はじめに
- 以下の内容は社内向けに作成した発表用のスライドです。なので、スライドモードでの閲覧をオススメ致しますmm
- 統計学の書籍(やさしい内容のやつ)を数冊読み、3週間ぐらいでまとめた内容です。
- なので、足りない部分や不勉強な部分もたくさんあると思いますので、その際はアドバイスを頂けるとうれしいです

- ある日、こんなのコードでテストデータを作っている時にArray#sampleの値の出方に違和感を覚えました

a = []
1000.times do
a << [1, 2, 3, 4].sample
end
a
=> [1, 1, 2, 4, 3, 4, 1, 3, 4, 2, 4, 1, 3...
 何か確かめる方法はないだろうか
何か確かめる方法はないだろうか
勉強中の統計学で何か分からない?
- この違和感を解消してくれる方法がないのかと思って調べてみた
あった 
あった
\chi^2 検定
読み方
カイ二乗検定
カイ二乗検定
を簡単な例を使って説明すると
カイ二乗検定
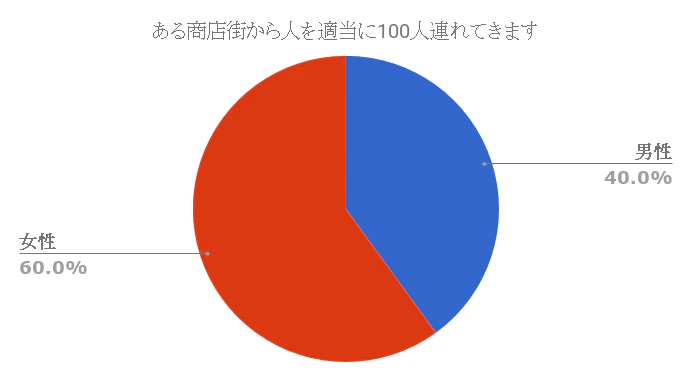
- ある商店街から人を適当に100人連れてきます。
- 100人中、男性が40人、女性が60人でした。
カイ二乗検定
- この割合は普通に起こる確率なのか、それとも滅多に起こらない確率なのかを調べられる事ができます。

