データベースの準備ができたので、APIを作成していきます。Data Serviceはクラスタ毎のサービスではなく、TiDB Cloudの組織単位のサービスです。そのため、トップレベルメニューのClustersの下にData Serviceがあります。
3.1 DataAppの作成
Data ServiceメニューからData Serviceの画面を開きます。Create DataApp を押してDataAppを作成します。DataAppはこれから作成する一連のAPIをまとめるグループです。

DataApp NameをEmployee Management、Link Data Sourceで作成したクラスタを選択します。DataApp Typeはデフォルトのままにしておきます。
Createを押すとDataAppが作成されます。
3.2 自動生成によるAPIエンドポイント作成
作成されたDataAppの右側にある+を押すと表示される選択肢から、Autogenerate Endpointを選択します。
表示されたダイアログで下記を設定します。
-
ClusterDatabaseTable- インポートしたデータが保存されているテーブルを指定します。 -
Auto-Depoloy Endpoint- on に設定
それ以外はデフォルトのままで問題ありません。
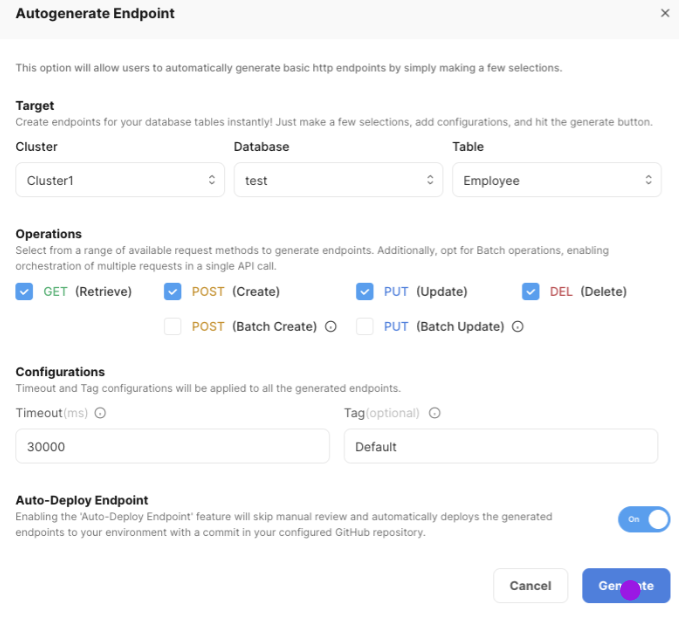
Generate を押して少し待つと、DataAppの下にGET/POSTなどのエンドポイントが出来ます。
APIの定義を見てみましょう。GETやPOSTなどのメソッドを選択すると、右側に元となるSQLが表示されます。
この定義を変更すると、APIが更新したり返したりする内容を変更できます。また、パラメーターも設定でき、
${empid}のような形式で指定することでSQLでその値を利用できます。
パラメーターの詳細はSQLエディタの右側のペインで指定します。今回はその部分の説明は割愛しますが、色々試してみていただければ分かると思います。

3.3 APIキーの取得
DataAppをクリックして、右側の画面のAuthenticationセクションからCreate API Keyボタンを押します。キーの名称は任意で構いませんが、Roleは更新もあるのでReadAndWriteとします。
Createを押した後のPublic KeyとPrivate Keyをエディタなどにコピーしておきます。
4. 作成したAPIの確認
これでAPIの準備ができました。実際に動かして確認してみます。
4.1 APIドキュメント
DataApp画面の右上上部のView API Docsボタンを押します。SwaggerのUIが開き、それぞれのAPI仕様が確認出来ます。試しにGETのレスポンスを確認すると、columns,rowsの属性を持ち、メタデータと結果の両方を返すことが分かります。

4.2 APIを叩いてみる
実際にSwagger UIからAPIを叩くには認証する必要があります。Authorizeボタンを押すとBasic認証の画面が出てきます。ここのUser NameにAPI KeyのPublic Keyを、PasswordにPrivate Keyを入力すると認証できます。
認証後はExecuteをすると実際にAPIを実行した結果が返ります。試しにempidに1001を指定して実行すると、実際のデータが返るのが確認できます。

5. おわりに
今回はCSVファイルを公開するAPIでしたが、同様に任意のデータベースを様々なSQLを使って公開することができます。
また、Github Actionと連携させたり、ChatGPTsと連携することも可能です。これらの利用法はまた別の記事で紹介していきます。皆さんも試して見てください。