はじめに
DynamoDBはキーバリュー形式のNoSQLデータベースであることはわかっている。そして、テーブル単位でありスキーマという概念がないこともわかった。で?という人に向けにDynamoDBの概要についてまとめる。
全体像
DynamoDBの全体像を図にまとめる。
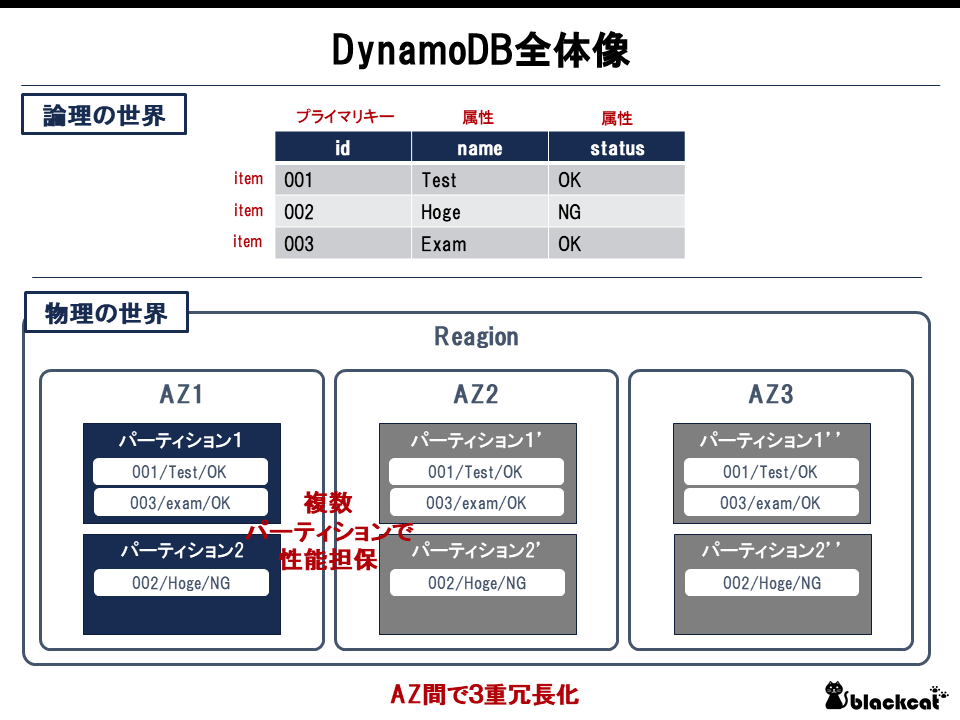
なるほど、AZ間で3重冗長化しているため、信頼性は確かに高い。そして、AZの中では複数のパーティションに分散されることで物理的な性能を担保している。パーティションの数がいくらかになるかは、計算式により算出できる。(後述)
2種類のテーブル
まず押さえておきたいのはDynamoDBのテーブルはプライマリキーの構成によって、2種類にわかれるということだ。
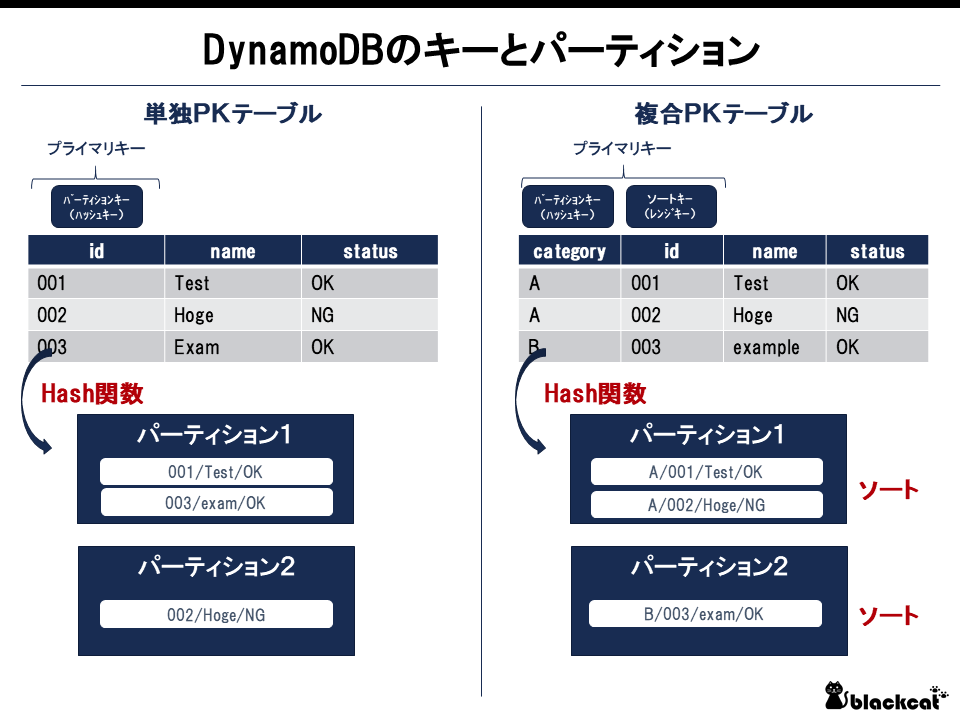
1つは、パーティションキーのみのパターン。(これを便宜的に単独PKテーブルとする)
プライマリキーは重複が許されないため、この場合パーティションキーは一意となる。パーティションへの分散はパーティションキーをHash関数にかませた結果により決定される。
もう1つは、パーティションキー&ソートキーのパターン。(これを便宜的に複合PKテーブルとする)
この場合は、2つのキーを組み合わせた結果が一意であればいい。パーティションの中では、ソートキーにより物理的にデータがソートされている。