違和感を計算してみました
その前に
Rubyの擬似乱数生成器について
- Array#sampleと呼び出すと疑似乱数生成にRandomオブジェクトを使います
- Randomオブジェクトはメルセンヌツイスタ(MT19937)というアルゴリズムを使って擬似乱数を生成しています
- 既存の疑似乱数列生成手法にある多くの欠点が無く、高品質の疑似乱数列を高速に生成できる
- 作者のHP
疑似乱数には2つの性質があります
- 当確率性(等出現性)
- 数値が出現する確率が同じであること
疑似乱数には2つの性質があります
- 当確率性(等出現性)
- 数値が出現する確率が同じであること
- 無規則性
- 出現した各値に相関性がないということ
疑似乱数には2つの性質があります
- 当確率性(等出現性) <== 今回は当確率性を調べます
- 数値が出現する確率が同じであること
-
無規則性出現した各値に相関性がないということ
DEMO
- ここから先は
Jupyter Notebook使ってデモをしながら発表しました。 - もし動かしてみたいのであれば、下のおまじないを初めに実行してからコードを動かしてください。
- 実行環境:Ruby 2.4.1、Enthought Canopy(Python:2.7)
# おまじない達
%matplotlib inline
from collections import Counter
from scipy.stats import chi2
import numpy as np
import matplotlib.pyplot as plt
カイ二乗検定の流れ
カイ二乗検定の流れ
- 仮説を2つ立てる(帰無仮説と対立仮説)
カイ二乗検定の流れ
- 仮説を2つ立てる(帰無仮説と対立仮説)
- 帰無仮説を捨てる基準を決める(有意水準と棄却域)
カイ二乗検定の流れ
- 仮説を2つ立てる(帰無仮説と対立仮説)
- 帰無仮説を捨てる基準を決める(有意水準と棄却域)
- データを収集する
カイ二乗検定の流れ
2.帰無仮説を捨てる基準を決める(有意水準と棄却域)
3. データを収集する
4. 収集したランダムな値の個数と理想の個数にどのくらいズレがあるか計算する(カイ二乗値)
カイ二乗検定の流れ
3.データを収集する
4. 収集したランダムな値の個数と理想の個数にどのくらいズレがあるか計算する(カイ二乗値)
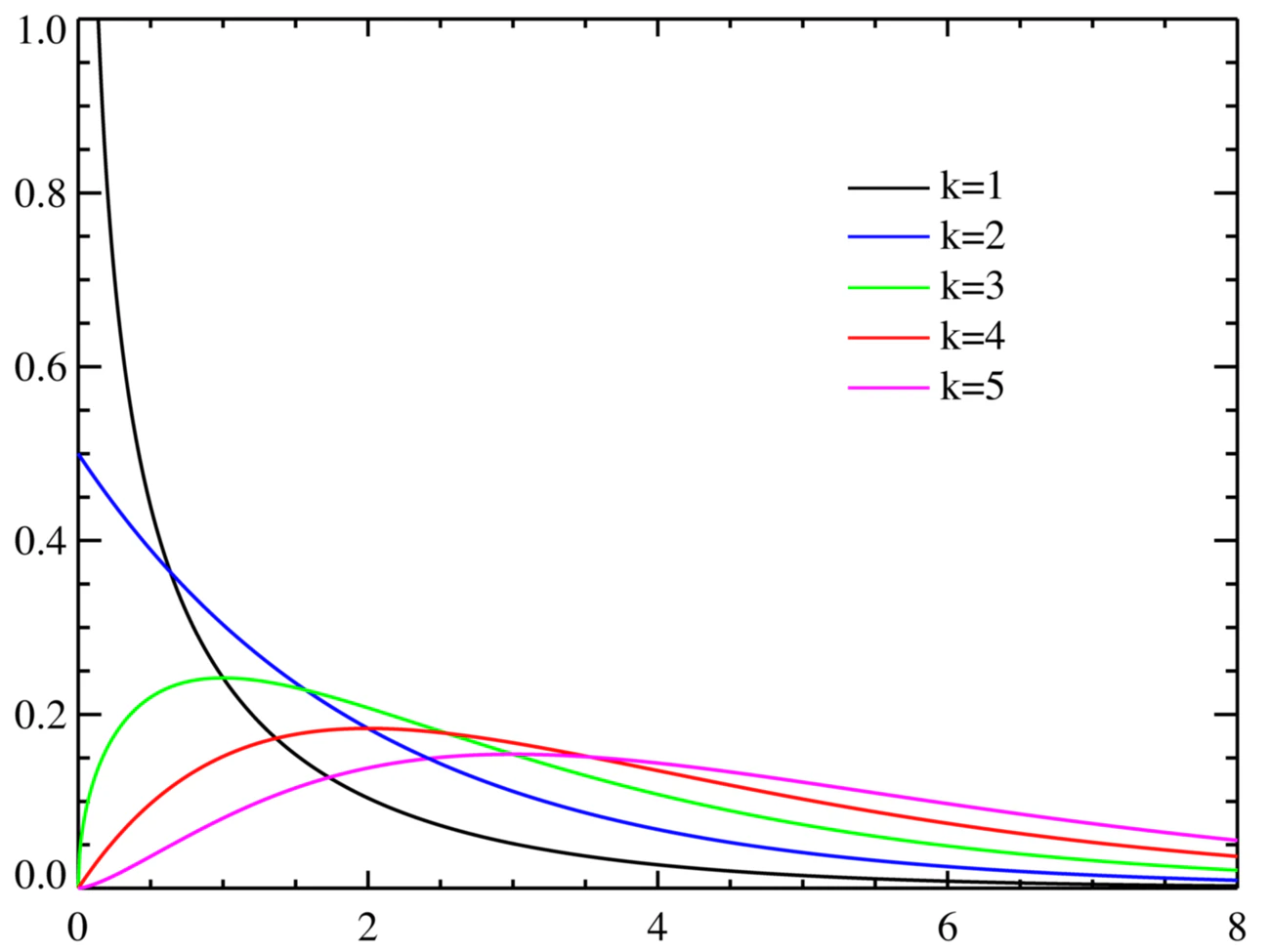
5. 4で計算したカイ二乗値は、カイ二乗分布のどこにいるか確認する
カイ二乗検定の流れ
4.収集したランダムな値の個数と理想の個数にどのくらいズレがあるか計算する(カイ二乗値)
5.4で計算したカイ二乗値は、カイ二乗分布のどこにいるか確認する
6. 4で計算したカイ二乗値は、帰無仮説を捨てる基準(有意水準)より大きいか小さいかを確認する
カイ二乗検定の流れ
5.4で計算したカイ二乗値は、カイ二乗分布のどこにいるか確認する
6. 4で計算したカイ二乗値は、帰無仮説を捨てる基準(有意水準)より大きいか小さいかを確認する
7. 結果
Array#sampleの結果が偏ってる気がして調べてみた
1. 仮説を2つ立てる(帰無仮説と対立仮説)
- 帰無仮説:
- 対立仮説:
Array#sampleの結果が偏ってる気がして調べてみた
1. 仮説を2つ立てる(帰無仮説と対立仮説)
- 帰無仮説:Array#sampleから返される乱数は偏っていない
- 対立仮説:Array#sampleから返される乱数は偏っている
Array#sampleの結果が偏ってる気がして調べてみた
1. 仮説を2つ立てる(帰無仮説と対立仮説)
-
帰無仮説:Array#sampleから返される乱数は偏っていない
- 通常、主張したい仮説ではない方をこちらに設定します
-
対立仮説:Array#sampleから返される乱数は偏っている
- 主張したい仮設
Array#sampleの結果が偏ってる気がして調べてみた
2. 帰無仮説を捨てる基準を決める(有意水準と棄却域)
- 有意水準:
Array#sampleの結果が偏ってる気がして調べてみた
2. 帰無仮説を捨てる基準を決める(有意水準と棄却域)
- 有意水準:5%とします

