追記事項(2020/10/13)
10月13日、本日Numerai Signalsが正式にリリースされた。これに伴ってFounderのRichard Craib氏がMediumに記事を投稿している(画像はMedium記事より引用)。

本記事の初回投稿時にはSignalsのターゲットはブラックボックスと書いたが、現在ヒストリカルターゲットが提供されるようになっている。これに加えてCraib氏の記事を受けて、Signalsに参加するインセンティブについても纏め直した。また記事の随所や画像についても最新のものに更新した。
はじめに
前回記事はこちら。
これまでベータ版であったNumerai Signalsの仕様がほぼほぼ確定した。株価のリターンを予測してシャープを競うベータ版から大きく変更が入り、誰も見たことのないようなオリジナルのSignalを探索するというタフな仕様となっている。筆者はこのトーナメントはまさしく世界で最も高度なファイナンスデータトーナメントであると考えており、そう考える理由について1つ1つの仕様を確認しながら解説していきたい。ここに「真のNumerai Signals」と題して新しく記事を興すことにする。
本記事はNumerai Tournamentに参加したことがある方を対象読者として想定しており、予備知識があるものとして説明を行う。
Numerai Signalsの仕様
Signals概要
Signalsのドキュメントはこちら。Signalsでは、トーナメントのように世界中の市場における株価の騰落を予測するのではなく、誰も見たことのないようなオリジナルの投資指標=Signalを探し当てることを目的とする。
世界中の様々なデータソースにアクセスし、たっぷりとアルファを含んだ特徴量を見つけ出し、そこから予測性能が高く且つオリジナリティのあるSignalを抽出する。そして自らがヘッジファンドの予測の一部として置き換わる。何ともエキサイティングな試みだろう。
Signalsの仕様はこれまでにない独自のSignalを探索するためのものである。それでは説明を始めよう。
対象アセット
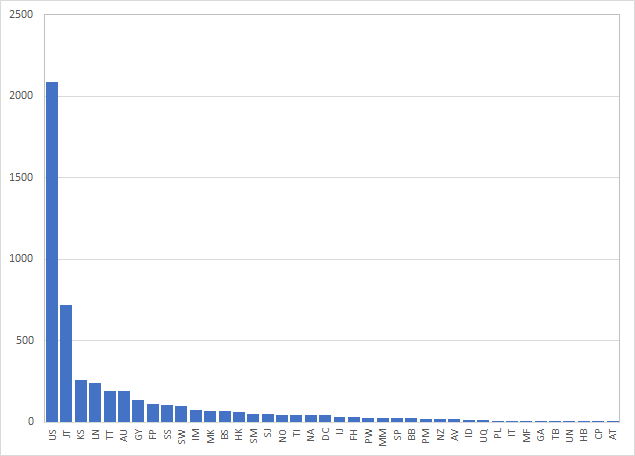
Numerai Signalsは世界中の市場における株式銘柄を対象としており、現時点でその総数はおよそ5200銘柄である。このリストには毎日変更が入るが、流動性不足の銘柄が入れ替わったりするだけで殆どの銘柄は据え置きとなる。最新のリストはこちらから入手することができる。
参考までにどの市場の銘柄がどれだけあるか集計した。最も多いのはUS市場でありおよそ2000銘柄超である。続いて日本市場、韓国市場、ロンドン市場と続いている。
参加者はこの全ての銘柄について予測を提出する必要はない。最低でも100銘柄以上の予測を提出すれば評価対象として舞台に登ることができる。ただし予測を提出しなかった銘柄については、一律で中央値として予測が割り振られ、これはユニバース全体から見れば予測性能が低下することになる。もしも高い性能を求めるのであれば、可能な限り多くの銘柄について予測を提出すべきである(予測の欠損の影響については後のほうで考察する)。
データの取得について
これらの銘柄について、予測に必要なデータは参加者自身が収集する必要がある。Numerai Signalsは、既に自身の予測システムを構築済みで市場データにアクセスできるユーザー向けのプラットホームなのだ。