キーを使った検索
単独PKテーブルと複合PKテーブルで仕様が異なる。
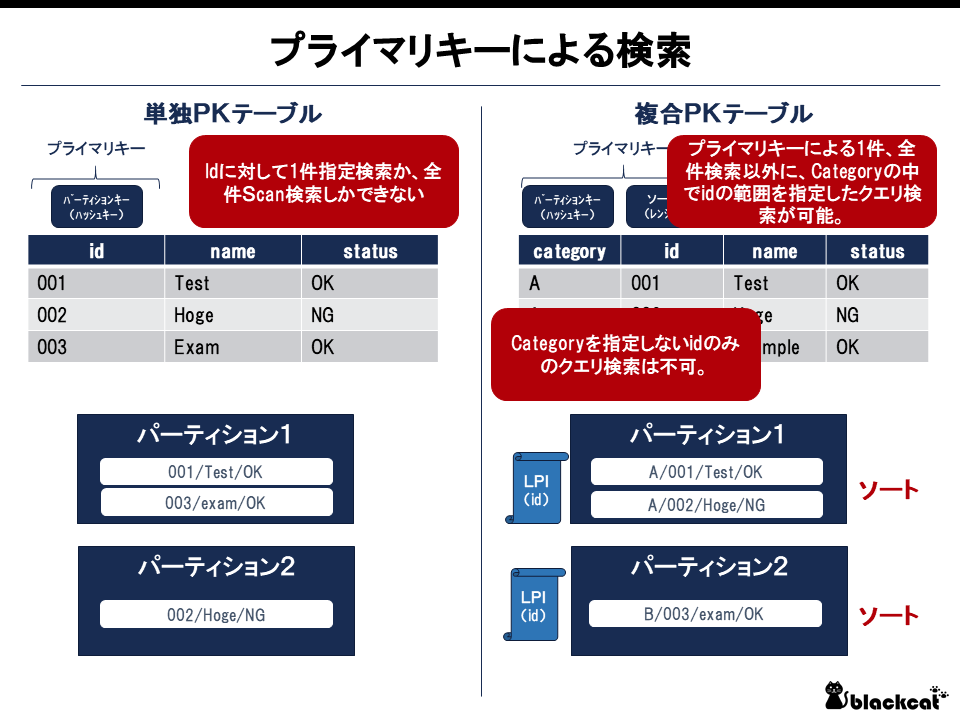
単独PKテーブルの場合は、プライマリキー(≒パーティションキー)指定による1件取得か、SCANによる全件取得しかできない。
一方、複合PKテーブルにはパーティション内にインデックスが作成されるため、「パーティションキーを指定した上でのソートキーによる範囲を指定したクエリ検索」が可能になる。
このインデックスを便宜的にローカル・プライマリ・インデックス(LPI)と呼ぶ。ローカルとは、各パーティション内に作成されていることを意味する。この構成上、「パーティションキーを指定しないソートキーのみの検索」はできない。
インデックスを使った検索
DynamoDBでキー以外での検索を行うためには、インデックスを最初に定義しておく必要がある。
なお、インデックスにはLSI(ローカル・セカンダリ・インデックス)とGSI(グローバル・セカンダリ。インデックス)の2種類が作成できる。
LSI
LSIはLPIを踏襲した仕組みだ。ソートキー以外にインデックスを作成できる。結果として、パーティションキーを指定した上でのインデックスを作成した属性のクエリ検索が可能になる。
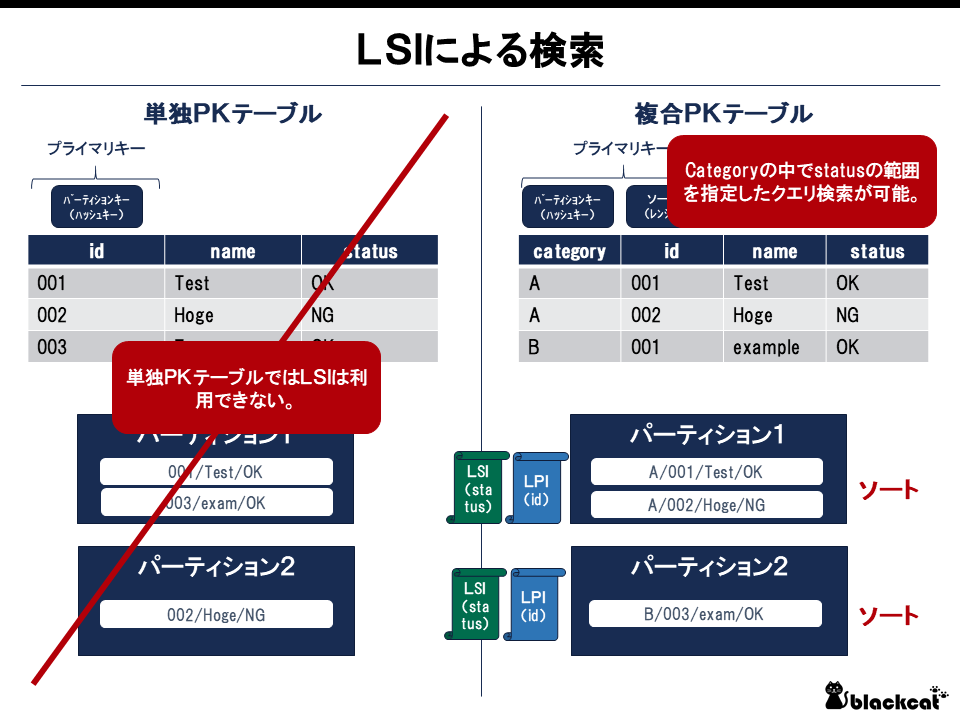
なお、LSIは最大10GBまでの制約がある。
