Quorum Clustering
Quorum Concept
A failover cluster is a group of independent servers which work collaboratively to ensure high availability and scalability for workloads such as File Server, Exchange, SQL, and Virtual Machines.
The nodes(servers) in the cluster are connected by physical cables and by software. If one of the cluster nodes fail, the services on the node failovered to another node in the cluster to provide service continuously. (For this failover capability, services on the cluster are proactively monitored to verify their are working properly. If they are not, they are moved to another node or restarted.)
In failover clustering, quorum concept is designed to prevent issues caused by "split-brain" in a cluster. As nodes in a cluster are communicating each other via network to achieve failover clustering functionality, when some problem occurs in the network, the nodes in the cluster become unable to communicate.
In that "split" situation, if both side of the separated cluster think itself as the brain of the cluster and try to write to the same disk, it can cause some critical problems. To avoid this issue when network disconnection occurs, either side of the separated cluster must stop running as a cluster.
So, how does the cluster decides to keep one of the separated cluster running as a cluster but stop the others? Here, quorum is used.
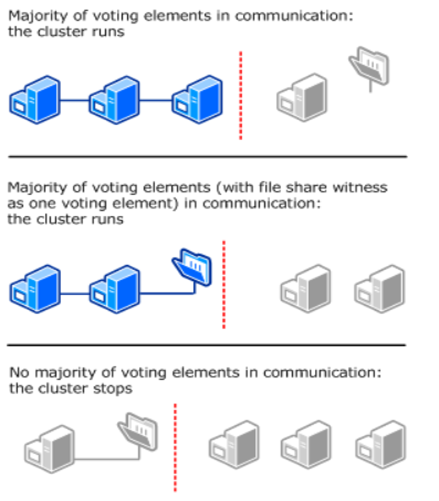
In a failover cluster, nodes running as a cluster must use a voting algorithm to determine which subset of the cluster has the majority (quorum) of the cluster. (The required number of "votes" to constitute a majority depends on the cluster's quorum configuration.)
If the number of quorum votes drops below the majority, the subset stops running as a cluster. But the nodes in the subset will still listen to other nodes, in case another node appears again on the network. Once the number of nodes reach the majority (or recover the connection to the majority cluster), the nodes restart running as a part of the cluster.
In this way, failover clustering guarantees that the only one (which has a majority of nodes running) of the subset groups will stay online in the cluster.
Quorum Mode (majority election)
Failover clustering supports 4 quorum modes. They are: Node Majority, Node and Disk Majority, Node and File Share Majority, and No Majority: Disk Only (Legacy).
As a general rule when configuring quorum mode, the sum of quorum votes in the cluster should be an odd number. (Because they are going to vote to decide majority!) Therefore, if the cluster contains an even number of nodes which has a quorum vote, you should configure a disk witness or a file share witness.
Note
Since Windows Server 2012 R2, "dynamic quorum" and "dynamic witness" are configured by default. ("dynamic quorum" and "dynamic witness" are explained in the later part of this section.)
Therefore, you don't need to cautiously choose which quorum mode to use anymore. However, in order to understand the majority election system using quorum in failover clustering, I would like to briefly describe each mode here.
Node Majority
This is recommended for clusters with an odd number of nodes. Only nodes are counted as quorum votes but a witness is not counted.
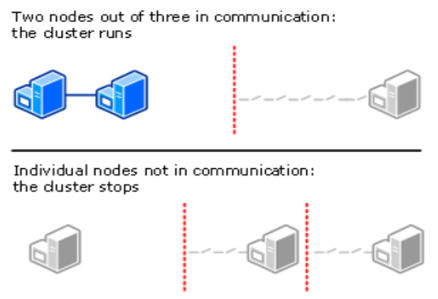
Node and Disk Majority
This is recommended for clusters with an even number of nodes. Not only the running nodes, but also "a disk witness" is counted as a quorum vote.
A disk witness is a clustered disk (not necessary to be big and 1 GB volume should be fine) which is in the Cluster Available Storage group.
With a disk witness, even if the half nodes in the cluster fails, in case the disk witness remains online, the cluster can keep its functionality as a cluster.
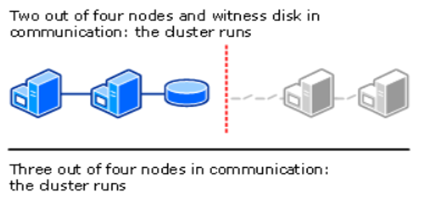
On the other hand, in case the disk witness is offline, the cluster sustain failures of half the nodes minus one in the cluster.