参加者の予測性能を評価するために運営が公式で使っているデータソースはQuandlである。その他のデータソースとしてQuantopianやAlpacaなどが挙げられる。NumeraiのForumでは安価なデータソースのリストが共有されているので、そちらを是非参考にすべきだろう。なお筆者は現時点ではYahoo Financeを使っている。
また、SignalsのExample modelではYahoo Financeから株価をDLするパイプラインが構築されている。そちらも是非参考にすべきであろう。
Submissionのタイムスケジュール
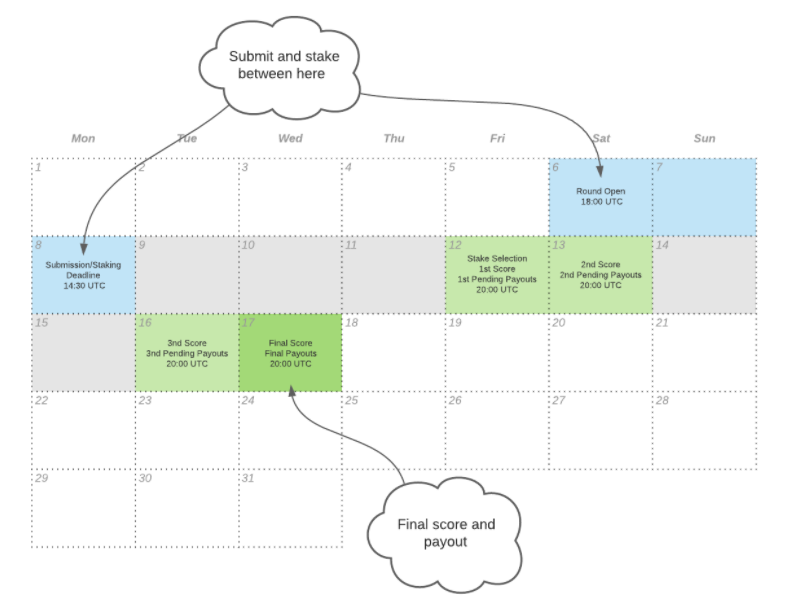
Signalsは週次ROUND制が敷かれている。ROUND開始は土曜日のUTC18:00(日本時刻で日曜日3:00)、予測の提出期限は翌月曜日のUTC14:30(日本時刻で月曜日23:30、Numeraiトーナメントの提出期限と同時刻)である。予測するタイムフレームは、各国の市場における火曜日の終値~翌月曜日の終値である。つまりROUND開始時点の週末から見ると、翌6営業日のリターンから初めの2日を控除したものだ。このラグはポートフォリオ構築に必要な時間を考慮したものだが、要するにNumeraiはTime Decayの小さいアルファを求めている、ということだ。ごく短期間の予測性能は意味を持たない。この点だけでも十分に難しい仕様となっている。
予測結果の直交化
Signalsでは、既知のファクターやSignalとは相関のない全く新しいSignalを探している。これを実現するための手段が、提出された予測を既知のファクターやSignalに対してNeutralize(直交化)することである。
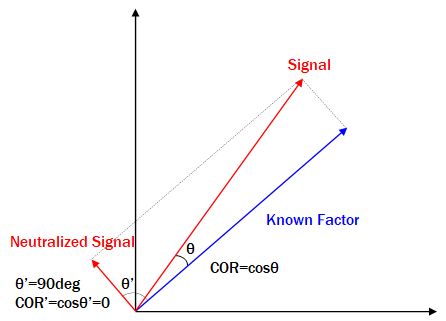
提出したSignalをN次元のベクトルと考える。このとき、既知のファクターに対して直交化すると、もともとのSignalが持つ情報(線形関係)を可能な限り維持しつつ、既知のファクターとの相関を0に変換できる(すなわち、既知のファクターに対するオリジナル成分を抽出できる)。分かりやすく2次元(N=2)の例を下に示す。提出したSignalと既知のファクターの相関係数は、各々のベクトルがなす角度(正確にはcosθ)を示す。以下のようにSignalのベクトルを既知のファクターのベクトルに対して直交化(垂直)することで、相関を0(つまりcosθ'=0)とすることができる。
重要なことであるが、この直交化は複数のベクトルを対象として行うことができる。3次元の空間を想像してみよう。Signalベクトルは既知のファクターベクトル1と2が作る平面に対して垂直成分を抽出できる。一般化すると、N次元ベクトルではN-1個のベクトルに対して直交化できるはずだ。つまりSignalsの次元は5000程度なので、少なくとも数千のファクターに対して同時に直交化を行うことが可能なのである。
Signalsの仕様では、提出された予測はBarraファクター、カントリー、業種、その他Numeraiが保有する全ての固有ファクターについて直交化を行う、と明言されている。この直交化によって、単純に単一のファクターによる線形情報を控除するだけでなく、既知のファクターをもとにモデリングした予測結果も同時に控除される可能性が高い。Numeraiは手持ちのFeatureについてツリー系のモデルやニューラルネットなどの非線形なモデルをいくつか作っておくことで、単純な情報のモデリングで生成される成分は全て控除することができるのである。
予測ターゲット
