はじめに
私は仕事でTiDBを利用するので、Momento CacheもDBに入れるデータのキャッシュとして利用したいですが、そうなるとMomento CacheのデータとDBのデータのJOINなどがやりたくなってきます。
もちろんクライアント側でコード書けばできますが、ここではApache Drillを利用してMomentoのデータをSQLで検索し、JOINする方法を紹介していきます。
Apache DrillでMomento Cacheのデータをクエリする
Apache Drillはデータベース以外の様々なデータソース、例えばCSVやJSON、オブジェクトストレージやdropboxといった様々なデータソースをSQLで扱えるようにするツールです。元のデータソースのスキーマ情報を定義する必要がなく、接続できればすぐに利用できる手軽さが便利な点です。
実態としてはSQLクエリエンジンで、SQLをパースして裏のデータソースのAPIを呼び出し、結果をパースして表形式にマップします。
Apache DrillはMomentoに直接対応しているわけではありませんが、JSONを返すHTTPエンドポイントをテーブルとして扱えるHTTP Storage Pluginという機能があります。また、MomentoにはHTTP APIがあり、HTTPでキャッシュの中身の取得が可能です。キャッシュにJSONを保存すれば、Apache Drillからも取得可能でしょう。
ここではmacosにインストールしてMomento Cacheの中身を検索してみます。
Apache Drillのインストール
Apache Drillをインストールします。Macの場合はbrewでインストール可能です。ラクですね。
brew install apache-drill
インストールできたら、drill-embedded コマンドで起動します。
> drill-embedded
Apache Drill 1.21.1
"Keep your data close, but your Drillbits closer."
apache drill>
[Momento] キャッシュの作成とAPIトークンの発行
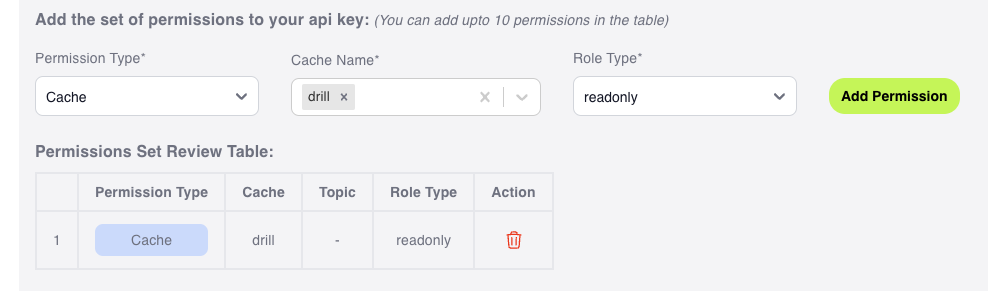
Momento側の準備をします。まず、この用途に使うキャッシュを作成しておきます。drillというキャッシュにしました。GUIでもCLIでも、お好きな方で作成してください。

次に、APIトークンを発行します。Fine Grained Access Keyで、今回作成したキャッシュのRead-Onlyで十分です。
HTTP Storage Pluginの設定
Apache Drill側の設定を行います。今回は試しに利用するだけですので、動作しているdrill-embeddedの設定を変更してしまいましょう。drill-embeddedは http://localhost:8047 でサービスを起動しているので、ここにアクセスします。
上部のメニューから、Storage を選択します。
デフォルトではHTTPプラグインは有効化されていないので、右側にあるDisabled PluginからHTTPプラグインを探し、Enableにします。