GSI
GSIはインデックス用に新たにパーティションキーとソートキーを指定して検索できるようになる。つまり、物理パーティションに囚われない検索が可能になる。
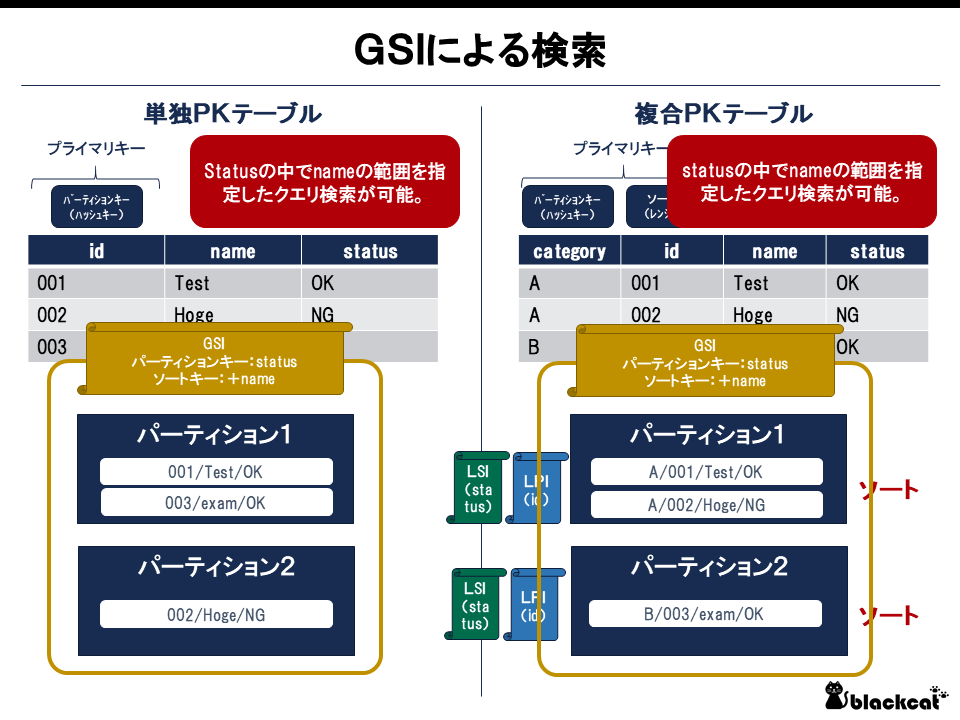
図でいうと「statusがOKでnameがTで始まるユーザを検索する」といった検索が可能になる。
なお、注意しないといけないのは、インデックス用のパーティションキーとソートキーは一意にならない可能性がある。(厳密にいうとDynamoDB側で一意制約をかけることができない。)したがって、完全な一意制は担保されず、2件以上が検索の結果として帰ってくる可能性があることは頭に入れておく必要がある。
また、GSIに指定した属性はnull(=存在しない)可能性もある。つまりSCANの結果返される値については「属性が存在するitemの全件数」となる。
ここで1点疑問が生じる。DynamoDBはパーティションの概念により性能を担保しているのに、GSIはパーティションを無視しているが大丈夫なのか?答えとしては、GSIは実体テーブルとは別に新たにパーティションを再分配しなおした射影テーブルが生成されるとのこと。これはテーブルの容量や後述する整合性、キャパシティに関連してくる。(なお、LSIも射影自体は生成される。ただし、実体テーブルと同じパーティション配置になる。)
整合性