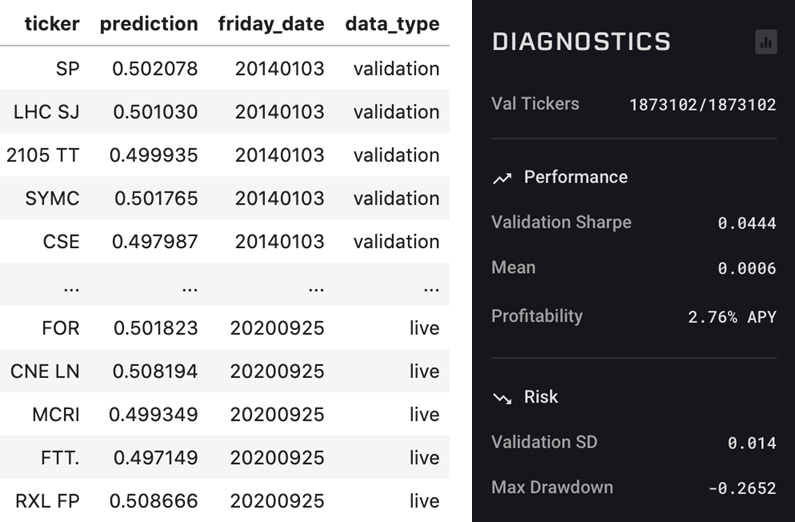
予測ターゲットは、こちらも予め市場リターンに対してNumeraiの持つ全ての情報に対して直交化される。このプロセスに関してはブラックボックスであるが、ユーザーにはヒストリカルターゲットが与えられる(こちら)。
このターゲットは、2003年から2012年までがtrain用のターゲット、2013年から2020年2月までがvalidation用のターゲットとなっている。ユーザーは最新の予測(live)を提出する際に過去の予測結果(validation)も同時に提出するとNumeraiの評価メトリクスに基づいた評価結果をもらうことができる。
ただしこれらの評価結果はあくまでも参考であり、オーバーフィッティングには最新の注意を払う必要がある。何よりも過去に得られた良い結果は未来に反映されることで劣化する可能性が高いと言及されている。
予測の評価とリーダーボード
予測の評価は以下の手順にて行われる。まず、参加者が提出した予測結果は、Numeraiの手によって全ての情報に対して直交化が行われる。その結果と、Numeraiのカスタムターゲット(これも直交化されている)との相関係数CORを計算する。この相関係数CORはアクティブポートフォリオ論において情報係数(IC:Information Coefficient)と呼ばれるもので、Signalの持つ予測力として判断される。
なおリーダーボードのランキングには直近20ROUND(つまり20週)のCOR平均が用いられる。
報酬体系
報酬体系であるが、参加者のステイク量に対して2*CORを乗じたものが報酬として付与(もしくは徴収)される。トーナメントでは上位入賞者のCOR平均はおよそ0.03(つまり3%程度)であった。Signalsについてはこれよりも低くなると想定されており、そのため係数として2倍を乗じている。
例えば、SignalsにおけるCORが週平均0.015であれば、ステイク量に対して平均週利3%が期待される。もしもこのようなパフォーマンスを達成できれば、年利として単利計算156%、複利計算365%という大きなリターンとなる。
またトーナメント同様、SignalsにもMMCによる報酬が存在する。MMCとはMeta Model Contributionであり、簡単に言うと他の参加者の予測に対するオリジナリティを競う部分である。
前節のCORの計算では、予めNumeraiの持つ情報が控除されたのに対し、MMCではそれに加えて他の参加者の提出した予測が控除される。この控除には、全参加者によるメタモデル(ここではNeutralize後のSignalのステイク加重平均)が使われる。
MMCによる報酬は選択制となっている。MMCは、オリジナルを探してきた者同士でさらにオリジナリティを競うという非常に厳しい仕様である。

Signalsにおける留意点
予測の欠損
Signalsでは5000銘柄以上の銘柄が対象であるため、その中にはデータが取得できない銘柄が当然あるだろうし、対象を限定して予測したい参加者も多いだろう。そもそもオルタナティブデータを探すのであれば、全ての銘柄についてそれを集めるのは不可能なことである。
参加者は最低でも100以上の銘柄を予測すれば良いが、その場合には欠損値が一律で中央値に置き換わるためCORの数値が劣化する。今回はその影響を見積もった。
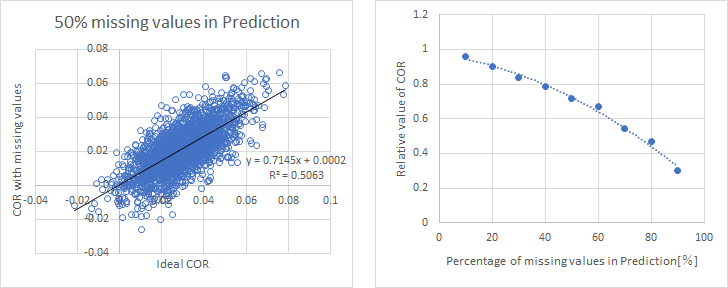