Array#sampleの結果が偏ってる気がして調べてみた
3. データを収集する
# Array#sampleの結果が偏ってる気がして調べてみた
# 3. データを収集する
# rubyから乱数をもらう
random_numbers = !ruby -e '1000.times {|i| p [1,2,3,4].sample}'
c = Counter(random_numbers)
s = sorted(c.most_common()) # 1=n回, 2=n回, ... の順にソート
o = [] # 観測値
for i in s:
o.append(i[1])
# 期待度数(理論値、期待値などと言ったりする
# 今回のケースであれば、完璧な乱数アルゴリズムであれば250個ずつ出現する
# わかりやすくするために赤線を引いています
plt.hlines([250], 0, 5, "red")
label = ['1', '2', '3', '4'] # ラベル
plt.bar([1, 2, 3, 4], o, align="center", tick_label=label)
plt.show()

Array#sampleの結果が偏ってる気がして調べてみた
4. ランダムな値の個数と理想の個数にどのくらいズレがあるか計算する(カイ二乗値)
# Array#sampleの結果が偏ってる気がして調べてみた
# 4. ランダムな値の個数と理想の個数にどのくらいズレがあるか計算する(カイ二乗値)
# カイ二乗値を算出
# o : 観測度数
# e : 期待度数
def chi2_test(o=[], e=[]):
chi2 = 0.0
for index, i in enumerate(o):
c = ((i - e[index]) ** 2) / float(e[index])
chi2 += c
return chi2
# 期待度数
e = [250, 250, 250, 250]
# カイ二乗値を算出
p = chi2_test(o, e)
print "カイ二乗値は", p, "でした"
カイ二乗値は 2.768 でした
Array#sampleの結果が偏ってる気がして調べてみた
5. 4で計算したカイ二乗値は、カイ二乗分布のどこにいるか確認する
# Array#sampleの結果が偏ってる気がして調べてみた
# 5. 4で計算したカイ二乗値は、カイ二乗分布のどこにいるか確認する
df = 3 # 自由度
rv = chi2(df)
left = np.linspace(chi2.ppf(0.00, df), chi2.ppf(0.99, df), 1000) # 等差数列
height = rv.pdf(left) # 確率密度関数
plt.vlines([p], 0.0, rv.pdf(p), colors="blue")
plt.plot(left, height, lw=2)
plt.show()

Array#sampleの結果が偏ってる気がして調べてみた
6. 4で計算したカイ二乗値は、帰無仮説を捨てる基準(有意水準)より大きいか小さいかを確認する
# Array#sampleの結果が偏ってる気がして調べてみた
# 6. 4で計算したカイ二乗値は、帰無仮説を捨てる基準(有意水準)より大きいか小さいかを確認する
plt.vlines([p], 0.0, rv.pdf(p), colors="blue")
chi2_value = 7.81 # 自由度3の優位確率5%の値
plt.vlines([chi2_value], 0.0, rv.pdf(chi2_value), colors="red")
x = np.arange(chi2_value, 12.0, 0.1)
y1 = rv.pdf(x)
plt.fill_between(x, y1, color="red", alpha=0.75) # 赤く塗りつぶされたところが棄却域
plt.plot(left, height, lw=2)
plt.show()

Array#sampleの結果が偏ってる気がして調べてみた
結果
- 先程計算した値は7.81以下になるので、帰無仮説の「Array#sampleから返される乱数は極端に偏っていない」が捨てる事ができません。
- つまり、**「気のせい」**だった可能性が高いという事が言えます。
参考資料
- 乱数の知識
- カイ二乗検定・適合度検定の計算法を例題から解説。確率の偏りに惑わされないための統計的検定とは
おわり
後日談
- 発表後、試行数を増やしてみては?とアドバイスを頂いたので、やってみました。
1,000,000回で実施
- 乱数集計

-
この時のカイ二乗値
- 7.55628
-
結果

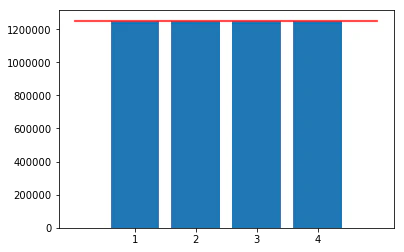
5,000,000回で実施
本当は1,000,000,000回で実施したかったのですが、カーソルが全く返ってこなかったので諦めました
-
乱数集計
-
この時のカイ二乗値
- 2.8323312
-
結果

後日談
- メルセンヌツイスタすごい(小並感)