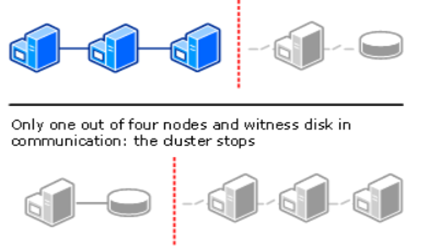
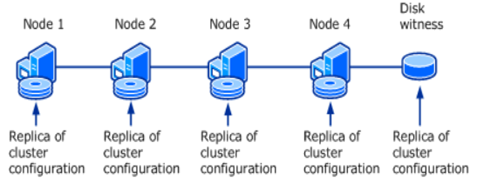
In addition, when using this quorum mode, the disk witness also contains a replica of the cluster configuration database.
Node and File Share Majority
From a perspective of majority election, this mode works in the same way as "Node and Disk Majority". The difference is that this mode uses a file share witness instead of a disk witness.
(The difference between a disk witness and a file share witness is explained in the next section.)
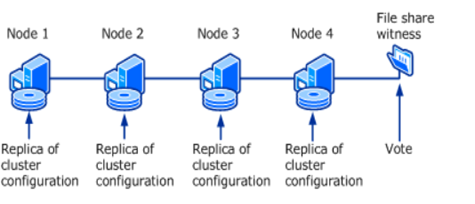
In this quorum mode, running nodes and a file share witness (like a disk witness) are counted as quorum votes.
Note that, not like a disk witness contains a backup of the cluster configuration database, the file share witness does not have a backup. But instead, it contains information about which node has the latest version of the cluster configuration database.
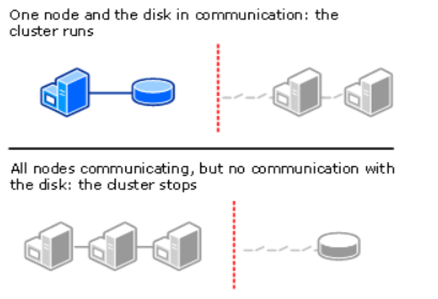
No Majority: Disk Only
This mode is a legacy configuration and not recommended. This is not majority election at all. The number of nodes are not counted as quorum votes. Only the disk is the quorum. As long as one of the node communicates with the disk, it is considered as a cluster. In the other word, you can run a cluster with a node and a disk. But the disk is a single point of failure and if the the disk fails the cluster becomes unavailable as well.
Dynamic Quorum and Dynamic Witness
Dynamic quorum modifies the vote allocation to nodes dynamically. For example, if a node is shutdown as part of a planned configuration, its vote is removed and not considered in quorum calculations. If a node successfully rejoins the cluster, a quorum vote is reassigned to the node. By dynamically adjusting the assignment of quorum votes, the cluster can increase/decrease the number of quorum votes required to keep running.
Note that quorum vote assignment is dynamically adjusted when the sum of votes is less than three in a multi-node cluster including a witness.
Since Windows Server 2012 R2, Dynamic Witness is enabled when dynamic quorum is configured (it is by default). Using this functionality, the witness vote is also dynamically adjusted based on the number of nodes who have a quorum vote in the current cluster membership. If there are an odd number of votes, the quorum witness does not have a vote. If there is an even number of votes, the quorum witness has a vote. This works in the way to keep the total number of quorum votes in the cluster odd number.
Note
What interesting to me is that the quorum voting and majority election concept is very similar to Zookeeper. (Or did they imitate it?)
https://zookeeper.apache.org/doc/r3.3.4/zookeeperInternals.html
When clustering Zookeeper, you need to have odd number of nodes in the cluster (but not mandatory). This is simply because, if you have even number of nodes in the cluster, in some cases there are 2 majority groups which has an identical number of nodes in the cluster and it becomes impossible to decide which group should control the cluster as the both sides own the majority.
Quorum Model
Currently, there are 3 available quorum models: Disk Witness, File Share Witness and Cloud Witness (available since Windows Server 2016). In this section, the difference among these quorum model and use cases for each model are covered.
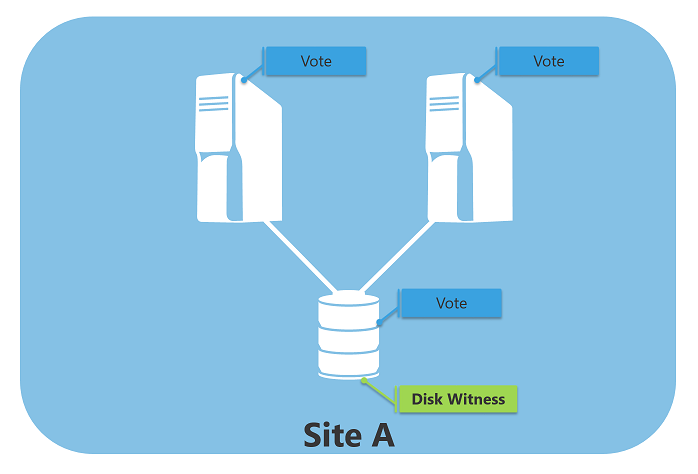
Disk Witness
When you create a new failover cluster, the cluster automatically assigns a vote to each node and selects a disk witness if there is a cluster shared storage available. In the other word, a disk witness is usually recommended for a local cluster where all nodes can see the same disk.
