さて、昨日は@k1_styleさんの「WordPressのREST APIを使ったSPAを作りたくて、TerraformでまずはAWS環境整えた話」でした。
Terraformまだ使ったことないんですよね。でも、構築をちまちまやるのは、面倒なので、来年は使ってみたいところです。
この記事はAmazonWebServicesアドベントカレンダー24日目です!
◆ はじめに
2016年12月20日時点のお話です。
初学者向けで、例はすべてnode.jsで書いています。
ほんとに初めてLambdaを触る人向けです。(自分)
◆ Lambda function codeを見てみよう(node.js)
まずは、AWSにログインして、「create lambda function」をしてみる。
- 「Blank function」を選択して、次の画面でのTriggerはデフォルトのままNextで遷移します。

- Functionを定義する画面に来ます。これが、Lambda Functionのスケルトンとなります。

ハンドラが定義されていて、引数に、event, context,callbackが渡されます。
このプログラミングモデルについて、少し理解しましょう。
> プログラミングモデル
- プログラミングモデル - AWS Lambda
-
プログラミングモデル (Node.js) - AWS Lambda
-
Lambda 関数ハンドラー (Node.js) - AWS Lambda
- Lambdaがよびだせる関数。callbackは省略可能。
- event | イベントデータ
- context | 実行中の Lambda 関数のランタイム情報
- callback | 呼び出し元に情報を返す
- 同期実行(RequestResponse呼び出しタイプ)と非同期実行(Event 呼び出しタイプ)がある
- 同期実行の場合、リクエストに対する HTTP レスポンスでは、JSON、ハンドラーが何も返さない場合はNULL
- 非同期実行(Event 呼び出しタイプ)の場合、値は破棄される
- Lambdaがよびだせる関数。callbackは省略可能。
-
Context オブジェクト (Node.js) - AWS Lambda
- context.getRemainingTimeInMillis()メソッド | Lambda 関数の残りの概算実行時間 (タイムアウトが発生するまで) を返却
- callbackWaitsForEmptyEventLoopプロパティ | コールバックメソッドのデフォルト動作をtrue,falseで変更できる(わりと重要)。自分が実行する処理によって、明確にtrue,falseを設定しておくことをお勧めします。
-
ログ作成 (Node.js) - AWS Lambda
- console.log()
- console.error()
- console.warn()
- console.info()
- Lambdaの実行コンソールからも見れるし、cloudwatchのログからも参照できる
-
例外 (Node.js) - AWS Lambda
- 同期実行(RequestResponse呼び出しタイプ)はエラー情報をスタックトレース要素の JSON 配列 stackTrace として返す
- 非同期実行(Event 呼び出しタイプ)返却なし、cloudwatchでエラー確認
-
Lambda 関数ハンドラー (Node.js) - AWS Lambda
> Node.jsのランタイムとコールバックメソッド
以前の Node.js ランタイム v0.10.42 を使用する - AWS Lambda
Node.js – v0.10.36, v4.3.2 (推奨)
v0.10.36と v4.3.2には、コンテキストメソッドに差異があるので注意しましょう。
推奨のv4.3.2 では、成功時とエラーの時のコールバックのメソッドは以下のとおりです。
// New way (Node.js runtime v4.3).
context.callbackWaitsForEmptyEventLoop = false;
callback(null, 'Success message');
// New way (Node.js runtime v4.3).
context.callbackWaitsForEmptyEventLoop = false;
callback('Fail object', 'Failed result');
◆ Getting Started
ざっくりとわかったところで、簡単なチュートリアルをやってみます。
-
Getting Started - AWS Lambda
- ステップ1はAWS-CLIの設定なので、すでにできているのでステップ2からやってみます。
・ Select blueprint - Helloを選択
・ Configure triggers
- 何も設定せずそのまま