Dynamo DBでは結果整合性という特性がある。つまり、データを更新(あるいは削除)した直後には一定の確率で古いデータが取得できてしまうことがある。
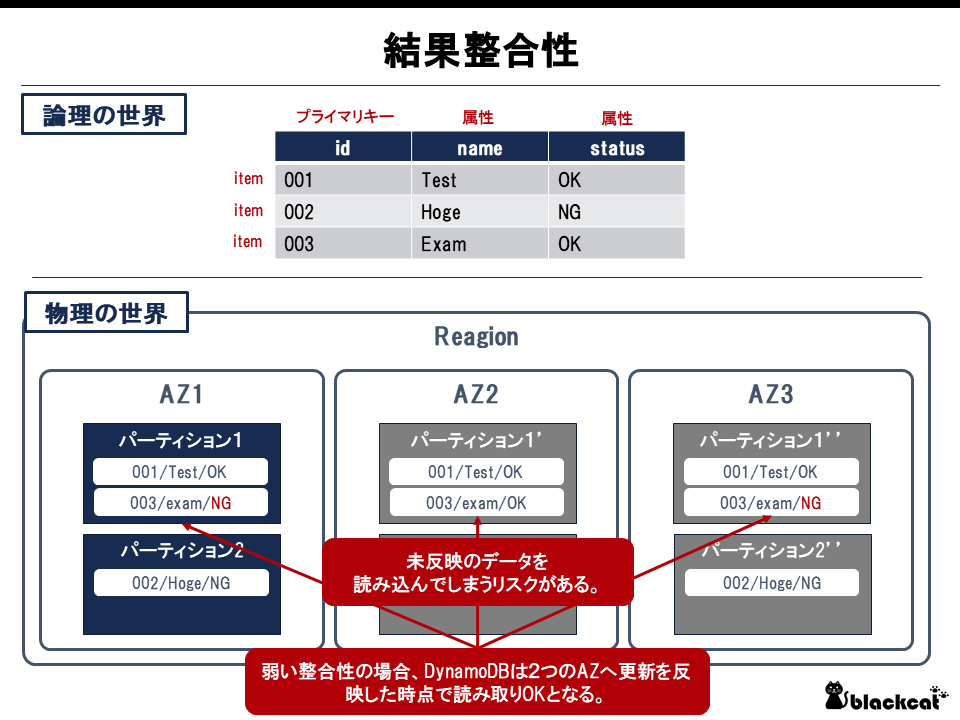
ただし、「強い整合性の読み込み」というオプションを利用できる。このオプションを利用すると、2つのAZを選択し、その値を比較。値が一致した場合は値を返し、もし値が不一致だった場合は残りの1つも読み出して、多数決で多い方の値を返す。つまり古いデータを読み込む可能性がない。
強い整合性の読み込みの制約
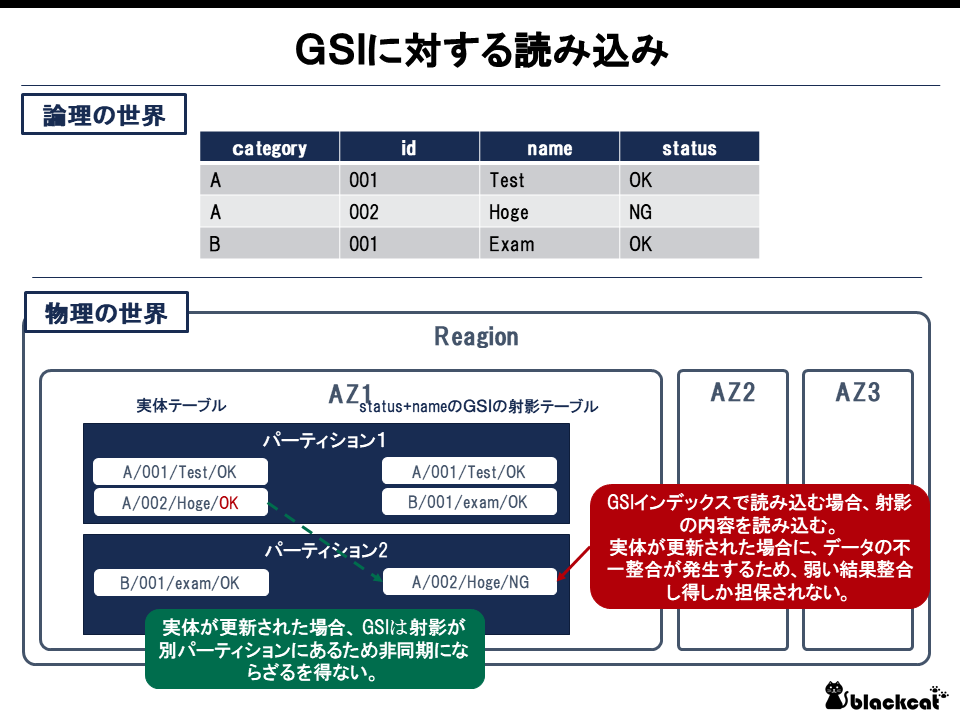
読み込みには「プライマリキーを利用した読み込み」と「インデックスを利用した読み込み」がるが、GSIを利用している場合は実体とは別の射影テーブルから読み込まれる。実体テーブルへの更新が射影テーブルに反映されるには物理パーティション構成が異なることから非同期とならざるを得ないため、GSIに対しては強い整合性の読み込みが利用できない。
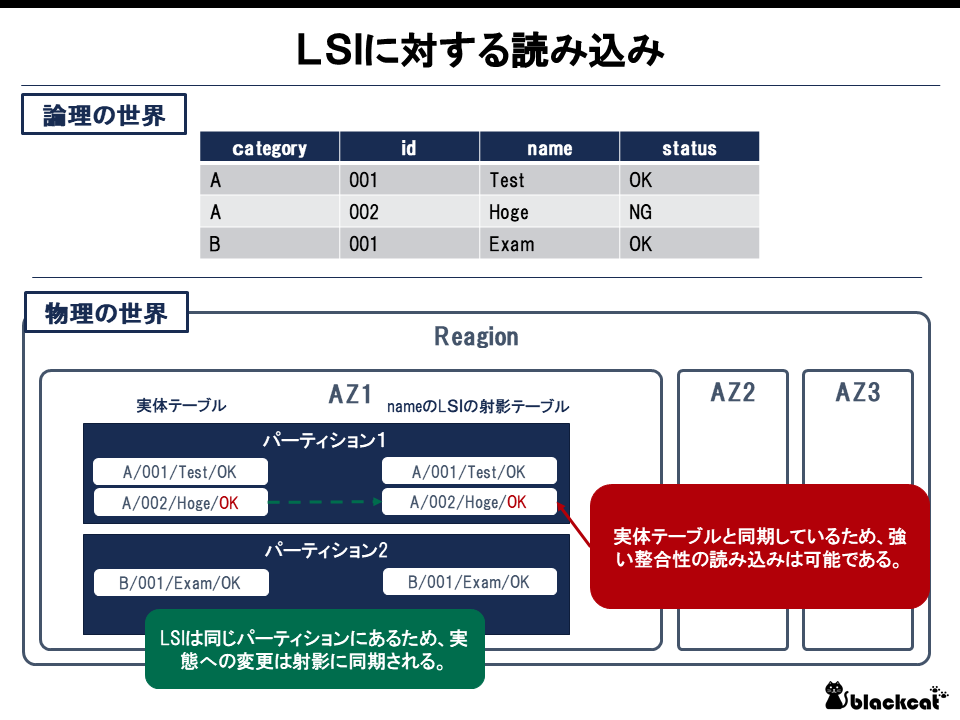
LSIの場合には実体テーブルと射影テーブルが同じ物理配置となるため、同期が可能であり、強い整合性の読み込みが可能となる。
読み込み・書き込みキャパシティ
DynamoDBでは読み込みと書き込みのキャパシティをそれぞれユニットと呼ばれる単位で設定できる。