If you need to have a multi-site failover cluster with a disk witness, you need to configure the disk witness with replicated storage which supports read/write access from all sites. In that case, you'd better to ask high-end storage vendor such as Dell EMC, which is the best storage company in the world but very expensive.
If you can not afford it, however, you should consider to use a cloud witness for multi-site failover cluster. (You can also use a file share witness for a multi-site cluster, however, it may cost you money as well to prepare an additional site for the file share.)
File Share Witness
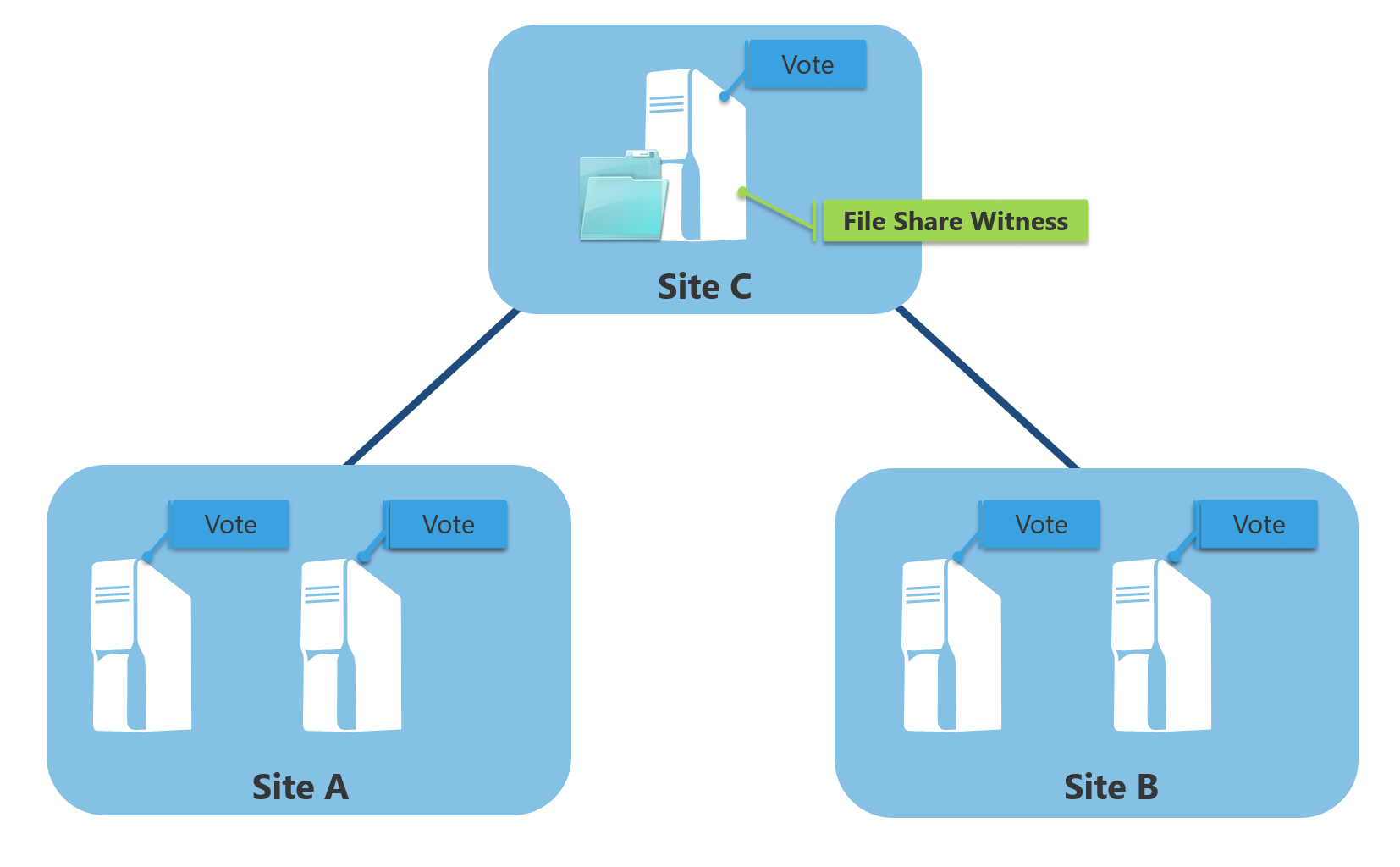
A file share witness is recommended for a geographically distributed cluster, for example, in case you are considering disaster recovery capability.