有効化されたら、Updateを押して設定ファイルを更新します。下記の内容を自分の環境に合わせて修正します。(恐らくAuthorizationのトークンの修正だけで良いはずです)
{
"type": "http",
"connections": {
"mo": {
"url": "https://api.cache.cell-ap-northeast-1-1.prod.a.momentohq.com/cache/drill?key=",
"requireTail": true,
"method": "GET",
"headers": {
"Authorization": "<YOUR API TOKEN>"
},
"authType": "none",
"inputType": "json",
"xmlDataLevel": 1,
"postParameterLocation": "QUERY_STRING",
"verifySSLCert": true
}
},
"retryDelay": 1000,
"proxyType": "direct",
"authMode": "SHARED_USER",
"enabled": true
}
設定の解説ですが、connectionsの下に接続先の設定を記載します。ここではmoという名前で定義していますが、これがSQLで検索するときのFROMで記載するテーブル名の一部になります。接続先設定で必須の内容は下記です。
- url - MomentoのHTTP APIエンドポイントを記載しています。キャッシュをパスに含め、キーは可変になるようにしています。
- requireTail - 追加情報をurlの末尾に追加するかどうかを指定します。ここではキー情報を与えるのでtrueにしています。このキー情報はFROMで指定するテーブル名として与えます。例えば、
testというキーから取得したい場合は、FROM http.mo.`test`のように指定すると、testがurlの末尾に追加されるというわけです。 - headers - HTTPリクエストの際のヘッダ情報を記載します。MomentoのHTTP APIはヘッダとパラメーターのいずれかでAPIトークンを渡すことができますが、Drillから利用する際はヘッダに含めた方が使い勝手が良いと思います。
それ以外のパラメーターは指定しなくても勝手に追加されるものですので、そのままの値で大丈夫です。
[Momento] キャッシュに値を入れる
クエリする前に値がないといけないので、キャッシュに値を入れます。JOINとかやってみたいので、関連テーブルみたいな形にしました。
key=companies
[
{
"companyId": 1,
"name": "SampleTech Inc.",
"location": "Tokyo"
},
{
"companyId": 2,
"name": "SampleDesign Co., Ltd.",
"location": "Osaka"
},
{
"companyId": 3,
"name": "SampleSolutions LLC",
"location": "Fukuoka"
}
]
key=employees
[
{
"employeeId": 101,
"name": "Taro Yamada",
"position": "Engineer",
"companyId": 1
},
{
"employeeId": 102,
"name": "Hanako Suzuki",
"position": "Designer",
"companyId": 2
},
{
"employeeId": 103,
"name": "Ichiro Sato",
"position": "Marketing Manager",
"companyId": 1
},
{
"employeeId": 104,
"name": "Rie Tanaka",
"position": "Sales",
"companyId": 3
}
]
検索する
では、drill-embeddedのコンソールに戻って検索していってみましょう。JSONのキーをそのまま列名として利用することが可能です。
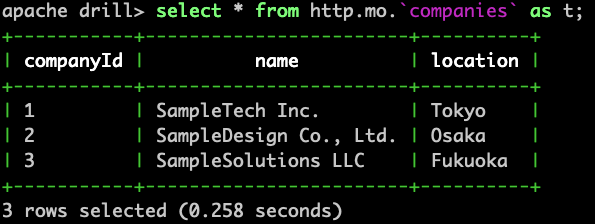
companiesの検索
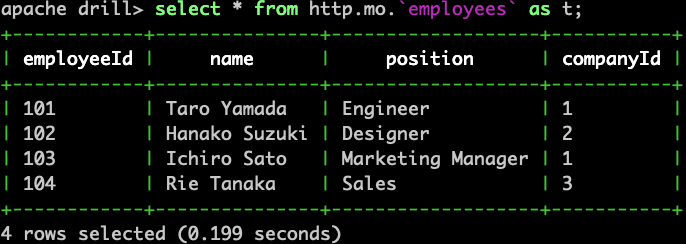
employeesの検索
JOIN

ちゃんと動作していますね。
実際に試した感じでは、JSONに日本語が含まれているとDrill側でパースに失敗します。どうもBOMつきUTF-8にしたりエンコード変えなかったりしないといけなそうなんですが、調べてはいないです。
おわりに
Apache Drillを使ってMomento CacheをSQLで検索する方法について紹介しました。この方法を使うと、Apache Drill経由で他のデータソースとMomentoに保存されたJSONを組み合わせて結果を返すことが可能になります。Momento Cacheには1キーあたり1MBの制限があるので本格的なデータベースとしての利用はちょっと厳しいですが、例えばリアルタイムランキングに詳細情報をJOINして返したいようなシチュエーションで役立つかもしれません。