右図は提出する予測に50%欠損が存在する場合にCORがどのように変化するか、ランダムシミュレーションを行った結果である。回帰直線の係数は0.715であり、50%欠損がある場合には全ての予測を提出した場合に対して平均してCORは0.7倍程度の値となる。
左図では横軸を欠損率で振ったものであり、例えば欠損が増えるに従って緩やかにCORが劣化していく様子が確認できる。
結論として、
- 予測に欠損がある場合、CORの値が劣化する。
- これはプラス側にもマイナス側にも起こりうる(つまりマイナス側だと損失が軽減される)
- つまり非対称性は存在せず、報酬の観点からは本来のCORに対してデレバレッジが掛かった状態となる。
- 一方で得られるCORの絶対値は低くなるため、LB上位を狙うには不利となる。
予測銘柄数をどのように選ぶか、参加者の判断が重要である。
予測の作り方
Signalsで高評価を得るためには、通常とは異なるデータソース(オルタナティブデータ)を用いるか、それともオルタナティブデータがなくとも既存のデータを用いて機械学習で独自のモデリングを行い、一般には得ることが難しいアルファを抽出することが考えられる。
前者の例を挙げると、簡単に考えつくものはチャートの画像認識や特徴抽出だ。チャートを何万枚も用意して教師なし学習で特徴抽出する。そして各銘柄のチャートの特徴を一次元まで圧縮し、この値をpredictionとして提出するのだ。このようなデータでは単純な株価の値動き自体に対する予測力がなくとも、カスタムターゲットには何らかの予測能力が生じる可能性がある。
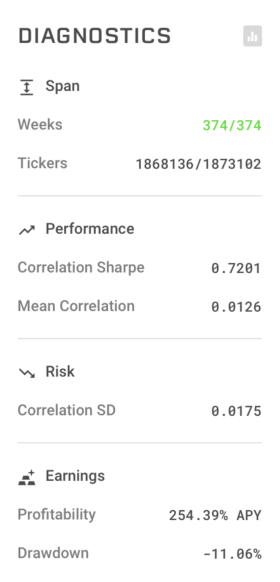
また後者の例では、以下のUpload結果例のようにオルタナティブデータがなくとも機械学習によって非線形アルファを抽出することでNeutralize後にも十分な予測力を保持できることが確認されている。このモデルのCORは0.0126、年利に換算するとおよそ254%であり、自身で一般的な投資を行うよりも十分すぎる値となっている。
Signalsに参加するインセンティブ
Signalsに参加するインセンティブとは、自身の持つ唯一無二の投資アイディアについて大きな収益性を得られることにある。
- カスタムターゲットでのモデリングにより、自身の持つ投資アイディアのオリジナリティを認識できる
- 自身の持つオリジナリティにベットすることで、既存の投資対象とは全く異なる収益源を構築することができる
- 本来これらの収益源は微小であるが、ステイク報酬には大きなレバレッジが利いており収益性を大きく向上できる
- 予測そのものにベットすることができ、取引コストが掛からず理想的な収益を享受できる。
おわりに
本記事ではNumerai Signalsの仕様について説明し、その攻略の考え方について記した。繰り返しになるが、Signalsは株価を予測するためのものではなく、この世のどこかから未知のデータを発掘してくるためのものである。
オルタナティブデータを含めた様々なアルファの探索は世界中のヘッジファンドで行われている。Signalsは単なるファイナンスデータトーナメントではなく、世界中のヘッジファンドと肩を並べてこれらの探索に加わるということを意味するのだ。Signalsとは、世界中のデータサイエンティストにデータを探索させてそれらを自動で収集・評価するためのプラットホームなのだ。
これがSignalsが最も高度なファイナンスデータトーナメントだと筆者が考える理由である。もしも金脈を発掘できた暁には最高の名誉が待っているだろう。
さあ世界中に埋もれたSignal探しの旅へ出発しよう。