For a file share witness, you need to have an additional site (in the figure below: Site C) other than the 2 sites where your cluster nodes are hosted and your services are running (in the figure below: Site A and Site B). In Site A and Site B the cluster nodes are running, and in Site C the file share witness is hosted. By doing so, even if Site A goes down, Site B would still be up. (Note that the file share witness must be accessible by all nodes in both sites)
However, maintaining the highly available File Server (Site C) to host the file share witness is expensive, so it is possible to put the file share witness in Site A if you want (but not recommended). In this case, Site A is considered as a primary site. You need to be sure that once Site A failed or is disconnected from the network, the cluster stop running and will not failover because the majority of the cluster nodes in a failed state.
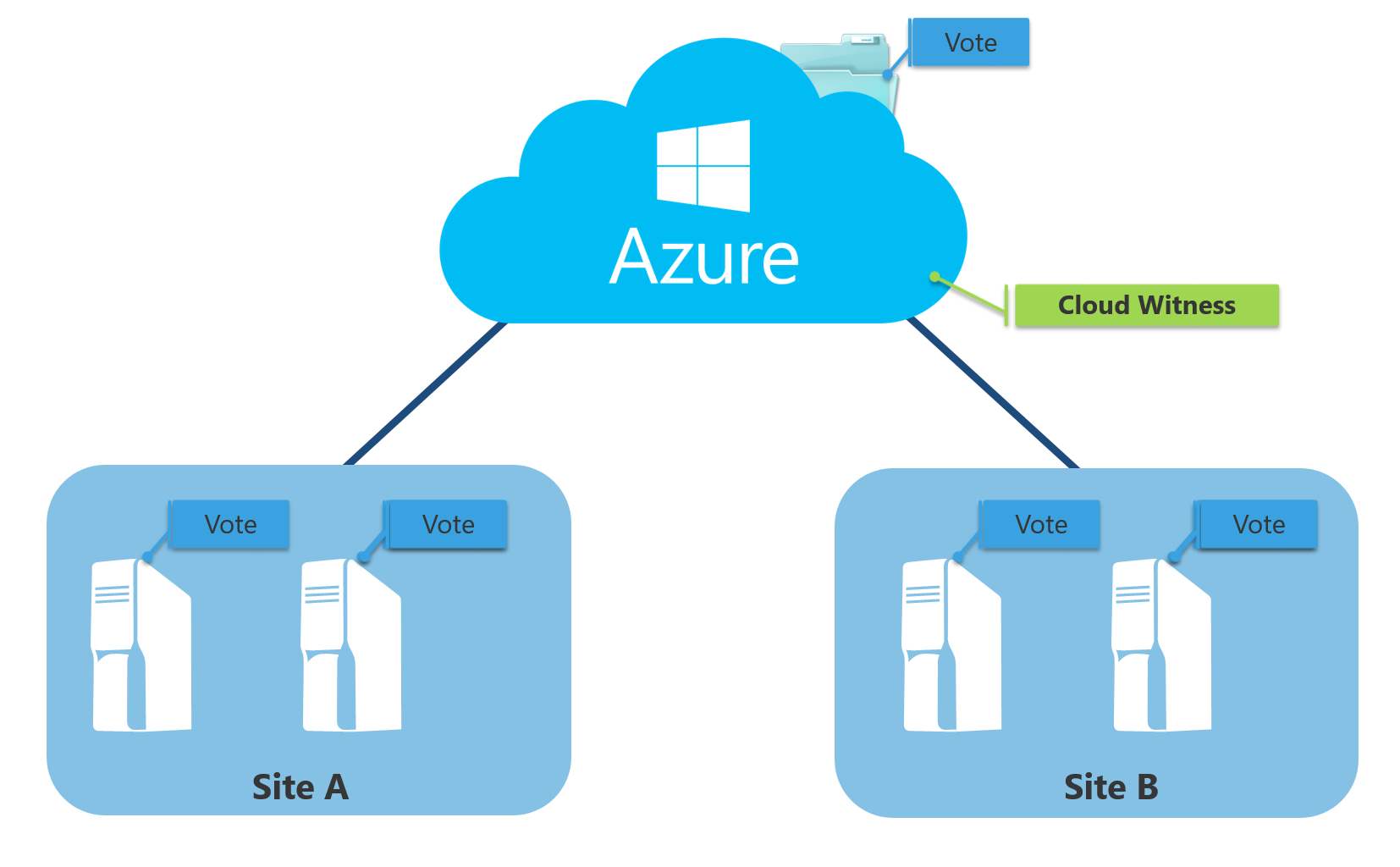
Cloud Witness
Cloud Witness is a new quorum model of failover clustering for a quorum witness that leverages Microsoft Azure public cloud by using Azure Blob Storage to read/write a blob file.
A cloud witness works in the same as a file share witness which does not contain a copy of the cluster database. In short, the additional site for the file share is on Azure public cloud. Therefore, this quorum witness model can be also used for multi-site clusters. In addition, comparing to a file share witness, a cloud witness is very cost effective. Very small data written per blob file and blob file is updated only once when cluster nodes' state changes. And also you can cut the maintenance fee for an additional date center site.