1ユニットの性能は以下である。
- 書き込み(WCU):1秒間に最大1KBのデータを1回書き込むことが可能
- 読み込み(RCU):1秒間に最大4KBのデータを2回読み込むことが可能
なお、強い整合性の読み込みを利用すると、 2回が1回に半減する。
キャパシティの分配
キャパシティはテーブルに対して設定する。一方テーブルは物理的にはパーティションに分割されている。この場合、キャパシティはパーティションに均等に分配される。
つまり、ホットパーティション(一部のパーティションに読み書きが集中すること)するようなテーブル設計をしてしまった場合、キャパシティは実質1/nしか利用されないこととなる。
という話ではあったが、最近「Adaptive Capacity」という機能がDynamoDBの裏側に追加された。
Amazon DynamoDBの適応能力が不均一なデータアクセスパターンに対応する仕組み(または、なぜDynamoDBについて知っている情報が古くなっているのか)
簡単に言うと、ホットパーティションが発生しそうな場合、他のパーティションでキャパシティが余っていたらそれを利用できるって話みたい。
リクエストスロットリング
クライアントからキャパシティを超えるリクエストを送った場合、DynamoDBはエラーを返す。
なので、エラーが返された場合の処理をクライアントには実装する必要がある。
キャパシティの変更
プロビジョンドスループットはオンラインで後から変更することが可能。