・ ConfigureFunction
- Roleのところをcreate new role from templates
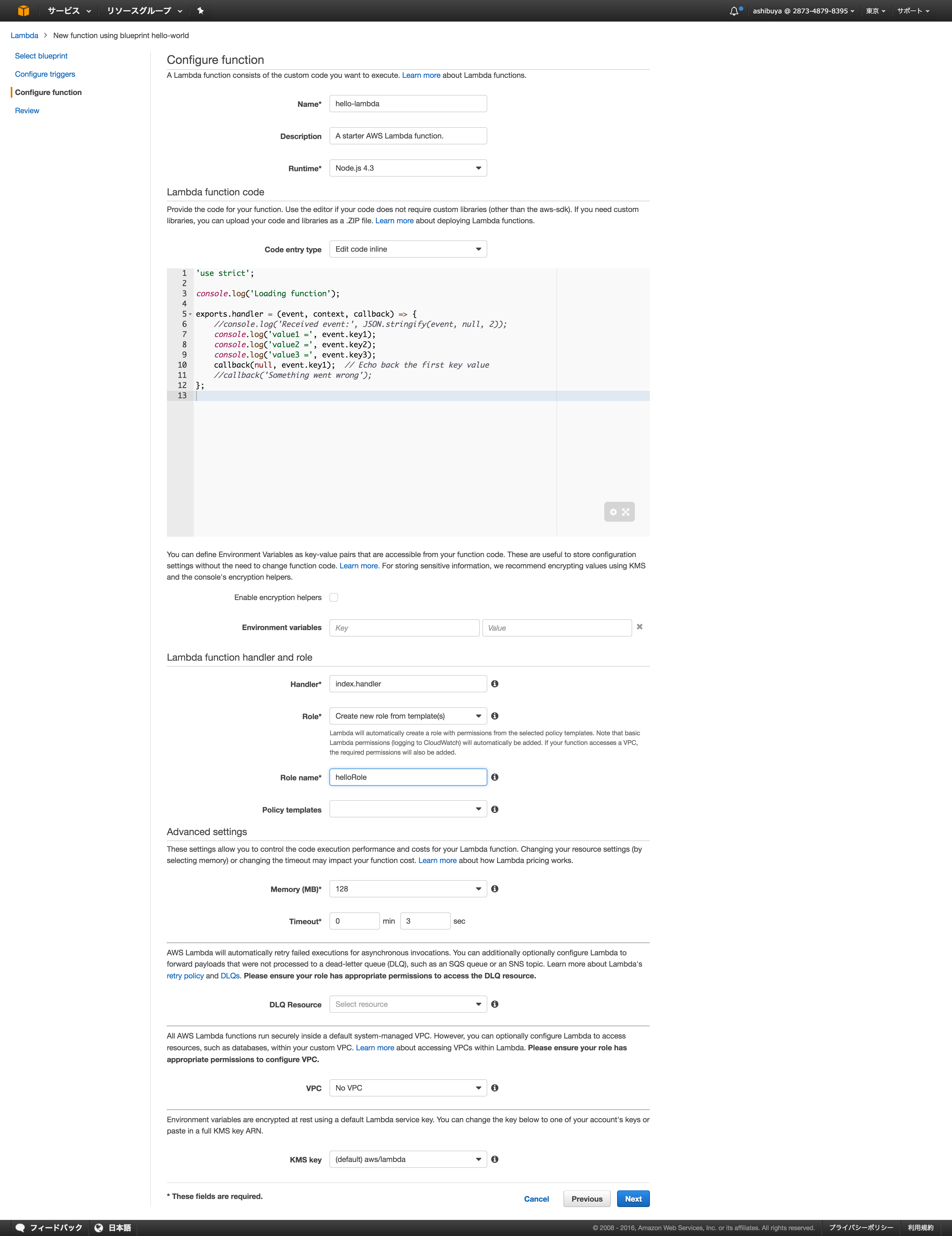
・ 作成完了したら、Testすると、実行結果とLogがコンソールに表示されます。

