In the case of customer segmentation analysis, Principal Components Analysis and K-Means Clustering methods are used very often. So I just very briefly wrote about these 2 methods at this post.
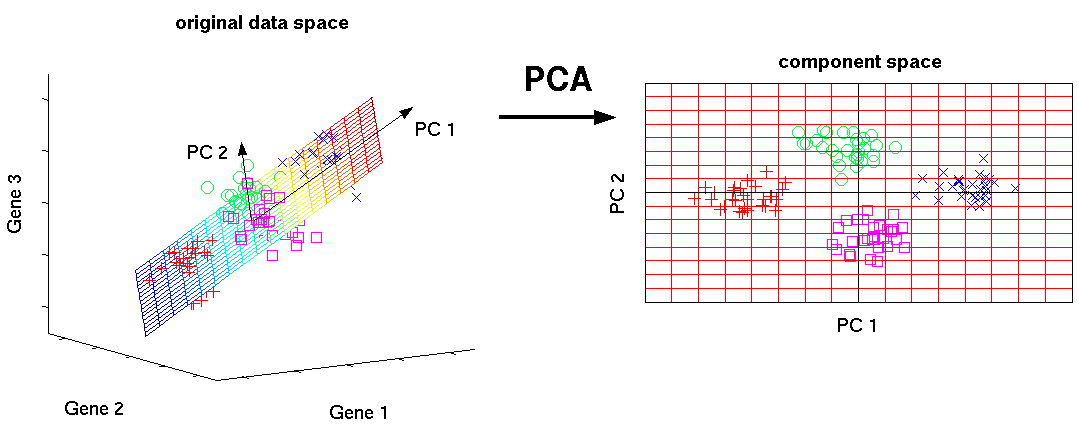
With PCA, you can reduce dimensions and abstract the meaning of features. It allows you to grab what factors influence the variance of samples.
http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
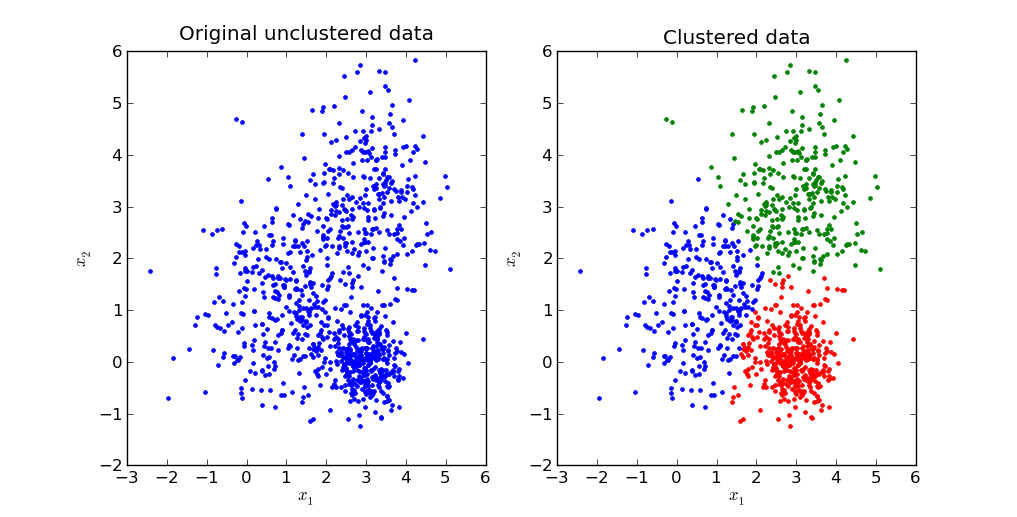
With K-Means clustering, you can mathematically group samples into a specific number of clusters. Plainly speaking, it divide samples into clusters based on how samples are closely distributed to each cluster's center.
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
These 2 methods are unsupervised algorithm and help you grab the concept of the distribution of samples in some ways. But, there are differences between the 2 methods. K-means mathematically decide which samples are belong to which groups. How many groups samples can be grouped into depends on you. On the other hands, using PCA, you can find the abstracted distribution of samples and reducted features but no grouping. How to interpret the results and cluster samples depends on how you see it.
When I studied at Udacity Machine Learning Course, I learned the combined method of PCA and K-means. Apply PCA to samples first, then, cluster with K-means using the PCA's result. In the class, I just followed the instruction and understand the concept of PCA and K-means. However, I didn't pay attention the reason why it was necessary to combine the 2 methods. What is the benefit of this combination?
In short, using PCA before K-means clustering reduces dimensions and decrease computation cost. On the other hand, its performance depends on the distribution of a data set and the correlation of features.So if you need to cluster data based on many features, using PCA before clustering is very reasonable.
However, if the data set contains only categorical data, PCA and K-means are not well suited. I need further investigations about it.
Memo 1:
There are many use cases in previous studies
Such unsupervised dimension reduction is used in very broad areas such as meteorology, image processing, genomic analysis, and information retrieval. It is also common that PCA is used to project data to a lower dimensional subspace and K-means is then applied in the subspace (Zha et al., 2002). In other cases, data are embedded in a low-dimensional space such as the eigenspace of the graph Laplacian, and K-means is then applied (Ng et al., 2001).
Memo 2:
In the beginning of the paper , It says "Here we prove that principal components are the continuous solutions to the discrete cluster membership indicators for K-means clustering."
Memo 3:
In wikipedia, it says the same thing, "It was proven that the relaxed solution of k-means clustering, specified by the cluster indicators, is given by principal component analysis (PCA)".
"relaxed solution" is;
In mathematical optimization and related fields, relaxation is a modeling strategy. A relaxation is an approximation of a difficult problem by a nearby problem that is easier to solve.