キャパシティのAuto Scaling
キャパシティは自分で設定する以外にも、AutoScalingさせることができる。実際には上限、下限、目標使用率を指定すると、その範囲で動的にスケールする。
DynamoDB On-demond
従来はキャパシティをプロビジョニングしていたため、実際に利用していなくても課金が発生していた。請求モードを変更することで、使った分だけ(リクエスト分だけの)の支払いができるようになった。
On-demandかAuto Scalingか自分で指定か?
ここで、DynamoDBを利用する場合、どれを選択すべきかが議論になる。
- 自分で設定してプロビジョニング(パーティション設計が必要)
- Auto Scalingによるプロビジョニング(パーティション設計が必要)
- On-demond(パーティション設計が不要)
On-demondならパーティション設計も不要だし、テーブル作ってもリクエストしなければ費用がかからないし、一見よさげに見えるが以下を見ると一概にそうとは言えない。
DynamoDBのオンデマンドとプロビジョニングの料金を比較をしてみた
結論に以下のような内容が書かれている。
ReadとWriteのそれぞれの操作に関してはそれぞれプロビジョニングしているキャパシティに対して実際のリクエスト数が14.4%程度の場合にオンデマンドとプロビジョニングの金額が一致していました。具体的には100 Read or Write capacity unitを確保している場合、理論上の1時間あたりの最大リクエスト数は36万リクエストになりますが、オンデマンドを利用した場合は実際のリクエスト数が51,997リクエストを超えるとプロビジョニングよりもAWS利用費が高くなるという意味です。
つまり、キャパシティを15%以上利用される設計にできるのであれば、プロビジョニングのほうが安く済むということだ。この辺は、システムの特性を見ながら考えていかなければいけない。
インデックスのキャパシティ
LSIの場合、テーブルのキャパシティが使われる。GSIの場合は、テーブルとは別にGSI用のプロビジョンドスループットが別に定義される。
パーティション数の決定
パーティション数の決定はストレージ利用容量による基準とキャパシティによる基準がある。
-
キャパシティ
簡単に言うと、パーティションの最大ユニット数を上回るキャパシティが設定されたら1つ増やすという話だ。 1パーティションの最大ユニット数は、読み込み:3000RCU、書き込み:1000WCRであるので...
パーティション数 = (読み込み)キャパシティ/3000RCU + (書き込み)キャパシティ/1000RCU -
ストレージ利用容量
これもキャパシティと同様1パーティションの最大容量を上回ると1つ増やすという。1パーティションの最大容量は10GBであるので...