・ Metrics

これが、画面上で実行する時のやり方です。
次のステップからはさらに実用的になります。
手順を追いかけながら、実際にやってみましょう。
◆ デプロイと簡易ローカルテスト
> デプロイ
node.jsの場合、各種ライブラリを読み込んで実行する必要があるので、なかなかコンソールだけでは完結しません。
なので、基本デプロイは関連するファイルをすべてzipで固めて、アップロードして実行します。
デプロイパッケージの作成 (Node.js) - AWS Lambda
- パッケージインストール
npm install async
- lambda実行ファイル
filename.js
- ディレクトリは次の構造になります。
filename.js
node_modules/async
node_modules/async/lib
node_modules/async/lib/async.js
node_modules/async/package.json
- フォルダーの内容を zip 圧縮します。これがデプロイパッケージ (たとえば、sample.zip) です。
zip -r sample.zip filename.js node_modules
- このzipファイルをアップロードします

> 簡易ローカルテスト
※あくまでこれは私の場合です。
いちいちzipで固めて、実行してログ確認して・・・というのは、なかなか面倒なので、スタブを作ってロジックの確認をしています。
他のAWS環境と連携するものでなければ、簡易的に確認できるのではないでしょうか。
- Lambda本体コード
'use strict';
var AWS = require('aws-sdk');
var redis = require('redis');
var http = require('http');
var msgpack = require('msgpack-lite');
var port = 6379;
var channel = 'test';
var redis_server = process.env.PUBSUB_SERVER;
var pubclient = redis.createClient(port, redis_server, { return_buffers: true });
exports.handler = (event, context) => {
context.callbackWaitsForEmptyEventLoop= false;
//call API
var publish_data = '';
getApiData( function(err, data) {
if(!err){
publish_data = JSON.stringify(data);
console.log('Publish '+ redis_server + ':' + channel + ':'+ publish_data);
//call pubsub with msgpack.encode
pubclient.publish(channel, publish_data, function(err) {
if (!err){
callback(null, 'Success Publish');
}else{
callback(err);
}
});
}else{
callback(err);
}
});
};
// Api data get
function getApiData(cb) {
//APIを叩いて値を返却
//(略)
}
- テスト用スタブコード
- event やcontextはその場に応じて値を入れます
var lambda = require('./index.js');
var event = null;
var context = null;
lambda.handler(event ,context);
- 実行
- 環境変数を渡す例です。
PUBSUB_SERVER=127.0.0.1 node test.js
- これで、ローカルで疎通出来てからzipに固めて、lambdaにアップして実行しています。
zip -r sample.zip index.js node_modules
◆ AWS Documentationの開発者ガイドに目を通す
AWS Documentationの開発者ガイドを読んで理解していきます。
実際に作り始めて、ぶつかった時に参照すればいいというのもありますが、どこに何が書かれているのかを先にざっくりと目を通しておくのも手です。特に、仕組みを解説してある部分については先に読んでおくのが良いです
AWS lambdaの仕組みのドキュメントに目を通す
備忘録として、かいつまんで重要かなと思われる情報を書いておきます。
詳しくは本家を読んでください。
> 仕組み
Lambdaを使う場合はここの仕組みセクションのすべてのトピックを理解しましょう、ということでした。
http://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-introduction.html
Lambdaがどのようにコードを実行するのか、コンテナ(実行環境)の起動の仕組みを説明しています。
例えば、データベース接続の再には、連続した呼び出しでは、元の接続を再利用するので、すでに接続が存在すれば、その接続を使って、データベースに接続するというロジックをかけますね。
とか、読んでおくといいようなことを書いてあったりします。
> イベントソース
イベントソースには2種類あります
| イベント | 実行単位 | 対象サービス |
|---|---|---|