As a result, it is recommended to configure a cloud witness for a multi-site cluster if all nodes in the cluster can reach the internet. This is also the reason why still File Share Witness model is necessary in some cases.
There are many companies whose data centers are out of the reach of the internet access because of some security reasons. In that case, they can not utilize Azure public cloud for a cloud witness. To implement multi-site clustering capabilities such as disaster recovery for those data centers, File Share Witness model can be used.
Cluster Shared Volumes
CSV Ownership Concept
Clustered Shared Volumes, or CSV, is special shared storage in a failover cluster designed for Hyper-V that allows each host in the cluster to have simultaneous read-write access to the same LUN. With CSV, any virtual machines on any node have access to the VHD file in the shared LUN as like in the following figure.
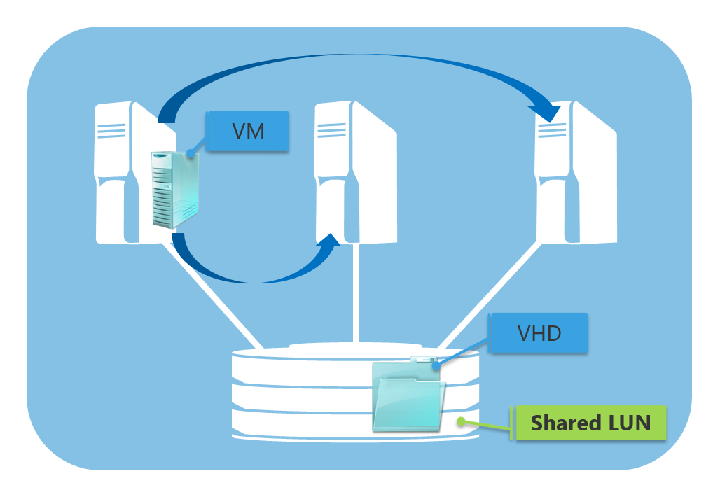
In Windows Server 2008 and earlier (when CSV was not available), only one node in a cluster had an access to a certain LUN at a time. Because of this limitation, if you want to migrate a virtual machine from one node to another in the cluster without affecting any other virtual machines, the virtual machine requires its own LUNs in order to fail over independently of other virtual machines. (Because when migrating from one to another, the LUN must be dismounted/remounted and this causes downtime to all virtual machines hosted in the LUN.) In the other word, a LUN is the smallest unit of failover. Therefore, the number of LUNs in the system increases while the number of virtual machines increases (if you want to migrate them between nodes). It makes management of LUNs and virtual machines more complex.
Using CSV, it allows nodes in the cluster to share access to certain LUNs and the services (virtual machines) on the LUNs to run on any nodes in the cluster. In this CSV environment, the shared LUNs appear as local disks (strictly speaking, it is CSV File System) for the virtual machines on the nodes, and it does not matter where each disk is actually mounted. Because of this, the dependency between VM resources (CPU and memory) and storage resources (disk devices) is isolated. As a result, when virtual machines fail over from one node to another in the cluster, it does not require drive ownership change or volume dismount/remount. It enables live-migration among nodes with zero (or little) downtime. (It means, the virtual machines are remain connected while moving to another node in the cluster.)
There are no limitations for the number of virtual machines that can be supported on a single CSV volume. However, according to this Microsoft document, you should consider the number of virtual machines in the cluster and the workload (I/O operations per second) for each virtual machine.
- One organization is deploying virtual machines that will support a virtual desktop infrastructure (VDI), which is a relatively light workload. The cluster uses high-performance storage. The cluster administrator, after consulting with the storage vendor, decides to place a relatively large number of virtual machines per CSV volume.
- Another organization is deploying a large number of virtual machines that will support a heavily used database application, which is a heavier workload. The cluster uses lower-performing storage. The cluster administrator, after consulting with the storage vendor, decides to place a relatively small number of virtual machines per CSV volume.
CSV I/O Flow
Distributed CSV ownership
In a failover cluster, one node is considered as the owner or "coordinator node" for a certain CSV. The coordinator node owns the physical disk associated with a LUN. Since Windows Server 2012 R2, CSV ownership is evenly distributed across a failover cluster based on the number of CSV volumes per node. Also, ownership is automatically rebalanced in cases such as CSV failover, a node joins/rejoins the cluster and a cluster node is restarted, in order to keep CSV ownership evenly distributed across the failover cluster. Distributed CSV ownership increases I/O performance by load balancing I/O across the cluster nodes.