パーティション数 = 利用容量/10GB
2つの計算式で算出された値を比べて大きいほうが採用される。つまり、プロビジョンドスループットが小さくても容量を多く使っていればパーティションは多くなし、容量を使ってなくてもキャパシティが大きければパーティションは多くなる。
パーティション数の増減
容量が増えたり、キャパシティを大きくするとパーティションは増える。
一方、容量が減ったり、キャパシティを小さくしてもパーティションが減ることはない。代わりに1つ当たりのパーティションのキャパシティが減る。
1つあたりのパーティションのキャパシティが低くなるため、ホットパーティションの影響を一層受けることになる。
パーティションのバースト
パーティションのキャパシティは300秒前分で使われなかったキャパシティをストックする。
つまり、一時的にプロビジョンドスループットが上がっても、ストック分を利用することでリクエストスロットリングを回避できる。ただし、ストック分を使い切ってしまった場合はリクエストスロットリングが発生する。
料金
- プロビジョニングされたキャパシティによる時間料金orリクエスト数重量課金
- 利用容量
その他機能
Streams&Triggers
DynamoDBに行われた追加・変更・削除を24時間保持し、旧データにアクセスできる機能。24時間が経過すると削除される。itemに対する順序性は保証されるが、item間の順序性は保証されない。
なお、DynamoDBのAPIエンドポイントとは別にStrems用のエンドポイントが作成される。
Triggersは、DynamoDB Streamsにデータが流れたことを引き金とし、Lambdaを発火させられる機能。この2つの機能を利用して、データの追加や変更時にLambdaを発火させることができる。
TTL
アイテムに有効期限を設定でき、有効期限が過ぎると自動的に削除されるように設定できる。有効期限が切れてから最大48時間以内に削除される。
DynamoDB Accelerator(DAX)
DynamoDBにキャッシュを置ける機能。キャッシュを置くと、キャッシュからのレスポンスをミリ秒単位からマイクロ秒単位になるように高速化することができる。AWSの裏側では、アイテムキャッシュとクエリキャッシュの2つが提供される。
Global Tables
別リージョンにテーブルの複製を作成して、最終的に同期してくれる機能。ただし、さすがにタイムラグがあるため、テーブルに強い整合性の読み取りを設定していても、リージョン間では結果整合性となる。書き込みに関しても最終的には更新時刻の遅いほうが適応される。
何が言いたいかというと一時的であるがリージョン間で不整合が発生することはあり得るということを意識しないといけない。
また制約として「空のテーブルである」ということが必要であり、後から変更することができないので、最初の設計が大事である。なお、もう一つの要件として「DynamoDB Streamsを有効化する必要あり」があるが、つまり、裏ではStreamsを利用して別リージョンのテーブルに変更を加えるだけと予想される。(それでも自分で設定しなくてよくて助かるのだが。。。)
Point-In-Time-Recovery
デフォルトで有効化されている機能。1秒単位でデータをバックアップし、35日以内であれば1秒単位でリストアできる。復元は別テーブルを作る形になる。
On-demand Backup
上記とは別に明示的にバックアップを取得できる機能。PITR同様復元は別テーブルを作る形になる。
Encryption at rest
DynamoDBはサーバーサイド暗号化が必須であり、しないという選択肢はない。そんな中で、KMSも使えるけどDynamoDBが用意したキーで勝手に暗号化してくれよという機能。
Transacitions
最近DynamoDBにトランザクション更新ができるようになった。つまり、まとめて更新時に1件でもミスったら全件取り消しみたいなことができる。
新機能 – DynamoDB Transactions
ただし、いろいろ罠が多くて、使うのは注意しないといけないみたい。
Itemはトランザクション中にロックされません。DynamoDB transactionsはトランザクション分離レベルだとserializableになります。トランザクションの進行中にアイテムがトランザクション外で変更された場合、トランザクションはキャンセルされ、例外を発生させたアイテムまたはItemに関する詳細がスローされます。
まとめ
キー&インデックス、パーティション、キャパシティの概念さえ掴めれば、そんなに難しい話ではない。あとは触っていけば理解が深まりそう。