| ストリームベースのイベントソース | ストリームごとのシャード数が同時実行の単位、Lambda 関数は各シャードで先着順にイベントを処理 | Amazon Kinesis Streams/DynamoDB(ストリームベースのサービス) |
| ストリームベースではないイベントソース | 発行されたイベントのそれぞれが作業単位、イベントソースが発行するイベント (またはリクエスト) の数が、同時実行数に影響 | Amazon S3/APIGateway(ストリームベースではないサービス) |
> Lambda関数の同時実行数
- デフォルトでは、AWS Lambda は特定のリージョン内のすべての関数にわたり、合計の同時実行数を 100 に制限
- Lambda 関数の同時呼び出し数の計算
events (or requests) per second * function duration
例)Amazon S3 イベントを処理する Lambda 関数の同時呼び出し数を求めてみます。
Lambda 関数が平均 3 秒
Amazon S3 が 1 秒あたり 10 個のイベントを発行
10 * 3 = 30
Lambda 関数の同時実行数は 30 です。
> エラー時の再試行
例外が発生した場合、イベントソースと関数の呼び出し方法により、例外の処理方法が異なります。
| 呼び出し方法 | 例外の処理方法 | 参照 |
|---|---|---|
| 同期 | 呼び出し元が 429 エラーを受け取り、再試行の処理が必要。API ゲートウェイ を通じて Lambda を呼び出す場合は、Lambda の応答エラーを API ゲートウェイ のエラーコードに必ずマップする必要がある。 | サポートされているイベントソース - AWS Lambda |
| 非同期 | 非同期イベントは Lambda 関数の呼び出しに使用される前にキューされます。デフォルトでは、非同期で呼び出されたエラーになった Lambda 関数は 2 回再試行され、その後イベントは破棄されます。デッドレターキュー (DLQ) を使用して、このような未処理イベントを、さらに作業が行える Amazon SQS キューまたは Amazon SNS トピックに代わりに送信するよう Lambda に指定できます。 | デッドレターキュー - AWS Lambda |
> アクセス権限モデル
Lambda関数を作成する時に IAM ロール (実行ロール) を設定します。
Lambdaに用意されている AWS 管理対象 (定義済み) アクセス権限ポリシー
| ロール | 解説 |
|---|---|
| AWSLambdaBasicExecutionRole | Lambda 関数がログ作成以外に他の AWS リソースにアクセスしない場合 |
| AWSLambdaKinesisExecutionRole | Amazon Kinesis ストリームイベントを処理する Lambda 関数を作成する場合に必要 |
| AWSLambdaDynamoDBExecutionRole | DynamoDB ストリームイベントを処理する Lambda 関数を作成する場合に必要 |
| AWSLambdaVPCAccessExecutionRole | VPC のリソースにアクセスする Lambda 関数を作成する場合に必要 |
とくに最後の「AWSLambdaVPCAccessExecutionRole」などは、VPC内にあるRedisやRDSにデータを格納するLambdaを作成する時に必要です。
- 知っておくこと
- 実は地味に以下に記述してあることが重要だったりします。このエントリの最後の「知っておくこと」です。
-
LambdaファンクションからのVPC内リソースへのアクセス
- この機能を有効二するとインターネットアクセスができなくなります。実は、私は最初外部のAPIをコールして、VPC内のRedisに書き込みしようと思ったのですが、外部に出て行くことができずに、なんでだろう・・・・と路頭に迷いかけました。NATインスタンスの実行が必要なんですね。
> Lambda 関数で使用できる環境変数
Lambda 環境変数の一覧が載っているので確認しておく。
Lambda 実行環境と利用できるライブラリ - AWS Lambda
> 環境変数の使い方
Environment Variables - AWS Lambda
環境変数を使用して Lambda 関数を作成する
例えば、設定したPUBSUB_SERVERの変数を取得する場合

var redis_server = process.env.PUBSUB_SERVER;
var pubclient = redis.createClient(port, redis_server, { return_buffers: true });
> AWS lambdaの制限
一時ディスク容量、プロセスとスレッドの数などLambdaの制限が書かれていますので、引っかかる前にチェックしておきましょう
◆ おわりに
最後の方は、ドキュメントのリンク紹介になっていますが、AWSの開発者ガイドでよく迷子になるので、自分のためにも、インデックスを作っておくのが良いかなと思いました。
AWSはサービスが多くて、新しいサービスに取り組む時はとりあえず動かして試行錯誤して、その時は理解するんですけど、ふと数ヶ月経ってもう一度使う時になると、すっかり忘れているという悲しい状況のため、主に自分のためにこのエントリは書きました。
gitHubのissueにその時々のことを残しているのですが、誰かに向けて書いていないので、数ヶ月後の自分には理解不能だったりします。
というわけで、小さなTipsでもログとしてこれからは残していこうと思います。
それが誰かの役に立てば幸いかもです。
明日のアドベントカレンダーの締めは@toshi__yaさんです!