I/O synchronization
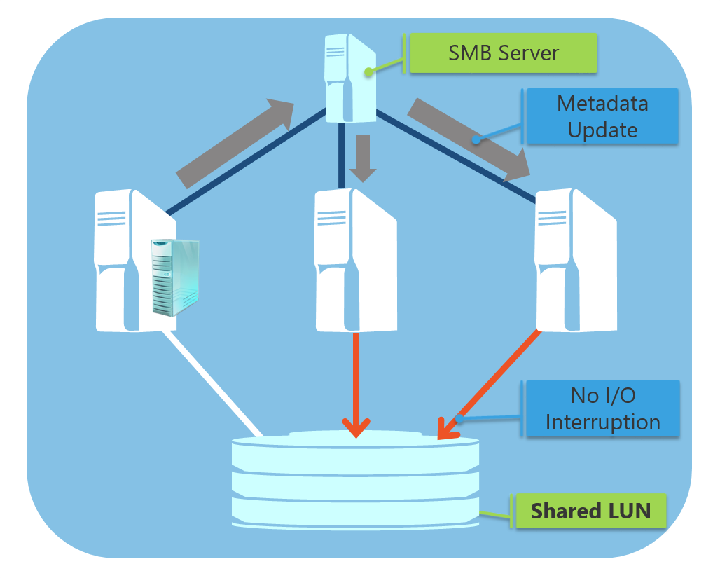
When some small changes occur in a CSV volume, such as a virtual machine is started/created/deleted/migrated, this metadata must be synchronized on each of the physical nodes that access the LUN, not only its coordinator node.
These metadata update operations are executed in parallel across the cluster networks by using SMB 3.0 and do not require physical nodes to communicate with the shared LUN (storage). Metadata synchronization occurs on the server sides, it does not cause I/O interruptions.
I/O Redirection
When the communication between a node and a storage device is disconnected, the node redirects I/O through a cluster network to the coordinator node where the disk is currently mounted, instead of trying to connect to the storage directly (because it will fail).
If the coordinator node is disconnected from a storage, all I/O operations are queued temporarily until a new node is established as a coordinator node.
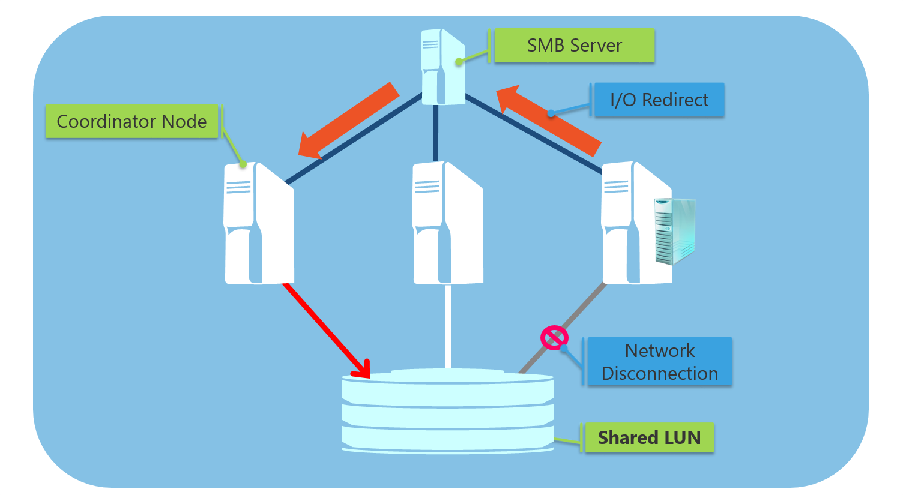
According to this document, there are 2 I/O redirection modes.
- File system redirection: Redirection is per volume—for example, when CSV snapshots are taken by a backup application when a CSV volume is manually placed in redirected I/O mode.
- Block redirection: Redirection is at the file-block level—for example, when storage connectivity is lost to a volume. Block redirection is significantly faster than file system redirection.
Honestly speaking, by just reading the above description, I can't imagine what the 2 I/O redirection modes are like. So here, 2 additional documents should be referenced.
If you really want to understand how I/O redirection works in CSV environment and somehow you accidentally reached this post, you should read these documents carefully rather than this post.
In a very simple explanation, the difference of the 2 modes is where I/O redirections occur and the path the I/O pass through.
Let's compare the data flow of the 2 modes.
The following figure shows the data flow of File System I/O Redirection.
The first thing you may notice is that I/O Redirections occur at CSV File System. After the redirection, I/O moves from Node 1 to Node 2 via the cluster network. Then, it goes through the NTFS stack on the coordinator node (Node 2). Finally it reaches to the disk and data is written.
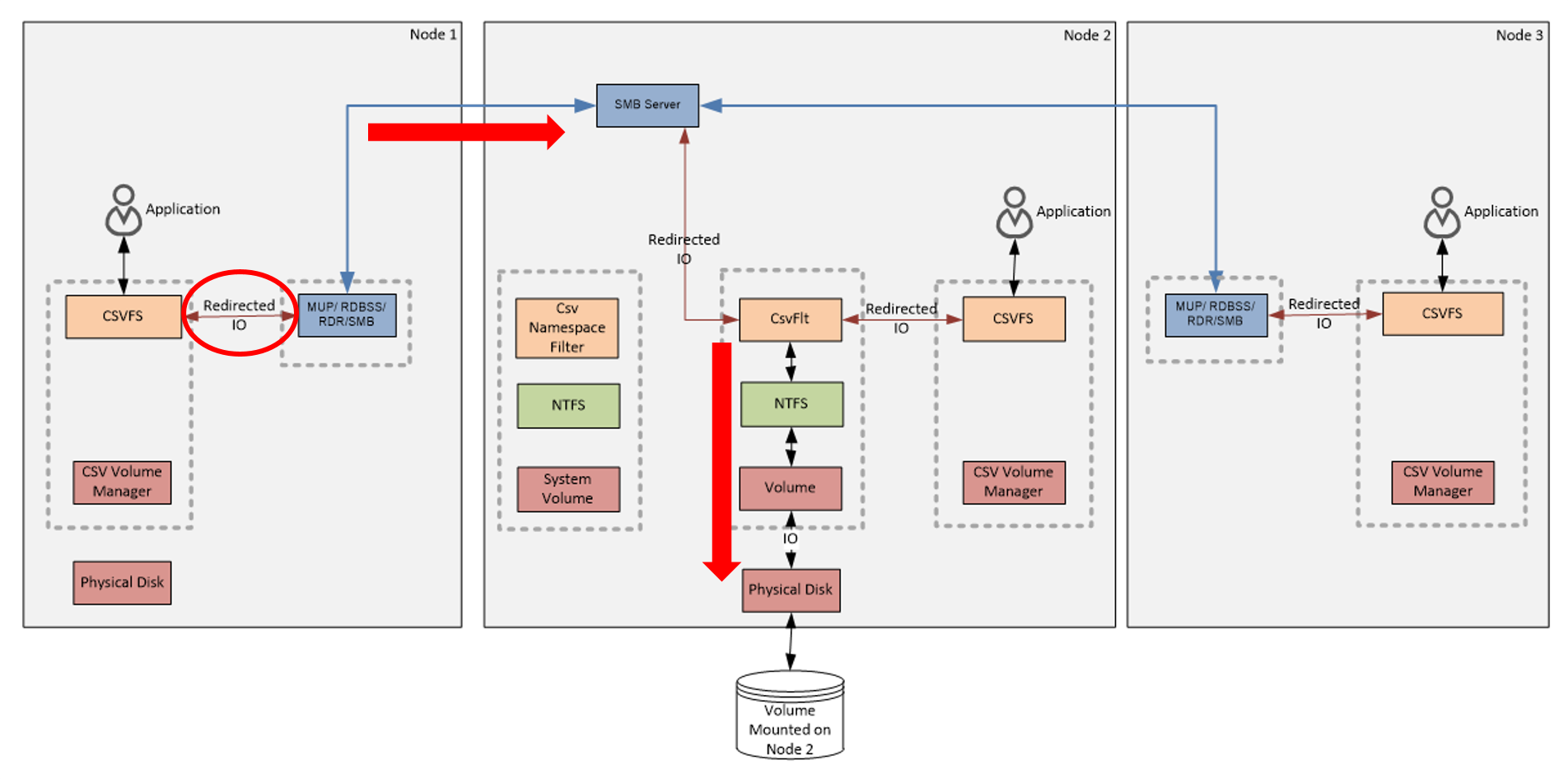
The following figure shows the data flow of Block Level I/O Redirection.
The point where the first I/O redirection occurs is CSV Volume Manager. Then, I/O moves to Node 2 via the cluster network. A notable thing here is the path I/O is going through. Not like File System I/O Redirection, when using Block Level I/O Redirection, the IO completely bypasses the NTFS stack and goes to the disk straightly. Not by passing through the NTFS stack on the coordinator node, it achieves much faster performance comparing to File System I/O Redirection.
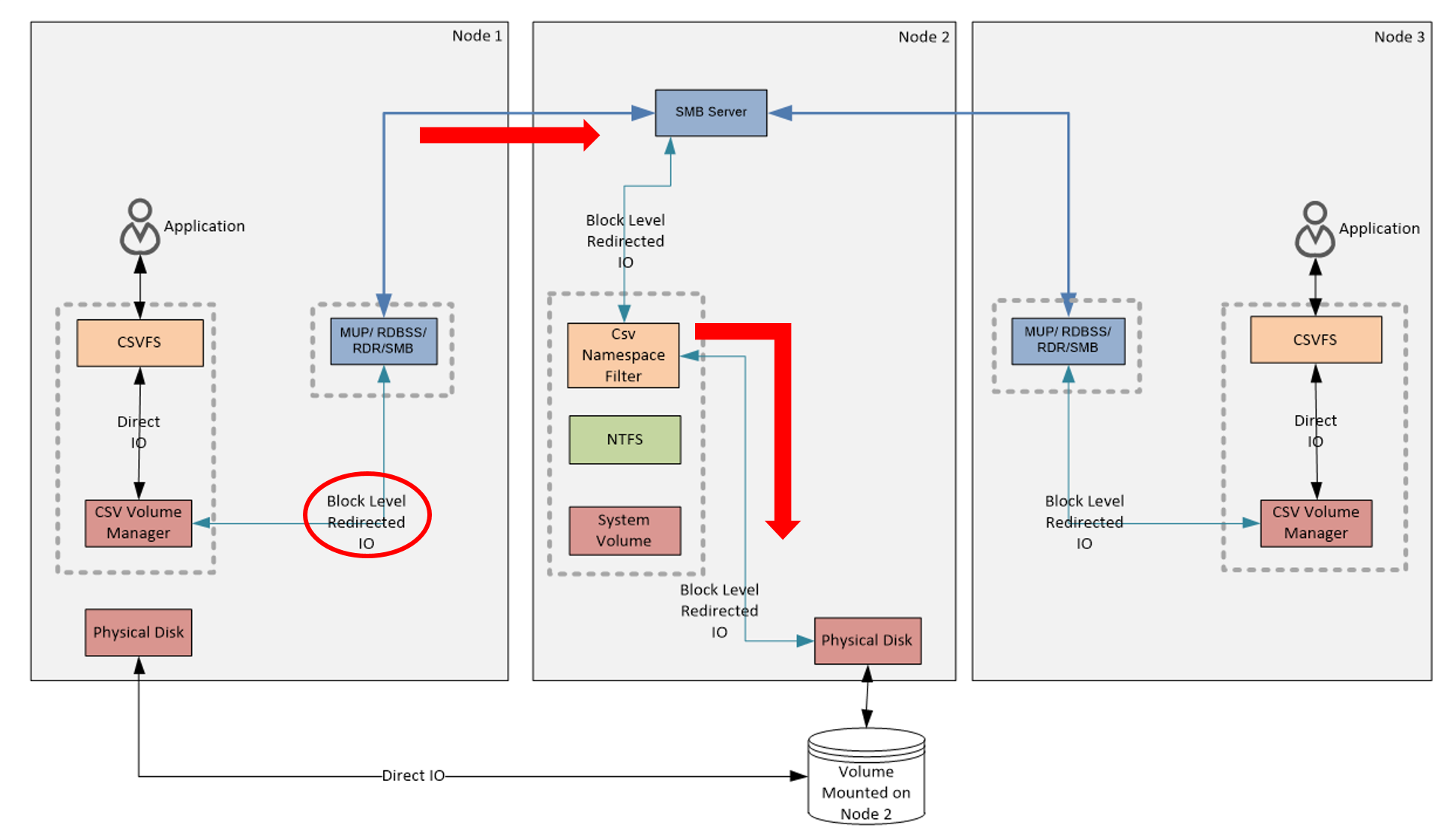
Reference URLs
The list below is the documents I read (but not all) to write this post (in no particular order). The explanations in this post are covered in the following links. If there is something wrong in this post, maybe I misunderstood what the documents say or possibly the contents were too complicated to understand.
I didn't expect there would be so many to refer. I should've assigned reference numbers at least...
https://docs.microsoft.com/en-us/windows-server/failover-clustering/failover-clustering-overview
https://technet.microsoft.com/en-us/library/cc731739.aspx
https://blogs.msdn.microsoft.com/clustering/2010/05/13/introduction-to-the-cluster-quorum-model/
https://docs.microsoft.com/en-us/windows-server/failover-clustering/failover-clustering-overview
https://technet.microsoft.com/en-us/library/jj612870.aspx
https://blogs.technet.microsoft.com/askcore/2016/04/27/free-ebook-introducing-windows-server-2016-technical-preview/
https://docs.microsoft.com/en-us/windows-server/failover-clustering/deploy-cloud-witness
https://technet.microsoft.com/en-us/library/cc731739.aspx
http://www.itprotoday.com/windows-8/dynamic-quorum-windows-server-2012
https://technet.microsoft.com/en-us/library/cc731739.aspx
https://technet.microsoft.com/en-us/library/cc770620.aspx
https://docs.microsoft.com/en-us/windows-server/failover-clustering/whats-new-in-failover-clustering
https://technet.microsoft.com/en-us/library/dn265972.aspx
https://technet.microsoft.com/en-us/library/jj612868.aspx
https://blogs.msdn.microsoft.com/clustering/2013/12/02/cluster-shared-volume-csv-inside-out/
https://blogs.msdn.microsoft.com/clustering/2013/12/05/understanding-the-state-of-your-cluster-shared-volumes-in-windows-server-2012-r2/